 數據集使用的Kaggle中辨別狗狗種類的競賽
數據集使用的Kaggle中辨別狗狗種類的競賽
編者按:在人工智能的各個領域,深度學習框架正變得越來越高效,其中圖像分類更是得益于此。在這篇文章中,作者devforfu嘗試用Keras庫將現成的ImageNet和預訓練深度模型應用到圖像分類框架上。他搭建了一款模型,可以辨別圖片中狗狗的種類。
數據集
在這個項目中,數據集使用的Kaggle中辨別狗狗種類的競賽,其中包含了將近10000張經過標記的圖像,大約涵蓋了120種狗狗,除此之外還有數量相當的測試數據。一般來說,這些圖像的分辨率、縮放程度都是不同的,其中也可能不止有一只狗,光線也會有差別。下面是數據集中的幾張圖像。
數據集中各種種類的狗狗數量大致相同,平均每種狗狗有59張圖像。以下是數據集中各種類狗狗的數量分布:
正如我們簡單分析過的,經過分析的數據集對深度學習框架來說并不復雜,并且有很多簡單結構。所以我們可以從數據集中得到各種類精確的結果。
Bottleneck特征
運用預訓練深度學習模型最直接的策略之一是將它們看作特征提取器。在現代神經網絡架構發展之前,圖像特征是手動過濾的,例如Canny edge detectors中的Sobel operator。運算符(operator)是一個3×3的矩陣,向其中輸入原始圖像后,它會將其轉化成一個正方形的圖塊,每個小方塊都會轉換成單一值。
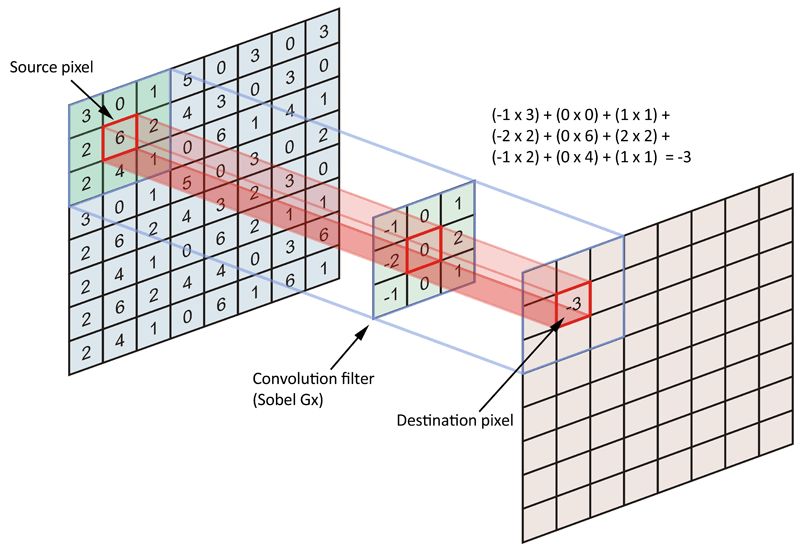
Sober運算符在單一圖像通道上的大致表示
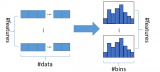
如今的技術可以從數據中直接自動提取特征。為此,我們用的是卷積層。每個卷積層都是具有隨機初始值的正方形矩陣堆棧。這些值在訓練過程中被更新,最終會收斂到適合數據集的特殊過濾器上。
下圖展示了深度學習分類器作為特征模塊序列的大致表示,將圖像從原始的像素表示轉換成更加抽象的表示:
如上圖,一個沒有頂層圖層的深度學習網絡為每張通過網絡的圖像生成了一套高水平的特征。這些特征被稱為bottleneck特征。深度模型自動推理出這些抽象的圖像特征,我們可以用它們以及任意“經典”的機器學習算法來預測目標。
注意:本文所提到的所有模型和特征提取器都是在單一1080Ti GPU上執行的。如果用CPU的話,在有數千張圖片的數據集上提取特征可能要耗費好幾個小時。
因此,想從圖片集中提取特征,研究者需要下載一個有預訓練權重的深度網絡,但是沒有頂層,之后為這些圖像”做預測“。示例如下:
classFeaturesExtractor:
"""Runs pretrained model without top layers on dataset and saves generated
bottleneck features onto disk.
"""
def __init__(self, build_fn, preprocess_fn, source,
target_size=(299, 299, 3), batch_size=128):
self.build_fn = build_fn
self.preprocess_fn = preprocess_fn
self.source = source
self.target_size = target_size
self.batch_size = batch_size
def __call__(self, folder, filename, pool='avg'):
model = self.build_fn(weights='imagenet', include_top=False, pooling=pool)
stream = self.source(
folder=folder, target_size=self.target_size,
batch_size=self.batch_size, infinite=False)
batches = []
with tqdm.tqdm_notebook(total=stream.steps_per_epoch) as bar:
for x_batch, y_batch in stream:
x_preprocessed = self.preprocess_fn(x_batch)
batch = model.predict_on_batch(x_preprocessed)
batches.append(batch)
bar.update(1)
all_features = np.vstack(batches)
np.save(filename, all_features)
return filename
代碼的第15行創造了一個沒有頂層的Keras模型,但是具有預先安裝的ImageNet權重。之后,22—25行對所有圖片進行了迭代,并將它們轉化成特征數組。之后在第29行,數組被永久存儲。注意,我們并不一次性下載所有可用圖片,而是創造一個生成器,替代從硬盤中讀取文檔。這樣操作可以允許在沒有足夠RAM的情況下處理大型數據集,因為圖片從JPEG轉換成PNG格式會消耗很大內存。
之后,我們可以用FeatureExtractor:
from keras.applications import inception_v3
extractor = FeatureExtractor(
build_fn=inception_v3.InceptionV3,
preprocess_fn=inception_v3.preprocess_fn,
source=create_files_iterator_factory())
extractor(folder_name, output_file)
Bootstrapped SGD
隨機梯度下降(SGD)是一種簡單高效的在凸形損失函數對線性分類器進行判別學習的方法。簡單地講,將圖片特征的數組和他們的標簽輸入算法中,訓練一個多種類的分類器,從而判斷狗狗的種類。
雖然現在已有了一個特殊的SGD分類器,但是還不夠穩定。對算法運行多次之后可能會得到不同精度的結果,因為算法在學習開始時對參數進行了隨機初始化。
為了讓訓練過程更加穩定并且可重復,為了達到最佳精度,我們將用bagging擴展SGD,這種方法可以訓練SGD分類器的集合,并且能從多個估算器中對反饋取平均值,得出最終的預測。下圖是這一過程的展示:
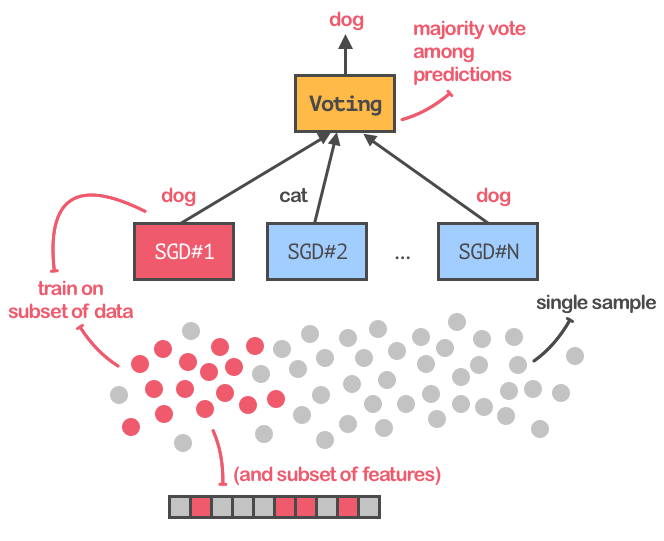
在SGD分類器上應用bagging技術
注意,我們不僅僅是將原始數據集拆分成子集,而是將不同特征的自己放入不同分類器訓練。另外,我們還應用了一個“變量閾值轉換器(variance threshold transformer)”,將值接近于0的bottleneck特征過濾掉,因為深度學習網絡提取的特征向量似乎非常稀疏。
下面的代碼展示了如何創建一個SGD分類器,以及如何計算能反映模型質量的預測標準:
def sgd(x_train, y_train, x_valid, y_valid, variance_threshold=0.1):
threshold = VarianceThreshold(variance_threshold)
sgd_classifier = SGDClassifier(
alpha=1./len(x_train),
class_weight='balanced',
loss='log', penalty='elasticnet',
fit_intercept=False, tol=0.001, n_jobs=-1)
bagging = BaggingClassifier(
base_estimator=sgd_classifier,
bootstrap_features=True,
n_jobs=-1, max_samples=0.5, max_features=0.5)
x_thresh = threshold.fit_transform(x_train)
bagging.fit(x_thresh, y_train)
train_metrics = build_metrics(bagging, x_thresh, y_train)
x_thresh = threshold.transform(x_valid)
valid_metrics = build_metrics(bagging, x_thresh, y_valid)
return bagging, train_metrics, valid_metrics
def build_metrics(model, X, y):
probs = model.predict_proba(X)
preds = np.argmax(probs, axis=1)
metrics = dict(
probs=probs,
preds=preds,
loss=log_loss(y, probs),
accuracy=np.mean(preds == y))
return namedtuple('Predictions', metrics.keys())(**metrics)
第四行是創建一個SGD分類器的示例,其中有一對正則化參數和運用CPU訓練模型的權限。第十行創建了一組分類器,15—20行訓練了分類器,并計算了幾個表現標準。
SGD基準
現在有很多可用的預訓練深度學習結構,它們在我們的數據集上用作特征提取器時是否表現得同樣好?下面讓我們來看看。
我們選取了以下三種結構來訓練SGD分類器:
InceptionV3
InceptionResNetV2
Xception
Keras中都包含這三種架構,每個分類器在9200個樣本上進行訓練并在1022個圖像上進行驗證。下表展示了訓練和驗證自己的預測結果。
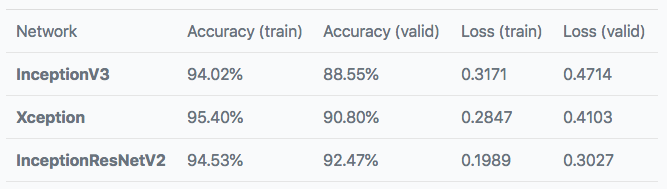
這個分數還不錯!對于如此簡單的實現過程,這個結果已經很令人滿意了。
對預訓練模型進行微調
在SGD分類器上對bottleneck特征的訓練已經表示,這些特征能達到良好的預測效果。然而,我們能夠通過重新訓練頂層、對模型進行微調來提高分類器的精度呢?同樣,我們能否通過對訓練集的預處理,讓模型在過擬合上更穩定,并且提高它的泛化能力?
微調的目的是讓預訓練模型適應數據。大多數情況下,重新使用的模型都會在含有不同種類的數據集上訓練。所以,你需要將網絡頂端的分類層替換掉。如圖所示:
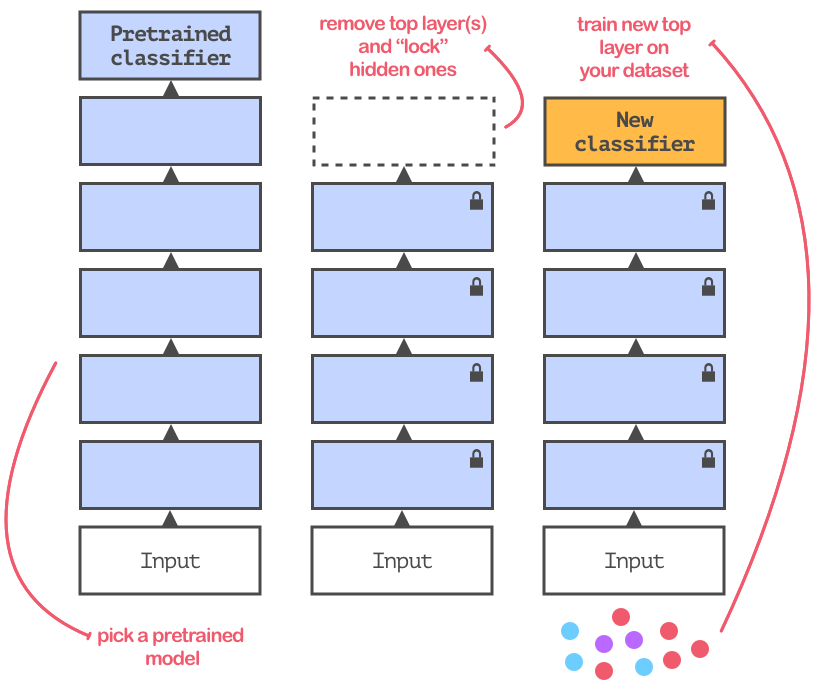
微調過程示意
新頂層的訓練過程和之前的并沒什么不同,我們只用了不同的分類器。但是,我們可以用數據增強的方式提高網絡的泛化能力。每個微調過的網絡都用稍微改動過的圖像訓練(例如稍微旋轉、縮放等)。
微調基準
為了測試微調后的精確度,我們將添加一個結構:
ResNet50
InceptionV3
Xception
InceptionResNetV2
每個模型進行100次迭代測試,每次有128個樣本:
from keras.optimizers import SGD
sgd = SGD(lr=0.001, momentum=0.99, nesterov=True)
下面是數據增強中參數的選擇:
from keras.preprocessing.image importImageDataGenerator
transformer = ImageDataGenerator(
width_shift_range=0.2,
height_shift_range=0.2,
zoom_range=0.2,
rotation_range=30,
vertical_flip=False,
horizontal_flip=True)
最后,模型訓練過程的實現:
from keras.models importModel
from keras.layers importDense
base = create_model(include_top=False)
x = Dense(120, activation='softmax')(x)
model = Model(inputs=base.inputs, outputs=x)
model.compile(optimizer=sgd, loss='categorical_crossentropy')
train_gen = create_training_generator()
valid_gen = create_validation_generator()
model.fit_generator(train_gen, validation_data=valid_gen)
下表是訓練后模型的表現:
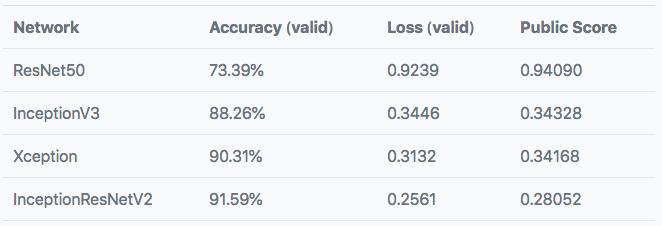
與之前的表現相比并沒有很大的提升,但是數據增強和預訓練InceptionResNetV2網絡頂部單一密集層的表現卻是最好的。
實際案例
讓我們看看模型在陌生圖像上的表現到底如何吧,下圖是數據集之外的網絡圖片,模型預測了五種最可能的狗狗品種:
模型對有些貓或狗的種類并不完全肯定,也就是說我們可以用它當做狗狗探測器。
結論
現成的模型在這個項目中的表現十分不錯,在狗狗分類數據集上訓練之后就能達到精確的結果。我相信如果再增加更多的頂層、“解鎖”更多隱藏層、加入正則化技術和更多優化,模型的表現會更好。
但是這一實驗的缺點是選擇的數據集是從ImageNet上挑選的狗類圖片,也就是說我們的網絡可能之前就見過它們了。關于這一問題論智君也曾報道過數據集的重復使用所帶來的副作用,可能會引起一些偏差。
-
人工智能
+關注
關注
1794文章
47622瀏覽量
239586 -
數據集
+關注
關注
4文章
1209瀏覽量
24789 -
深度學習
+關注
關注
73文章
5512瀏覽量
121404
原文標題:拉布拉多還是巴哥?用Keras輕松識別狗子的品種
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Kaggle機器學習/數據科學現狀調查

Hfut | 集電競賽
如何辨別各種類型的接口
用這個可以知道你的狗狗每天的活動
Kaggle沒有否認將被谷歌收購
如何很容易地將數據共享為Kaggle數據集

Kaggle創始人Goldbloom:我們是這樣做數據科學競賽的
騰訊宣布其人工智能球隊獲首屆谷歌足球Kaggle競賽冠軍
Kaggle神器LightGBM的最全解讀
如何從13個Kaggle比賽中挑選出的最好的Kaggle kernel
PyTorch教程-5.7. 在 Kaggle 上預測房價






 工商網監
工商網監
評論