") 如何賦予機器自主學(xué)習(xí)的能力,強化學(xué)習(xí)結(jié)構(gòu)與理論
如何賦予機器自主學(xué)習(xí)的能力,強化學(xué)習(xí)結(jié)構(gòu)與理論
如何賦予機器自主學(xué)習(xí)的能力,一直是人工智能領(lǐng)域的研究熱點。
強化學(xué)習(xí)與寬度學(xué)習(xí)
如何賦予機器自主學(xué)習(xí)的能力,一直是人工智能領(lǐng)域的研究熱點。在越來越多的復(fù)雜現(xiàn)實場景任務(wù)中,需要利用深度學(xué)習(xí)、寬度學(xué)習(xí)來自動學(xué)習(xí)大規(guī)模輸入數(shù)據(jù)的抽象表征,并以此表征為依據(jù)進行自我激勵的強化學(xué)習(xí),優(yōu)化解決問題的策略。深度與寬度強化學(xué)習(xí)技術(shù)在游戲、機器人控制、參數(shù)優(yōu)化、機器視覺等領(lǐng)域中的成功應(yīng)用,使其被認(rèn)為是邁向通用人工智能的重要途徑。
澳門大學(xué)講座教授,中國自動化學(xué)會副理事長陳俊龍在中國自動化學(xué)會第5期智能自動化學(xué)科前沿講習(xí)班作了題目為「從深度強化學(xué)習(xí)到寬度強化學(xué)習(xí):結(jié)構(gòu),算法,機遇及挑戰(zhàn)」的報告。
陳俊龍教授的報告大致可以分為三個部分。首先討論了強化學(xué)習(xí)的結(jié)構(gòu)及理論,包括馬爾科夫決策過程、強化學(xué)習(xí)的數(shù)學(xué)表達式、策略的構(gòu)建、估計及預(yù)測未來的回報。然后討論了如何用深度神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)來穩(wěn)定學(xué)習(xí)過程及特征提取、如何利用寬度學(xué)習(xí)結(jié)構(gòu)跟強化學(xué)習(xí)結(jié)合。最后討論了深度、寬度強化學(xué)習(xí)帶來的機遇與挑戰(zhàn)。
強化學(xué)習(xí)結(jié)構(gòu)與理論
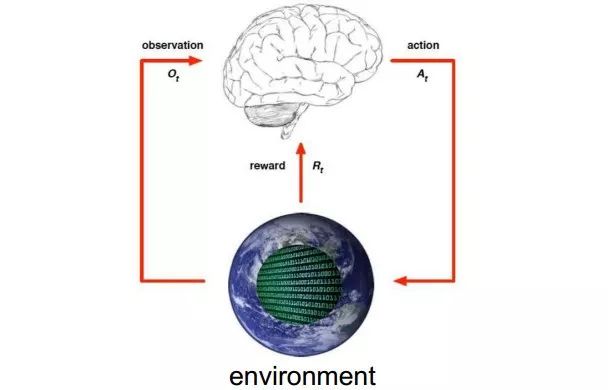
陳教授用下圖簡單描述強化學(xué)習(xí)過程。他介紹道所謂強化學(xué)習(xí)就是智能體在完成某項任務(wù)時,通過動作A與環(huán)境(environment)進行交互,在動作A和環(huán)境的作用下,智能體會產(chǎn)生新的狀態(tài),同時環(huán)境會給出一個立即回報。如此循環(huán)下去,經(jīng)過數(shù)次迭代學(xué)習(xí)后,智能體能最終地學(xué)到完成相應(yīng)任務(wù)的最優(yōu)動作。
提到強化學(xué)習(xí)就不得不提一下Q-Learning。接著他又用了一個例子來介紹了強化學(xué)習(xí)Q-Learning的原理。
Q-learning
假設(shè)一個樓層共有5個房間,房間之間通過一道門連接,如下圖所示。房間編號為0~4,樓層外的可以看作是一個大房間,編號5。
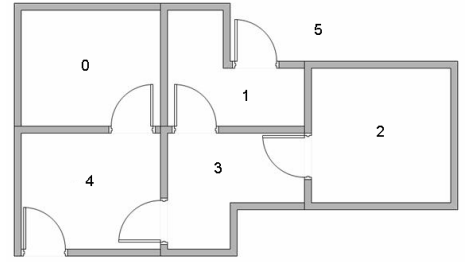
可以用圖來表示上述的房間,將每一個房間看作是一個節(jié)點,每道門看作是一條邊。
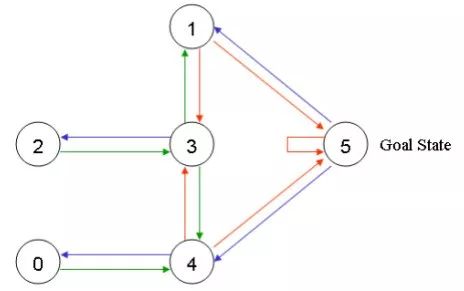
在任意一個房間里面放置一個智能體,并希望它能走出這棟樓,也可以理解為進入房間5。可以把進入房間5作為最后的目標(biāo),并為可以直接到達目標(biāo)房間的門賦予100的獎勵值,那些未與目標(biāo)房間相連的門則賦予獎勵值0。于是可以得到如下的圖。
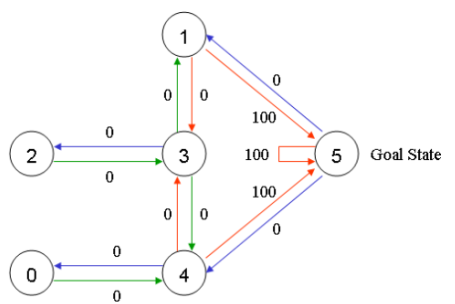
根據(jù)上圖可以得到獎勵表如下,其中-1代表著空值,表示節(jié)點之間無邊相連。
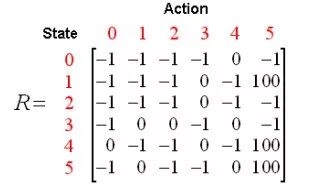
再添加一個類似的Q矩陣,代表智能體從經(jīng)驗中所學(xué)到的知識。矩陣的行代表智能體當(dāng)前的狀態(tài),列代表到達下一狀態(tài)的可能動作。

然后陳教授又介紹了Q-Learning的轉(zhuǎn)換規(guī)則,即Q(state, action)=R(state, action) + Gamma * Max(Q[next state, all actions])。
依據(jù)這個公式,矩陣Q中的一個元素值就等于矩陣R中相應(yīng)元素的值與學(xué)習(xí)變量Gamma乘以到達下一個狀態(tài)的所有可能動作的最大獎勵值的總和。
為了具體理解Q-Learning是怎樣工作的,陳教授還舉了少量的例子。
首先設(shè)置Gamma為0.8,初始狀態(tài)是房間1。
對狀態(tài)1來說,存在兩個可能的動作:到達狀態(tài)3,或者到達狀態(tài)5。通過隨機選擇,選擇到達狀態(tài)5。智能體到達了狀態(tài)5,將會發(fā)生什么?觀察R矩陣的第六行,有3個可能的動作,到達狀態(tài)1,4或者5。根據(jù)公式Q(1, 5) = R(1, 5) + 0.8 * Max[Q(5, 1), Q(5, 4), Q(5, 5)] = 100 + 0.8 * 0 = 100,由于矩陣Q此時依然被初始化為0,Q(5, 1), Q(5, 4), Q(5, 5) 全部是0,因此,Q(1, 5) 的結(jié)果是100,因為即時獎勵R(1,5) 等于100。下一個狀態(tài)5現(xiàn)在變成了當(dāng)前狀態(tài),因為狀態(tài)5是目標(biāo)狀態(tài),故算作完成了一次嘗試。智能體的大腦中現(xiàn)在包含了一個更新后的Q矩陣。

對于下一次訓(xùn)練,隨機選擇狀態(tài)3作為初始狀態(tài)。觀察R矩陣的第4行,有3個可能的動作,到達狀態(tài)1,2和4。隨機選擇到達狀態(tài)1作為當(dāng)前狀態(tài)的動作。現(xiàn)在,觀察矩陣R的第2行,具有2個可能的動作:到達狀態(tài)3或者狀態(tài)5。現(xiàn)在計算Q 值:Q(3, 1) = R(3, 1) + 0.8 * Max[Q(1, 2), Q(1, 5)] = 0 + 0.8 *Max(0, 100) = 80,使用上一次嘗試中更新的矩陣Q得到:Q(1, 3) = 0 以及 Q(1, 5) = 100。因此,計算的結(jié)果是Q(3,1)=80。現(xiàn)在,矩陣Q如下。

智能體通過多次經(jīng)歷學(xué)到更多的知識之后,Q矩陣中的值會達到收斂狀態(tài)。如下。

通過對Q中的所有的非零值縮小一定的百分比,可以對其進行標(biāo)準(zhǔn)化,結(jié)果如下。
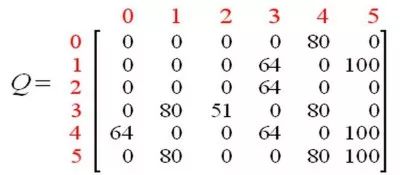
一旦矩陣Q接近收斂狀態(tài),我們就知道智能體已經(jīng)學(xué)習(xí)到了到達目標(biāo)狀態(tài)的最佳路徑。
至此陳教授已經(jīng)把Q-learning簡單介紹完了。通過上文的介紹大致可以總結(jié)出強化學(xué)習(xí)的六個特點:
無監(jiān)督,只有獎勵信號
不需要指導(dǎo)學(xué)習(xí)者
不停的試錯
獎勵可能延遲(犧牲短期收益換取更大的長期收益)
需要探索和開拓
目標(biāo)導(dǎo)向的智能體與不確定的環(huán)境間的交互是個全局性的問題
四個要素:
一、策略:做什么?
1)確定策略:a=π(s)
2)隨機策略:π(a|s)=p[at=a|st=s],st∈S,at∈A(St),∑π(a|s)=1
二、獎勵函數(shù):r(在狀態(tài)轉(zhuǎn)移的同時,環(huán)境會反饋給智能體一個獎勵)
三、累積獎勵函數(shù):V(一個策略的優(yōu)劣取決于長期執(zhí)行這一策略后的累積獎勵),常見的長期累積獎勵如下:
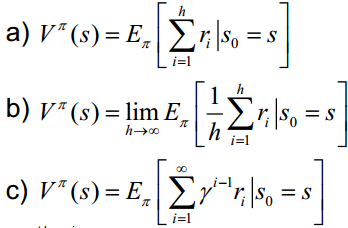
四、模型:用于表示智能體所處環(huán)境,是一個抽象概念,對于行動決策十分有用。
所有的強化學(xué)習(xí)任務(wù)都是馬爾科夫決策過程,陳教授對MDP的介紹如下。

一個馬爾可夫決策過程由一個五元組構(gòu)成M =(S,A,p,γ,r)。其中S是狀態(tài)集,A是動作集,p是狀態(tài)轉(zhuǎn)移概率,γ是折扣因子,r是獎勵函數(shù)。
陳教授在介紹強化學(xué)習(xí)這部分的最后提到了目前強化學(xué)習(xí)面臨的兩大挑戰(zhàn)。
信度分配:之前的動作會影響當(dāng)前的獎勵以及全局獎勵
探索開拓:使用已有策略還是開發(fā)新策略
Q-Learning可以解決信度分配的問題。第二個問題則可以使用ε-greedy算法,SoftMax算法,Bayes bandit算法,UCB算法來處理等。
值函數(shù)(對未來獎勵的一個預(yù)測)可分為狀態(tài)值函數(shù)和行為值函數(shù)。
1. 狀態(tài)值函數(shù)Vπ(s):從狀態(tài)s出發(fā),按照策略π采取行為得到的期望回報,
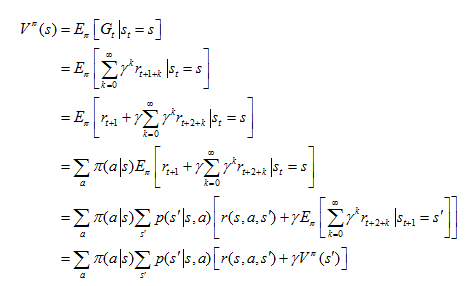
也被稱為Bellman方程。
2. 行為價值函數(shù)Qπ(s,a):從狀態(tài)s出發(fā)采取行為a后,然后按照策略π采取行動得到的期望回報,
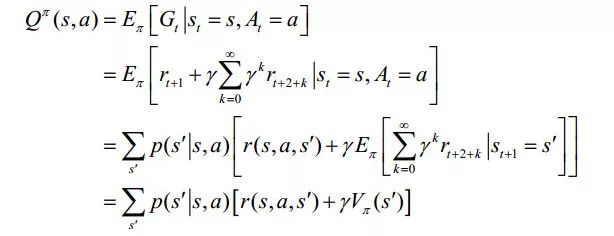
同樣被稱為動作‐值函數(shù)的Bellman方程。
類似的給出了相應(yīng)的最優(yōu)值函數(shù)為:
1. 最優(yōu)值函數(shù)V*(s)是所有策略上的最大值函數(shù):
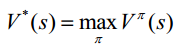
2. 最優(yōu)行為值函數(shù)Q*(s,a)是在所有策略上的最大行為值函數(shù):
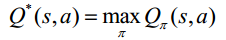
從而的到Bellman最優(yōu)方程:
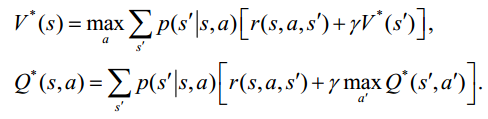
及對應(yīng)的最優(yōu)策略:
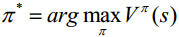
陳教授介紹了求解強化學(xué)習(xí)的方法,可分為如下兩種情況:
模型已知的方法:動態(tài)規(guī)劃模型未知的方法:蒙特卡洛方法,時間差分算法
陳教授進一步主要介紹了時間差分算法中兩種不同的方法: 異策略時間差分算法Q‐learning和同策略時間差分算法Sarsa, 兩者的主要區(qū)別在于at+1的選擇上的不同,
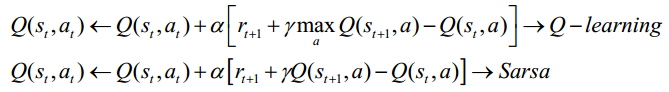
普通的Q‐learning是一種表格方法,適用于狀態(tài)空間和動作空間是離散且維數(shù)比較低的情況;當(dāng)狀態(tài)空間和動作空間是高維連續(xù)的或者出現(xiàn)一個從未出現(xiàn)過的狀態(tài),普通的Q‐learning是無法處理的。為了解決這個問題,陳教授進一步介紹了深度強化學(xué)習(xí)方法。
深度強化學(xué)習(xí)
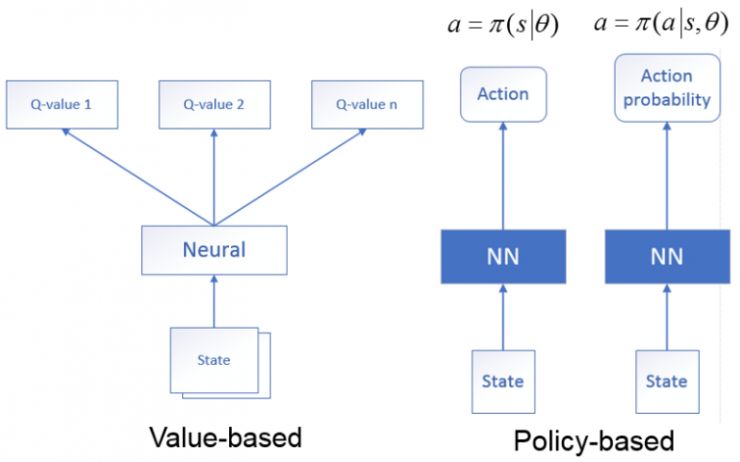
深度強化學(xué)習(xí)是深度神經(jīng)網(wǎng)絡(luò)與強化學(xué)習(xí)的結(jié)合方法, 利用深度神經(jīng)網(wǎng)絡(luò)逼近值函數(shù),利用強化學(xué)習(xí)的方法進行更新,根據(jù)解決問題思路的不同可分為:
1.基于價值網(wǎng)絡(luò):狀態(tài)作為神經(jīng)網(wǎng)絡(luò)的輸入,經(jīng)過神經(jīng)網(wǎng)絡(luò)分析后,輸出時當(dāng)前狀態(tài)可能執(zhí)行的所有動作的值函數(shù),即利用神經(jīng)網(wǎng)絡(luò)生成Q值。
2.基于策略網(wǎng)絡(luò):狀態(tài)作為神經(jīng)網(wǎng)絡(luò)的輸入,經(jīng)過神經(jīng)網(wǎng)絡(luò)分析后,輸出的是當(dāng)前狀態(tài)可能采取的動作(確定性策略),或者是可能采取的每個動作的概率(隨機性策略)。
陳教授也提到了Deepmind公司在2013年的Playing Atari with Deep Reinforcement Learning (DRL) 提出的DQN算法,Deep Q‐learning是利用深度神經(jīng)網(wǎng)絡(luò)端到端的擬合Q值,采用Q‐learning算法對值函數(shù)更新。DQN利用經(jīng)驗回放對強化學(xué)習(xí)過程進行訓(xùn)練,通過設(shè)置目標(biāo)網(wǎng)絡(luò)來單獨處理時間差分算法中的TD偏差。
基于上面內(nèi)容,陳教授進一步介紹了另外一種經(jīng)典的時間差分算法,即Actor-Critic的方法,該方法結(jié)合了值函數(shù)(比如Q learning)和策略搜索算法(Policy Gradients)的優(yōu)點,其中Actor指策略搜索算法,Critic指Qlearning或者其他的以值為基礎(chǔ)的學(xué)習(xí)方法,因為Critic是一個以值為基礎(chǔ)的學(xué)習(xí)法,所以可以進行單步更新,計算每一步的獎懲值,與傳統(tǒng)的PolicyGradients相比提高了學(xué)習(xí)效率,策略結(jié)構(gòu)Actor,主要用于選擇動作;而值函數(shù)結(jié)構(gòu)Critic主要是用于評價Actor的動作,agent根據(jù)Actor的策略來選擇動作,并將該動作作用于環(huán)境,Critic則根據(jù)環(huán)境給予的立即獎賞,根據(jù)該立即獎賞來更新值函數(shù),并同時計算值函數(shù)的時間差分誤差TD-error,通過將TDerror反饋給行動者actor,指導(dǎo)actor對策略進行更好的更新,從而使得較優(yōu)動作的選擇概率增加,而較差動作的選擇概率減小。
寬度學(xué)習(xí)
雖然深度結(jié)構(gòu)網(wǎng)絡(luò)非常強大,但大多數(shù)網(wǎng)絡(luò)都被極度耗時的訓(xùn)練過程所困擾。首先深度網(wǎng)絡(luò)的結(jié)構(gòu)復(fù)雜并且涉及到大量的超參數(shù)。另外,這種復(fù)雜性使得在理論上分析深層結(jié)構(gòu)變得極其困難。另一方面,為了在應(yīng)用中獲得更高的精度,深度模型不得不持續(xù)地增加網(wǎng)絡(luò)層數(shù)或者調(diào)整參數(shù)個數(shù)。因此,為了提高訓(xùn)練速度,寬度學(xué)習(xí)系統(tǒng)提供了一種深度學(xué)習(xí)網(wǎng)絡(luò)的替代方法,同時,如果網(wǎng)絡(luò)需要擴展,模型可以通過增量學(xué)習(xí)高效重建。陳教授還強調(diào),在提高準(zhǔn)確率方面,寬度學(xué)習(xí)是增加節(jié)點而不是增加層數(shù)。基于強化學(xué)習(xí)的高效性,陳教授指出可以將寬度學(xué)習(xí)與強化學(xué)習(xí)結(jié)合產(chǎn)生寬度強化學(xué)習(xí)方法,同樣也可以嘗試應(yīng)用于文本生成、機械臂抓取、軌跡跟蹤控制等領(lǐng)域。
報告的最后陳教授在強化學(xué)習(xí)未來會面臨的挑戰(zhàn)中提到了如下幾點:
安全有效的探索
過擬合問題
多任務(wù)學(xué)習(xí)問題
獎勵函數(shù)的選擇問題
不穩(wěn)定性問題
-
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5512瀏覽量
121415 -
強化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
268瀏覽量
11283
原文標(biāo)題:陳俊龍:從深度強化學(xué)習(xí)到寬度強化學(xué)習(xí)—結(jié)構(gòu),算法,機遇及挑戰(zhàn)
文章出處:【微信號:AItists,微信公眾號:人工智能學(xué)家】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
深度強化學(xué)習(xí)實戰(zhàn)
將深度學(xué)習(xí)和強化學(xué)習(xí)相結(jié)合的深度強化學(xué)習(xí)DRL
基于LCS和LS-SVM的多機器人強化學(xué)習(xí)
人工智能機器學(xué)習(xí)之強化學(xué)習(xí)
什么是強化學(xué)習(xí)?純強化學(xué)習(xí)有意義嗎?強化學(xué)習(xí)有什么的致命缺陷?

深度強化學(xué)習(xí)你知道是什么嗎
一文詳談機器學(xué)習(xí)的強化學(xué)習(xí)
83篇文獻、萬字總結(jié)強化學(xué)習(xí)之路
機器學(xué)習(xí)中的無模型強化學(xué)習(xí)算法及研究綜述

《自動化學(xué)報》—多Agent深度強化學(xué)習(xí)綜述

徹底改變算法交易:強化學(xué)習(xí)的力量
強化學(xué)習(xí)的基礎(chǔ)知識和6種基本算法解釋

什么是強化學(xué)習(xí)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論