 利用深度學習模型實現監督式語義分割
利用深度學習模型實現監督式語義分割
語義分割是計算機視覺中的任務,語義分割讓我們對圖像的理解比圖像分類和目標物體檢測更詳細。這種對細節的理解在很多領域都非常重要,包括自動駕駛、機器人和圖片搜索引擎。來自斯坦福大學的Andy Chen和Chaitanya Asawa為我們詳細介紹了進行精確語義分割都需要哪些條件。本文將重點講解利用深度學習模型實現監督式語義分割。
人類如何描述一個場景?我們可能會說“窗戶下面有一張桌子”或者“沙發右邊有一盞臺燈”。將場景分割成獨立的實體是理解一張圖像的關鍵,它讓我們了解目標物體的行為。
當然,目標檢測方法可以幫我們在特定實體周圍畫出邊界框。但是要想像人類一樣對場景有所了解還需要對每個實體的邊界框進行監測和標記,并精確到像素級。這項任務變得越來越重要,因為我們開始創建自動駕駛汽車和智能機器人,它們都需要對周圍環境有著精確的理解。來自斯坦福大學的Andy Chen和Chaitanya Asawa就為我們詳細介紹了進行精確語義分割都需要哪些條件。以下是論智的編譯。
什么是語義分割
語義分割是計算機視覺中的任務,在這一過程中,我們將視覺輸入中的不同部分按照語義分到不同類別中。通過“語義理解”,各類別有一定的現實意義。例如,我們可能想提取圖中所有關于“汽車”的像素,然后把顏色涂成藍色。
雖然例如聚類等無監督的方法可以用于分割,但是這樣的結果并不是按照語義分類的。這些方法并非按照訓練方法進行分割,而是按照更通用的方法。
語義分割讓我們對圖像的理解比圖像分類和目標物體檢測更詳細。這種對細節的理解在很多領域都非常重要,包括自動駕駛、機器人和圖片搜索引擎。這篇文章將重點講解利用深度學習模型實現監督式語義分割。
數據集和標準
經常用于訓練語義分割模型的數據集有:
Pascal VOC 2012:其中有20個類別,包括人物、交通工具等等。目的是為了分割目標物體類別或背景。
Cityscapes:從50個城市收集的景觀數據集。
Pascal Context:有超過400種室內和室外場景。
Stanford Background Dataset:該數據集全部由室外場景組成,但每張圖片都有至少一個前景。

用來評估語義分割算法性能的標準是平均IoU(Intersection Over Union),這里IoU被定義為:
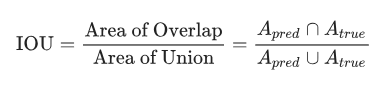
這一標準能保證我們不僅能捕捉到每個目標對象,還能非常精確地完成這一任務。
語義分割過程(Pipeline)
在高級過程中,通常應用語義分割模型的過程如下:
輸入→分類器→后處理→最終結果
之后我們將詳細討論分類器和后處理的過程。
結構和分割方法
用卷積神經網絡進行分類
最近進行語義分割的結構大多用的是卷積神經網絡(CNN),它首先會給每個像素分配最初的類別標簽。卷積層可以有效地捕捉圖像的局部特征,同時將這樣的圖層分層嵌入,CNN嘗試提取更寬廣的結構。隨著越來越多的卷積層捕捉到越來越復雜的圖像特征,一個卷積神經網絡可以將圖像中的內容編碼成緊湊的表示。
但是想要將單獨的像素映射到標簽,我們需要在一個編碼-解碼器設置中增強標準的CNN編碼器。在這個設置中,編碼器用卷積層和池化層減少圖像的寬度和高度,達到一個更低維的表示。之后將其輸入到解碼器中,通過上采樣“恢復”空間維度,在每個解碼器的步驟上擴大表示的尺寸。在一些情況中,編碼器中間的步驟是用來幫助解碼器的步驟的。最終,解碼器生成了一群表示原始圖像的標簽。

SCNet的編碼-解碼設置
在許多語義分割結構中,CNN想要最小化的損失函數是交叉熵損失。這一目標函數測量每個像素的預測概率分布與它實際概率分布的距離。
然而,交叉熵損失對語義分割并不理想,因為一張圖像的最終損失僅僅是每個像素損失的總和,而交叉熵損失不是并行的。由于交叉熵損失無法在像素間添加更高級的架構,所以最小化交叉熵的標簽會經常變得不完整或者失真,這時候就需要后處理了。
用條件隨機場進行改進
CNN中的原始標簽經常是經過補綴的圖像,其中可能有一些地方是錯誤的標簽,與周圍的像素標簽不一致。為了解決這一不連貫的問題,我們可以應用一種令其變光滑的技術。我們想保證目標物體所在圖像區域是連貫的,同時任何像素都與其周圍有著相同的標簽。
為了解決這一問題,一些架構用到了條件隨機場(CRFs),它利用原始圖像中像素的相似性調整CNN的標簽。
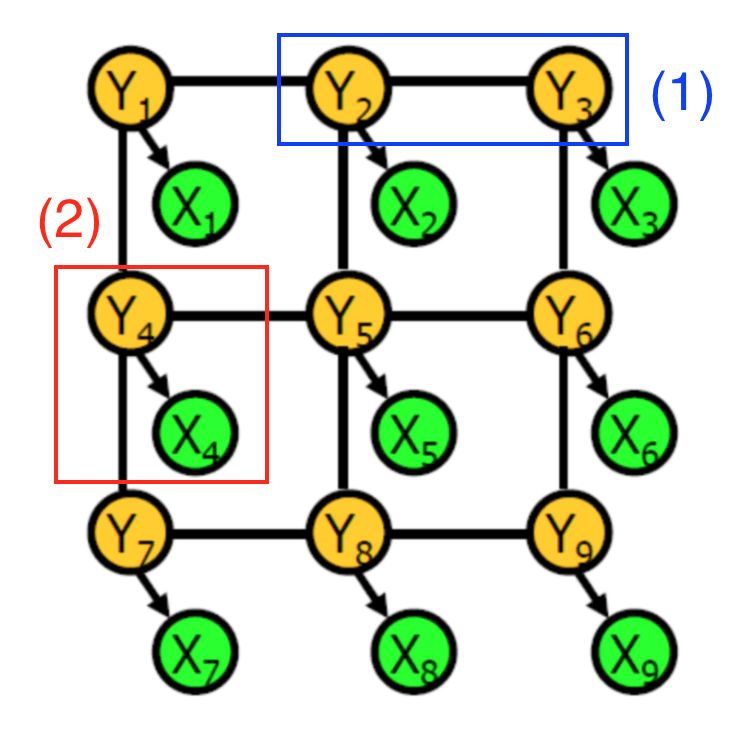
條件隨機場的示例
一個條件隨機場是由隨機變量組成的圖形。在這一語境中,每個節點代表:
特定像素的CNN標簽(綠色)
特定像素的實際物體標簽(黃色)
每個連接線中編碼了兩個類型的信息:
藍色:兩像素中實際標簽之間的相關性
紅色:CNN原始預測和給定像素的實際標簽之間的依賴關系
每種依賴關系都與潛力有關,它是由兩個相關隨機變量表示的函數。例如,當相鄰像素的實際標簽相同時,第一種依賴關系的可能性更高。更直接地說,對象標簽起到隱藏變量的作用,可以根據某些概率分布生成可觀察的CNN像素標簽。
要用CRF調整標簽,我們首先用訓練數據學習圖像模型的參數。然后,我們再調整參數使概率最大化。CRF推斷的輸出就是原始圖像像素的最終目標標簽。
在實際中,CRF圖形是完全連接的,這意味著即使與節點相對的像素距離很遠,仍然可以在一條連接線上。這樣的圖形有幾十億條連接線,在計算實際的推斷時非常耗費計算力。CRF架構將用高效的估算技術進行推斷。
分類器結構
CNN分類之后的CRF調整只是語義分割過程的一個示例。許多研究論文都討論過這一過程的變體:
U-Net通過生成原始訓練數據的變形版本增強其訓練數據。這一步驟讓CNN的編碼-解碼器在應對這樣的變形時更加穩定,同時能在更少的訓練圖像中學習。當在一個不到40張的醫學圖像集中訓練時,模型的IoU分數依然達到了92%。
DeepLab結合了CNN編碼-解碼器和CRF調整,生成了它的對象標簽(作者強調了解碼過程中的上采樣)。空洞卷積使用每層不同尺寸的過濾器,讓每個圖層捕捉到不同規模大小的特征。在Pascal VOC 2012測試集上,這一結構的平均IoU分數為70.3%。
Dilation10是空洞卷積的替代方法。在Pascal VOC 2012測試集上,它的平均IoU分數為75.3%。
其他訓練過程
現在我們關注一下最近的訓練案例,與含有各種元素、優化不同的是,這些方法都是端到端的。
完全差分條件隨機場
Zheng等人提出的CRF-RNN模型介紹了一種將分類和后處理結合到一種端到端模型的方法,同時優化兩個階段。因此,例如CRF高斯核的權重參數就可以自動學習。它們浮現了推理近似算法作為卷積而達到這一目的,同時使用循環神經網絡模擬推理算法的完全迭代本性。
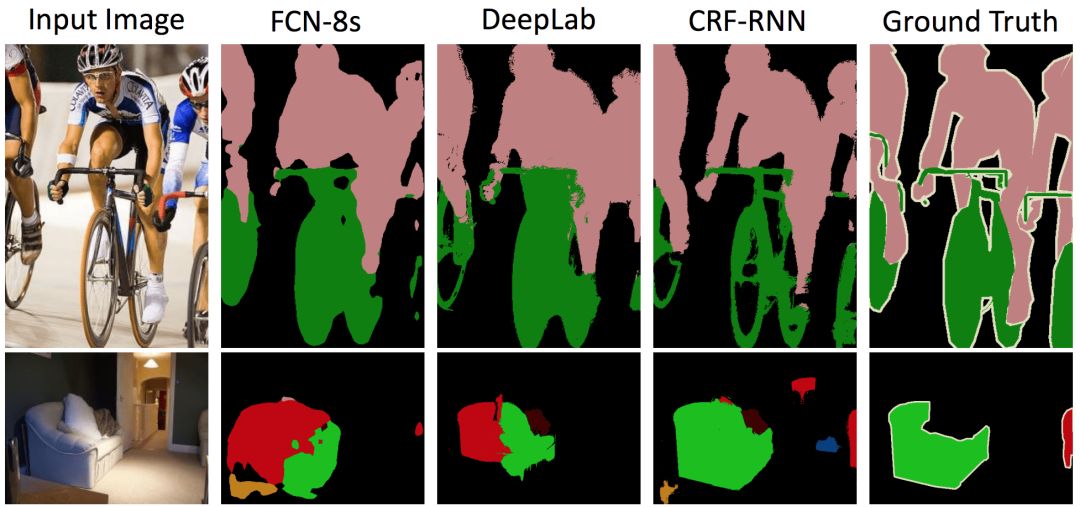
分別用FCN-8s、DeepLab和CRF-RNN生成的兩張圖片的分割
對抗訓練
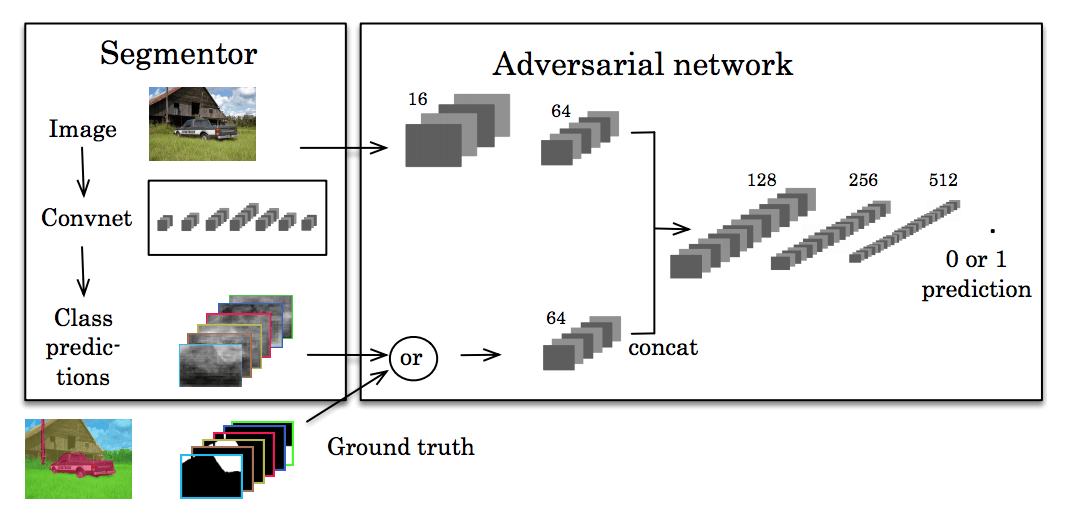
最近,還有人研究了利用對抗訓練幫助開發更高程度的一致性。受到生成對抗網絡的啟發,Luc等人訓練了一個標準的CNN用來做語義分割,同時還有一個對抗網絡,試著學習標準分割與預測分割之間的區別。分割網絡的目的是生成對抗網絡無法分辨的語義分割。
這里的中心思想是,我們想讓我們的分割看起來盡可能真實。如果其他網絡可以輕易識破,那么我們做出的分割預測就不夠好。
隨時間進行分割
我們如何預測目標物體在未來會如何呢?我們可以對某一場景中的分割動作建模。這可以應用到機器人或自動交通工具中,這些產品需要對物體的移動進行建模,從而做計劃。
Luc等人在2017年討論了這一問題,在論文中他們表示直接預測未來的語義分割會生成比預測未來框架然后再分割更好的性能。
他們用了自動回歸模型,用過去的分割預測下一個分割,以此類推。
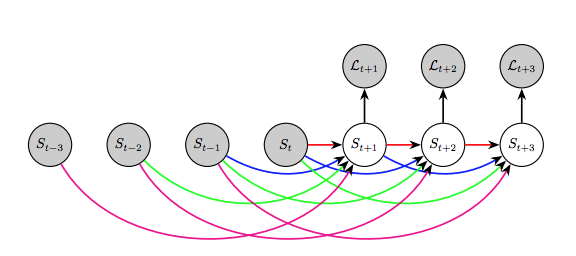
最終發現這種方法長期的性能不太好,中短期來看效果不錯。
結語
在這之中的很多方法,例如U-Net,都遵循了一個基礎結構:我們引用深度學習(或卷積網絡),之后用傳統概率的方法進行后處理。雖然卷積網絡的原始輸出不太完美,后處理能將分割的標簽調整到接近人類的水平。
其他方法,例如對抗學習,可以看作是分割的強大端到端解決方案。與之前的CRF步驟不同,端到端技術無需人類建模調整原始預測。由于這些技術目前的性能比多步驟的方案都好,未來將有更多關于端到端算法的研究。
-
編碼器
+關注
關注
45文章
3664瀏覽量
135072 -
神經網絡
+關注
關注
42文章
4779瀏覽量
101049 -
深度學習
+關注
關注
73文章
5512瀏覽量
121413
原文標題:細說語義分割,不只是畫個邊框那么簡單
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
van-自然和醫學圖像的深度語義分割:網絡結構
van-自然和醫學圖像的深度語義分割:網絡結構
基于深度學習的多尺幅深度網絡監督模型


結合雙目圖像的深度信息跨層次特征的語義分割模型

基于深度學習的三維點云語義分割研究分析


基于SEGNET模型的圖像語義分割方法
模型在學習可轉移的語義分割表示方面的有效性
CVPR 2023 | 華科&MSRA新作:基于CLIP的輕量級開放詞匯語義分割架構







 工商網監
工商網監
評論