

基于3DGS和NeRF的三維重建技術(shù)在過去的一年中取得了快速的進步,動態(tài)模型也變得越來越普遍,然而這些模型僅限于處理原始軌跡域內(nèi)的對象。
HRMAD作為一種混合方案,將傳統(tǒng)的基于網(wǎng)格的動態(tài)三維神經(jīng)重建和物理渲染優(yōu)勢結(jié)合,支持在任意位置部署網(wǎng)格動態(tài)代理,自由調(diào)整環(huán)境條件,在多個相機視角下進行自由切換,與傳統(tǒng)仿真方法相比有效減少了領(lǐng)域差距,同時保留了可控性。
一、方法描述
HRMAD提出的NeRF2GS雙模型訓(xùn)練范式顯著提升了合成質(zhì)量,尤其是道路和車道標志,同時滿足交互式幀率。通過此塊級并行訓(xùn)練架構(gòu),可以處理超過10萬平方米場景重建,并同步傳輸出分割掩膜/法線圖/深度圖。通過物理光柵化/光線追蹤渲染后端,HRMAD支持多個相機模型、LiDAR和Radar的實時多模態(tài)輸出。如圖1所示的模型架構(gòu)。
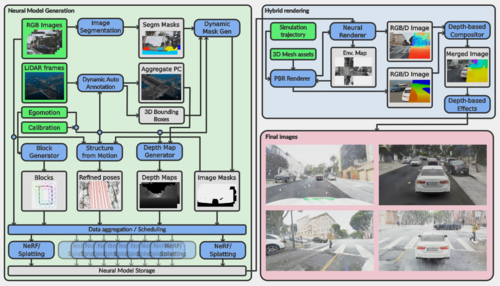
圖1
具體而言,HRMAD基于RGB相機、GNSS和LiDAR的同步數(shù)據(jù)進行模型訓(xùn)練。該方案結(jié)合了NeRF優(yōu)秀的泛化能力和3DGS實時的渲染速度,通過T-S結(jié)構(gòu),將NeRF生成的深度、法線和外觀監(jiān)督信息傳遞給3DGS模型,并通過正則化將LiDAR深度數(shù)據(jù)引入NeRF,從而實現(xiàn)更準確的幾何結(jié)構(gòu)建模。
傳統(tǒng)基于透視投影的渲染方法通常依賴于特定的投影模型,為了在3DGS場景中適配任意傳感器,HRMAD提出了一種新的渲染算法架構(gòu),如下圖2所示。
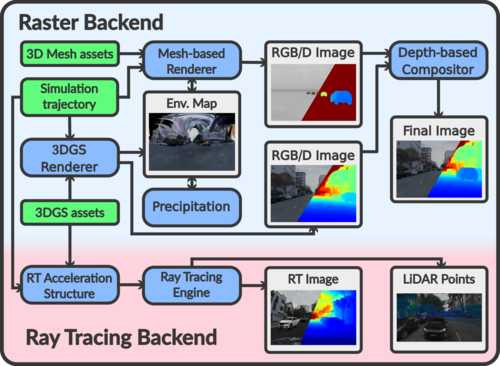
圖2
該架構(gòu)基于共享代碼庫實現(xiàn)了光柵化和光線追蹤渲染,用于計算高斯沿射線的貢獻。這樣不僅能夠在三維重建場景中支持任意相機畸變模型,還能夠減輕LiDAR仿真中偽影的產(chǎn)生。圖3展示了在aiSim中采用HRMAD渲染場景并配置LiDAR后,點云的可視化效果。

圖3
圖4表明HRMAD在極端視角下RGB、深度、法線和分割(基于Mask2Former)模態(tài)下的幾何細節(jié)和表面特性,重建面積約為165000平方米(ZalaZone測試場,此重建場景將于aiSim5.7版本進行發(fā)布)。

圖4
二、下游任務(wù)驗證
1、重建質(zhì)量驗證
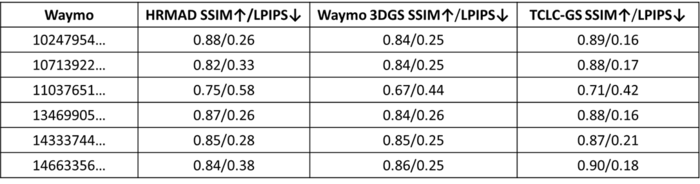
由于HRMAD采用的是基于雙邊網(wǎng)格的色彩校正方法,傳統(tǒng)的PSNR指標不再適用,而SSIM和LPIPS指標對結(jié)果相似性更為敏感,但從結(jié)果上看,這兩個指標仍然受到ISP解耦導(dǎo)致的RAW與重建圖像之間色彩失配的影響。這一影響體現(xiàn)在了評估結(jié)果中,如表1,表中對比了原始3DGS和TCLC-GS在6個Waymo場景上的指標表現(xiàn)。
表1
2、語義分割驗證
在語義分割上分別從三個角度評估模型性能,首先通過統(tǒng)計所有像素中語義分類一致的比例,反映全局重建一致性。
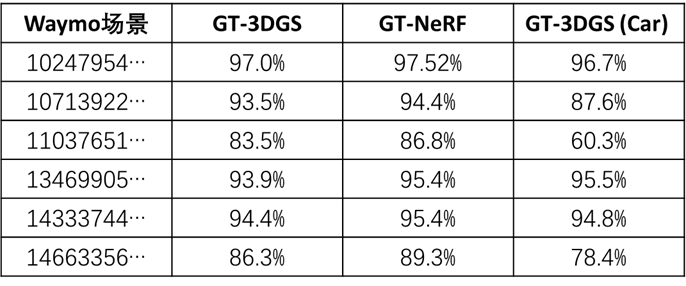
通過Mask2Former獲取真實圖像上計算的分割Mask,并與HRMAD-NeRF(Teacher)和HRMAD-NeRF(Student)渲染得到的分割Mask進行比較,驗證重建的準確性。同時為了降低道路、天空等易分割區(qū)域?qū)φw結(jié)果的偏差影響,針對"Car"進行單獨IoU計算。
為確保驗證過程的公平性,真實圖像被重投影至與渲染過程一致的無畸變針孔相機參數(shù)空間,當重建結(jié)果正確標注了遠距離或被遮擋物體,而Mask2Former因輸入信息有限導(dǎo)致誤判時,此類誤差會被計入評估指標。同時在夜間拍攝場景和相機直對太陽的場景中(如場景11037651和14663356),掩膜一致性顯著下降。結(jié)果如表2所示。
表2
其次在非常規(guī)視角下進行模型渲染,并基于Mask2former生成的Mask與模型預(yù)測Mask進行比較。此渲染視角沿自車軌跡生成,并在[-1,3]米范圍內(nèi)平移前視相機仿真模型。表3展示了針對道路表面信息和車輛的重建性能。其中Car類型的重建性能相對較低,這是由于Mask2Frame無法檢測遠處或被遮擋的物體,從而擴大了差異。圖5顯了示相關(guān)結(jié)果,綠色為匹配區(qū)域,藍色和橙色分別表示模型預(yù)測Mask和Mask2Former的Mask輸出。
表3
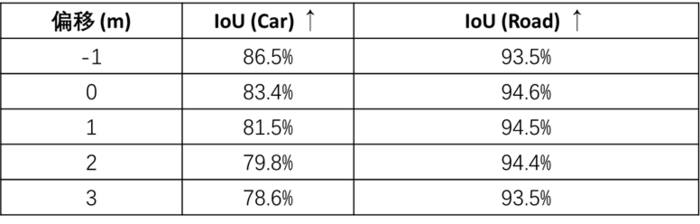

圖5
最后在極端渲染視角下(高5m,橫向偏移2m,向下偏轉(zhuǎn)25°),針對車道線和路沿語義分割結(jié)果進行了定性評估,如圖6所示。

圖6
3、3D目標檢測驗證
為了驗證HRMAD在3D目標檢測上的一致性,采用在Waymo Open數(shù)據(jù)集訓(xùn)練中公開的DEVIANT 3D目標檢測模型,進行定量和定性實驗。
定量實驗中,在Waymo-13469905891836363794片段中從[0,3]橫向偏移視角下進行驗證,并通過平移變換后的3DBBox定量計算。定性實驗選取三個駕駛片段進行靜態(tài)環(huán)境渲染,并基于網(wǎng)格渲染添加動態(tài)車輛,主要用于評估仿真生成的車輛是否引入了領(lǐng)域差距。
表4基于Waymo指標進行驗證,Original為原始圖像。特別在近距離下,HRMAD的表現(xiàn)性能要優(yōu)于原始圖像,這是由于原始圖像中假陽FP數(shù)量更高。在非常規(guī)視角渲染下,觀察到的差異主要是橫向偏移視角下目標截斷的數(shù)量增加,但整體檢測結(jié)果在很大程度上保持一致。
表4
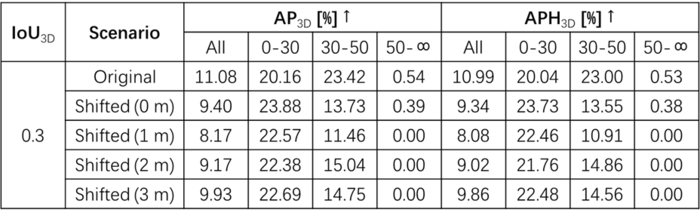
圖7為DEVIANT模型在HRMAD渲染W(wǎng)aymo場景中的表現(xiàn)。

圖7
三、結(jié)語
雖然HRMAD渲染方法旨在最大程度減少區(qū)塊邊界的不連續(xù)性,但仍不可避免地會產(chǎn)生可見的偽影,特別是在天空和遠距離目標區(qū)域中。比如天空的RGB重建效果良好,但在自動駕駛仿真測試場景中,在非常規(guī)視角下仍然會導(dǎo)致偽影和結(jié)構(gòu)痕跡。
在下游任務(wù)中,HRMAD針對自動駕駛場景的評估結(jié)果已非常接近真實數(shù)據(jù),但由于樣本有限,仍需要更大規(guī)模的數(shù)據(jù)集進行進一步驗證。未來的研究也會致力于進一步縮小重建場景和真實數(shù)據(jù)之間的領(lǐng)域差距,具體來說,可以通過探索層次化高斯?jié)姙R來減少區(qū)塊偽影,并利用生成的法線信息改進LiDAR強度模擬,來更好地反應(yīng)點云數(shù)據(jù)的方向敏感強度。
目前,HRMAD生成場景已集成在aiSim中,可在不同傳感器模型配置方案下,實現(xiàn)端到端仿真測試交互式驗證和測試。
-
端到端測試
+關(guān)注
關(guān)注
0文章
4瀏覽量
5767 -
算法
+關(guān)注
關(guān)注
23文章
4657瀏覽量
93950 -
仿真
+關(guān)注
關(guān)注
50文章
4179瀏覽量
134724 -
渲染
+關(guān)注
關(guān)注
0文章
74瀏覽量
11039 -
場景
+關(guān)注
關(guān)注
1文章
9瀏覽量
7698
發(fā)布評論請先 登錄
相關(guān)推薦
未來已來,多傳感器融合感知是自動駕駛破局的關(guān)鍵
自動駕駛的到來
即插即用的自動駕駛LiDAR感知算法盒子 RS-Box
如何讓自動駕駛更加安全?
網(wǎng)聯(lián)化自動駕駛的含義及發(fā)展方向
自動駕駛技術(shù)的實現(xiàn)
實現(xiàn)自動駕駛,唯有端到端?

Mobileye端到端自動駕駛解決方案的深度解析

Waymo利用谷歌Gemini大模型,研發(fā)端到端自動駕駛系統(tǒng)
連接視覺語言大模型與端到端自動駕駛

端到端自動駕駛技術(shù)研究與分析
康謀分享 | 3DGS:革新自動駕駛仿真場景重建的關(guān)鍵技術(shù)

DiffusionDrive首次在端到端自動駕駛中引入擴散模型

動量感知規(guī)劃的端到端自動駕駛框架MomAD解析
端到端自動駕駛多模態(tài)軌跡生成方法GoalFlow解析





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論