

來源:Juicedata
近期,DeepSeek 開源了其文件系統 Fire-Flyer File System (3FS),使得文件系統這一有著 70 多年歷時的“古老”的技術,又獲得了各方的關注。在 AI 業務中,企業需要處理大量的文本、圖像、視頻等非結構化數據,還需要應對數據量的爆炸式增長,分布式文件系統因此成為 AI 訓練的關鍵存儲技術。
本文旨在通過深入分析 3FS 的實現機制,并與 JuiceFS 進行對比,以幫助用戶理解兩種文件系統的區別及其適用場景。同時,我們將探討 3FS 中的值得借鑒的創新技術點。
01 架構對比
3FS
3FS[1](Fire-Flyer File System) 是一款高性能的分布式文件系統,專為解決 AI 訓練和推理工作負載而設計,該系統使用高性能的 NVMe 和 RDMA 網絡提供共享存儲層。3FS 由 DeepSeek 在 2025 年 2 月開源。
3FS 主要包括以下模塊:
? 集群管理服務(Cluster Manager)
? 元數據服務(Metadata Service)
? 存儲服務(Storage Service)
? 客戶端 (FUSE Client、Native Client)
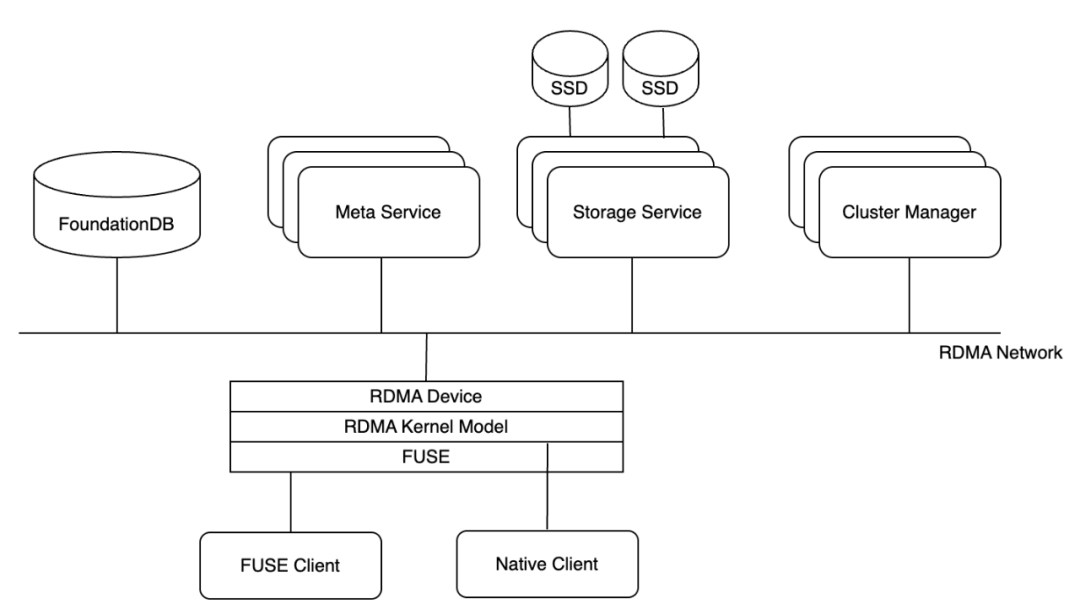
3FS 架構
所有模塊通過 RDMA 網絡通信。元數據服務和存儲服務向集群管理服務發送心跳信號。集群管理服務負責處理成員變更,并將集群配置分發給其他服務和客戶端。為了提高系統的可靠性和避免單點故障,會部署多個集群管理服務,其中一個被選為主節點。當主節點發生故障時,另一個管理器會被提升為主節點。集群配置通常存儲在可靠的分布式服務中,例如 ZooKeeper 或 etcd。
當進行文件元數據操作(例如打開或創建文件/目錄),請求被發送到元數據服務,以實現文件系統語義。元數據服務有多個,并且是無狀態的,它們不直接存儲文件元數據,而是依賴支持事務的鍵值數據庫 FoundationDB 來存儲這些數據。因此,客戶端可以靈活地連接到任意元數據服務。這種設計使得元數據服務可以在沒有狀態信息的情況下獨立運作,進而增強了系統的可伸縮性和可靠性。
每個存儲服務管理若干本地 SSD,并提供 chunk 存儲接口。存儲服務采用 CRAQ ( Chain Replication with Apportioned Queries)來確保強一致性。3FS 中存儲的文件被拆分為默認 512K 大小相等的塊,并在多個 SSD 上進行復制,從而提高數據的可靠性和訪問速度。
3FS 客戶端提供兩種接入方式:FUSE Client 和 Native Client。FUSE Client 提供常見 POSIX 接口的支持,簡單易用。Native Client 提供更高的性能,但是用戶需要調用客戶端 API ,具有一定的侵入性,下文我們還將對此作更詳盡的解析。
JuiceFS
JuiceFS 是一個云原生分布式文件系統,其數據存儲在對象存儲中。社區版[2]可與多種元數據服務集成,適用場景廣泛,于 2021 年在 GitHub 開源。企業版專為高性能場景設計,廣泛應用于大規模 AI 任務,涵蓋生成式 AI、自動駕駛、量化金融和生物科技等。
JuiceFS 文件系統包括三部分組成:
? 元數據引擎:用于存儲文件元數據,包括常規文件系統的元數據和文件數據的索引。
? 數據存儲:一般是對象存儲服務,可以是公有云的對象存儲也可以是私有部署的對象存儲服務。
? JuiceFS 客戶端:提供 POSIX(FUSE)、Hadoop SDK、CSI Driver、S3 網關等不同的接入方式。
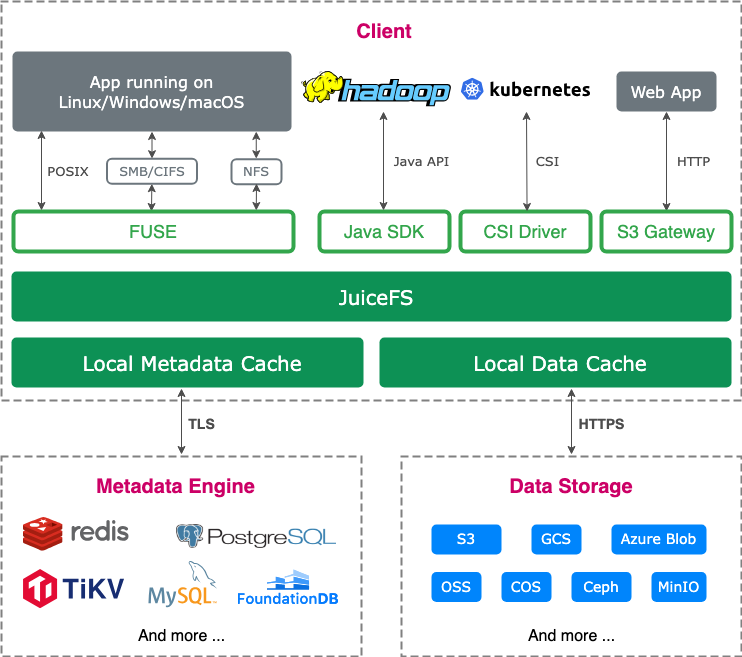
JuiceFS 社區版架構圖
架構差異
從模塊劃分上看兩個文件系統差異不大,都采用了元數據與數據分離的設計,各個模塊功能也較類似。不同于 3FS 和 JuiceFS 企業版,JuiceFS 社區版兼容多種開源數據庫存儲元數據,對元數據的操作都封裝在客戶端,用戶不需要再單獨運維一個無狀態的元數據服務。
存儲模塊
3FS 使用大量本地 SSD 進行數據存儲,為了保證數據存儲的一致性,3FS 使用 CRAQ 這一簡潔的數據一致性算法 。幾個副本被組成一個 Chain,寫請求從 Chain 的 Head 開始,一直到達 Chain 的 Tail 時返回寫成功應答。讀請求可以發送到 Chain 的所有副本,如果讀到臟節點的數據,該節點會聯系 Tail 節點檢查狀態。如下圖所示。
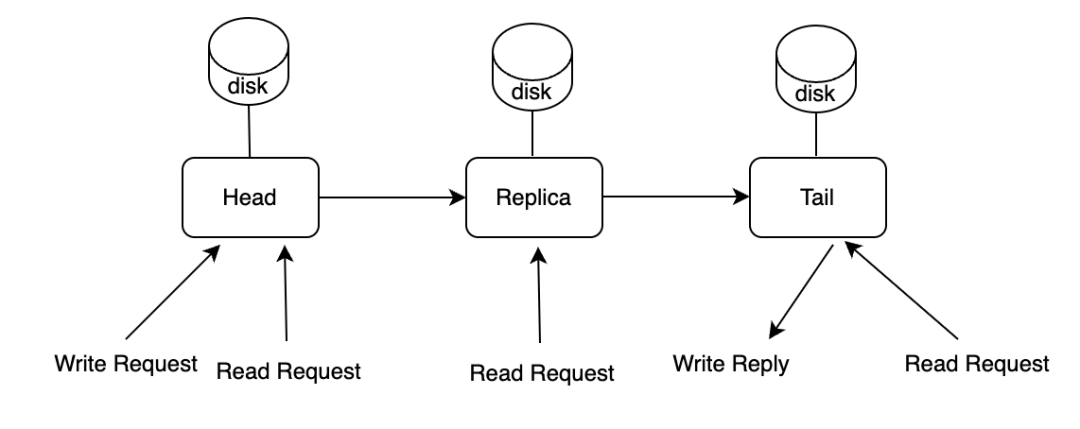
CRAQ 一致性算法
數據的寫入是按順序逐節點傳遞,因此會帶來比較高的延時。如果 Chain 當中的某個副本不可用, 3FS 會把這個副本移到 Chain 的末尾,等副本可用的時候再做恢復。恢復的時候需要把整個 Chunk 的內容復制到這個副本,而非使用不可用期間的增量數據。如果要做到同步寫所有副本和增量恢復數據,那寫的邏輯會復雜非常多,比如 Ceph 使用 pg log 保證數據一致性。盡管 3FS 這種設計會導致寫延遲,但是對于以讀為主的 AI 應用場景,影響不大。
JuiceFS 利用對象存儲作為數據存儲解決方案,從而可享有對象存儲帶來的若干優勢,如數據可靠性、一致性等。存儲模塊提供了一組用于對象操作的接口,包括 GET/PUT/HEAD/LIST 等,用戶可以根據自己的需求對接具體的存儲系統。比如不同云廠商的對象存儲,也可以選擇私有部署的對象存儲比如 MinIO、Ceph RADOS 等系統。社區版 JuiceFS 提供本地緩存來應對 AI 場景下的帶寬需求,JuiceFS 企業版使用分布式緩存滿足更大的聚合讀帶寬的需求。
元數據模塊
在 3FS 中,文件的屬性以 KV 的形式存儲在元數據服務中。該服務是一個無狀態的高可用服務,依靠 FoundationDB 做支撐。FoundationDB 是 Apple 開源的優秀分布式 KV 數據庫,具有很高的穩定性。FoundationDB 所有鍵值使用 Key 做全局排序,然后均勻拆分到不同的節點上。
為了優化 list 目錄的效率,3FS 使用字符 “DENT” 前綴加父目錄 inode 號和名字作為 dentry 的 Key。Inode 的 Key 是通過將 "INOD" 前綴與 inode ID 連接而構造的,其中 inode ID 采用小端字節序編碼,以便將 inodes 分布到多個 FoundationDB 節點上。這個設計與 JuiceFS 使用的TKV(Transactional Key-Value Database)[3]進行元數據服務的存儲方式類似。
JuiceFS 社區版的元數據模塊,與存儲模塊類似也提供一組操作元數據的接口,可以接入不同的元數據服務,比如 Redis,TiKV 等 KV 數據庫,MySQL,PostgreSQL 等關系型數據庫,也可以使用 FoundationDB。JuiceFS 企業版使用自研高性能元數據服務,可根據負載情況來平衡數據和熱點操作,以避免大規模訓練中元數據服務熱點集中在某些節點的問題(比如因為頻繁操作臨近目錄文件的元數據引起)。
客戶端
3FS 的客戶端除了提供 FUSE 操作外,還提供了一組 API 用于繞過 FUSE 直接操作數據,也就是 Native Client,接口的調用方式有點類似于 Linux AIO。這組 API 的作用是避免使用 FUSE 模塊帶來的數據拷貝,從而減少 I/O 延遲和對內存帶寬的占用。下面將詳細解析這組 API 如何實現用戶進程與 FUSE 進程之間的零拷貝通信。
3FS 通過hf3fs_iov保存共享內存的大小,地址和其他一些屬性,使用IoRing在兩個進程間通信。
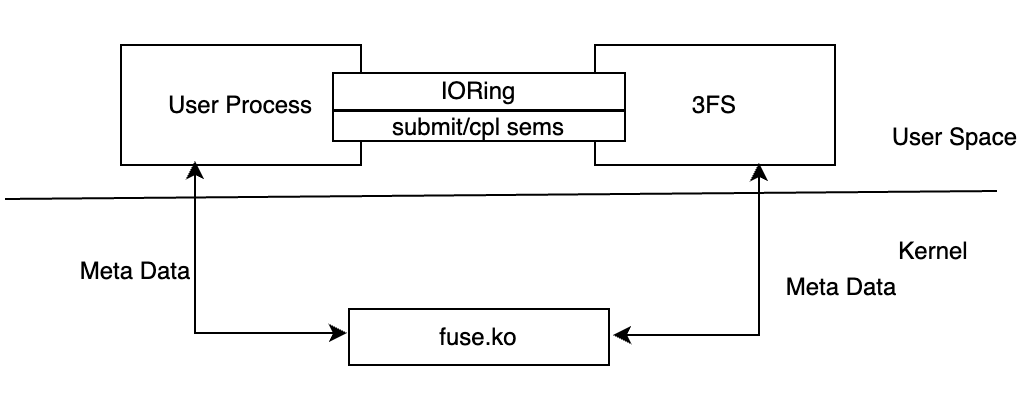
3FS NATIVE Client API
當用戶調用接口,創建hf3fs_iov時,會在/dev/shm上分配內存,并創建一個指向這個共享內存的軟鏈接,軟鏈接的地址位于/mount_point/3fs-virt/iovs/,這是個虛擬目錄。3FS FUSE 進程收到創建軟鏈接請求,并且發現它的地址位于上述虛擬目錄后,就會根據軟鏈接的名字解析出這塊共享內存的相關參數,并將內存的地址注冊到所有 RDMA 設備(除了IORing)。ibv_reg_mr返回的結果被存在RDMABuf::Inner數據結構中,用于后續發送 RDMA 請求。
同時,IORing的內存也使用hf3fs_iov保存,只是在創建對應的軟鏈接時,文件名中會有更多的IORing相關的信息。如果 FUSE 進程發現這個內存是用于創建IORing,也會在它的進程內創建對應的IORing。這樣設置之后,用戶進程和 FUSE 進程就可以訪問相同的IORing了。
進程間協作方面,3FS 在/mount_point/3fs-virt/iovs/目錄中創建 3 個不同的虛擬文件用于共享 3 個不同優先級的提交信號量 (submit sem ),用戶進程將請求放到IORing后使用這些信號量通知 FUSE 進程有新的請求。IORing尾部包含請求完成信號量,FUSE 進程通過調用sem_post通知用戶進程IORing上有新的請求完成。以上整個機制確保了兩個進程間的高效數據通信和操作同步。
3FS 的 FUSE 客戶端實現了文件和目錄的基本操作,而 JuiceFS FUSE 客戶端的實現更加全面。比如,在 3FS 文件系統中文件的長度是最終一致的,這意味著在寫的過程中用戶可能訪問到不正確的文件長度。而 JuiceFS 在每次成功上傳對象后會立即更新文件長度。此外,JuiceFS 還提供了以下這些常用的高級文件系統功能:
? 支持 BSD 鎖(flock)和 POSIX 鎖(fcntl)
? 支持file_copy_range接口
? 支持readdirplus接口
? 支持fallocate接口
除了 FUSE 客戶端,JuiceFS 還提供 Java SDK,S3 Gateway,CSI Driver 等接入方式。企業版還提供 Python SDK,Python SDK 將 JuiceFS 客戶端在用戶進程中運行,避免了通過 FUSE 導致的額外性能開銷。具體見文檔:Python SDK[4]。
02 文件分布對比
3FS 文件分布
3FS 將每個文件分成固定長度的 chunk,每個 chunk 位于一個上文提到的鏈上( CRAQ 算法)。用戶使用 3FS 提供的一個腳本,生成一個 chain table。然后將這個表提交到元數據服務。創建新文件時,系統會從表中選取特定數量的 chain (數量由 stripe 定義),并將這些 chain 的信息存入文件的元數據中。
因為 3FS 中的 chunk 是固定的,客戶端只需要獲取一次 inode 的 chain 信息,就可以根據文件 inode 和 I/O 請求 的 offset,length 計算出這個請求位于哪些 chunk 上,從而避免了每個 I/O 都從數據庫查詢的需求。可以通過offset/chunk_size得到 chunk 的索引。而 chunk 所在的 chain 的索引就是chunk_id%stripe。有了 chain 的索引就可以得到 chain 的詳細信息(比如這個 chain 由哪些 target 組成)。然后,客戶端根據路由信息將 I/O 請求發送到相應的存儲服務。存儲服務收到寫請求后以 copy-on-write (COW)的方式將數據寫入新的位置。原來的數據在引用數據清零前仍然是可讀的。
為了應對數據不平衡問題,每個文件的第一個 chain 按照輪詢( round roubin) 的方式選擇。比如當 stripe 為 3 時,創建一個文件,其選擇的 chain 為:chain0,chain1,chain2。那么下一個文件的 chain 為:chain1,chain2 和 chain3。系統會將選擇的 3 個 chain 做隨機排序,然后存儲到元數據中。下圖為 stripe 為 3 時一個文件的分布示例,chain 隨機排序后的順序是:1,3,2。
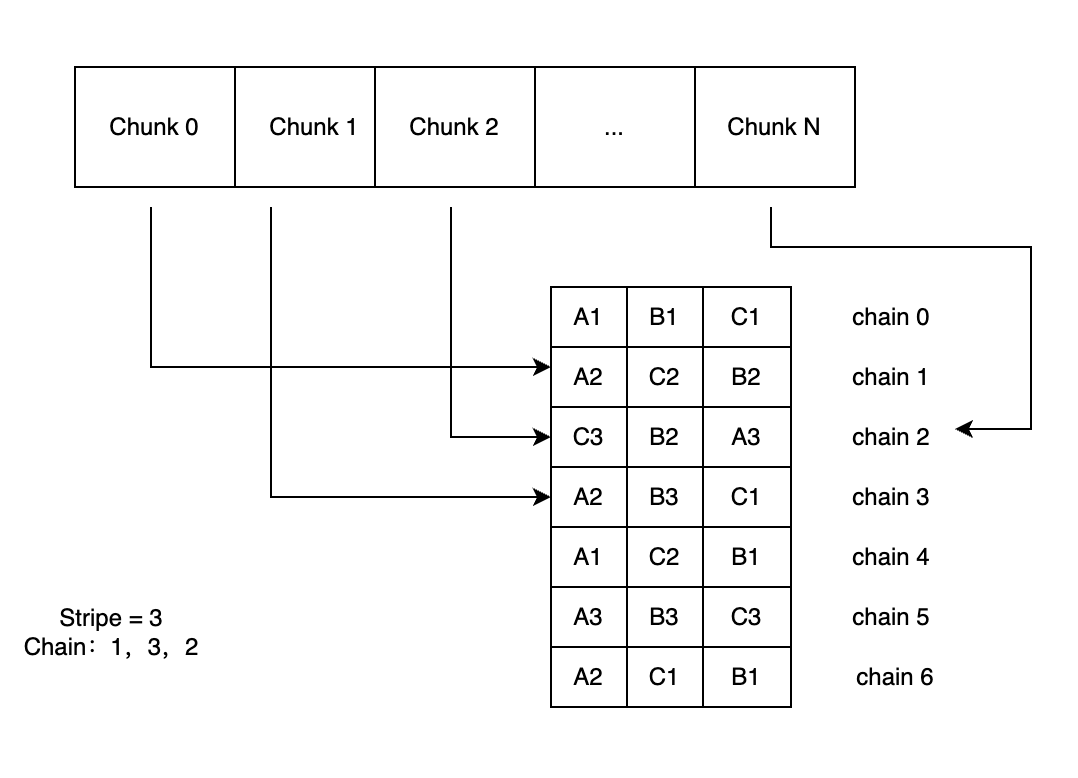
3FS 文件分布
JuiceFS 文件分布
JuiceFS 按照 Chunk、Slice、Block 的規則進行數據塊管理。每個 Chunk 的大小固定為 64M,主要用于優化數據的查找和定位。實際的文件寫入操作則在 Slice 上執行,每個 Slice 代表一次連續的寫入過程,屬于特定的 Chunk,并且不會跨越 Chunk 的邊界,因此長度不超過 64M。Chunk 和 Slice 主要是邏輯上的劃分,而 Block(默認大小為 4M)則是物理存儲的基本單位,用于在對象存儲和磁盤緩存中實現數據的最終存儲。更多細節可以參考官網介紹[5]。
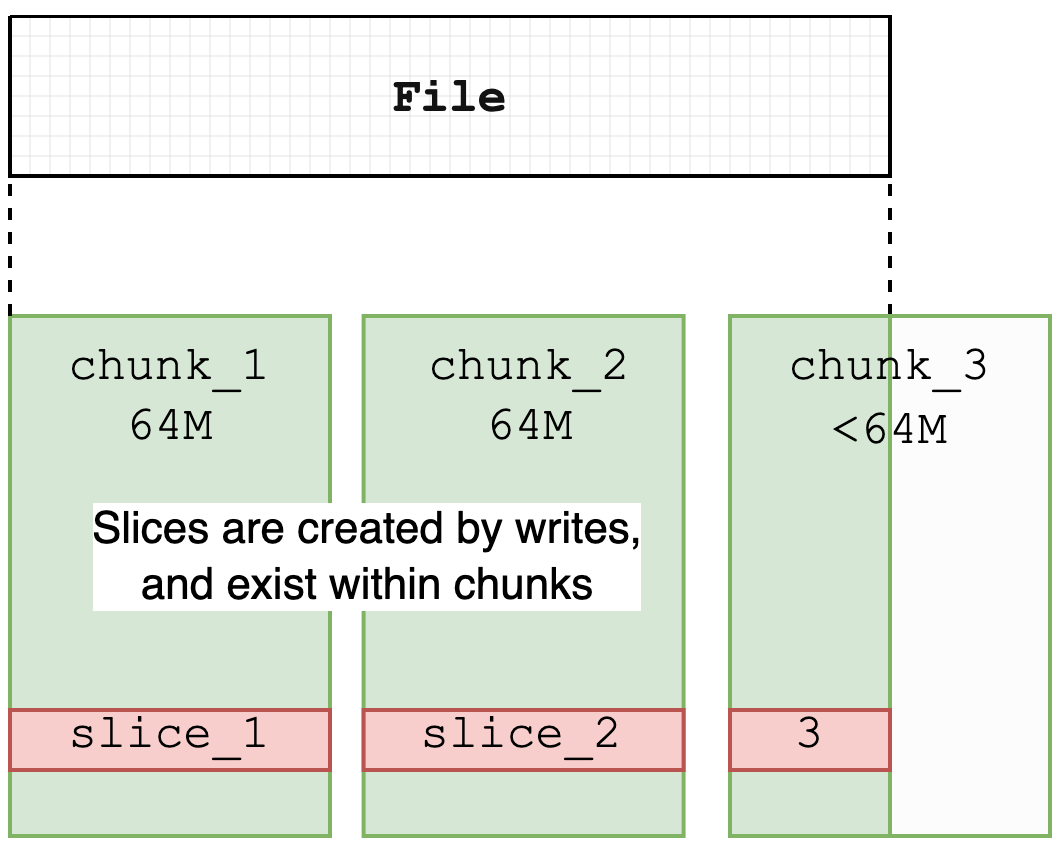
JuiceFS 文件分布
JuiceFS 中的 Slice 是在他文件系統中不常見的一個結構。主要功能是記錄文件的寫入操作,并在對象存儲中進行持久化。對象存儲不支持原地文件修改,因此,JuiceFS 通過引入 Slice 結構允許更新文件內容,而無需重寫整個文件。這與 Journal File System 有些類似,其中寫入操作僅創建新對象,而不是覆蓋現有對象。修改文件時,系統會創建新的 Slice,并在該 Slice 上傳完畢后更新元數據,從而將文件內容指向新的 Slice。被覆蓋的 Slice 內容隨后通過異步壓縮過程從對象存儲中刪除,導致在某些時刻對象存儲的使用量會暫時超過文件系統實際使用量。
此外,JuiceFS 的所有 Slice 均為一次性寫入,這減少了對底層對象存儲一致性的依賴,并大大簡化了緩存系統的復雜度,使數據一致性更易于保證。這種設計還為實現文件系統的零拷貝語義提供了便利,支持如 copy_file_range 和 clone 等操作。
03 3FS RPC (Remote Procedure Call) 框架
3FS 使用 RDMA 作為底層網絡通信協議,目前 JuiceFS 尚未支持,下面對此做一些分析。
3FS 通過實現一個 RPC 框架,來完成對底層 IB 網絡的操作。除了網絡操作外,RPC 框架還提供序列化,小包合并等能力。因為 C++ 不具有反射能力,所以 3FS 還通過模版實現了一個反射庫,用于序列化 RPC 使用的 request、response 等數據結構。需要被序列化的數據結構只需要使用特定的宏定義需要序列化的屬性。RPC 調用都是異步完成的,所以序列化后的數據只能從堆上分配,等待調用完成后再釋放。為了提高內存的分配和釋放速度,分配對象都使用了緩存。3FS 的緩存有兩部份組成,一個 TLS 隊列和一個全局隊列。從 TLS 隊列獲取緩存時不需要加鎖;當 TLS 緩存為空時就得加鎖,從全局隊列中獲取緩存。所以在最優情況下,獲取緩存是不需要加鎖的。
與 I/O 請求的負載不同,緩存對象的內存都未注冊到 RDMA 設備中。因此,當數據到達 IBSocket 后,會被拷貝到一個在 IB 設備注冊過的緩沖區中。多個 RPC 請求可能被合并為一個 IB 請求發送到對端。下圖為 FUSE Client 調用 Meta 服務的 RPC 過程。
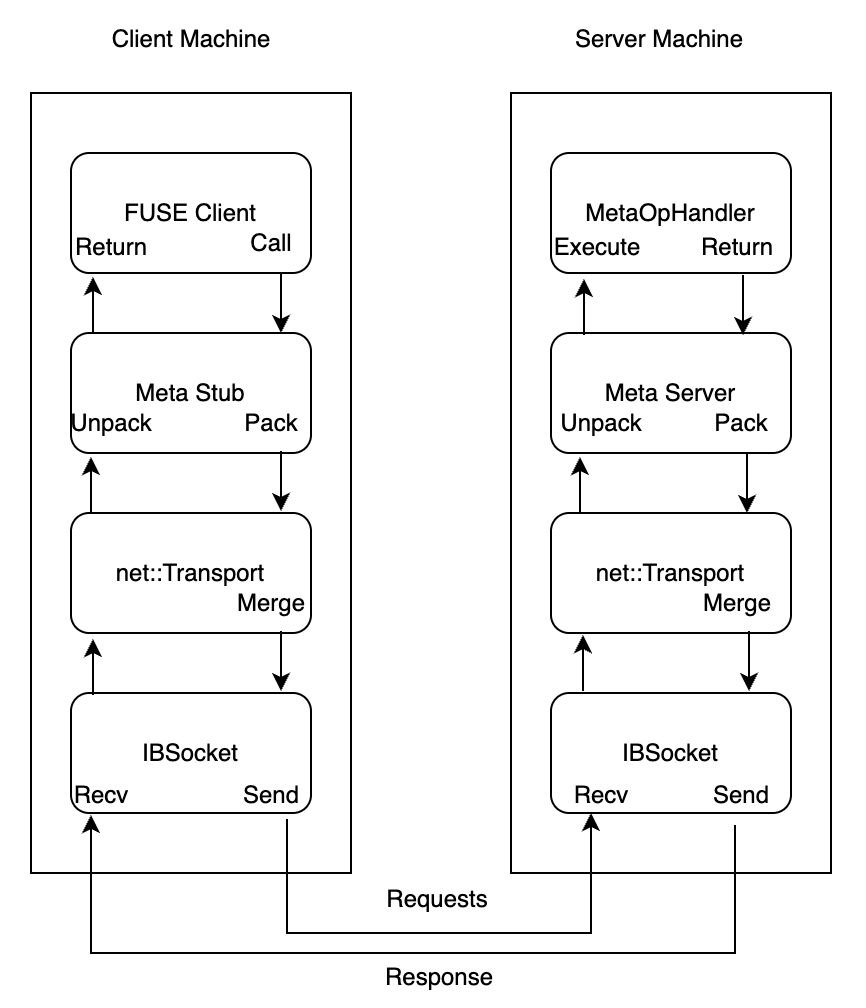
3FS FUSE Client 調用 Metadata服務的 RPC 過程
04 特性對比
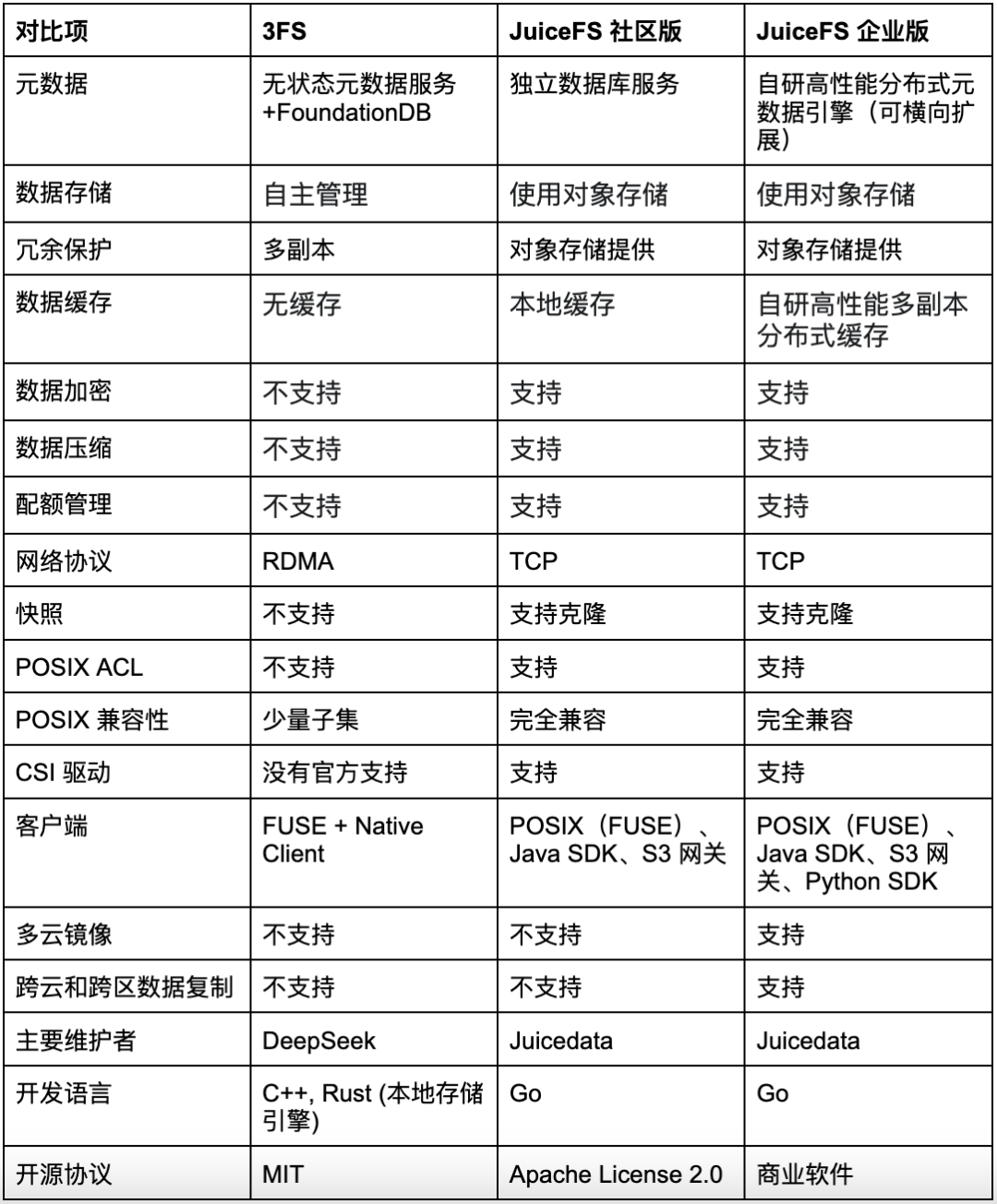
05 總結
大規模 AI 訓練中最主要的需求是高讀帶寬,為此 3FS 采用了性能優先的設計策略,將數據存儲在高速磁盤上,并且用戶需要自行管理底層數據存儲。這種方法提升了性能,但成本較高,維護也更繁重。此外,為了充分發揮底層硬件的性能,其架構實現了客戶端到網卡的零拷貝,利用共享內存和信號量減少 I/O 延遲和內存帶寬占用。此外,通過帶 TLS 的 I/O buffer pool 和合并網絡請求,3FS 增強了小 I/O 和文件元數據操作的能力,并引入了性能更優的 RDMA 技術。我們將繼續關注 3FS 在性能優化方面的進展,并探索如何將這些技術應用于我們的場景中。
JuiceFS 使用對象存儲作為底層數據存儲,用戶因此可大幅降低存儲成本并簡化維護工作。為了滿足 AI 場景的對讀性能的需求,JuiceFS 企業版引入了分布式緩存、分布式元數據服務和 Python SDK,從而提高文件系統的性能和擴展能力,并同時兼顧低存儲成本。在接下來發布的 v5.2 企業版中,在 TCP 網絡中實現了零拷貝,進一步提升數據傳輸效率。
JuiceFS 提供完整的 POSIX 兼容性和成熟活躍的開源生態,適應更廣泛的使用場景,并支持Kubernetes CSI,極大簡化了云平臺的部署和運維工作。此外,JuiceFS 還提供了 Quota、安全管理和數據災備等多項企業級管理功能,讓企業可以更便捷地在生產環境中部署和應用 JuiceFS。
關于作者
劉慶
Juicedata 核心系統開發工程師
-
存儲
+關注
關注
13文章
4433瀏覽量
86620 -
文件系統
+關注
關注
0文章
293瀏覽量
20121 -
開源
+關注
關注
3文章
3492瀏覽量
43083 -
DeepSeek
+關注
關注
1文章
697瀏覽量
579
原文標題:DeepSeek 3FS與JuiceFS:架構與特性比較
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
在龍芯3a6000上部署DeepSeek 和 Gemma2大模型
了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應用選擇
添越智創基于 RK3588 開發板部署測試 DeepSeek 模型全攻略
鴻蒙原生應用開發也可以使用DeepSeek了
RK3588開發板上部署DeepSeek-R1大模型的完整指南
北京大學兩部 DeepSeek 秘籍新出爐!(附全集下載)
HarmonyOS NEXT開發實戰:DevEco Studio中DeepSeek的使用
DeepSeek推動AI算力需求:800G光模塊的關鍵作用

貼片電容0402與0603型號規格全面對比

華為ModelEngine AI平臺全面支持DeepSeek





 工商網監
工商網監

評論