") 使用MaxCompute阿里大數(shù)據(jù)計算方法詳解
使用MaxCompute阿里大數(shù)據(jù)計算方法詳解
給大家分享一下基于MaxCompute搭建社交好友推薦系統(tǒng),使用MaxCompute阿里的大數(shù)據(jù)計算的方法可以做哪些事情,如果說是以社交好友的推薦,來給大家去演示一下。好友推薦系統(tǒng)它的一個場景介紹,現(xiàn)在大家都在講大數(shù)據(jù),如果想去使用這些數(shù)據(jù),我們認(rèn)為它需要具備三個要素,第一個要素是海量的數(shù)據(jù),數(shù)據(jù)量越多越好,只有數(shù)據(jù)量達(dá)到了足夠大,我們才能夠成為一個數(shù)據(jù)里面潛在去挖掘出來。第二個是處理數(shù)據(jù)的能力,有了這樣很高的快速處理數(shù)據(jù)的能力,可以讓我們更快的去把數(shù)據(jù)里面的信息挖掘出來。第三個是商業(yè)變現(xiàn)的一個場景,我們采集大數(shù)據(jù)的時候,并不是數(shù)據(jù)越多越好,一定要有一個具體的場景。以推薦系統(tǒng)為例來看一下大數(shù)據(jù)的一個應(yīng)用。
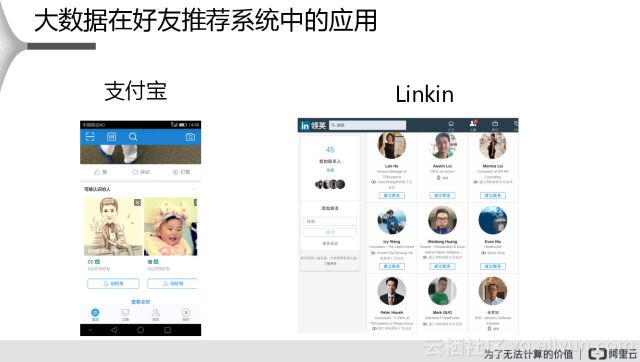
左邊是支付寶,在支付寶一打開的時候,下面會有一欄推薦可能是你的好友,一般的話下面的那些人都是你認(rèn)識的,可能還沒加他們?yōu)楹糜选S覀?cè)是Linkin,它是一個求職社交網(wǎng)站,Linkin也會給你這樣的一個推薦,會告訴你哪一些用戶是你潛在的好友,而且Linkin會告訴你這個好友跟你是一度的關(guān)系的還是兩度的關(guān)系或者是三度的關(guān)系。潛在關(guān)聯(lián)性高的,會在前面直接顯示出來,潛在關(guān)聯(lián)性沒有那么高的也會在后面顯示出來,這兩個都是典型的一個好友推薦。
進(jìn)行好友推薦的時候,怎么給用戶進(jìn)行推薦,首先這兩個人是非好友的關(guān)系,接著我們?nèi)タ匆幌滤麄儌z潛在共同好友的處理,通過這種方式去給用戶推送,比方說潛在好友數(shù)量多,我就認(rèn)為這兩個人是好友關(guān)系,就是通過這種方式來實現(xiàn)的。
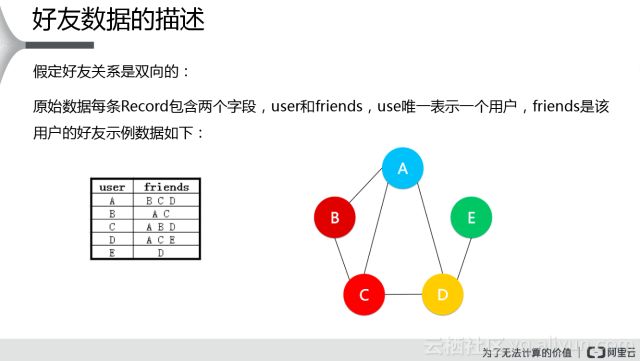
上圖的右側(cè)是人與人之間的一個社交關(guān)系的服務(wù),比如說A跟B是一個好友,我們可以通過這五個方式畫出來,讓機(jī)器去分析這些數(shù)據(jù),需要把右邊這種社交的關(guān)系,轉(zhuǎn)換成機(jī)器可以識別的數(shù)據(jù),轉(zhuǎn)換成左側(cè)這樣的二維表的數(shù)據(jù),比如說A跟B、C、D他們之間是好友,我們左側(cè)是A跟B、C、D是好友關(guān)系,剩下這些也是類似的,這樣就可以把這個表傳到機(jī)器里面進(jìn)行分析,比方說通過分析之后,發(fā)現(xiàn)A跟E有一個共同好友,B跟D有兩個共同好友,然后C跟E有一個共同好友。這個時候就可以推薦B跟D他兩個是一個潛在的好友,而排在前面,A跟E或者C跟E排在概率往下,稍微低一些,潛在好友多的排在前面,潛在好友少的排在后面,通過這種方式來進(jìn)行排列,這個是我們期望的結(jié)果。
好友推薦系統(tǒng)的分析模型
我們怎么來去計算呢?我們一般使用方式是什么呢?使用的是MapReduce這樣的一個計算模型,MapReduce是一種編程模型,用于大規(guī)模數(shù)據(jù)集的并行運(yùn)算,它由三部分組成分別是Map、Combine、Reduce。
以好友推薦這樣的一個場景為例。
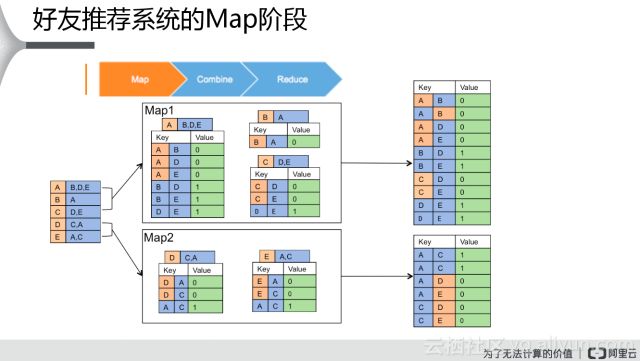
首先輸入左側(cè)機(jī)器可以識別的數(shù)據(jù),輸入之后,在Map端先把數(shù)據(jù)做一個拆分,拆分成兩份不同的數(shù)據(jù),在拆分的同時把它轉(zhuǎn)換成key、value的類型,比方說A、B、D、E這幾行數(shù)據(jù)轉(zhuǎn)換成什么呢?A跟B,然后value是零,零代表他們兩個已經(jīng)是好友。如果兩個不是好友的話,自定義這一行數(shù)據(jù),B跟D不是好友,就把他的值視為1。下面的B、E,還有D跟E也是1。把原來一行數(shù)據(jù)轉(zhuǎn)換成Key、Value這個形式的數(shù)據(jù),類似于右邊這樣的數(shù)據(jù),上面是key、value的一個類型,下面也是類似的。這個是在Map做的事情,把這個數(shù)據(jù)通過兩個key、value進(jìn)行一個拆分,轉(zhuǎn)化成key、value這樣的一個類型。
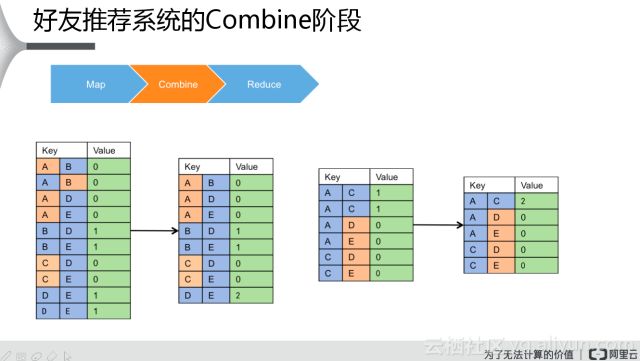
Combine是對數(shù)據(jù)先做一個本地的匯總,先看到有一些數(shù)據(jù)是重復(fù)的,比如說A跟B是零,A跟B是零,出現(xiàn)了兩次,這個時候就存一個就可以。其他類似的,這樣我把這些數(shù)據(jù)在本地做完匯總,類似于這張表,這兩個數(shù)據(jù)。
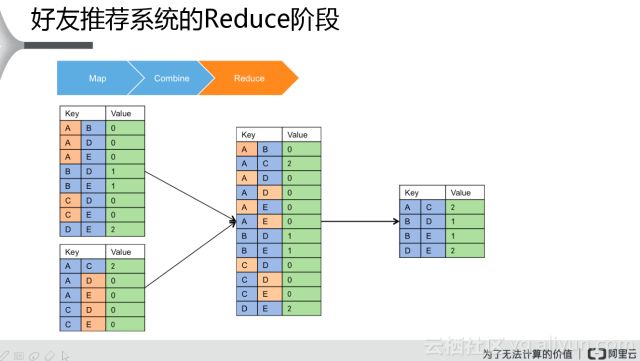
接著是第三步是Reduce階段,Reduce是對這些數(shù)據(jù)進(jìn)行一個匯總,把兩邊數(shù)據(jù)匯總到一起,然后對每一個Key值對應(yīng)唯一的一個value值做一個匯總,這個就是它最終計算的一個結(jié)果。如果兩個用戶已經(jīng)是好友了,Value值是零的話,不需要再給他推薦。所以說A、B如果是零的話就剔掉,只需要知道它的value值是大于零的,有潛在好友,同時這兩個人目前還是非好友的關(guān)系,這個就達(dá)到了想要的效果。
好友推薦系統(tǒng)在阿里云上的實現(xiàn)方式
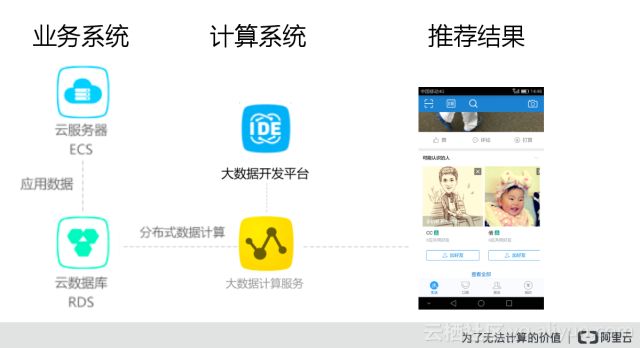
好友推薦阿里云實現(xiàn)整個的架構(gòu)是怎么樣的呢?比方現(xiàn)在有一個社交軟件是一個業(yè)務(wù)系統(tǒng),前端使用阿里云的云服務(wù)器ECS去部署整個的社交的軟件的應(yīng)用,入庫的一些數(shù)據(jù)存到阿里的RDS,這個就是當(dāng)前的一個社交應(yīng)用系統(tǒng)。業(yè)務(wù)系統(tǒng)里面產(chǎn)生了一個數(shù)據(jù),怎么來對數(shù)據(jù)進(jìn)行分析,首先需要在數(shù)據(jù)庫里邊把這個數(shù)據(jù)提取出來,提取到阿里云的大計算服務(wù)MaxCompute里面,很類似于我們傳統(tǒng)做數(shù)倉的時候ETL的一個過程,會利用阿里云的大數(shù)據(jù)開發(fā)平臺對數(shù)據(jù)進(jìn)行分析和處理。
使用它可以快速便捷的去開發(fā)我們數(shù)據(jù)植入或者數(shù)據(jù)這樣的一個流程,這個就是會使用大數(shù)據(jù)開發(fā)平臺和大數(shù)據(jù)制造,結(jié)果是一個數(shù)據(jù)分析結(jié)果,還需要前端的應(yīng)用數(shù)據(jù)對分析出來的結(jié)果展示出來。
MaxCompute的技術(shù)特點
對于MaxCompute的一些技術(shù)特點主要有一下幾點:
-
分布式:分布式集群、跨集群技術(shù)、可靈活擴(kuò)展。
-
安全性:從安全性來講具有自動存儲糾錯、沙箱機(jī)制、多分備份。
-
權(quán)限控制:多租戶管理、用戶權(quán)限策略、數(shù)據(jù)訪問策略。
MaxCompute的使用場景
對于MaxCompute的使用的場景,可以使用MaxCompute搭建自己的一個數(shù)據(jù)倉庫,同時,MaxCompute還可以提供一種分布式的應(yīng)用系統(tǒng),比方說可以通過圖計算,或者通過有效的寬幅的方式,可以搭建一個工作流;比方說數(shù)據(jù)分析并不是說只分析一天就不分析了,其實是周期性的。如果數(shù)據(jù)每天要分析一次,可以在MaxCompute里面生成那樣的任務(wù)工作流,設(shè)置一個周期性的調(diào)度,每天要讓它調(diào)度一次,MaxCompute可以按照設(shè)計好的工作流,調(diào)動周期,然后去運(yùn)行;MaxCompute在機(jī)器學(xué)習(xí)里面也是有用的,因為機(jī)器學(xué)習(xí)會用到MaxCompute分析出來的數(shù)據(jù),其他相類似的服務(wù)對數(shù)據(jù)進(jìn)行分析處理,分析出來的結(jié)果數(shù)據(jù)放到機(jī)器學(xué)習(xí)平臺里面,讓機(jī)器通過一些算法一些模型,去學(xué)習(xí)這里邊的數(shù)據(jù),生成一個希望達(dá)到的一個模型。
大數(shù)據(jù)開發(fā)套件DataIDE
另外一個除了MaxCompute之外還有一個會用到一個大數(shù)據(jù)開發(fā)操作DateIDE,大數(shù)據(jù)開發(fā)套件DataIDE(現(xiàn)名:數(shù)據(jù)工場DataWorks)提供一個高效、安全的離線數(shù)據(jù)開發(fā)環(huán)境。為什么介紹它呢?是因為DateIDE只是對數(shù)據(jù)任務(wù)工作流的一個開發(fā),其實底層的數(shù)據(jù)處理,數(shù)據(jù)分析,都是在MaxCompute上完成,可以簡單理解為DateIDE就是一個圖象化的數(shù)據(jù)開發(fā)的服務(wù),它是為了幫助我們更好去使用MaxCompute。也可以看到,這我們可以在DateIDE進(jìn)行一個開發(fā),不需要直接在MaxCompute里面進(jìn)行開發(fā)了,在MaxCompute開發(fā)的一個效果,跟在DateIDE里面開發(fā)的效果對比。
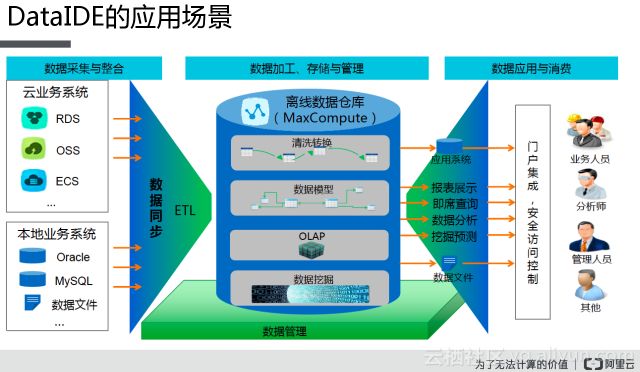
這個是DateIDE整個應(yīng)用的一個場景,我們在進(jìn)行數(shù)據(jù)分析的時候,需要對里面的原數(shù)據(jù)進(jìn)行整合統(tǒng)一保存,這個時候可以在DateIDE上實現(xiàn),把所有的原數(shù)據(jù)的信息統(tǒng)一匯總到MaxCompute里面進(jìn)行一個保存,同時還可以DateIDE進(jìn)行數(shù)據(jù)的加工,存儲等操作都可以在DateIDE上完成。DateIDE在整個數(shù)據(jù)分析的過程中可以對數(shù)據(jù)存儲、分析、處理、集群等處理。
MaxCompute的應(yīng)用開發(fā)流程
MaxCompute的應(yīng)用開發(fā)流程一共需要六步分別是:
-
安裝配置環(huán)境
-
開發(fā)MR程序
-
本地模式測試腳本
-
導(dǎo)處jar包
-
上傳到MaxCompute項目空間
-
在MaxCompute中使用MR
下面我們以一個好友推薦的事例來詳細(xì)講解一下這個過程。首先需要去安裝MaxCompute客戶端,使用它的好處是可以在本地通過命令的方式去遠(yuǎn)程使用阿里云的MaxCompute,在本地只需要配置MaxCompute信息就可以。另外還需要去配置自己的一個開發(fā)環(huán)境,因為現(xiàn)在阿里云的MaxCompute主要是兩種語言,一種是Java一種是Eclipse。然后新建項目,在開發(fā)新建項目的時候,大家可以看到這個紅包,這個紅包就是需要配置本地的客戶端的信息。在進(jìn)入到寫代碼的過程。
接下來就是簡單的測試,開發(fā)之后要測試,這個代碼是不是按照設(shè)想的方式去工作的。接著這邊輸入的是一個測試數(shù)據(jù),這個輸出的數(shù)據(jù)類別,就是輸出的這樣的一個表格,表格有三列,第一類是用戶A,第二類是用戶B,第三類是兩個潛在的共同好友的數(shù)量,只需要關(guān)注這三個數(shù)據(jù)就可以,然后就可以測試。接著第三個本地運(yùn)行的數(shù)據(jù)的代碼,運(yùn)行的結(jié)果就是通過本地的開發(fā)測試,在本地測試的時候這邊有一個數(shù)據(jù),你第一步需要選擇是使用哪一個的一個項目處理。第二個要選擇輸入表和輸出表,要告訴他輸出表是哪個,輸出表的目的是什么,告訴這個程序,你輸出的結(jié)果保存在表里面,配置好點擊運(yùn)行這個結(jié)果就出來了。
本地開發(fā)測試成功之后,接著要把它打成一個Jar包,然后上傳到阿里云上,就是上傳到MaxCompute的集群里邊。第二個打完Jar包以后添加資源,下面就把剛剛輸出的Jar包,通過資源的管理,把剛剛輸入的Jar包上傳上來。本地開發(fā)測試好的一個MR的Jar包已經(jīng)上傳到MaxCompute集群里邊。
上傳好了之后就可以使用它,去新建一個任務(wù),然后這個任務(wù)去起個名字,這個任務(wù)跟哪一個Jar包相關(guān)聯(lián),接著是OPENBMR,我們選的是MR的程序,所以里面選的是OPENMR模塊,生成這樣的一個任務(wù),進(jìn)入到編輯頁面,在編輯頁面里面首先告訴它,這個OPENMR這樣的一個任務(wù),使用的是上傳的好友推薦的一個Jar包,最下面告訴它Jar包里面的程序的邏輯是什么,在這個里面制定好之后點擊運(yùn)行結(jié)果就會出來。這個就是我們在本地開發(fā)測試,把資源上傳到MaxCompute的集群里面,接著在集群里面去使用我在本地開發(fā)好的Jar包,這個就是整個的一個開發(fā)和部署的一個流程。
-
嵌入式
+關(guān)注
關(guān)注
5089文章
19170瀏覽量
306801 -
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
8904瀏覽量
137631
原文標(biāo)題:基于大數(shù)據(jù)搭建社交好友推薦系統(tǒng)
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
電阻器的工作原理與計算方法
波特率的定義和計算方法 波特率與數(shù)據(jù)傳輸速度的關(guān)系
FPGA門數(shù)的計算方法
人工智能云計算大數(shù)據(jù)三者關(guān)系
云計算在大數(shù)據(jù)分析中的應(yīng)用
電流計算方法與配線法的區(qū)別
電荷放大電路的帶寬 和IV轉(zhuǎn)換電路帶寬計算方法不一樣嗎?
使用位置傳感器輸出數(shù)據(jù)的角度計算方法

DCS系統(tǒng)I/O點數(shù)計算方法與原則
相電流和線電流的關(guān)系計算方法

儲能容量的計算方法
電壓探頭延遲計算方法及應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論