

【概要】
根據數據的壽命將數據存放在SSD的不同塊內可以顯著提高SSD的GC效率、減少WAF、提高SSD的壽命和性能。多流技術(Multi-stream technology)可以設置數據放置策略從而減少WAF和數據碎片。本文提出了FileStream,利用聚類算法學習文件特征從而給文件分配數據流,使得相似壽命的數據存放在SSD的同一塊內。最后作者測試了六個不同的benchmark,和baseline和兩個自動流管理技術相比,分別平均減少了寫放大34.5%和21.6%。
【背景與相關工作】
1. 多流技術
用戶可以在寫請求中傳遞一個hint(流ID,Stream ID),流ID不同的數據會被放在SSD的不同的地方(如不同的塊內)。所以當主機根據數據的壽命分配不同的流ID時,壽命不同的數據將被分開存放,從而提高GC效率。
目前,NVMe已經添加了多流技術,而Linux 4.13內核也增加了“write lifetime hints”來攜帶流ID。同時,多流技術不僅僅可以用于多流SSD,還可以用于其他設備如OpenChannel SSD、Zoned Namespace SSD。
2. 流ID分配的相關工作
手動分流
在應用的代碼中實現一個固定的流分配策略(基于文件類型和一些內部的機制)。缺點是無法適應多樣的工作集和應對工作集的特征的改變。同時,把這些策略應用在生產中成本略高,因為需要修改應用代碼或者內核代碼。
表1 手動分流的相關論文

自動分流
不依賴于具體應用進行流分配。如下表,現存的自動分流策略無法直接用在某些通用的工作集中,而且比不過手動分流。
表2 各種自動分流策略一覽
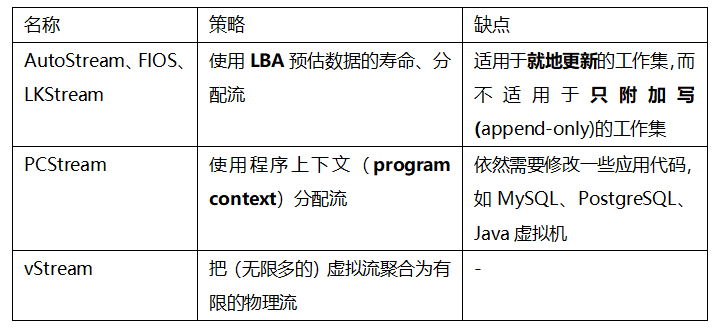
表3 自動分流的相關論文

FileStream——基于文件特征實現自動分流
1)動態適應多樣的工作集
2)在Linux用戶態實現,除了傳遞stream ID之外,不會影響應用和內核。
文件特征分析
只附加寫的文件(Append-only File)
這類文件只會順序寫入,不允許修改舊數據,更新的數據會寫入一個新文件,如日志結構的文件(例如RocksDB和Cassandra的寫前日志和數據文件,它們使用LSM樹進行管理)。
文件中的數據壽命很難通過LBA的訪問次數得出。一個文件的數據的LBA可能不連續,而且數據可能被其他文件覆寫。
文件中的數據的壽命和文件的類型有關,如下圖,數據文件有多個等級(L0~L3),低等級的文件在合并入高等級文件后會被刪除,所以它們的壽命更短。然而,文件的等級只能通過修改應用代碼獲得,所以這種分流思路只能適用于手動分流。
不過,從圖中可以得到兩個信息:
① 這類文件從創建到結束寫入的時間很短,而且同時正寫入的文件很少,而同一文件的數據的壽命通常類似。同時,根據經驗,不同時間使用同一流ID寫入SSD的數據通常不會寫入同一塊。
② 寫前日志的壽命比數據文件短,不同類型文件的壽命不同。
綜上,可以通過文件類型區分文件中的數據壽命。
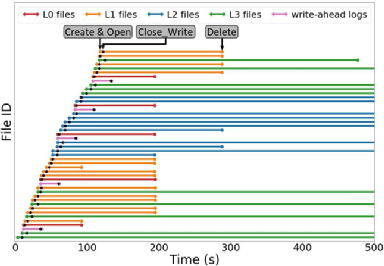
圖1 RocksDB 文件的操作
就地更新的文件(In-place Update File)
這類文件允許隨機寫,允許文件內更新數據,如關系數據庫中的數據文件(例如MySQL和PostgreSQL中的表文件)。這類文件的存在時間通常比較長,它們隨著表的創建和刪除而創建或刪除。
若對一個LBA的寫很頻繁,意味著大部分寫入這個LBA的數據壽命較短。下圖顯示了同一個表文件中LBA的訪問頻率相似,而不同表文件中LBA的訪問頻率不同。為了從文件的角度看待LBA的訪問頻率,作者提出USM(unit-size-modification)——文件被修改的次數比上文件的大小。對于這類文件,可以通過USM區分文件中的數據壽命。

圖2 在MySQL和PostgreSQL中的數據寫入
【方法】
1. Mapper:初分流
因為append-only文件從打開到結束寫入的時間很短,所以有必要在文件一打開就決定文件中數據的流ID,而此時我們并沒有很多文件的修改信息。FileStream的設計思路為,最小化同一流內不同壽命的文件的寫入量。設具有同一個父路徑和擴展的文件為同類文件。
對于選定時刻的選定流內的選定文件fi將來要寫入的數據量的計算方式如下:
設m(fi)是fi每秒的修改量,cd(fi)是fi的當前已持續寫入的時間,wd(fi)是fi這類文件平均寫持續時間,amount(fi)是fi將來要寫入的數據量。則:
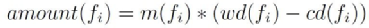
對于fi和新打開的文件fo之間的壽命差異計算如下:
設Fi是和fi同類型的文件,Ni是這類文件的數量,l(fa)是Fi中的文件的壽命。Fo、No和l(fb)的定義同理。dif(fi,fo)是fi和fo的壽命差異(最大值為1)。則:
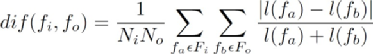
綜上,設Fs為流s中正在寫入的文件集,對某一流s的評分如下:
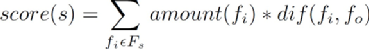
在分配時選擇評分低的s分配給fo。其中,流編號為1到d。
2. Remapper:再分流
如果一個文件打開了T秒,則啟動remapper來根據文件的訪問情況分配新的流ID。此時可以認為該文件是就地更新的文件,文件中的數據壽命可以根據USM決定。
作者每T秒啟動一個聚類算法(Kmeans++),為這類文件分配編號為d+1到N的流。(N是SSD允許的最大流編號)
3. Devider:決定mapper和remapper映射的流ID區間
divider每T秒調節d的大小。若mapper中處理的文件較多、更新較頻繁,則d更大。調節方式如下:
設FNm和FNr分別表示mapper和remapper管理的文件數量,MNm和MNr分別表示它們的文件修改總次數。首先計算一個系數proportion:
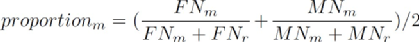
隨后計算d為:
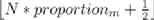
【實驗】
1.實驗設置
本文在真實的多流SSD——SAMSUNG PM963 SSD(支持8流)上進行了測試。內核4.13不支持傳入流ID信息,所以作者在內核上打了補丁。
實驗測試了6個工作集,具體信息如下表:
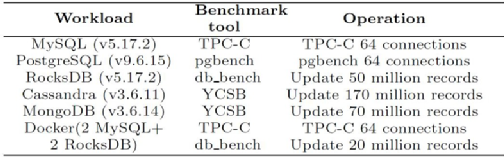
實驗比較了FileStream和四個方案的性能差異:
①baseline:沒有多流技術
②AutoStream:根據LBA的訪問情況(連續性、更新頻次、時間)自動分流
③LKStream:通過相關的數據集的特點(I/O大小、I/O數目和帶寬),預測數據的溫度來進行分流
④ManualStream:手動分流。數據先根據文件類型區分,然后對于數據文件,根據文件的等級(對于RocksDB和Cassandra)或者更新頻次(對于MySQL、PostgreSQL和MongoDB)分流。
T被設置為60s。
2.結果分析
WAF
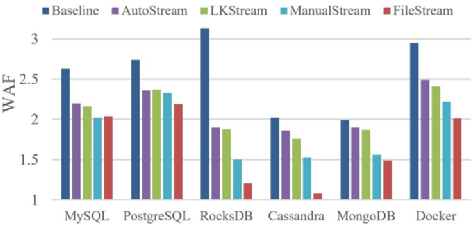
在幾乎所有策略中,FileStream表現最好,甚至比手動分流還要好。和baseline、AutoStream和LKStream相比,FileStream平均減少了WAF34.5%、22.3%和20.8%。Docker是一個混合了多類工作集的復雜工作集,FileStream可以很好地區分不同的數據壽命,所以它的表現比其他策略更好。
Throughput
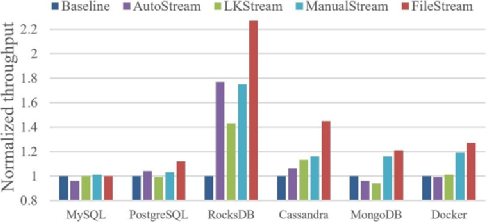
注:對于MySQL和PostgreSQL,使用每分鐘的事務數表示帶寬;對于RocksDB、Cassandra、MongoDB,使用每秒鐘操作數表示帶寬;對于Docker,使用IOPS表示帶寬。
FileStream和其他策略相比,帶寬明顯更高。和AutoStream和LKStream相比,帶寬分別平均提高了21.9%和25.8%。因為mapper把append-only文件的數據分到不同的流中,比手動分流分得更加徹底,所以FileStream的帶寬更好。
不同模塊的分析
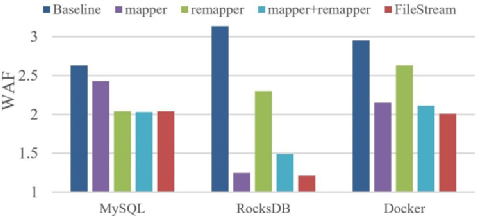
圖中mapper+remapper表示mapper和remapper平均分配N流,從圖中可以看出來,此時并不能達到最優,所以divider是很有必要的。
T的分析
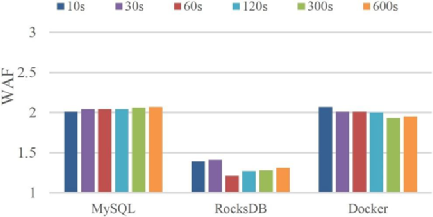
從圖可知,60s并沒有達到最優,后續或許可以進行動態調整。然而,WAF對T的變化并不敏感。
資源消耗分析
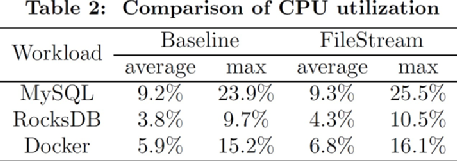
因為聚類只使用USM,所以對CPU的占用只有微弱的提升。同時內存消耗不會超過50MB。
【總結與未來的工作】
FileStream總結
(1)使用mapper,基于流的使用情況和文件類型把新打開的文件分到不同的流中
(2)使用remapper,利用Kmeans++聚類,把文件分到不同類中
實驗顯示FileStream可以減少WAF、提高帶寬。
未來工作
(1)將FileStream擴展到更多的設備上,如Zoned Namespace SSD。
(2)當文件內的數據壽命不一致時,結合文件信息和LBA相關的信息進行進一步決策。
致謝
感謝本次論文解讀者,來自華東師范大學的碩士生俞丁翠,主要研究方向為智能存儲。
-
數據
+關注
關注
8文章
7230瀏覽量
90502 -
SSD
+關注
關注
21文章
2921瀏覽量
118678 -
文件
+關注
關注
1文章
575瀏覽量
25038 -
nvme
+關注
關注
0文章
227瀏覽量
22947
原文標題:多流技術:不同壽命數據存在SSD的不同塊
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
服務器+SSD之間的物理反應
C-RIO中多塊板卡的FPGA到RT的程序如何傳遞多塊板卡的數據
這些ssd的頁面大小和塊擦除大小是?
SSD固態硬盤壽命短?平衡算法如何進行挽救
基于生命數據的大健康公鏈生命之花FOLI介紹
三星FIP故障定位技術,讓SSD的壽命提升
西數推出企業級TLC SSD 壽命和可靠性都是頂級的存在
SSD固態硬盤使用壽命解讀 為什么會有如此限制
如何衡量SSD的壽命水平?關于SSD的可用年數
如何衡量SSD的壽命水平?SSD硬盤多久才能寫死?
磨損均衡及其對SSD預期壽命的影響
磨損均衡及其對SSD預期壽命的影響

MVTRF:多視圖特征預測SSD故障






 工商網監
工商網監

評論