 高通量測序面臨的5大挑戰
高通量測序面臨的5大挑戰
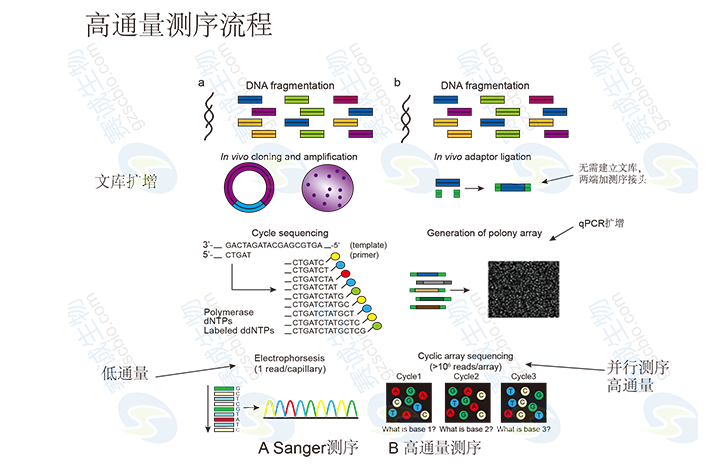
高通量測序
測序方案建立在雙脫氧測序法(Sanger等,1977)的基礎上。為了從每一克隆插入片段兩端成對地進行測序,每一個質粒模板DNA板應配備兩個384孔循環測序反應板。測序反應采用Big Dye Terminator chemistry version 3.1(AppliedBiosystems)和標準M13或常用正向引物和反向引物。測序反應通過BiomekFX(Beckman)移液操作工作站建立。機械臂負責等分模板試樣,起與反應液混合的作用,反應液含有雙脫氧核苷酸、熒光標記的核苷酸、TaqDNA聚合酶、序列引物和緩沖液。
模板和反應板有條形碼,且在BiomekFX移液操作工作站上有條形碼讀取器跟蹤,確保模板和反應液轉移中沒有錯誤。30~40線性擴增步驟連續循環在MJResearchTetrads或9700熱循環儀(Ap—pliedBiosystems)中進行。反應產物可以用異丙醇在室溫下高效率沉淀,4C下保存或懸浮在水中密閉保存。如果測序儀器正常,在掃描反應板的條形碼后,會自動為每一反應板生成一個樣品膜。然后將反應板移至一臺ABIPrism3700DNA分析儀或AppliedBiosystems 3730xiDNA分析儀上,進行電泳。現在的多聚體和軟件允許每天在ABIPrism 3700 DNA分析儀上進行8次電泳,在AppliedBiosystems 3730xlDNA分析儀上進行12次,調試時間少于1h。
平行運行大量工作的高通量測序設備通常需要通過實驗室信息管理和樣品跟蹤系統(1aboratory information management and sample tracking system,LIMS)(Kerlavage等,1993)進行自動化管理。在TIGR,這種系統包括從文庫構建早期經測序到結束的樣品跟蹤的整套軟件。經過這種處理,數據保存在Sybase關系數據庫表格中。數據庫儲存和聯系在整個基因組測序流程中所收集的全部數據,允許使用者以各種方式回溯數據流,可從已經注釋的基因回溯到基因的原始測序跟蹤文件。這個系統包括樣品管理、數據輸入、文庫管理和序列加工的客戶端/服務器應用軟件。經過多年改進,并且結合新的實驗室方法、新型的儀器和軟件,這一系統已成熟穩定。這些整合應用包括自動載體清除、確定和屏蔽重復元件、發現污染的克隆和跟蹤克隆及模板信息。
在測序流程中,生成的模板和序列的質量每天可通過用戶友好界面系統地監控。這就保證了迅速發現并改正工作中的潛在問題。通常,質量控制和質量測評(qualitycontrol/qualityassessment,QC/QA)組共同應用質量檢測標準。他們負責檢驗和提供試劑給生產組,并在流程中檢測模板質量、調查失敗和偏離正常表現范圍的情況、監控數據質量、審計、確定可改進的方面、制作控制文件(標準操作步驟),以保證這些文件具有格式上的一致性和技術上的準確性。
高通量測序面臨5大挑戰
基因測序作為醫療健康行業的火爆技術,近年來越來越得到臨床的認可,并逐步被應用到各大領域中。尤其是精準醫療概念提出以后,基因測序更是備受青睞,它為精準醫療解答了很多未知的問題。
如今,基因測序已經形成了一定的產業規模,大量的企業以不同形式躋身進來。但是,在表面飛速發展的背后,技術上仍有大量的挑戰。外媒《GEN》Shawn C. Baker博士撰文講解該領域面臨的困難與挑戰,雷鋒網(公眾號:雷鋒網)AIHealth欄目編譯如下:
過去十年里,高通量測序技術經歷了跨越式的發展,測序能力大幅上升,費用下降,兩者的變化都是數量級的。到目前為止,全球范圍內,共配備測序設備超過一萬臺。
過去十幾年來,主要的平臺公司都致力于提升系統的易用性。Illumina的最新桌面系統,比如 NextSeq、MiSeq、和MiniSeq 系統,均通過試劑盒進行操作,以減少了手工操作的次數和開機時間。
一直以來, Illumina的系統都比賽默飛的 Ion Torrent 系統更加易用,但后者最新的系統Ion S5特別設計簡化了整個工作流程,涉及設計準備庫到數據生成的整個流程。
行業外讀者在聽聞了測序行業的許多進展后,如強大的測序能力、更低的成本以及更好的易用性,可能會誤認為,基因測序所有的困難已經都解決了,測序過程的所有障礙都移除了。
但是真正的困難還剛開始,大量的挑戰在前方。
樣品質量
問題最嚴重的一個領域,也是易被忽略的是:樣品質量,雖然測試平臺經常會校準,使用的樣本也是經過校準的,但是真實世界中的樣本經常會面臨很多意想不到的挑戰。
在人類基因測序中,一個最普遍使用的樣本類型是FFPE (formalin-fixed paraffin-embedded)。FFPE的廣泛應用有多種原因,其中最重要的是豐富性。據估計,全球范圍內,有超過100億FFPE樣本存檔。FFPE塊的臨床樣本存儲已經變成工業級別的標準實踐,其樣本數量將繼續保持增長。
除全球范圍的廣泛應用外,FFPE樣本通常包含著大量可用的表型信息。例如,FFPE樣本可與治療方法和臨床數據綜合應用。
但FFPE 樣本出現的問題是:固定過程和存儲條件均會造成大量的DNA損傷。
BioCule公司CEO、聯合創始人 Hans G. Thormar博士認為,
評估了BioCule的QC平臺超過1000份樣本后,我們看到了DNA樣品中大量的變異和各種類型的損傷,例如鏈間、鏈內交聯,單鏈DNA的聚合以及單鏈DNA破壞。
DNA損傷的變異數量和類型,如果忽略,可能會對最終結果產生負面影響。
Thormar認為,
這對下游應用比如測序的影響是巨大的:從簡單測序文庫構建的失敗到虛假文庫的產生,最終導致結果的錯誤。因此,在測序項目開始時正確評估每個樣本的質量變得至關重要。
測序文庫
盡管,各大測序平臺公司花大力氣在降低生成原始序列的成本上,但是在構建測序庫方面卻不然。人類基因測序的測序文庫的構建,每個樣本大約花費50美元,在總花銷中是相對較小的一部分。但是在其他應用中,例如細菌基因組測序或低深度RNA測序,它占據總成本很大一部分。
幾個小組研究了多元化自制解決方案,期望可以有效降低成本,但在商業領域并沒有太多發展。在開發單細胞測序解決方案中有一個亮點,例如10X Genomics公司的Chromium?系統,利用基于珠的系統可以并行處理數百到數萬個樣品。
10X Genomics 公司的CEO兼聯合創始人Serge Saxonov博士堅持道,
我們認為單細胞RNA測序是進行基因表達分析的正確方式,在接下來的幾年,全球許多地區,RNA試驗將轉向單細胞分辨率,我們的平臺有可能在這方面引領浪潮。
對于大型項目,比如在降低樣品成本方面,單細胞RNA測序中要求的高度多元解決方案將是關鍵的因素。
長讀數與短讀數
Illumina對于基因測序市場的主導,意味著到目前為止產生的絕大多數數據都基于短讀數(short reads,高通量測序平臺產生的序列就稱為reads,這是測序讀到的堿基序列片段,測序的最小單位)。大量短讀數的產生對大多數的應用都很適用。例如檢測基因組DNA的單核苷酸多態性和計數RNA的轉錄物。然而,在許多其他的應用中,僅有短讀數是不夠的,例如閱讀基因組的高度重復區域和確定長鏈結構。
長讀數平臺,例如Pacific Biosciences公司的RSII和Sequel,Oxford Nanopore的MinION,通常能生成15-20kb范圍長度的讀數,最高曾報道過超過100kb長度的讀數。這樣的平臺贏得科學界的贊賞,例如加利福尼亞大學戴維斯分校細胞生物學教授Charles Gasser博士。
我對于用長讀數方法進行基因組裝配的成功印象深刻,特別是與短讀數高保真數據相結合時的混合裝配中。技術的結合使得小群體、小預算的單個研究者從一個新的生物基因組中產生一個可用的組裝。
為了充分利用這些長讀數平臺,有必要通過新方法進行制備DNA樣品,標準分子生物學方法尚未優化用來分離超長鏈DNA片段,所以,在制備長讀數庫時必須特別小心。
例如,供應商創建了一種高分子量試劑盒用于分離大于100kb的的DNA片段,優化靶向DNA方案來選擇性富集DNA的大片段,為了保證長讀數產量的最大化,這些方法和技術必須掌握。
短讀數的一種特殊形式是鏈接讀數,例如10X Genomics,可作為真正長讀數的一種替代方法。鏈接讀數是這樣產生的:每個長DNA片段,通常大于100kb,其中產生的每個短讀數,均加入一個獨一無二的條形碼,在分析階段,這種獨特的條形碼就可以將分離的短讀數鏈接在一起,從而提供長鏈基因信息,使得構建大單倍型塊和對復雜結構信息的闡釋成為可能。
短讀數測序,因其高精確度和高通量,通常具有強大的功能,但只能獲取小部分的基因信息。這是因為基因組是基本重復的,基因組中的大量信息編碼在長鏈中。
數據分析
研究人員面臨的領一大挑戰是生成的數據量非常大。單個30X人全基因組樣品的BAM文件(半壓縮比對文件)約為90GB;一個相對中等的項目,包含100個樣本,其BAM文件可達到9TB。
一個Illumina HiSeq X儀器,每年能產生超過130TB的數據,很快數據的存儲就變成一個大問題。例如,Broad研究所以每12分鐘分析一個30X人全基因組速率產生基因測序數據——每年可產生將近4000TB的BAM文件。
BAM文件可以轉化為VCF文件(變體調用格式),后者僅包含不同于標準序列的信息。雖然VCF文件小并且更加好用,但是保存原始序列文件仍是必要的,方便研究者將來查看這些數據。
隨著測序成本下降,一些人就得出這樣的結論:對樣本重測序會很容易,并且可能更便宜,而分析大量數據時,研究人員的選擇空間非常大。但事實上,在OMICtools中有超過3000個序列分析工具可供選擇,研究人員想要找到最好的那一個,也不容易。
臨床解釋和報銷
最后,對于臨床樣本,還有一個挑戰:對于測序序列的變異提供一致可靠的解釋。
一個典型的外顯子包含1萬~2萬個突變,全基因樣本則會產生超過300萬種變異。在通常的解釋中,根據變異造成的疾病相似性分類。
為了協助指導臨床醫生,美國醫學遺傳學和基因組學,分子病理學協會和美國病理學家學院創建了一套對突變進行分類的系統。分類目錄包括致病性,可能致病性,不確定的顯著性(目前占外源和全基因組樣本的絕大多數),可能良性和良性。
然而,這種方案有其局限性。即時使用一種公認的分類方案分類同一個數據庫,不同的項目組可能會提出不同的解釋。對新系統的一個試驗研究中,參與的不同臨床實驗室僅在34%的情況下,對于分類的解釋一致。
如果存在分歧或需要額外的分析來解釋實驗結果,那么就存在報銷的問題。基于NGS的測試的報銷可能是一個大障礙,但是對于解釋的報銷幾乎是不可能的。
Rady兒童基因組醫學研究所臨床研究員Jennifer Friedman博士說,
實驗室不可能對試驗的解釋付費,如果這種服務可以提供,這是非常有價值的,但是沒有人做到這個。
沒有辦法為此付費,保險公司不報銷。盡管對于精準醫學的關注度上升,但是無論是臨床醫生或實驗室做出的解釋,都沒有被醫療保健支付者承認或是重視。
到目前為止,病人樣本的分析基本上是作為一個研究項目來對待的,是在研究型醫院中的一個選擇,并且僅用于有限數量的患者。
發布評論請先 登錄
相關推薦
高通量測序數據分析:RNA-seq 精選資料分享
全基因組測序的優勢 精選資料分享
研究首次實現高通量小RNA芯片非標記檢測
高通量測序技術及原理介紹
高通量測序常用名詞匯總
高通量測序技術及其應用
高通量測序生物信息學分析





 工商網監
工商網監
評論