 存算一體技術的分類
存算一體技術的分類
近年間,云計算與人工智能技術的蓬勃興起,計算中心面臨著數據效率低、能耗大等核心挑戰,這促使學術界和工業界重新聚焦。
開宗明義,定義先行。
首先,我們先來了解一下什么是存算一體:
存算一體是通過在存儲器中嵌入計算能力,實現數據存儲與計算的緊密結合。其技術不僅能夠顯著提升計算效率,還能大幅降低能耗。
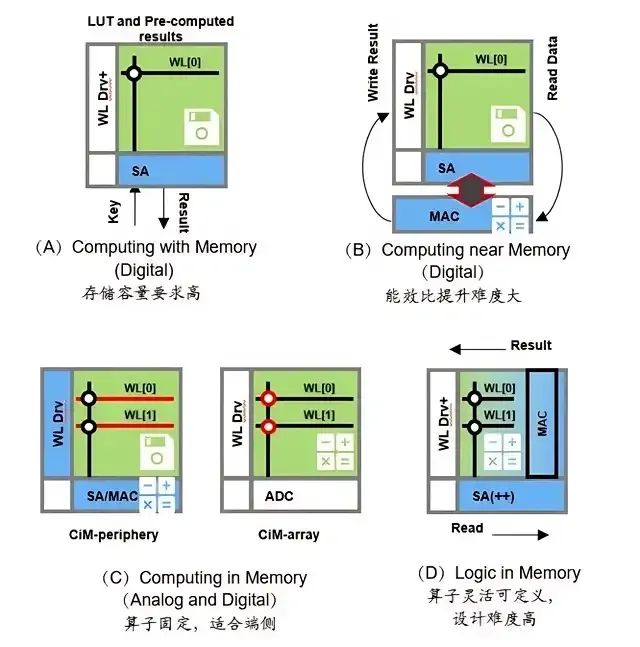
緊接著,存算一體技術分為三類:近存計算(Processing Near Memory, PNM)、存內處理(Processing In Memory, PIM)和存內計算(Computing In Memory, CIM)。
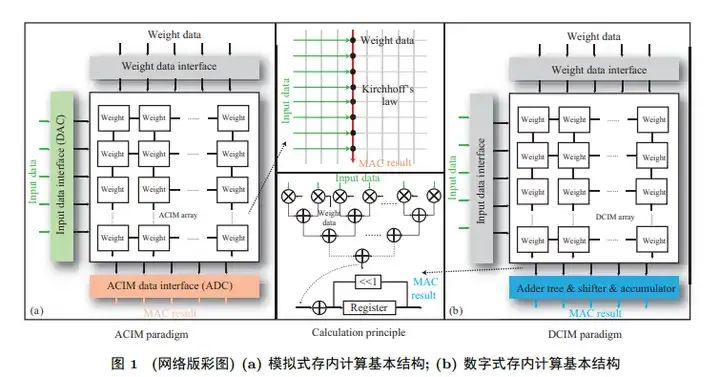
近存計算:不改變計算單元和存儲單元本身設計功能,采用先進的封裝方式及合理的硬件布局和結構優化,增強二者間通信寬帶,增大傳輸速率。
存內處理:側重于將計算過程盡可能地嵌入到存儲器內部,這種方法的能效比通常較高,但計算精度可能受限。另一種思路是在存儲器內部集成額外的計算單元,以支持高精度計算。
存內計算:存儲單元與計算單元完全融合,無獨立計算單元,通過存儲器顆粒上嵌入算法,由存儲器芯片內部的存儲單元完成計算操作。
 圖源:Google
圖源:Google
事實上,存算一體的概念由來已久。早在1969年,斯坦福研究所的Kautz等人提出了存算一體計算機的概念。其受限于當時的芯片制造技術和算力需求的匱乏,那時存算一體僅僅停留在理論研究階段,并未得到實際應用。
因此,后續研究人員在芯片電路結構、計算架構與系統應用等方面開展了一系列研究。但受限于電路設計復雜度與工藝難度,后續的大部分研究本質上實現的是 “近存計算”,其與存內計算最大的區別是,近存計算仍然需把數據從內存中讀取出來之后再就近進行計算,計算的結果再存儲到內存當中。
與此同時,存算一體技術的核心在于將數據存儲與計算融合在同個芯片的同片區之中,從而徹底消除馮諾依曼計算架構的瓶頸;將通過存儲器內部進行數據處理或計算,此技術能夠大幅減少數據在計算與存儲之間的傳輸時間,提升整體性能。
尤其,在馮諾伊曼架構中,計算單元與內存是兩個分離的單元。計算單元根據指令從內存中讀取數據,在計算單元中完成計算和處理,完成后再將數據存回內存。
然而,整個過程中,存儲器與處理器之間數據交換通路窄,以及由此引發的高能耗形成兩大難題,在存儲與計算之間筑起一道“存儲墻”。能耗方面,大部分能耗在數據搬運過程中產生,數據搬運功耗是計算功耗的1000倍。而數據搬運速度方面,AI運算需1PB/s,但DRAM 40GB-1TB/s 都遠達不到要求。
 存算一體技術的分類
存算一體技術的分類
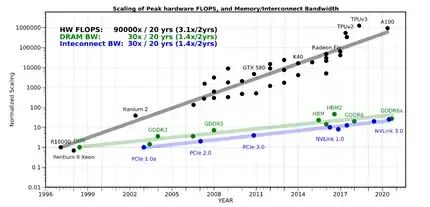
過去數載,處理器性能以每年大約55%的速度提升,而相比之下,內存性能的提升則顯著放緩,其年增長率僅約為10%。這種長期存在的性能發展不均衡現象,導致當前存儲系統的訪問速度相較于處理器的計算能力出現了顯著的滯后現象。
目前,在傳統計算機的設定里,存儲模塊是為計算服務的,因此設計上會考慮存儲與計算的分離與優先級。但如今,存儲和計算不得不整體考慮,以最佳的配合方式為數據采集、傳輸和處理服務。
其中,雖然多核(例如CPU)/眾核(例如GPU)并行加速技術也能提升算力,但在后摩爾時代,存儲帶寬制約了計算系統的有效帶寬,芯片算力增長步履維艱。從處理單元外的存儲器提取數據,搬運時間往往是運算時間的成百上千倍,整個過程的無用能耗大概在60%-90%之間,能效非常低,“存儲墻”成為了數據計算應用的一大障礙。
其次,存內計算和存內邏輯,即存算一體技術直接利用存儲器進行數據處理或計算,從而把數據存儲與計算融合在同一個芯片的同一片區之中,從而徹底消除馮諾依曼計算架構瓶頸,以便適用于深度學習神經網絡這種大數據量大規模并行的應用場景。
 算力發展速度遠超存儲
算力發展速度遠超存儲
顯然,存算一體技術的演進軌跡導向了計算精度的提升、算力輸出的增強及能效比優化的高階,以此映射出該技術內進步邏輯的必然走向。
前移至感知端,向 “極致低功耗” 邁進:面向可穿戴設備、物聯網設備等端側市場,打造超低功耗、超低成本的解決方案。當前感知芯片采集到的模擬信號依賴模數轉換器轉換成數字,信號再通過智能處理器進行處理,速度慢、功耗高。
后移至邊緣端/云端,向 “極致大算力”邁進:面向邊緣端/云端服務器、數據中 心與自動駕駛等場景,利用存算一體芯片大規模并行運算的特點,打造超大算力解決方案。當前的邊緣端/云端處理器大多基于 GPU 平臺,而 GPU 仍然受 “存儲墻” 限制,存在巨大的數據通信開銷,導致其實際算力不到標稱算力的 10%。據分析, 以 ChatGPT 為代表的主流大模型的基本組成單元 Transformer 中約有 90% 以上的運算為大規模矩陣運算,可以基于存算一體陣列高效完成。
協同異構架構與異構集成,實現合力突圍:異構架構將不同計算架構、不同功能的硬件單元進行融合,充分發揮各自的優勢,彌補各自的不足,以實現系統更高的性能。例如,單一的數字存算一體架構或模擬存算一體架構在精度、能效、面積、成本等指標上各有優劣,采用單一架構難以兼具各項性能。
驅動 EDA 設計工具與應用工具鏈開發:隨著存算一體芯片 從 0 到 1 的突破,已驗證了其在 AI 應用中的發展潛力與市場前景,進而吸引上下游企業的加入,催生相應的自動化 EDA 設計工具、開發環境、仿真器、編譯工具與智能算法的協同發展,縮短芯片的研發周期與應用開發周期,進而推動開源與標準生態的建立與繁榮,形成良性循環,加速存算一體芯片的規模化量產與應用。
綜上所述,當前的存算一體芯片研究集中在單點技術,且在器件、電路、架構、EDA工具及系統應用等方面仍然存在諸多技術待解決。
另外,從技術的角度,存算一體芯片未來的研究將圍 繞新型器件優化、低功耗數模混合電路設計、高性能異構芯片架構、先進集成與封裝、工具鏈開發等。
-
處理器
+關注
關注
68文章
19395瀏覽量
230673 -
存儲器
+關注
關注
38文章
7524瀏覽量
164147 -
算力
+關注
關注
1文章
1009瀏覽量
14899 -
存算一體
+關注
關注
0文章
102瀏覽量
4315
原文標題:打破算力極限,存算一體技術并駕齊驅
文章出處:【微信號:奇普樂芯片技術,微信公眾號:奇普樂芯片技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
存算一體大算力AI芯片將逐漸走向落地應用
比存算一體更進一步,“感存算一體化”前景如何?
探索存內計算—基于 SRAM 的存內計算與基于 MRAM 的存算一體的探究


知存科技數模混合存算一體AI芯片專利解析







 工商網監
工商網監
評論