 電子發燒友App
電子發燒友App


ChatGPT開啟大模型“軍備賽”,存儲作為計算機重要組成部分明顯受益:?
ChatGPT開啟算力軍備賽,大模型參數呈現指數規模,引爆海量算力需求,模型計算量增長速度遠超人工智能硬件算力增長速度,同時也對數據傳輸速度提出了更高的要求。XPU、內存、硬盤組成完整的馮諾依曼體系,以一臺通用服務器為例,芯片組+存儲的成本約占70%以上,芯片組、內部存儲和外部存儲是組成核心部件;存儲是計算機的重要組成結構,“內存”實為硬盤與CPU之間的中間人,存儲可按照介質分類為ROM和RAM兩部分。
存算一體,后摩爾時代的必然發展:?
過去二十年中,算力發展速度遠超存儲,“存儲墻”成為加速學習時代下的一代挑戰,原因是在后摩爾時代,存儲帶寬制約了計算系統的有效帶寬,芯片算力增長步履維艱。因此存算一體有望打破馮諾依曼架構,是后摩時代下的必然選擇,存算一體即數據存儲與計算融合在同一個芯片的同一片區之中,極其適用于大數據量大規模并行的應用場景。存算一體優勢顯著,被譽為AI芯片的“全能戰士”,具有高能耗、低成本、高算力等優勢;存算一體按照計算方式分為數字計算和模擬計算,應用場景較為廣泛,SRAM、RRAM有望成為云端存算一體主流介質。
存算一體前景廣闊、漸入佳境:?
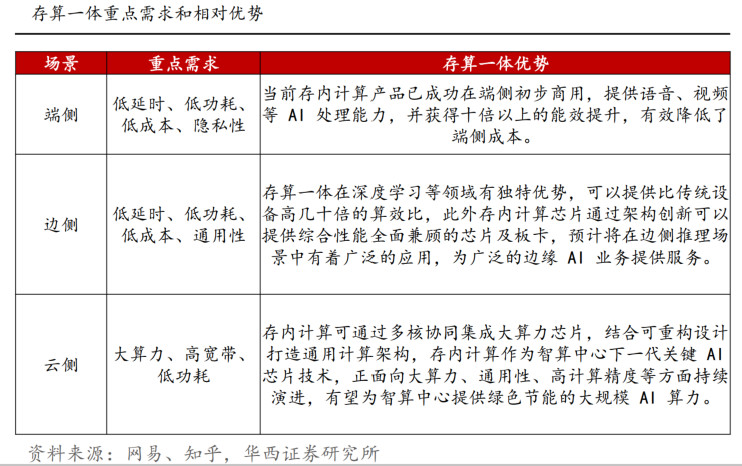
存算一體需求旺盛,有望推動下一階段的人工智能發展,原因是我們認為現在存算一體主要AI的算力需求、并行計算、神經網絡計算等;大模型興起,存算一體適用于從云至端各類計算,端測方面,人工智能更在意及時響應,即“輸入”即“輸出”,目前存算一體已經可以完成高精度計算;云端方面,隨著大模型的橫空出世,參數方面已經達到上億級別,存算一體有望成為新一代算力因素;存算一體適用于人工智能各個場景,如穿戴設備、移動終端、智能駕駛、數據中心等。我們認為存算一體為下一代技術趨勢并有望廣泛應用于人工智能神經網絡相關應用、感存算一體,多模態的人工智能計算、類腦計算等場景。
01.?存算一體,開啟算力新篇章
1.1 ChatGPT開啟大模型“軍備賽”,算力呈現明顯缺口
ChatGPT開啟算力軍備賽:?我們已經在《ChatGPT: 百度文心一言暢想》中證明數據、平臺、算力是打造大模型生態的必備基礎,且算力是訓練大模型的底層動力源泉,一個優秀的算力底座在大模型(AI算法)的訓練和推理具備效率優勢;同時,我們在《ChatGPT打響AI算力“軍備戰”》中證明算力是AI技術角逐“入場券”,其中AI服務器、AI芯片等為核心產品;此外,我們還在《ChatGPT ,英偉達DGX引爆AI “核聚變”》中證明以英偉達為代表的科技公司正在快速補足全球AI算力需求,為大模型增添必備“燃料”。
大模型參數呈現指數規模,引爆海量算力需求:?根據財聯社和OpenAI數據,ChatGPT浪潮下算力缺口巨大,根據OpenAI數據,模型計算量增長速度遠超人工智能硬件算力增長速度,存在萬倍差距。運算規模的增長,帶動了對AI訓練芯片單點算力提升的需求,并對數據傳輸速度提出了更高的要求。根據智東西數據,過去五年,大模型發展呈現指數級別,部分大模型已達萬億級別,因此對算力需求也隨之攀升。
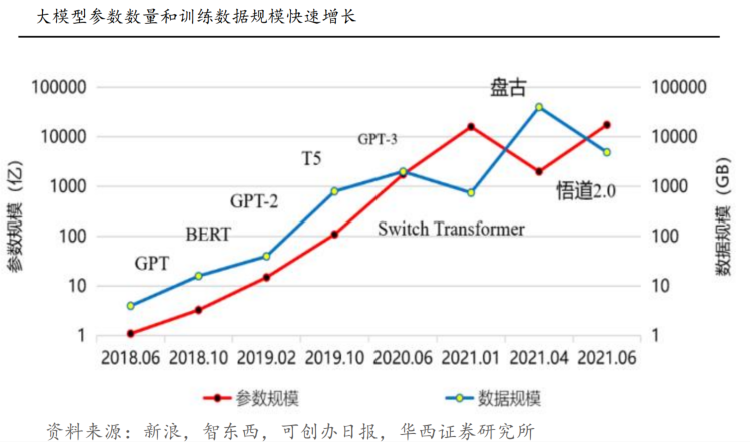
資料來源:新浪,智東西,可創辦日報,華西證券研究所
1.2 深度拆解服務器核心硬件組成部分
服務器的組成:?我們以一臺通用服務器為例,服務器主要由主板、內存、芯片組、磁盤、網卡、顯卡、電源、主機箱等硬件設備組成;其中芯片組、內部存儲和外部存儲是組成核心部件。
GPU服務器優勢顯著: GPU服務器超強的計算功能可應用于海量數據處理方面的運算,如搜索、大數據推薦、智能輸入法等,相較于通用服務器,在數據量和計算量方面具有成倍的效率優勢。此外,GPU可作為深度學習的訓練平臺,優勢在于1、GPU 服務器可直接加速計算服務,亦可直接與外界連接通信;2、GPU服務器和云服務器搭配使用,云服務器為主,GPU服務器負責提供計算平臺;3、對象存儲COS 可以為GPU 服務器提供大數據量的云存儲服務。
AI服務器芯片組價值成本凸顯:?以一臺通用服務器為例,主板或芯片組占比最高,大約占成本50%以上,內存(內部存儲+外部存儲)占比約為20%。此外,根據Wind及芯語的數據,AI服務器相較于高性能服務器、基礎服務器在芯片組(CPU+GPU)的價格往往更高,AI服務器(訓練)芯片組的成本占比高達83%、AI服務器(推理)芯片組占比為50%,遠遠高于通用服務器芯片組的占比。
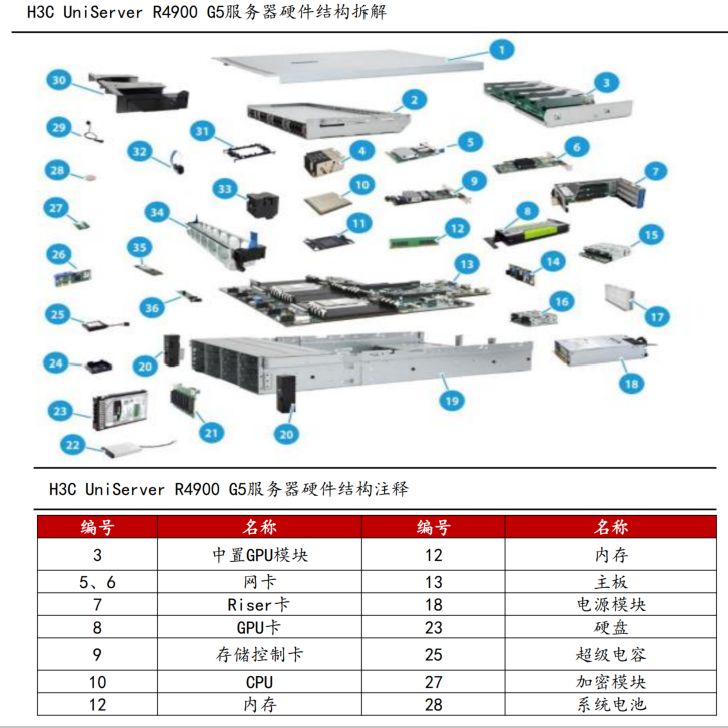
資料來源:H3C UniServer R4900 G5技術白皮書,華西證券研究所
1.3 存儲,計算機的重要組成結構
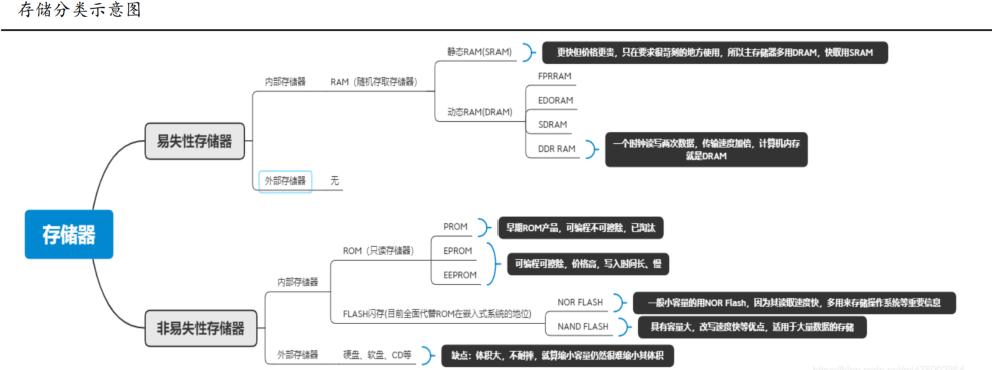
存儲是計算機的重要組成結構:?存儲器是用來存儲程序和數據的部件,對于計算機來說,有了存儲器才有記憶功能,才能保證正常工作。存儲器按其用途可分為主存儲器和輔助存儲器,主存儲器又稱內存儲器(簡稱內存),輔助存儲器又稱外存儲器(簡稱外存)。
內存:?主板上的存儲結構,與CPU直接溝通,并用其存儲數據的部件,存放當前正在使用的(即執行中)的數據和程序,一旦斷電,其中的程序和數據就會丟失;
外存:?磁性介質或光盤,像硬盤,軟盤,CD等,能長期保存信息,并且不依賴于電力來保存信息。
XPU、內存、硬盤組成完整的馮諾依曼體系: “內存”實為硬盤與CPU之間的中間人,CPU如果直接從硬盤中抓數據,時間會太久。所以“內存”作為中間人,從硬盤里面提取數據,再讓CPU直接到內存中拿數據做運算。這樣會比直接去硬盤抓數據,快百萬倍;CPU里面有一個存儲空間Register(寄存器),運算時,CPU會從內存中把數據載入Register, 再讓Register中存的數字做運算,運算完再將結果存回內存中,因此運算速度Register > 內存> 硬盤,速度越快,價格越高,容量越低。
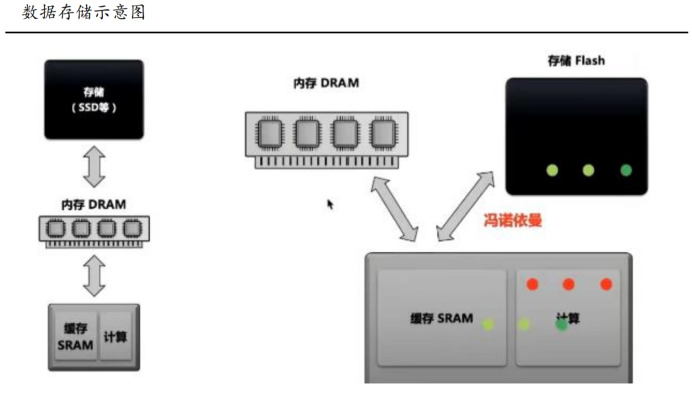
資料來源:CSDN,華西證券研究所
存儲按照易失性分類:?分別為ROM(只讀存儲器)是Read Only Memory的縮寫,RAM(隨機存取存儲器)是Random Access Memory的縮寫。ROM在系統停止供電的時候仍然可以保持數據,而RAM通常都是在掉電之后就丟失數據,典型的RAM就是計算機的內存。
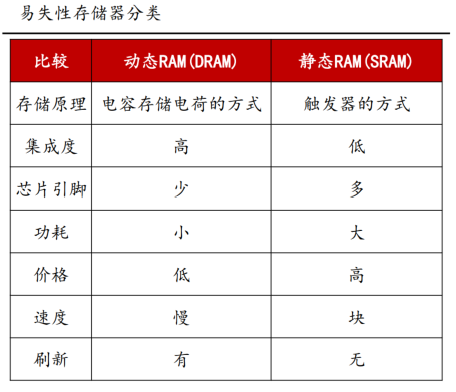
RAM(隨機存取存儲器)作為內存架構廣泛應用于計算機中:是與中央處理器直接交換數據的內部存儲器。可以隨時讀寫且速度很快,通常作為操作系統或其他正在運行中的程序的臨時資料存儲介質。RAM可分為靜態SRAM與動態DRAM,SRAM速度非常快,是目前讀寫最快的存儲設備了,但是價格昂貴,所以只在要求很苛刻的地方使用,譬如CPU的一級緩沖,二級緩沖;DRAM保留數據的時間很短,速度也比SRAM慢,不過比任何的ROM都要快,但從價格上來說DRAM相比SRAM要便宜,因此計算機內存大部分為DRAM架構;
ROM(只讀存儲器)作為硬盤介質廣泛使用: Flash內存的存儲特性相當于硬盤,它結合了ROM和RAM的長處,不僅具備了電子可擦除可編程的性能,還不會斷電丟失數據同時可以快速讀取數據,近年來Flash已經全面替代傳統ROM在嵌入式系統的定位,目前Flash主要有兩種NOR Flash和NAND Flash。Nand-flash存儲器具有容量較大,改寫速度快等優點,適用于大量數據的存儲,因此被廣泛應用在各種存儲卡,U盤,SSD,eMMC等等大容量設備中;NOR-Flash則由于特點是芯片內執行,因此應用于眾多消費電子領域。
資料來源:CSDN,華西證券研究所
1.4 存算一體,后摩爾時代的必然發展
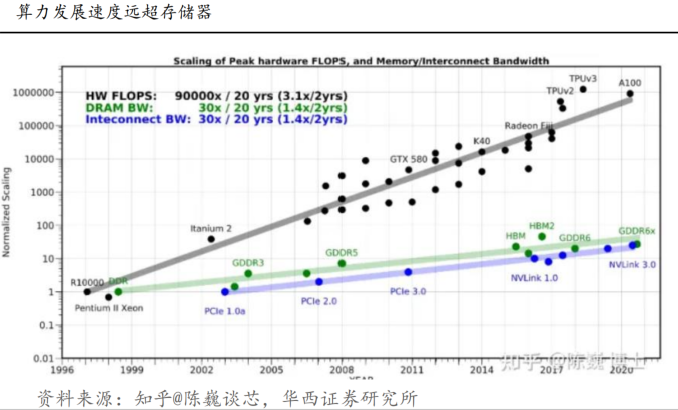
算力發展速度遠超存儲,存儲帶寬限制計算系統的速度:?在過去二十年,處理器性能以每年大約55%的速度提升,內存性能的提升速度每年只有10%左右。因此,目前的存儲速度嚴重滯后于處理器的計算速度。能耗方面,從處理單元外的存儲器提取所需的時間往往是運算時間的成百上千倍,因此能效非常低;“存儲墻”成為加速學習時代下的一代挑戰,原因是數據在計算單元和存儲單元的頻繁移動。
存儲墻、帶寬墻和功耗墻成為首要限制關鍵:?在傳統計算機架構中,存儲與計算分離,存儲單元服務于計算單元,因此會考慮兩者優先級;如今由于海量數據和AI加速時代來臨,不得不考慮以最佳的配合方式為數據采集、傳輸、處理服務,然而存儲墻、帶寬墻和功耗墻成為首要挑戰,雖然多核并行加速技術也能提升算力,但在后摩爾時代,存儲帶寬制約了計算系統的有效帶寬,芯片算力增長步履維艱。
存算一體有望打破馮諾依曼架構,是后摩時代下的必然選擇:?存算一體是在存儲器中嵌入計算能力,以新的運算架構進行二維和三維矩陣乘法/加法運算。存內計算和存內邏輯,即存算一體技術優勢在于可直接利用存儲器進行數據處理或計算,從而把數據存儲與計算融合在同一個芯片的同一片區之中,可以徹底消除馮諾依曼計算架構瓶頸,特別適用于深度學習神經網絡這種大數據量大規模并行的應用場景。
資料來源:知乎@陳巍談芯,華西證券研究所
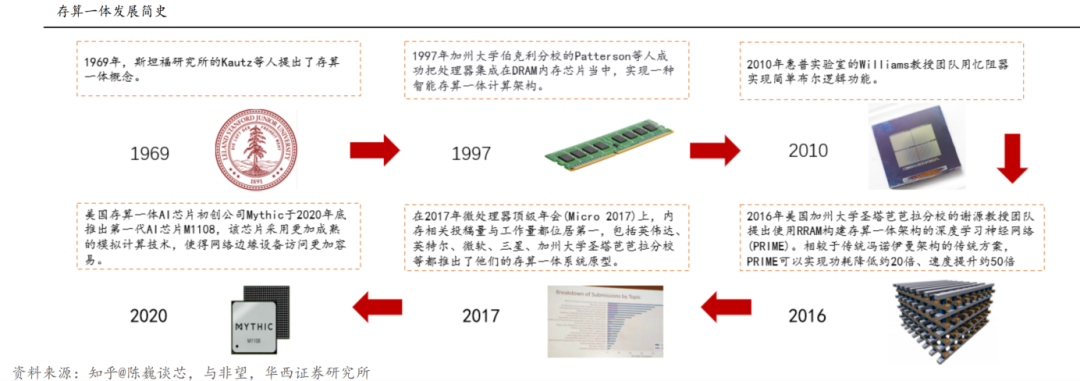
存算一體概念已有50年歷史:早在1969年,斯坦福研究所的Kautz等人提出了存算一體計算機的概念。但受限于當時的芯片制造技術和算力需求的匱乏,那時存算一體僅僅停留在理論研究階段,并未得到實際應用。然而為了打破馮諾依曼架構,降低“存儲-內存-處理單元”過程數據搬移帶來的開銷, 業內廣泛采用3D封裝技術實現3D堆疊提供更大帶寬,但是并沒有改變數據存儲與數據處理分離的問題;
近年來,存算一體隨著人工智能的驅動得到較快發展:?隨著半導體制造技術突破,以及AI等算力密集的應用場景的崛起,為存算一體技術提供新的制造平臺和產業驅動力。2016年,美國加州大學團隊提出使用RRAM構建存算一體架構的深度學習神經網絡(PRIME)。相較于傳統馮諾伊曼架構的傳統方案,PRIME可以實現功耗降低約20倍、速度提升約50倍;此外,2017年,英偉達、微軟、三星等提出存算一體原型;同年起,國產存算一體芯片企業開始“扎堆”入場,例如千芯科技、智芯微、億鑄科技、后摩時代、蘋芯科技等。
資料來源:知乎@陳巍談芯,與非望,華西證券研究所
1.5 存算一體: AI芯片的“全能戰士”
存算一體優勢顯著,被譽為AI芯片的“全能戰士”其優勢如下:?
1、成百上千倍的提高計算效率,降低成本:存算一體的優勢是打破存儲墻,消除不必要的數據搬移延遲和功耗,使用存儲單元提升算力;
2、特定領域提供更高算力與能效:存算一體架構消除了計算與存儲的界限,直接在存儲器內完成計算,因此屬于非馮諾伊曼架構,在特定領域可以提供更大算力(1000TOPS以上)和更高能效(超過10-100TOPS/W),明顯超越現有ASIC算力芯片;
3、存算一體代表了未來AI計算芯片的主流架構: 除AI計算外,存算技術也可用于感存算一體芯片和類腦芯片,可減少不必要的數據搬運與使用存儲單元參與邏輯計算提升算力,原因在于等效于在面積不變的情況下規模化增加計算核心數。
目前存算技術按照歷史路線順序演進:
A、查存計算: GPU中對于復雜函數就采用了這種計算方法,通過在存儲芯片內部查表來完成計算操作,目前應用較為廣闊,且技術相較成熟;
B、近存計算: 計算操作由位于存儲區域外部的獨立計算芯片/模塊完成。這種架構設計的代際設計成本較低,適合傳統架構芯片轉入。例如AMD的Zen系列CPU、三星的HBM-PIM、特斯拉Dojo(AI訓練計算機)、阿里達摩院等,近存計算技術早已成熟,被廣泛應用在各類CPU和GPU上;
C、存內計算: 計算操作由位于存儲芯片/區域內部的獨立計算單元完成,存儲和計算可以是模擬的也可以是數字的。這種路線一般用于算法固定的場景算法計算,典型代表如Mythic、千芯科技、閃億、知存、九天睿芯等;
D、存內邏輯: 這種架構數據傳輸路徑最短,同時能滿足大模型的計算精度要求。通過在內部存儲中添加計算邏輯,直接在內部存儲執行數據計算。典型代表為TSMC和千芯科技等。
存算一體按照計算方式分為數字計算和模擬計算:?
模擬計算:?模擬存算一體通常使用FLASH、RRAM、PRAM等非易失性介質作為存儲器件,存儲密度大,并行度高,但是對環境噪聲和溫度非常敏感。模擬存算一體模型權重保持在存儲器中,輸入數據流入存儲器內部基于電流或電壓實現模擬乘加計算,并由外設電路對輸出數據實現模數轉換。由于模擬存算一體架構能夠實現低功耗低位寬的整數乘加計算,因此非常適合邊緣端AI場景。
數字計算:?隨著AI任務的復雜性和應用范圍增加,高精度的大規模AI模型不斷涌現。這些模型需要在數據中心等云端AI場景完成訓練和推理,產生巨大的算力需求,相比于邊緣端AI場景,云端AI場景具有更多樣的任務需求,因此云端AI芯片必須兼顧能效、精度、靈活性等方面以保證各種大規模AI推理和訓練;數字存算一體主要以SRAM和RRAM作為存儲器件,采用先進邏輯工藝,具有高性能高精度的優勢,且具備很好的抗噪聲能力和可靠性,因此較為適合在云端大算力高能效的商用場景。
02.?存算一體,打開海量應用空間
存算一體需求旺盛,有望推動下一階段的人工智能發展:?我們認為現在存算一體主要AI的算力需求、并行計算、神經網絡計算等,因此存算一體需求旺盛;以數據中心為例,百億億次(E級)的超級計算機成為各國比拼算力的關鍵點,為此美國能源部啟動了“百億億次計算項目”,我國則聯合國防科大、中科曙光等機構推出首臺E級超算,而E級超算面臨的主要問題為功耗過高、現有技術超算功率高達千兆瓦,需要一個專門的核電站來給它供電,而其中50%以上的功耗都來源于數據的“搬運”,本質原因是計算與存儲分離所致。
大模型興起,存算一體適用于從云至端各類計算: ChatGPT等“大模型”興起,本質即為神經網絡、深度學習等計算,因此,我們認為對算力需求旺盛;端測方面,人工智能更在意及時響應,即“輸入”即“輸出”,同時,隨著存算一體發展,存內計算和存內邏輯,已經可以完成高精度計算;云端方面,隨著大模型的橫空出世,參數方面已經達到上億級別,因此對算力的能耗方面考核更加嚴格,隨著SRAM和PRAM等技術進一步成熟,存算一體有望成為新一代算力因素,從而推動人工智能產業的發展。
資料來源:網易、知乎,華西證券研究所
編輯:黃飛
?


























 工商網監
工商網監
評論