

商湯科技算法平臺團隊和北京大學高能效實驗室聯合提出一種基于 FPGA 的快速 Winograd 算法,可以大幅降低算法復雜度,改善 FPGA 上的 CNN 性能。早在2016年,論文中的實驗使用了當時最優的多種 CNN 架構,已經實現了 FPGA 加速之下的最優性能和能耗。
摘要
近年來,卷積神經網絡(CNN)越來越廣泛地應用于計算機視覺任務。FPGA 因其高性能、低能耗和可重配置性成為 CNN 的有效硬件加速器而備受關注。但是,之前基于傳統卷積算法的 FPGA 解決方案通常受限于 FPGA 的計算能力(如 DSP 的數量)。本論文展示了快速的 Winograd 算法,該算法可以大幅降低算法復雜度,改善 FPGA 上的 CNN 性能。我們首先提出了一種新型架構在 FPGA 上實現 Winograd 算法。我們的設計利用行緩沖結構(line buffer structure)來高效重用不同 tile 的特征圖數據。我們還高效架構 Winograd PE 引擎,通過并行化啟動多個 PE。同時存在復雜的設計空間有待探索。我們提出一種分析模型,用于預測資源使用情況、推斷性能。我們使用該模型指導快速的設計空間探索。實驗使用了當前最優的 CNN,結果表明其實現了在 FPGA 上的最優性能和能耗。我們在 Xilinx ZCU102 平臺上達到了卷積層平均處理速度 1006.4 GOP/s,整體 AlexNet 處理速度 854.6 GOP/s,卷積層平均處理速度 3044.7 GOP/s,整體 VGG16 的處理速度 2940.7 GOP/s。
引言
深度卷積神經網絡(CNN)在多個計算機視覺任務上取得了優秀的性能,包括圖像分類、目標檢測和語義分割 [1, 2]。CNN 的高準確率是以極大的計算復雜度為代價的,因為它需要對特征圖中的所有區域進行綜合評估 [3, 4]。為了解決如此巨大的計算壓力,研究者使用 GPU、FPGA 和 ASIC 等硬件加速器來加速 CNN [5–17]。其中,FPGA 因其高性能、低能耗和可重配置性成為有效解決方案。更重要的是,使用 C 或 C++的高級綜合(High Level Synthesis,HLS)大幅降低了 FPGA 的編程障礙,并提高了生產效率 [18–20]。
CNN 通常包含多個層,每一層的輸出特征圖是下一層的輸入特征圖。之前的研究發現當前最優 CNN 的計算主要由卷積層主導 [6, 7]。使用傳統的卷積算法,則輸出特征圖中的每個元素要經多步乘積累加運算進行單獨計算。盡管之前使用傳統卷積算法的 FPGA 解決方案取得初步成功 [5–9, 11],但是如果算法更加高效,該解決方案的效率可能會更高。本文展示了使用 Winograd 算法的卷積算法 [21] 如何大幅降低算法復雜度,改善 FPGA 上的 CNN 性能。使用 Winograd 算法,利用元素之間的結構相似性生成輸出特征圖中的一列元素。這減少了乘法運算的數量,從而降低算法復雜度。研究證明快速的 Winograd 算法適合為具備小型濾波器的 CNN 推導高效算法 [16]。
更重要的是,CNN 的當前趨勢是帶有小型濾波器的深度拓撲。例如,Alexnet 的所有卷積層(除了第一層)都使用 3 × 3 和 5 × 5 濾波器 [3];VGG16 僅使用 3 × 3 濾波器 [22]。這為使用 Winograd 算法高效實現 CNN 創造了機會。但是,盡管在 FPGA 上使用 Winograd 算法很有吸引力,但仍然存在一些問題。首先,設計不僅要最小化內存帶寬要求,而且要匹配計算引擎與內存吞吐量。其次,在 FPGA 上映射 Winograd 算法時存在很大的設計空間。很難推斷哪些設計會改善性能,抑或損害性能。
本文設計了一種行緩沖結構為 Winograd 算法緩存特征圖。這允許不同的 tile 在卷積運算進行時重用數據。Winograd 算法的計算涉及通用矩陣乘法(GEMM)和元素級乘法(EWMM)的混合矩陣變換。然后,我們設計了一種高效的 Winograd PE,并通過并行化啟動多個 PE。最后,我們開發分析模型用于評估資源使用情況,并預測性能。我們使用這些模型探索設計空間,確定最優的設計參數。
本文的貢獻如下:
提出一種架構,可在 FPGA 上使用 Winograd 算法高效實現 CNN。該架構把行緩沖結構、通用和元素級矩陣乘法用于 Winograd PE 和 PE 并行化。
開發出分析性的資源和性能模型,并使用該模型探索設計空間,確定最優參數。
使用當前最優的 CNN(如 AlexNet 和 VGG16)對該技術進行嚴格驗證。
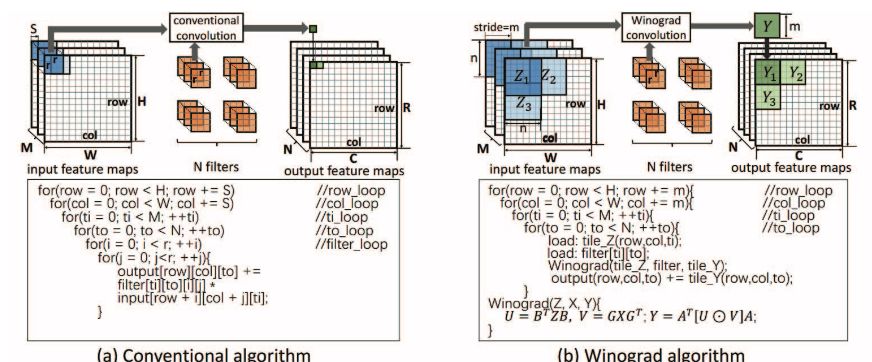
圖 1:傳統卷積算法和 Winograd 卷積算法的對比。我們假設 Winograd 算法的步幅 S 為 1。
架構設計
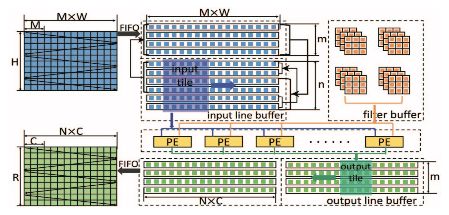
圖 2:架構圖示
圖 2 表示在 FPGA 上基于 Winograd 算法的卷積層架構。研究者在相鄰 tile 的特征圖中確定數據重用機會。最后,自然而然地實現了行緩沖。輸入特征圖 (M) 有多個通道,如圖 1 所示。行緩沖的每一行都存儲所有通道中同樣的一行。Winograd PE 從行緩沖中獲取數據。具體來說,給出一個 n×n 輸入 tile,Winograd PE 將生成一個 m × m 輸出 tile。研究者通過并行化多個通道的處理來啟動 PE 陣列。最后,使用雙緩沖(double buffer)重疊數據遷移和計算。所有輸入數據(如輸入特征圖、濾波器)最初都存儲在外部存儲器中。輸入和輸出特征圖通過 FIFO 被遷移至 FPGA。但是,濾波器的大小隨著網絡深度增加而顯著擴大。將所有濾波器加載到片上存儲器(on-chip memory)中是不切實際的。在本論文的設計中,研究者將輸入和輸出通道分成多組。每個組僅包含一部分濾波器。研究者在需要時按組加載濾波器。為方便陳述,下文中假設只有一組。
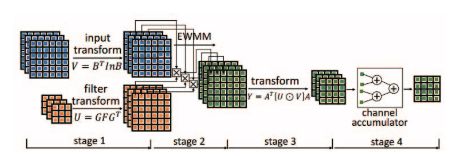
圖 3:Winograd PE 設計圖示
自動工具流程
研究者設計了一個自動工具流程將 CNN 自動映射至 FPGA,如圖 5 所示。該流程包括設計空間探索引擎(DSEE)。研究者使用 Caffe prototxt 來描述 CNN 的結構 [24]。FPGA 配置參數包括內存帶寬、DSP 數量、邏輯單元和片上內存容量。DSEE 的輸出是最優解 {n, Tm, Tn}。在步驟 2 中,基于最優解,研究者開發了代碼生成引擎(CGE),可自動生成 Winograd 卷積函數。該函數描述整個加速器結構,包括行緩沖、緩沖管理和 Winograd PE。生成的實現是 HLS 兼容的 C 代碼。編譯指令如內存分區因素、循環展開因素 Tn Tm 以及 FIFO 接口被插入函數中。步驟 3 中,研究者使用 Xilinx HLS 工具將代碼合成為寄存器傳輸級別。最后,研究者使用 Xilinx SDSoC(軟件定義片上系統)工具鏈來生成比特流。
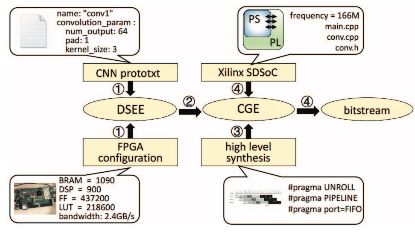
圖 4:自動工具流程
實驗評估

表 1:設計參數
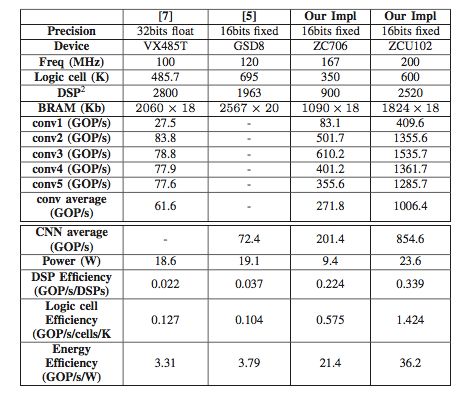
表 2:Alexnet 的性能對比
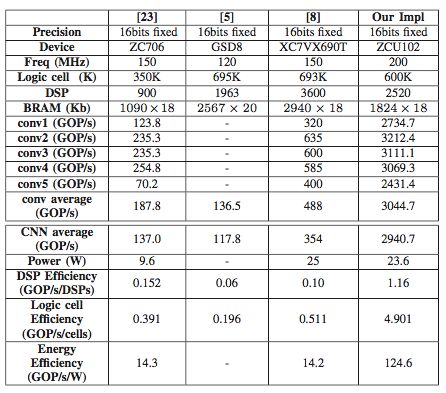
表 3:VGG 的性能對比
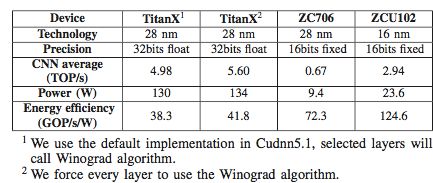
表 4:GPU 平臺對比
-
FPGA
+關注
關注
1638文章
21877瀏覽量
610627 -
算法
+關注
關注
23文章
4666瀏覽量
94162 -
cnn
+關注
關注
3文章
353瀏覽量
22544 -
商湯科技
+關注
關注
8文章
535瀏覽量
36487
原文標題:商湯聯合提出基于FPGA的快速Winograd算法:實現FPGA之上最優的CNN表現與能耗
文章出處:【微信號:SenseTime2017,微信公眾號:商湯科技SenseTime】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于紋理復雜度的快速幀內預測算法
如何降低LMS算法的計算復雜度,加快程序在DSP上運行的速度,實現DSP?
求一種基于802.16d的低復雜度的幀同步和定時同步聯合算法

圖像復雜度對信息隱藏性能影響分析
降低FBMC-OQAM峰均值比的低復雜度PTS算法
基于移動音頻帶寬擴展算法計算復雜度優化
基于I幀復雜度的初始量化參數(QP)選擇算法
虛擬MIMO中低復雜度功率分配算法
常見機器學習算法的計算復雜度
算法時空復雜度分析實用指南(上)
算法時空復雜度分析實用指南(下)





 工商網監
工商網監

評論