 探討篇(四):分布式數據訪問解決方案
探討篇(四):分布式數據訪問解決方案
背景
如果數據在同一個服務的同一個數據庫,通過SQL即可查詢相對比較簡單,但當數據被分布到不同服務不同的數據庫中時,訪問組合數據的操作就變的比較困難。針對這個問題,本文描述了服務讀取不同服務的數據庫的幾種方法:服務間通信模式、數據緩存模式、數據復制模式、數據共享模式
本文的觀點源自我在日常學習與實踐過程中的思考,尚處于不斷探索和驗證的階段。希望能“拋磚引玉”,激發更多的討論與交流。讓我們共同進步,在探討與實證中尋求真知。
一、服務通信模式
如果一個服務需要讀取它無法直接訪問的數據庫,只需要使用遠程調用比如RPC協議訪問另外一個服務即可,這也是很多團隊采用的一種方式,如下圖:
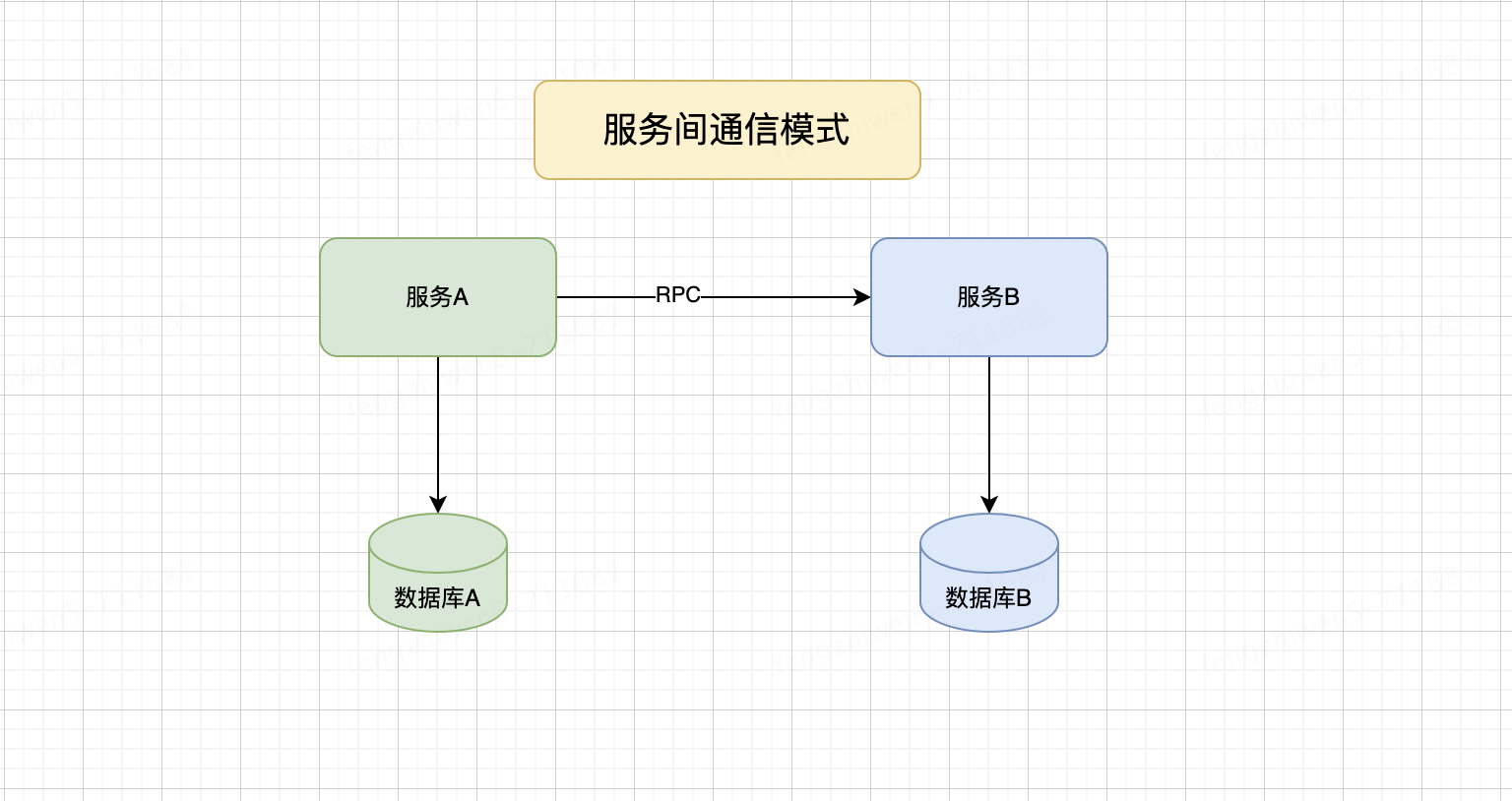
這看起來很簡單,但技術充滿挑戰問題
?首先是數據網絡延遲導致服務A性能下降。
?服務之間的耦合,為了滿足服務A的訪問量,B服務必須隨著A服務的流量規模變化而變化。
| 服務通信模式優缺點 | |
| 優點 | 1、沒有數據量問題 |
| 缺點 | 1、網絡延遲導致性能問題,很常見的TP99跳點,抖動現象 2、可伸縮性和吞吐量問題 3、可用性問題 |
二、數據緩存模式
在上面服務通信的基礎上加上緩存,這是很多團隊使用的第二種方式。數據保存在每個服務的內存中并持續同步,因此服務擁有完全相同的數據。緩存又分為本地緩存+分布式緩存的組合關系。
1.單機本地緩存,每個服務都包含自己的數據。這種模式對應服務之間無法共享,比如服務啟動加載數據到本地緩存。
2.分布式緩存:數據服務之間共享。但這種模式不是有效的復制緩存模式,因為它不能解決服務間通信模式下存在的容錯性問題,獲取數據從服務調用變成了緩存服務。其次由于緩存數據是中心化及共享的,打破數據所有權,并且可能導致緩存和數據庫數據不一致。
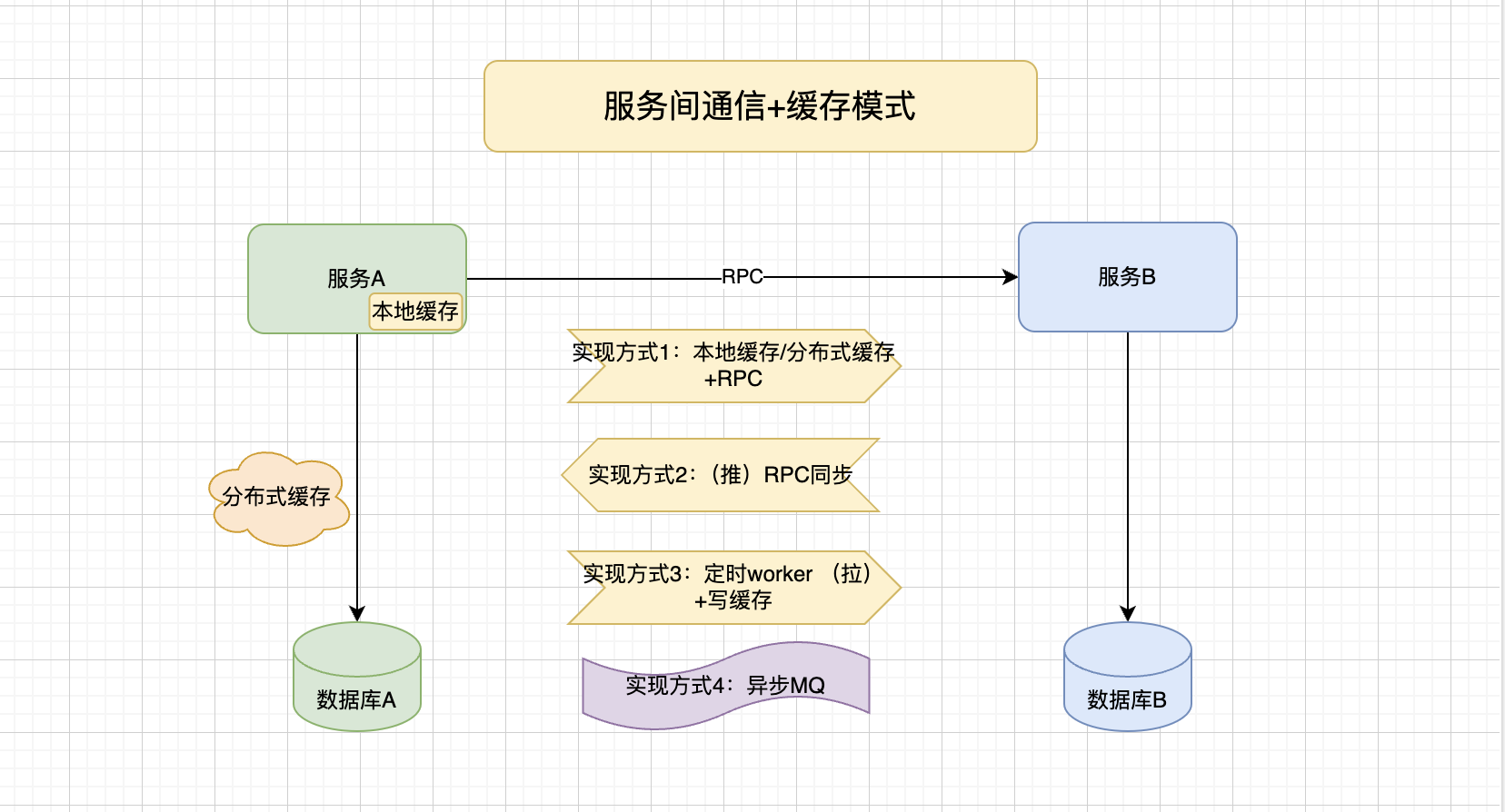
以下是每種實現方式優缺點如下:
實現方式一:本地緩存/分布式緩存+RPC遠程調用
| 實現方式一:緩存前置(本地緩存/分布式緩存+RPC遠程調用),它的核心思想是利用緩存來減少對遠程服務的調用次數,從而提高系統的性能和響應速度 | |
| 優點 | 1、減少延遲:通過從本地或分布式緩存中讀取數據,可以顯著減少對遠程服務的調用次數,從而降低響應時間和提高用戶體驗 2、減輕遠程服務壓力:緩存可以吸收大量讀請求,減少遠程服務的負載,特別是在高流量場景下。 |
| 缺點 | 1、數據一致性問題:緩存中的數據可能會過時,如果遠程服務的數據發生變化,緩存中的數據需要及時更新,否則可能會導致數據不一致。 2、復雜性增加:緩存策略的引入增加了系統的復雜性,需要考慮緩存更新、失效策略、數據一致性保證等問題。 3、資源消耗:緩存需要占用額外的存儲空間,如果數據量很大,緩存可能會消耗大量內存或磁盤空間。 |
實現方式二:通過RPC服務通訊同步推送數據+本地緩存
| 實現方式二:通過RPC服務通訊同步推送數據+本地緩存 | |
| 優點 | 1)實時性:服務B在數據發生變化時立即推送,服務A可以實時獲取最新數據。 2)資源利用率高:只有在數據發生變化時才會進行通信,減少了無謂的資源消耗。 3)減少輪詢壓力:避免了定時任務輪詢對服務器的壓力。 |
| 缺點 | 1)復雜性:需要在服務B中實現推送邏輯,增加了系統的復雜性。 2)維護成本:推送機制需要額外的維護,包括失敗重試、消息順序保證等 |
實現方式三:通過定時任務worker,服務A通過RPC調用服務B拉數據
| 實現方式三:通過定時任務worker,服務A通過RPC調用服務B拉數據 | |
| 優點 | 1)無需變更現有服務:不需要修改服務B的代碼,只需在服務A中添加定時任務。 |
| 缺點 | 1)性能開銷:頻繁的定時任務可能會對服務A和服務B的性能產生一定影響。 2)延遲性:數據更新可能存在延遲,特別是如果定時任務的頻率不高。 3)資源占用:即使沒有數據更新,定時任務也會占用系統資源。 4)靈活性差:如果數據更新頻率變化較大,固定周期的定時任務可能不夠靈活 |
實現方式四:通過異步MQ獲取數據
| 實現方式四:通過異步MQ獲取數據 | |
| 優點 | 1)異步、削峰、解耦:服務B在數據發生變化時只需發送消息,不需要等待服務A的處理結果。 2)容錯性:MQ通常提供消息持久化機制,即使服務A暫時不可用,消息也不會丟失。 |
| 缺點 | 1)復雜性:引入MQ增加了系統的復雜性,需要考慮消息的順序性、消息丟失、重復消費等問題。 2)延遲:雖然MQ可以提供實時消息傳遞,但在高并發或者網絡問題的情況下,仍然可能存在延遲。 |
緩存模式優缺點:
| 緩存模式優缺點 | |
| 優點 | 1、提高了數據訪問性能 2、沒有可伸縮性和吞吐量問題 3、良好容錯性 |
| 缺點 | 1、大數據量不友好(比如200M),可行性降低 2、高頻更新不友好,無法保持完全同步,對于相對靜態數據,比較合適 3、緩存數據和服務啟動的服務依賴關系。常見機器擴容N臺機器,N臺同時通過RPC訪問服務B,導致服務B流量暴漲,并且寫分布式緩存流量暴漲(N臺*每臺緩存大小) 4、適合一致性較弱的場景,緩存一致性問題,可能導致數據陳舊 |
三、數據復制模式
在數據復制模式中,表之間會進行數據復制,也就是在數據庫A冗余數據庫B數據。這樣可以確保服務A直接訪問數據庫A獲取到數據庫B的數據。可以通過很多種實現方式:
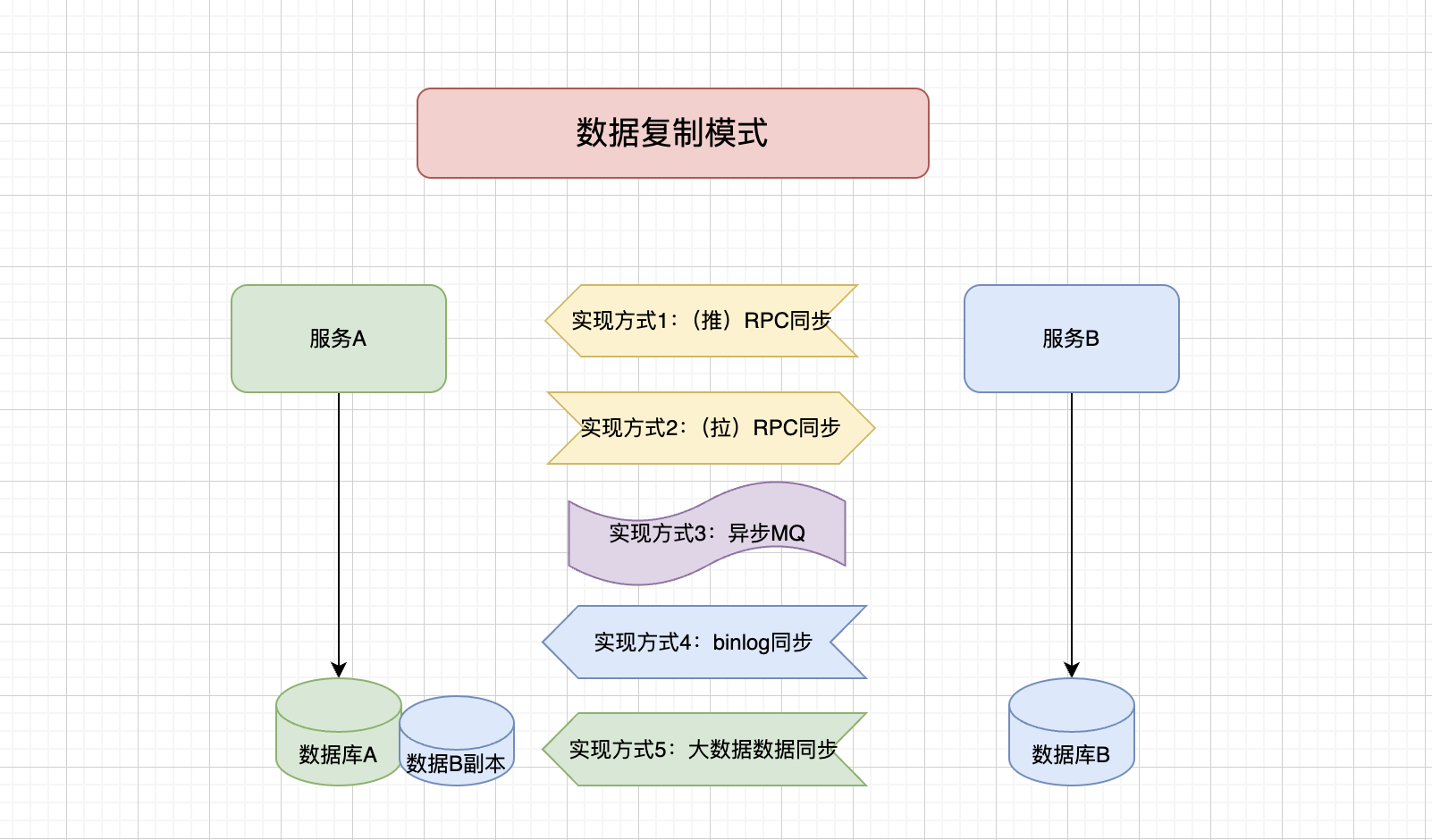
但這同樣存在如下問題:如何管理數據所有權?到處都有這種數據,數據一致性問題
| 實現方式四:binlog同步,需要注意binlog數據量 | |
| 優點 | 1)實時性:Binlog可以捕獲數據庫的實時變化,使得數據同步具有較低的延遲。 |
| 缺點 | 1)性能影響:雖然Binlog的開銷相對較小,但在高并發寫入的場景下,Binlog的生成和處理仍然會對數據庫性能產生一定影響。 2)依賴數據庫:這種同步方式依賴于MySQL的Binlog功能 |
這種方案改善了上面服務通信的性能,容錯性,可伸縮性問題。某些場景可用,比如聚合,報表或者其他不適合高性能需求,高容錯性的時候
| 數據復制模式優缺點 | |
| 優點 | 1、良好的數據訪問性能 2、沒有可伸縮性和吞吐量問題 3、沒有容錯性問題 4、沒有服務直接依賴 |
| 缺點 | 1、數據一致性問題 2、數據歸屬權問題 3、需要數據同步 |
四、數據共享模式
如果上面的3種方式都不行,那可以用兜底方式,用創建數據領域,把數據組合到共享的數據庫,讓服務A和服務B都能訪問。
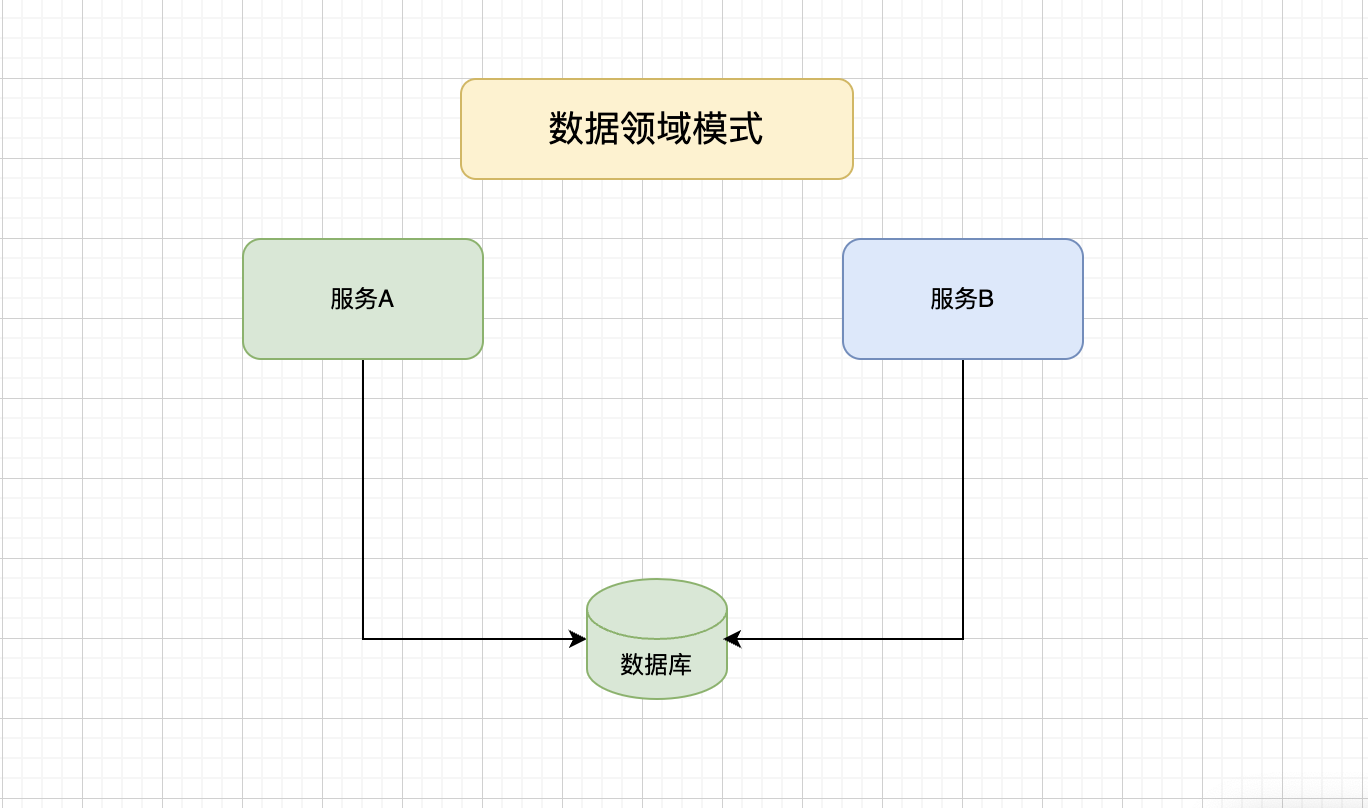
服務之間完全解耦,解決了可用性依賴,響應性,吞吐量和可伸縮性問題
| 數據庫共享模式優缺點 | |
| 優點 | 1、良好的數據訪問性能 2、沒有可伸縮性和吞吐量問題 3、良好容錯性 4、無服務依賴 5、數據保持一致 |
| 缺點 | 1、數據所有權治理 2、數據訪問安全 |
總結
1.通過本文的探討,大家可以更全面地了解分布式數據訪問的挑戰和可能的解決方案
2.每種模式都有其優勢和不足以及應用場景,本文旨在通過對比分析,為實際應用中的選擇提供指導。
3.如果以上文案有問題或者還有更好的方案,歡迎評論區留言補充完善,謝謝
審核編輯 黃宇
-
SQL
+關注
關注
1文章
767瀏覽量
44173 -
數據庫
+關注
關注
7文章
3822瀏覽量
64506 -
RPC
+關注
關注
0文章
111瀏覽量
11540 -
分布式
+關注
關注
1文章
908瀏覽量
74558 -
數據訪問
+關注
關注
0文章
9瀏覽量
6552
發布評論請先 登錄
相關推薦







 工商網監
工商網監
評論