 AI是把雙刃劍,HPC面臨的全新機遇與挑戰
AI是把雙刃劍,HPC面臨的全新機遇與挑戰
電子發燒友網報道(文/周凱揚)高性能計算也就是HPC(High Performance Computing),是一種利用超級計算機或高性能計算機集群的能力實現并行計算,以處理標準工作站無法完成的數據密集型計算任務的技術。現如今的HPC隨著芯片設計和AI技術的發展,也在邁向全新的道路,帶動整個HPC市場穩步增長。
HPC市場趨勢——需求與政策帶動市場穩步增長
據統計全球高性能計算市場規模在 2023 年達到569.8 億美元,預計到 2028 年將達到 967.9 億美元,在預測期間以 11.18% 的復合年增長率增長。過去幾年由于疫情、災難氣候等事件,推動了HPC的新需求。隨著HPC在云端部署和需求的增加,人工智能、數據分析上也面臨著快速處理數據、高精度日益增長的需求,包括生命科學、汽車、金融和航天航空等行業。
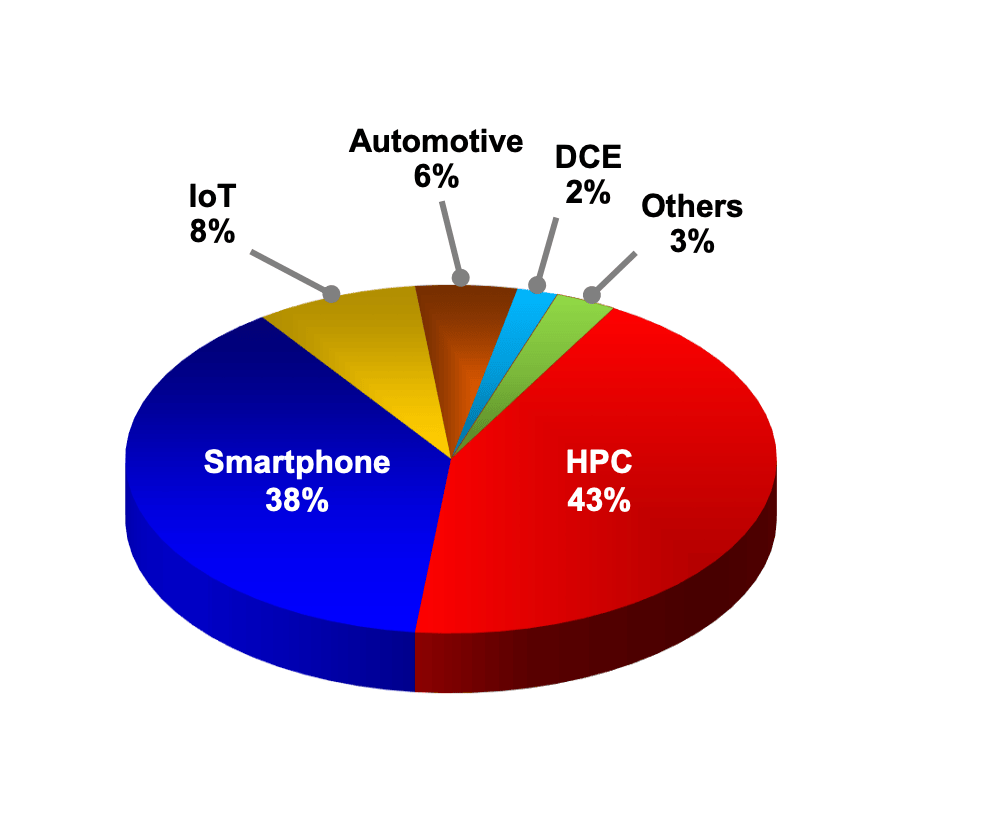
2023年不同平臺營收占比 / 臺積電
從上游晶圓廠的角度來看,HPC貢獻的營收已經穩定超過智能手機業務。以臺積電為例,其去年的HPC營收占比達到43%,已經是連續兩年超過智能手機業務營收了。臺積電CEO魏哲家預估,今年半導體產業產值將可望成長10%以上,晶圓代工產業將年成長20%,預期臺積電2024年在人工智能(AI)和HPC需求帶動下,全年營收有望實現20%以上的增長。
除了市場需求外,政策激勵也在促進HPC的市場發展。比如國內發布的《十四五規劃》中就提到,加快建設新型基礎設施,建設 E 級和 10E 級超級計算中心,并在合肥、蘭州、廈門、太原等地都將陸續建立高性能計算中心。
美國也發布了《保持美國高性能計算在E(百億億次級計算)時代的領先地位》這一指導文章,其中提到要落實芯片與科學法案中與HPC相關的投資與項目,增加能源部、區域創新中心超算項目的資助。
HPC不同應用的性能要求——不只是算力,I/O與時延同樣重要
HPC提供了超高浮點計算能力解決方案,可用于各種海量數據處理等業務的計算需求,比如各種傳統科學運算,常見的應用領域有基礎科研、氣象研究、制造仿真、材料計算、生命科學、地球物理等等。
除此之外,還有各種商業領域也得到了廣泛應用,比如動畫渲染、生物制藥和基因測序等等。相較于其他通用計算系統而言,HPC系統往往需要對單一應用做出特殊的優化,無論是硬件還是軟件。所以缺乏HPC系統彈性部署的同時,卻也代表著極致的性能。不同的應用往往會對HPC系統的性能提出截然不同的要求。
比如在動畫渲染中,關鍵參數為浮點算力、I/O性能,這是因為1.資產重、難度大的3D渲染,對緩存層的吞吐和I/O壓力極大。2.需要快速交付海量算力,縮短制作周期,比如《長津湖之水門橋》《流浪地球2》《三體》等作品,都用到了貴安超算中心的龐大算力。
在氣象研究中,關鍵參數為浮點算力、網絡時延。因為1.氣象觀測時空分辨率增加,氣象行業數據量大幅增長,處理能力有待提升。2.短臨預報精度較低,需要更低的時延。在工程仿真中,網絡時延、內存帶寬至關重要。因為操作過程中,1.三維交互較多,對時延要求高2.要求高并發存取,更高的內存帶寬可以顯著提高效率。
HPC上游產業鏈——x86依然占據主導,Arm崛起
在HPC市場中,上游產業鏈主要是HPC系統的計算處理資源,包括CPU、GPU、DPU和其他加速器。中游則涵蓋了服務器產品,以及對應的附屬資源,包括存儲、網絡設備、電源、冷卻設備等。下游則是把HPC系統投入應用的部署廠商,包括云服務廠商、超算中心和科研機構等等。
在上游產業鏈中,HPC系統最重要的莫過于CPU和GPU這兩大硬件。CPU廠商包括英特爾、AMD、英偉達、IBM、申威和龍芯中科等。GPU則包括英偉達、AMD、英特爾等廠商。DPU則包括英偉達、AMD、英特爾、亞馬遜、阿里巴巴、云豹智能、星云智聯。除此之外,HPC系統偶爾也會集成別的加速器設備,比如谷歌NPU,Cerebras的晶圓級AI處理器、景嘉微的景宏系列智算模塊等。
從占比的角度來看,x86 CPU在HPC系統中依然占據絕對的主導地位,具體產品以英特爾的Xeon系列CPU和AMD的EPYC系列CPU為主。除了本身的性能足夠強外,也少不了這么多年以來x86在HPC軟件生態上的積累。
不過隨著Arm架構在設計上的不斷創新,相關的產品也在層出不窮,比如基于Neoverse核心設計的英偉達Grace CPU、阿里倚天710、華為鯤鵬920,又或是依靠自研核心打造的富士通A64FX CPU、飛騰騰云S5000C等。而且隨著Arm打通了開發高性能計算生態,相關的計算庫和軟件也已經跟進了。
除了以上兩個架構外,還有其他架構的CPU也在超算領域嶄露頭角,比如RISC-V架構以及其他自研RISC架構,但除了IBM的Power架構外,相關的硬件與軟件生態都還不完善。

B200 GPU / 英偉達
在HPC系統所用到的加速器中,GPU占據了絕對的主導地位,其中市場份額最高的當數英偉達的高性能GPU產品。在時下性能排名靠前的HPC系統中,集成了英偉達發布跨度數年的產品,從Tesla 100到H100,英偉達的CUDA生態也已經在HPC軟件中得到應用。除此之外,英偉達也打造了自己的超算Earth-2,用于天氣預測。
其次是AMD的Instinct系列產品,充分利用了AMD的CDNA架構,為HPC系統提供強大的通用GPU計算性能。目前全球排名第一的超算系統Frontier,用到的就是AMD的MI250X GPU。
最后是英特爾數據中心GPU Max系列,使用該系列GPU的HPC系統不多,主要是搭配英特爾的Xeon處理器作為打包方案提供給客戶。
需要注意的是,之所以目前用于HPC的GPU系統幾乎只有這三家,是因為其提供了主流HPC應用所需的FP64精度支持。而近幾年發布的GPU,由于專注于AI計算和消費級應用上,大部分最高只支持到FP32。
HPC中游產業鏈——AI同時拔高了HPC系統的存儲與供電要求
在HPC服務器廠商中,市場份額占比最高的為HPE和戴爾兩家廠商,除此之外聯想、浪潮、中科曙光、IBM、Atos、富士通和NEC等,也推出了對應的產品解決方案。在HPC存儲器方案上,由于HPC系統的特殊文件系統,往往還是由服務器廠商提供解決方案,包括戴爾、IBM、HPE、聯想、DDN和希捷等。最后則是電源等附屬設備,HPC系統電源以臺灣供應商居多,包括臺達電子、光寶科技、康舒、群電、肯微等等。
AI和HPC相融合,對于HPC的存儲提出了新的要求,比如在接口上,雖然POSIX還是主流解決方案。但由于英偉達GPU在AI HPC系統中的廣泛使用,也出現支持GDS(GPU直接存儲)接口的存儲方案。除此之外,AI HPC往往有著處理海量小文件的需求,對存儲系統的擴展性要求較高。而且為了留存計算得到的臨時結果,需要一定的臨時存儲空間需求。
就HPC系統的發展來看,目前的趨勢是處理器的功耗每兩年翻一番。2000A 的峰值電流現在已經很普遍。但隨著HPC系統功耗繼續升高,我們面臨的是更高的PUE要求。比如我國就要求新建成的服務器PUE要小于1.3。這不僅對電源效率提出了新的挑戰,也對散熱方案提出了更高的要求,未來液冷方案可能會成為HPC系統的主流散熱方案。
此外,AI HPC集群的供電要求更高。AI HPC系統的電源已經達到了3kW到4kW的區間,隨著氮化鎵和碳化硅技術在服務器電源領域的普及,未來可以支持到10kW級別的服務器電源。
超算市場的變與不變
超級計算機作為高性能計算的子集應用,代表了市面上最強大的計算系統。它們在進行特定的通用科學運算方面表現突出,但在處理一般計算工作時性能并不突出。據mordorintelligence預測,超級計算機市場規模預計到 2024 年將達到 121.0 億美元,預計到 2029 年將達到 121.5 億美元, 年復合增長率只有0.09%。雖然看起來市場增長不多,但政府和企業都在持續投入超算的部署。
超級計算機對一個國家的科學進步和國家安全作出了重大貢獻,能源中心、超級計算中心均使用超算來處理工作負載。不僅如此,超算也用來打造國家超算互聯網,接入第三方應用、數據、模型服務商,提供科學計算、工業仿真、人工智能模型訓練的商用,緩解算力供需矛盾。
在企業投入上,云服務廠商加大投入,尤其是將HPC與AI計算結合的超算系統,并已經成為為HPC市場增長的主要貢獻者。為了解決超算系統利用率低的問題,云服務廠商在服務器資源規劃和靈活部署上采用了新的設計。
接著我們來看看TOP500超算榜單中的前十名,從23年11月公布的TOP500超算榜單中可以看出,中國已公開成績的最強超算,神威太湖之光已經掉出前十的行業。當然了,這是由于多方面因素造成的,其實國內已經至少有兩臺E級的超算了,只是出于各種原因并未提交成績。
其實還有不少私有HPC系統,已經在全速商用運行中,沒有必要花費時間來運行LINPACK測試。其實,從2017年起,除了最快的這一批TOP10系統每年都會有所更新外,TOP500每年的提交數量就一直在降低,這是因為新的超算部署成本越來越高,而且這兩年不少HPC硬件資源被優先投入進AIGC相關應用的開發中去。
HPC技術發展趨勢——AI與云化部署
現如今HPC面臨著兩大技術變革,AI與云化部署。AI增強了數據集分析,在相同準確度水平下可以更快地獲取結果。從新部署的一批HPC系統硬件配置就可以看出,GPU提供的算力比重越來越高,所以也出現了HPC-MxP這樣專門針對AI性能進行測試的榜單,從榜單上也可以看出,通用算力和AI算力并不是一回事。
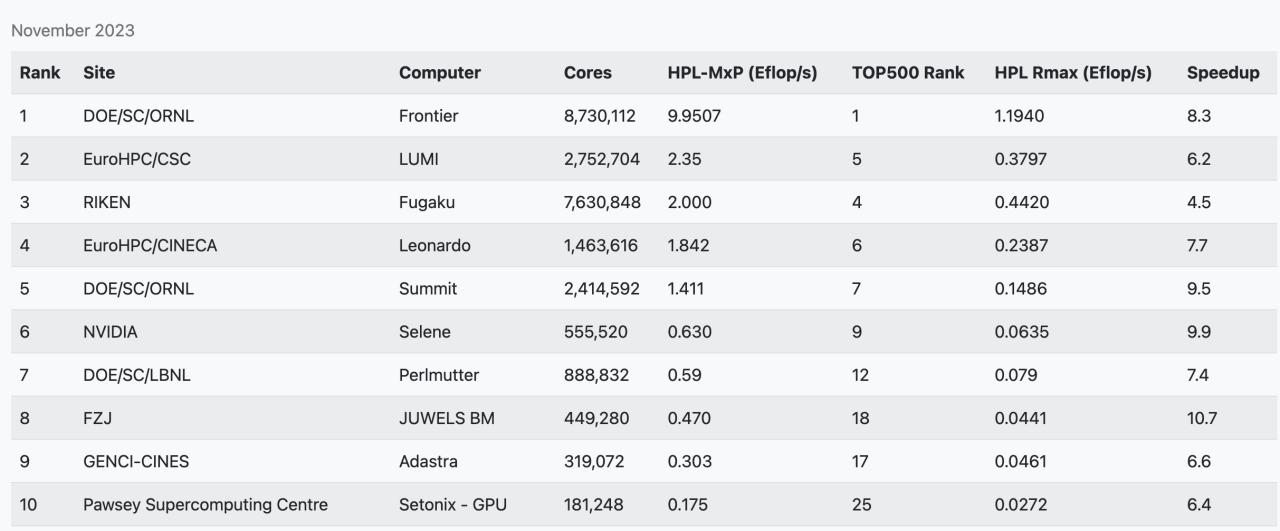
HPC-MxP 超算AI算力榜單
無論是在科學研究還是商業應用領域,都已經出現了對應的AI集成HPC軟件,包括1.金融服務分析、物流和制造計算 2.流體力學、計算機輔助工程和輔助設計 3.高能物理的可視化和仿真 4.天氣預報、氣象學等。
出現這種趨勢并不奇怪,近幾年GPU演進速度和算力提升速度遠遠高于CPU,不過HPC系統與這些大火的GPT、LLM應用不一樣的是,往往不會去追最新的GPU硬件,原因有二:
1.因為HPC集群規模較大,制造商下GPU訂單后,也需要不短的交期才能交付,而目前最新的GPU往往都交付給了云服務廠商;2.如今的GPU在高精度算力上的提升并不如低精度算力,這是因為目前最火的還是各類大模型應用,他們處理的往往是更低精度的數據。
第二個趨勢就是云化部署,傳統的本地HPC應用往往采用封閉機型和專屬架構,包括富岳、神威·太湖之光等,這類系統在計算密集類的應用上依然占據著很大的優勢,在科學研究類工作中仍被廣泛應用。然而在商業領域,云化部署的HPC運用受歡迎程度越來越高。
但正如上面提到的,新系統的成本越來越高,不僅是硬件成本,還有維護成本。再加上擴容困難、資源利用率較低等問題,把HPC系統轉換為數字資源并采用云化部署成了新的趨勢。
AWS、Azure、谷歌、阿里云和華為云等推出的HPC集群,為HPC云端部署提供了更加簡單的方案。云化部署簡化了HPC應用的部署和擴容過程,而且靈活的配置,和近乎無限的scale out拓展性,讓其無論是成本還是性能來說,對不少HPC應用而言都是最優解。當然對于國家研究中心之類的單位而言,為了信息安全等考量,本地HPC系統依然是部署的首要選擇。
HPC面臨的挑戰——成本與電力墻
盡管出現了各類創新,HPC市場依舊面臨著不小的挑戰。首先就是硬件成本的增加,AI的加入,使得HPC系統的總成本再度上了一個新臺階。為了在提高通用計算性能的同時,提高AI算力,大量使用GPU幾乎是唯一的出路。而且在目前AI GPU產能有限的情況下,對于一些科研HPC單位而言,獲取難度更大。
以H100 GPU為例,Meta、微軟、谷歌、Oracle、特斯拉等私有云、公有云廠商的擁有量更大,而且這些廠商仍在持續投入。從前十的超算排名中就能看出,不少國家HPC要么用到AMD或英特爾的GPU,要么采用A100或GV100之類的前代產品比如,單單Meta一家,就需要借助近60萬塊H100 GPU打造下一代GenAI應用,相較之下排名第三的Eagle超算,只集成了14400塊H100 GPU。
另一大挑戰就是電力墻。隨著計算能力的增加,硬件功耗也隨之增加,這導致了熱管理和電力供應方面的問題。對于大規模的HPC系統,比如數據中心計算集群和超算而言,電力和冷卻成本都會變得非常高。
我們拿排名靠前的幾大超算系統為例,其中富岳超級計算機的系統功耗在30到40MW之間,Frontier超級計算機的系統功耗22.7MW。為了推動HPC系統充分改善能效,減少碳足跡,Green500榜單被推出,以單位瓦數的峰值算力作為參考,為的就是促進設計廠商推出能效更高的硬件,以及應用開發商對HPC軟件進行進一步優化。
-
AI
+關注
關注
87文章
31077瀏覽量
269412 -
HPC
+關注
關注
0文章
317瀏覽量
23811 -
高性能計算
+關注
關注
0文章
82瀏覽量
13393
發布評論請先 登錄
相關推薦
12月微軟要聞速遞
“AI接吻”——AI技術的雙刃劍
動態海外住宅IP:全球訪問與數據安全的雙刃劍
探索出口美國480V變120V UL認證變壓器的新機遇

存力與算力并重:數據時代的雙刃劍
共話出海未來,共謀發展新篇—“生成式AI,解鎖出海新機遇”沙龍成功舉辦

拉丁美洲與加勒比地區:人工智能浪潮下的就業市場雙刃劍
平衡創新與倫理:AI時代的隱私保護和算法公平
蘋果AI服務在華面臨挑戰,尋求本土合作新機遇
華為歐洲游戲沙龍聚焦土耳其,共探市場新機遇
中軟國際攜手華海智匯共同探索智慧ICT市場新機遇
敦泰:布局高端產品,搶抓柔性OLED市場新機遇






 工商網監
工商網監
評論