 星脈網絡深度解析:GOR全鏈路流量規劃與擁塞控制機制
星脈網絡深度解析:GOR全鏈路流量規劃與擁塞控制機制
轉載自:
作者:Rock、付博睿
前言
DCN(Data Center Network)數據中心網絡是現代信息技術基礎設施的重要組成部分。它提供了連接與通信的基礎,支撐數據中心內外部各種應用和服務。作為一個復雜的網絡系統,DCN承載著大量數據流量和通信需求,為AI、大數據、云計算等關鍵技術提供基礎底座。
在傳統DCN中,CPU被用作核心來處理復雜的計算任務和少量數據。然而,隨著AI人工智能的迅速發展,GPU的重要性日益凸顯。作為一種高度并行的硬件加速器,GPU非常適合處理AI所需的大量數據。AI的快速發展不僅增加了對GPU計算能力的需求,還對網絡的傳輸和穩定性提出了新的挑戰,傳統的DCN已經無法滿足AI大模型訓練的需求。在這個背景下,傳統的以CPU為核心的DCN正在向全新的以GPU為核心的星脈AI高性能網絡演進升級。騰訊星脈AI高性能網絡專為AI大模型而設計,提供大帶寬、高利用率以及零丟包的高性能網絡服務,以保障AI大模型的訓練效率。星脈AI高性能網絡架構如圖1所示,包括:高速自研交換機、端網協同的擁塞控制+負載均衡TiTa+GOR(Global Optimized Routing)、高性能集合通信庫TCCL(Tencent Collective Communication Library)以及端到端運營系統GOM(Global Optimized Monitoring)。
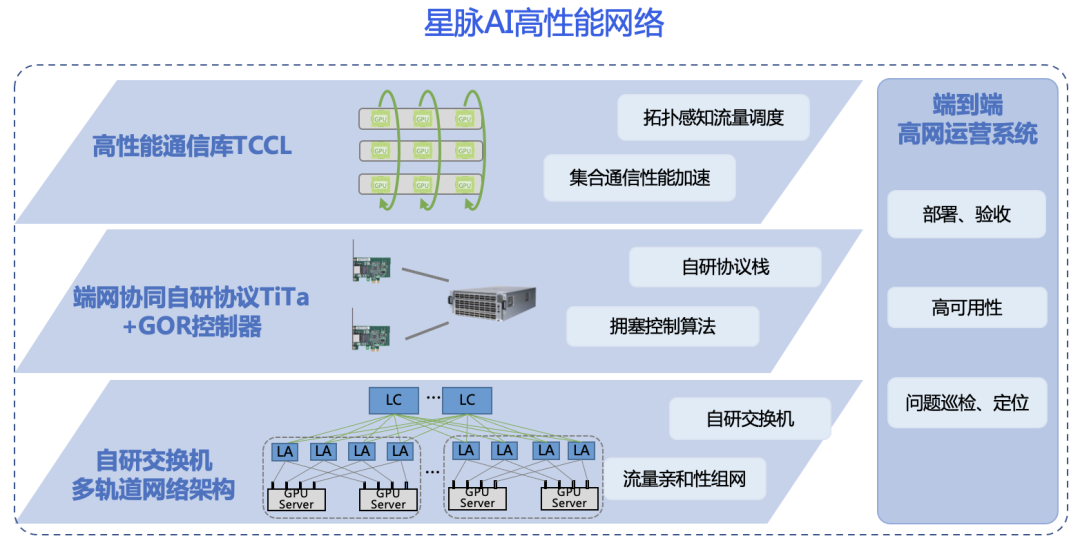
圖1.星脈AI高性能網絡 在傳統DCN中,我們已經廣泛應用網絡控制器來實現網絡變更灰度和路由監控,以確保網絡的穩定性,此時的控制器叫做DCN控制器1.0。然而,在星脈AI高性能網絡中,由于AI大模型訓練需要處理大量的數據,同時各種并行模式和加速框架也引入了海量的通信需求,因此為了保證AI大模型訓練的效率,超高速且無擁塞的網絡成為至關重要的前提條件。在這個背景下,我們將網絡控制器進一步演進升級到DCN控制器2.0—GOR控制器。GOR是星脈AI高性能網絡的關鍵技術之一,通過GOR控制器的精細控制,實現網絡流量合理規劃和動態調整,從而達到超低時延與超高帶寬,保障AI大模型訓練效率。
DCN控制器1.0,網絡穩定性的守護者
網絡變更灰度:DCN中網絡設備數量多、組網復雜、流量復雜,并且單臺設備承載的流量大。日常運營中經常涉及設備的維修替換,這就需要處理設備從在線到隔離再到重上線的過程。設備處于隔離狀態時沒有入向流量,從隔離狀態轉換到重上線狀態過程中重新對外引流。此時如果設備有問題(硬件、配置等),影響的用戶范圍非常廣,穩定性風險很高。因此我們在實際運營中,使用DCN控制器將少部分流量引到隔離設備上。通過觀察灰度流量是否正常來判斷設備是否正常。如果灰度流量有問題則快速回滾,將故障影響面控制到最小,保證網絡的穩定性。
路由監控:路由監控的目標是對DCN內外網路由進行采集、監控,對不符合預期的路由進行提前告警和控制,優化路由自動管理,提前發現網絡故障隱患。DCN承載的業務復雜多樣,內、外網路由策略各不相同,甚至部分業務還對路由存在特殊需求,因此如何確保各種場景下海量路由的正確性,是網絡運營的一個重要挑戰。 在路由監控中,DCN控制器與網絡設備建立BGP鄰居,收集設備上的路由,按照各種功能和業務需求進行監控:功能類監控面向通用場景,支持不同維度路由查詢、回溯,監控特定路由(特定大段路由、匯總路由)等;業務類監控針對具體業務,路由的產生者是業務網關,不同業務路由策略各不相同,包括主備路由監控、anycast路由監控、路由震蕩監控、公網路由掩碼監控以及路由來源監控等。通過多維度的路由監控,確保網絡的正確性、一致性。
星脈GOR控制器(DCN控制器2.0),網絡流量工程的領航員
AI網絡中的數據流就好像拉力賽道上飛馳的賽車,在賽道上高速前進。但是由于賽道的寬度有限,如果一條賽道上同時有多輛賽車,那么賽車就需要降低速度來避免碰撞;AI網絡中的數據流也類似,如果一條網絡鏈路上有多條數據流,那么不同流的總和容易超過鏈路的最大帶寬,從而出現擁塞導致流降速,最終影響AI大模型的訓練效率。為了避免上述沖突,拉力賽中需要領航員規劃賽車路線,避免多輛賽車同時通過賽道。此外在出現突發狀況時,領航員快速調整路線避免賽車間沖突碰撞,如圖2所示。在AI網絡中,我們也需要類似負責規劃與調度的領航員,這就是星脈網絡GOR控制器。一方面GOR控制器預先規劃網絡中數據流路徑,避免擁塞;另一方面在擁塞發生時(例如網絡鏈路故障),GOR控制器動態調度快速消除擁塞,從而保證AI大模型的訓練效率。
●AI大模型網絡特征 組網復雜。AI大模型網絡通常組網復雜、流量復雜。圖3分別是4K卡和16K卡集群的組網抽象圖。在如此復雜的網絡拓撲下,多任務并行以及相應的網絡流量規劃和網絡流量擁塞調度都面臨著極大的挑戰。
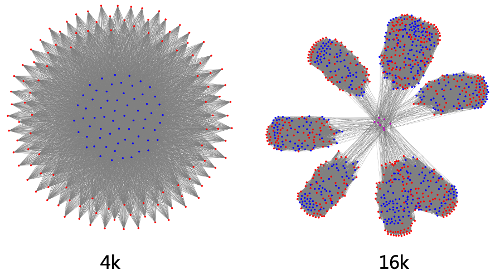
圖3.4K、16K卡集群組網抽象圖 局部負載不均。負載均衡是網絡領域的經典問題。如何均衡網絡流量、提高利用率、避免擁塞,從而保證業務質量是網絡持續追求的目標。雖然我們的網絡帶寬越來越大(設備交換芯片容量從6.4T、12.8T、25.6T到51.2T),但伴隨著業務的井噴式發展,服務器端側的帶寬也在快速增加(從10G、25G、100G到200G)。因此,大象流或者局部負載不均導致的網絡擁塞在DCN仍然很常見,尤其在AI網絡中問題更加突出。這是因為AI大模型業務特征是業務流數少,單流帶寬大。這種流量模型對網絡基于流Hash的負載均衡機制“并不友好”,容易造成局部熱點,從而產生擁塞。 我們在現網運營中觀察到很多AI網絡集群并不能達到理想的負載均衡,圖4是某個AI集群的網絡流量分布熱力圖,顏色越深代表鏈路上流量越大,可以看到明顯的負載不均。
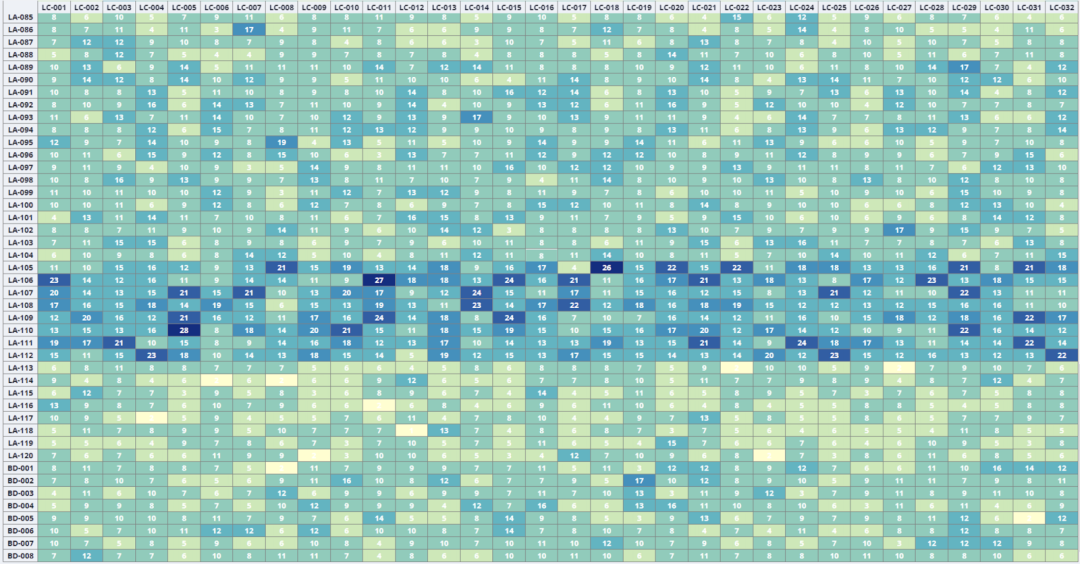
圖4. 網絡鏈路流量分布 AI網絡性能決定GPU集群算力,負載不均引起的網絡擁塞會導致有效帶寬降低、端側通信時長增加,從而影響AI大模型的訓練效率。我們可以采用多種指標衡量網絡擁塞,例如:擁塞計數、延時、帶寬占用率、緩存隊列等。從圖5可以看出,ECN計數突增的同時,伴隨端側計算通信時長顯著增加,嚴重降低AI大模型訓練效率、影響訓練成本。
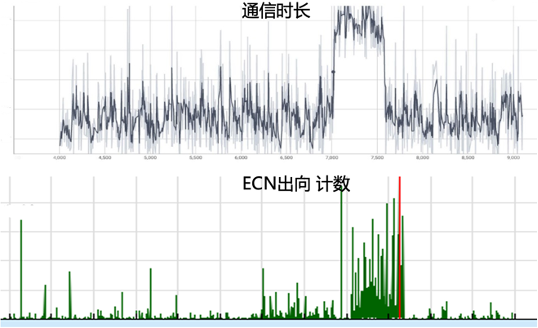
圖5.ECN計數與端側通信時長 流量可預測。AI大模型網絡流量具有高度可預測特性。從宏觀角度看,一旦AI大模型訓練任務啟動,我們可以提前確定哪些節點之間需要進行通信,以及在何時、如何進行通信;從微觀角度看,節點之間的通信數據流呈現出高度周期性的特點。圖6分別是RDMA QP(Queue Pair)維度和五元組數據流維度的趨勢圖,可以看到無論從單個QP還是多個QP聚合的五元組數據流維度統計,流量都呈現明顯的周期性。
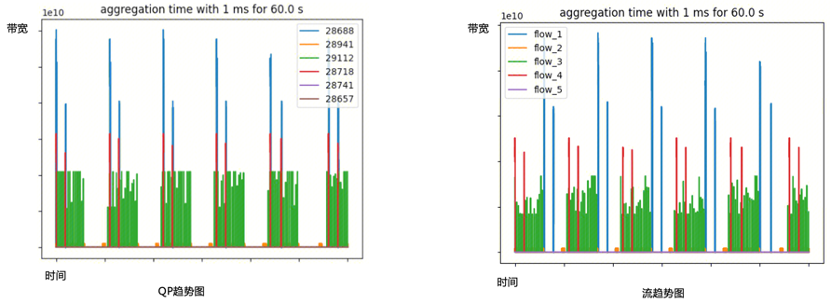
圖6.QP、流趨勢圖 ●GOR控制器設計 GOR控制器包括兩部分:訓練任務啟動前的預規劃以及訓練任務進行中的動態調度。預規劃階段,控制器通過結合全局網絡拓撲與任務信息,為每條業務流規劃最佳路徑;動態調度階段,將熱點區域的數據流進行調度換路,繞開擁塞,從而保障AI大模型的訓練效率。預規劃的目標是盡量減少、避免網絡擁塞;動態調度的目標是當擁塞發生時(例如網絡鏈路故障),通過對相關流進行動態換路來消除擁塞。線上數據表明,通過GOR控制器的調度,網絡擁塞時間縮短超過90%。 GOR控制器包括三個部分:采集、計算和調度/監控,總體控制流程如圖7所示。采集階段,GOR控制器通過分析秒級Telemetry數據找到出現擁塞的交換機端口以及業務流詳情,按照一定的策略選出需要調度走的業務流。
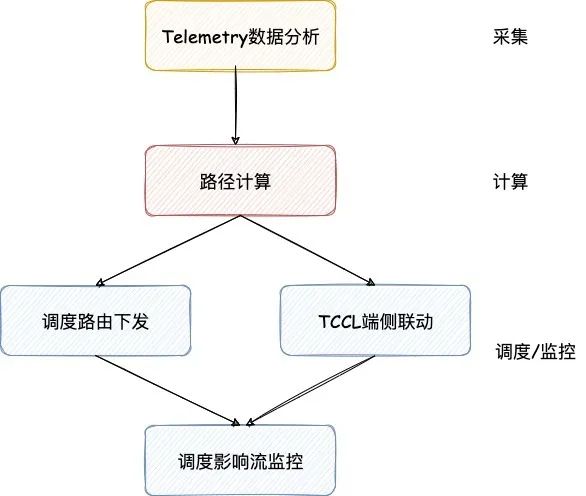
圖7. GOR控制器流程 路徑計算的核心訴求是結合網絡實時拓撲,為上一階段選出的每個要調度的流找到最優新路徑。同時要對新路徑進行容量評估,避免調度到新路徑后產生新的擁塞。 調度的方法是修改流路徑,具體有兩種方式:下發調度路由和TCCL端側聯動。下發調度路由方式中,控制器通過向網絡設備下發路由從而修改對應流路徑;TCCL端側聯動方式中,控制器與TCCL聯動修改流路徑,最終繞開出現擁塞的交換機端口。 調度下發后,控制器對影響的訓練任務流進行監控。當訓練任務結束后需要撤銷相應的調度路由,避免AI訓練任務變化后,之前下發的調度路由對新任務產生非預期的影響。 ●GOR控制器規劃、調度效果 GOR預規劃的目標是避免擁塞,保證端側通信速率,從而保障AI大模型訓練效率。預規劃階段,控制器為每條數據流進行高速算路,單條路徑計算時間在微秒級,萬條路徑計算時間小于1秒。圖8所示是千卡任務預規劃后的網絡鏈路流量分布,顏色越深代表鏈路上流量越大,顏色相近代表鏈路負載均衡,與圖4對比可以看到GOR預規劃對網絡負載均衡效果顯著。預規劃可以實現95%以上的業務均衡,在業務親和情況下可以實現近100%無擁塞。
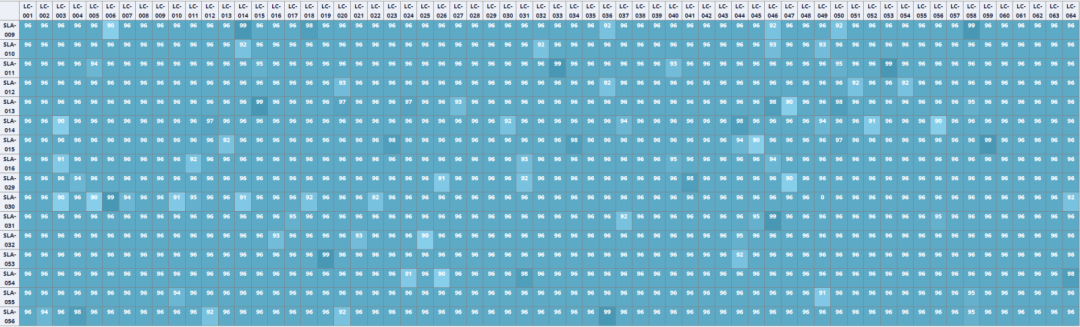
圖8.預規劃后網絡流量分布 預規劃提高網絡負載均衡度,從而保證端側通信速率。圖9是AllReduce通信模型下,GPU集群針對不同Message size預規劃前后的通信速率性能測試結果。可以看到GOR預規劃對端側通信速率提升明顯,AllReduce性能提升近20%。
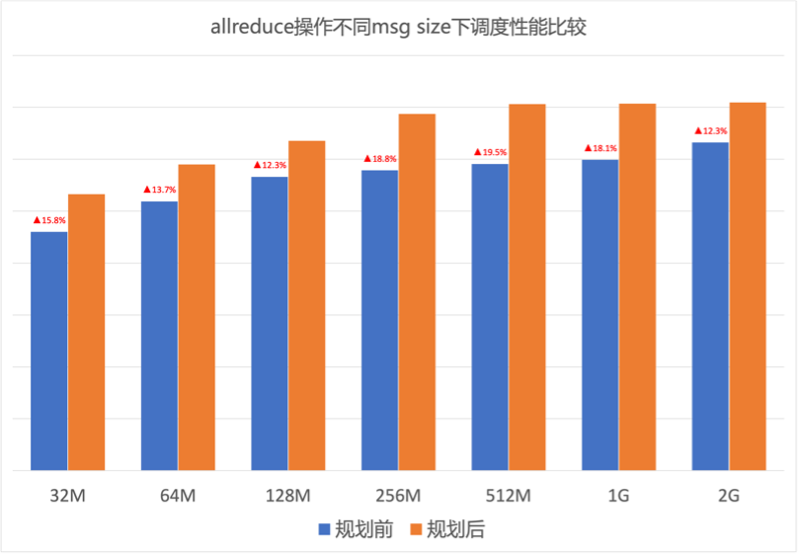
圖9.AllReduce性能對比 GOR動態調度的目標是當擁塞出現時快速消除擁塞。我們對線上某個AI網絡集群的ECN告警數與告警時長持續監控一個月,如圖10所示。開啟GOR控制器調度后,擁塞告警數與告警時長均顯著下降,告警恢復時間小于3分鐘,GOR調度對網絡總體的擁塞消除效果顯著。
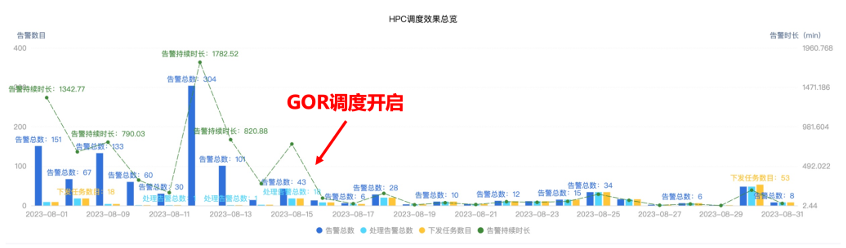
圖10. 某AI網絡集群ECN告警統計 為了更加直觀展示GOR控制器調度效果,我們選取一些典型業務場景進行分析說明。圖11是一個線上發生一般擁塞后,GOR控制器調度消除擁塞的效果。這種流量模型一般常見于AllReduce通信場景。從圖中可以看到,GOR控制器執行調度后,交換機端口的ECN數歸零,代表擁塞立即消除。
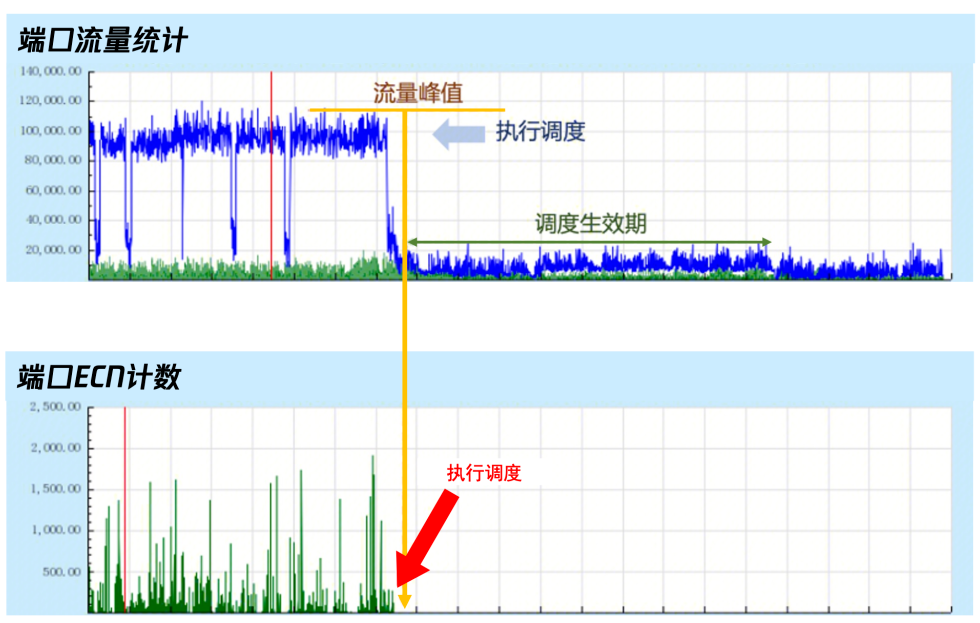
圖11. 一般擁塞鏈路上的GOR調度 圖12是線上一個網絡鏈路嚴重擁塞時GOR的調度效果。這種流量模型通常出現在多個訓練任務疊加場景,以及All2All通信場景。從圖中可以看到,初始ECN數值超過了10000,表明鏈路已經嚴重擁塞。在首次調度后,GOR控制器成功將擁塞鏈路中的最大流調度至目的鏈路-1,這使得擁塞鏈路的帶寬利用率顯著降低,同時ECN計數也得到一定程度緩解,降至2000左右。在GOR控制器完成告警恢復校驗后,繼續調度,將鏈路中的次大流調度至目標鏈路-2,從而使ECN數值進一步降至約1000左右。經過兩次調度,擁塞鏈路的ECN數值仍然很高,GOR繼續第三次調度,最終成功將ECN數值降低至500以下,從而消除了該鏈路的擁塞。
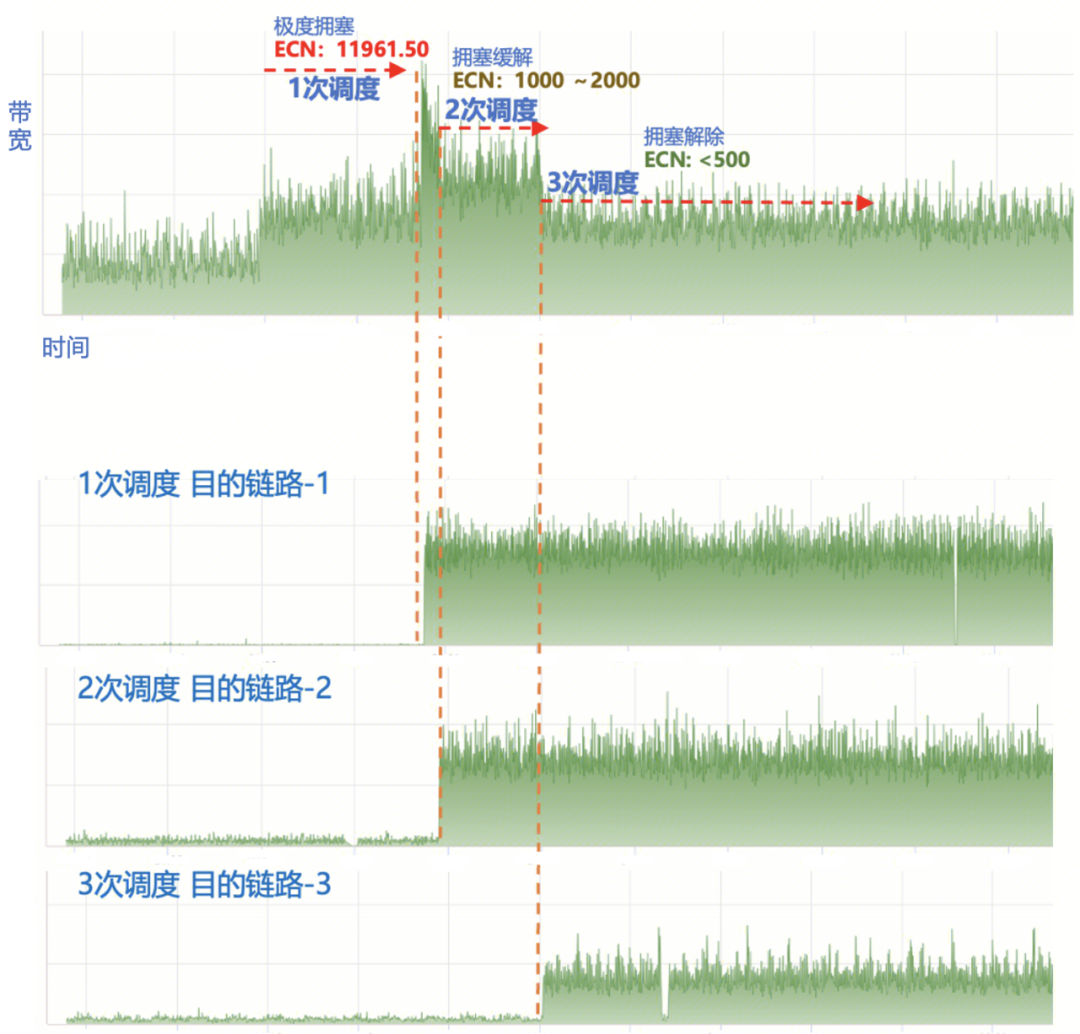
圖12.嚴重擁塞鏈路上的GOR調度 圖13是一臺機器網卡的RDMA速率監控,可以看到GOR控制器調度后,網卡的出方向速率持續升高,最終達到預期值。
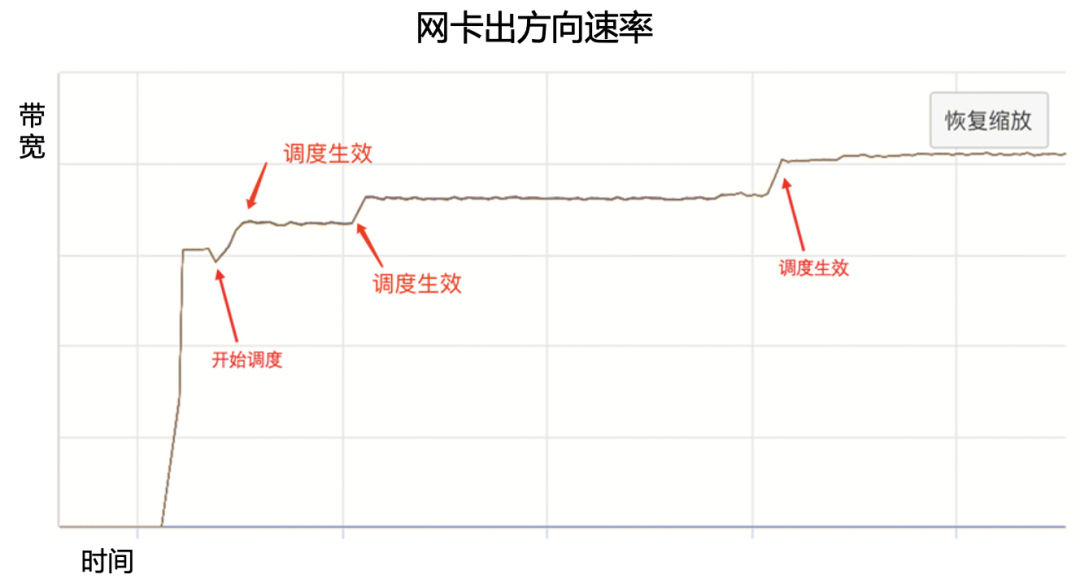
圖13.GOR調度對網卡出向速率的影響 AI大模型的算力基礎是GPU,不同廠商異構GPU的通信模式、流量模型差異很大。GOR控制器在不同GPU集群中都可以顯著消除網絡擁塞,加速端側通信速率,從而保證AI大模型訓練效率。圖14、圖15分別所示在A、B兩種GPU集群中針對不同Message size調度前后的All2All測試結果,可以看到GOR調度后效果顯著,All2All性能提升30%~50%。
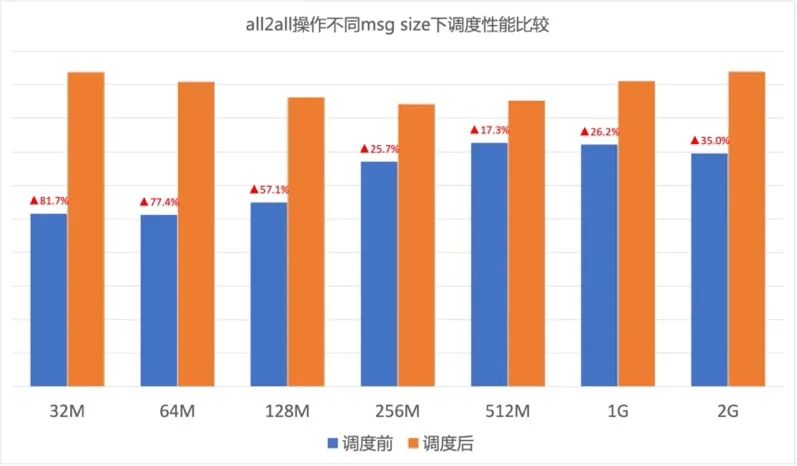
圖14. A廠商GPU集群調度開啟前后All2All性能對比
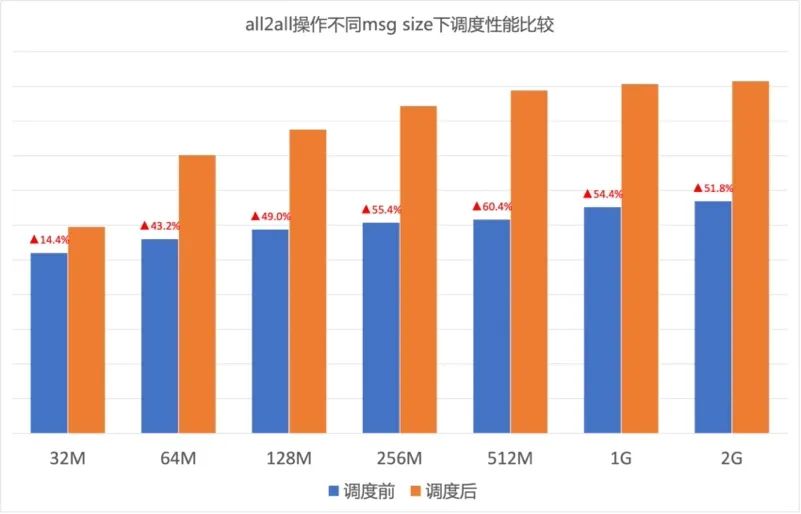
圖15. B廠商GPU集群調度開啟前后All2All性能對比 實際場景中,GOR控制器預規劃與動態調度結合使用。圖16所示在GPU集群All2All性能測試場景中,預規劃提升All2All性能45%以上,顯著解決負載不均問題。當網絡鏈路故障時,性能下降約20%。檢測到擁塞后,GOR控制器動態調度將性能恢復到理想水平。
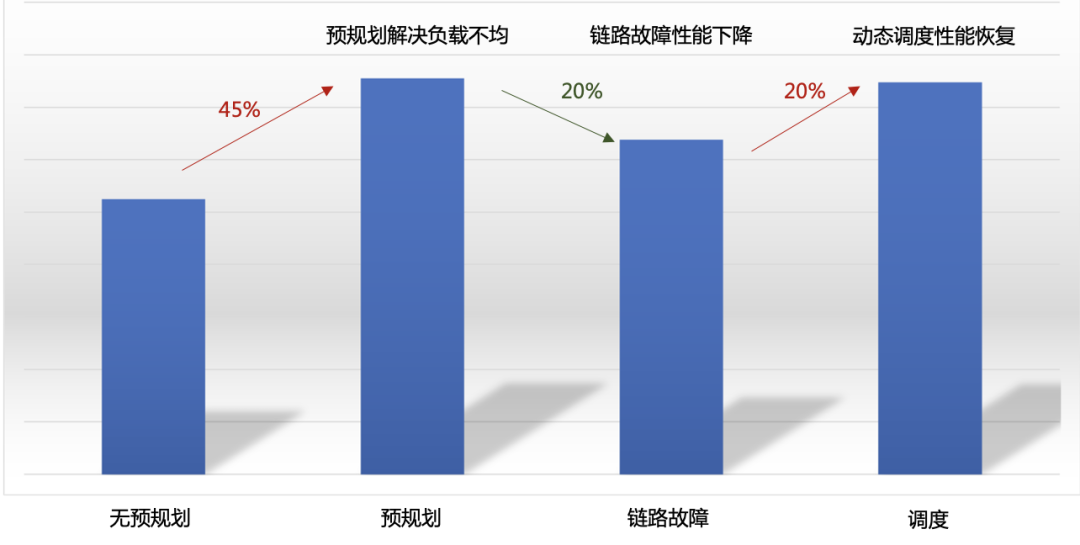
圖16. 各場景下All2All性能 ●GOR控制器業務級運營效果 除了規劃和調度功能外,GOR控制器還實時監控網絡中流的五元組信息,并結合業務側的AI大模型訓練任務,以提供星脈網絡的業務級運營能力。業務級運營將底層網絡流的五元組信息與上層的AI大模型訓練任務結合起來,以便在訓練任務出現問題時快速定位相應的網絡流,同時結合規劃和調度信息判斷是否與網絡有關。同樣地,當檢測到網絡擁塞時,能夠快速找到相關的訓練任務信息,并判斷其對業務的影響。 圖17是GOR控制器對網絡流五元組信息的實時監控效果,網絡中任一時刻、任一條鏈路上的所有流的五元組信息均可以完整記錄,并且可以根據某個五元組還原對應流在網絡中的完整路徑。
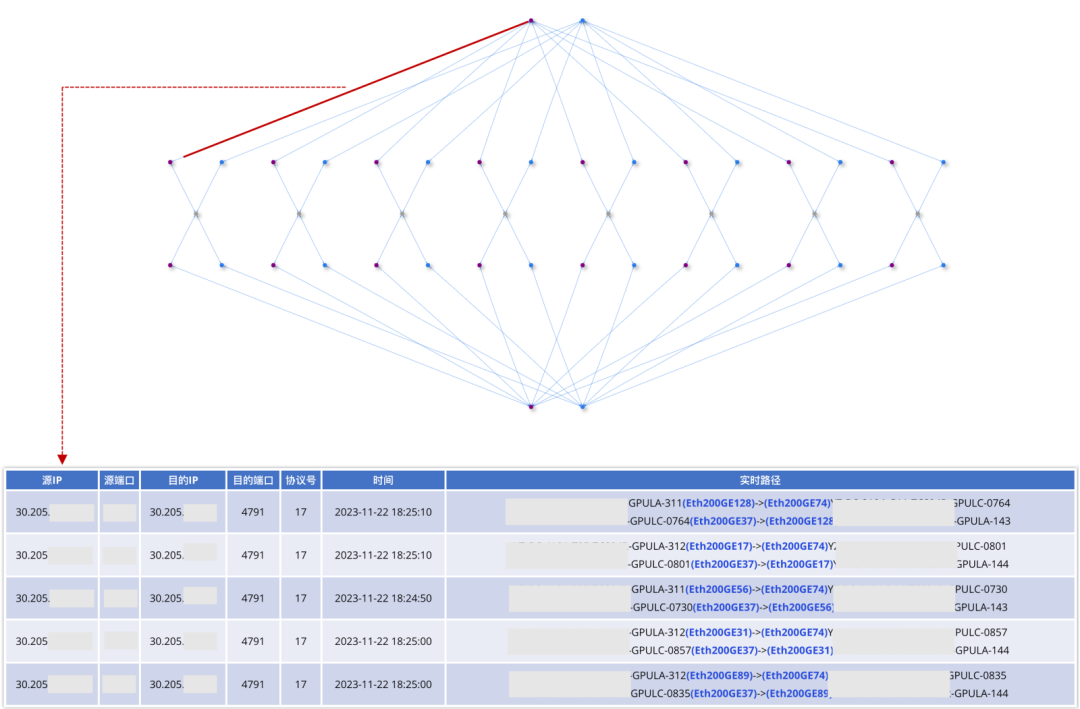
圖17.網絡流五元組信息實時監控 圖18是訓練任務與端側節點的對應關系,GOR控制器通過聚合網絡流的五元組信息并結合端側和訓練框架信息,還原出訓練任務以及與訓練任務相關的所有端側節點信息。
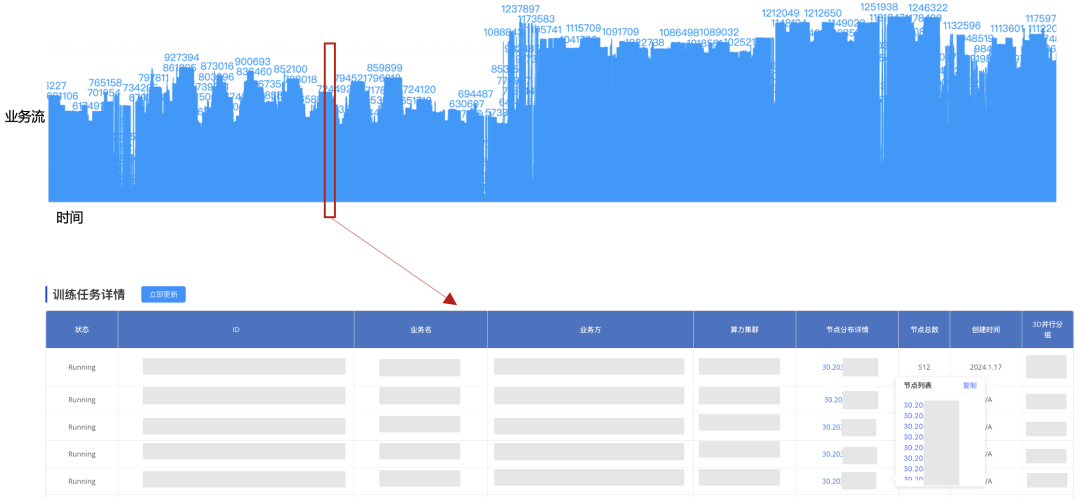
圖18.訓練任務與端側節點對應關系
總結
作為現代信息技術的基礎設施,DCN承載了AI、大數據、云計算等應用的海量數據流量和通信需求。尤其隨著ChatGPT、Sora的出現,AI大模型引爆了新一輪算力網絡需求浪潮,傳統的以CPU為核心的DCN演進升級到了全新的以GPU為核心的星脈AI高性能網絡。在傳統DCN中,我們應用DCN控制器1.0實施網絡變更灰度和路由監控來保證網絡的穩定性;在星脈AI高性能網絡中,DCN控制器1.0進一步演進升級到星脈GOR控制器。星脈GOR控制器通過精細控制實現網絡流量合理規劃和動態調整,并提供業務級運營能力,全面提升AI大模型的訓練效率。
審核編輯:黃飛
-
控制器
+關注
關注
112文章
16434瀏覽量
178982 -
cpu
+關注
關注
68文章
10900瀏覽量
212626 -
數據中心
+關注
關注
16文章
4848瀏覽量
72290 -
AI
+關注
關注
87文章
31436瀏覽量
269832 -
dcnn
+關注
關注
0文章
7瀏覽量
3010
原文標題:星脈網絡解密之——GOR全鏈路流量規劃與擁塞控制
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
TCP優化之TCP/IP網絡流量加速
高速網絡中TCP擁塞控制算法的研究
因特網絡擁塞控制機制的數學架構研究






 工商網監
工商網監
評論