 多任務微調框架MFTCoder詳細技術解讀
多任務微調框架MFTCoder詳細技術解讀
代碼大模型(Code LLMs)已經成為一個專門的研究領域,通過使用代碼相關數據對預訓練模型進行微調來提升模型的編碼能力。以往的微調方法通常針對特定的下游任務或場景進行定制,意味著每個任務需要單獨進行微調,需要大量的訓練資源,并且由于多個模型并存而難于維護和部署。此外,這些方法未能利用不同代碼任務之間的內在聯系。 為了克服這些限制,我們提出了一種多任務微調框架——MFTCoder,它可以實現在多個任務上同時并行地進行微調。通過結合多種損失函數,我們有效地解決了多任務學習中常見的任務間數據量不平衡、難易不一和收斂速度不一致等挑戰。
大量實驗結果顯示,相較于單獨對單個任務進行微調或者多任務混合為一后進行微調,我們的多任務微調方法表現更優。此外,MFTCoder具備高效訓練特征,包括提供高效的數據Tokenization模式和支持PEFT微調,能有效提升微調訓練速度并降低對資源的需求。 MFTCoder已適配支持了多個主流開源LLMs,如LLama-1/2、CodeLLama、Qwen、CodeGeeX2、StarCoder、Baichuan2、ChatGLM2/3、GPT-Neox等。
以CodeLLama為底座,使用MFTCoder微調得到的CODEFUSE-CODELLAMA-34B在HumaneEval測試中pass@1得分高達74.4%,超過了GPT-4的表現(67%,zero-shot, 2023年3月)。
對應的代碼也已經開源到github: https://github.com/codefuse-ai/MFTCoder? 本文旨在對MFTCoder論文做一個詳細技術解讀。

?
引言
ChatGPT和GPT-4的橫空出世使得大模型(LLMs)研發井噴式爆發,這也同時進一步引燃了將大模型應用于代碼生成與理解的研發熱潮,這一分支被稱為代碼大模型(即Code LLMs)方向。通過在大量的代碼數據(例如GitHub公開數據)和自然文本數據上進行預訓練,代碼大模型可以有效完成各種代碼相關的任務,例如代碼自動補全、基于描述生成代碼、為代碼添加注釋、解釋代碼功能、生成單測用例、修復代碼、翻譯代碼等。 盡管(代碼)LLMs的預訓練階段旨在確保其對不同的下游任務具有泛化能力,但隨后的微調階段通常只針對特定任務或場景而進行。這種方法忽視了兩個關鍵挑戰。
首先,它涉及針對每個任務進行資源密集型的單獨微調,這阻礙了在生產環境中的高效部署;其次,代碼領域任務的相互關聯性表明,與單獨微調相比,聯合微調可以提高性能。因此,進行多任務微調是至關重要的,可以同時處理所有任務,并利用相關任務的優勢來增強其他任務的表現。 為了更好地闡明,假設我們有兩個相關的任務:代碼補全和代碼摘要。代碼補全是基于部分代碼片段預測下一行代碼,而代碼摘要旨在生成給定代碼片段的簡潔易讀的摘要。傳統上,每個任務會分別進行微調,導致資源密集型的重復。然而,代碼補全和代碼摘要之間存在內在聯系。
代碼片段的補全依賴于對整體功能和目的的理解,而生成準確的摘要則需要理解結構、依賴關系和預期功能。通過采用多任務學習,可以訓練一個單一模型來共同學習這兩個任務,利用共享的知識和模式,從而提高兩個任務的性能。模型理解代碼元素之間的上下文依賴關系,有助于預測下一個代碼片段并生成信息豐富的摘要。此外,多任務學習在個別任務性能之外還提供了額外的好處:任務之間的共享表示有助于減輕過擬合問題,促進更好的泛化,并增強模型處理特定任務的數據稀缺性的能力。如果代碼補全具有比代碼摘要更大的訓練數據集,模型可以利用豐富的補全數據來提高摘要的性能,從而有效地解決數據稀缺性挑戰。多任務學習甚至使模型能夠處理未見過但相關的任務,即使沒有特定的訓練數據。
總體而言,多任務學習允許模型共同學習多個相關的任務,從共享的知識中受益,提高性能,增強泛化能力,并應對數據稀缺性。 盡管多任務學習很重要,但在自然語言處理領域,只有少數幾項現有研究探索了這種方法(Raffel等,2023年;Aghajanyan等,2021年;Aribandi等,2022年)。這些研究將多任務數據合并用于大模型學習,而沒有明確區分任務。更不幸的是,這些研究往往優先考慮樣本量較大的任務,忽視了樣本量較小的任務。此外,它們未能確保任務間的收斂速度相等,導致一些任務過度優化,而其他任務則欠優化。 本文聚焦于大模型多任務微調(MFT, Multitask Fine-Tuning),意在使樣本數量存有差異的任務獲得相等的關注并取得相近的優化。
雖然我們的方法不限于代碼大模型領域,但本文我們重點關注代碼大模型,這是考慮到代碼領域的下游任務往往更具相關性,這也是MFTCoder命名的來源。我們強調,MFTCoder可以簡單地擴展到任意一組相關的NLP任務。為了提高MFTCoder的效率,我們采用了包括LoRA(Hu等,2021年)和QLoRA(Dettmers等,2023年)在內的參數高效的微調技術。實驗結果表明,使用MFT方法訓練的多任務模型在性能上優于單獨為每個任務進行微調或合并多個任務的數據進行微調而得到的模型。我們進一步適配并驗證了MFTCoder對各種當前流行的預訓練LLMs的有效性,例如Qwen、Baichuan2、Llama、Llama 2、StarCoder、CodeLLama、CodeGeex2等。值得一提的是,當以CodeLlama-34B-Python為基座模型,MFTCoder微調得到的CodeFuse-CodeLLama-34B模型在HmanEval評測集上取得了74.4%的pass@1得分,超過了GPT-4(67%,zero-shot, 2023年3月)的表現。 文章主要貢獻總結如下:
提出了MFTCoder,將多任務學習應用于代碼大模型微調,重點解決了先前多任務微調方法中常見的數據不平衡和收斂速度不一致問題。
大量實驗表明,MFT方法在性能上優于單獨微調和多任務混合合并微調方法。基于CodeLlama-34B-Python底座,MFTCoder微調得到的模型CodeFuse-CodeLLama-34B在HumanEval評測集上取得了74.4%的pass@1得分,超過了GPT-4(67%,零樣本),并開源了該模型和一個高質量指令數據集。
我們在多個流行LLMs上適配并驗證了MFTCoder的表現,包括Qwen、Baichuan2、Llama、Llama 2、StarCoder、CodeLLama、CodeFuse和CodeGeex2等,證明了其與不同底座模型的兼容性和可擴展性。
方法
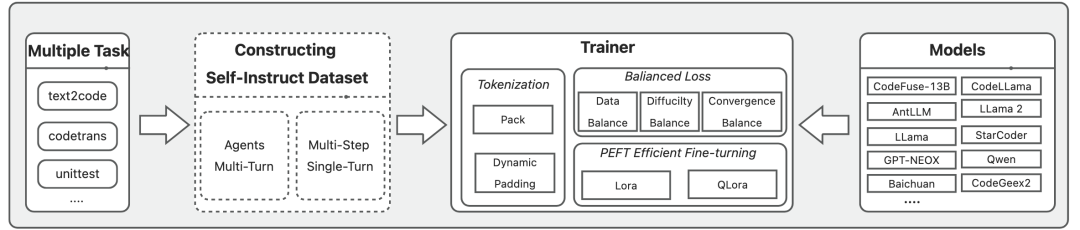
圖1:MFT架構圖 01
框架
MFTCoder的總體框架如圖 1所示,包括多任務支持、多模型適配、高質量數據集構建、高效數據使用方式、高效訓練方式及多任務均衡設計。
(多任務)MFTCoder旨在無縫地適配LLMs到不同的場景,并在特定的場景中最大化它們的性能。在將MFTCoder應用于新場景時,首要步驟便是將場景分解為對應于目標能力的較小任務。例如,在代碼LLMs領域,增強模型的代碼能力的總體目標可以進一步拆解為更細粒度的任務,如代碼補全,文本到代碼生成,單元測試用例生成,代碼修復,代碼調試,甚至跨語言翻譯。我們廣泛的實踐經驗表明,MFTCoder可以有效處理從單個任務到數十甚至數百個任務的多任務規模。
(數據集構建與高效訓練)拆分完后,下一步便是為每個任務收集和整理微調數據集,然而,某些任務的數據收集可能會存在挑戰。為了克服這一問題,MFTCoder利用了Self-Instruct(Wang等,2022年)和Agents技術來生成指令數據集。多任務微調往往意味著一次微調會使用較大量的訓練數據,為了確保高效的訓練過程,MFTCoder采用了兩種高效的數據Tokenization模式,并支持PEFT(Parameter-Efficient Fine-Tuning)技術來提高訓練效率。
(任務均衡設計)針對多任務學習領域普遍存在的任務間數據量不均衡、難易不一及收斂速度不一致的挑戰,MFTCoder引入或調整不同的損失函數以實現任務平衡。
(多模型適配)鑒于不同的大型模型具有不同的優勢和能力,為支持按需選擇適合的模型底座進行微調以實現最佳性能,MFTCoder已適配了若干主流的開源LLMs,包括LLama,LLama 2,CodeLLama,Qwen,Baichuan 1/2,ChatGLM 2,CodeGeeX 2,GPT-NEOX,CodeFuse-13B,StarCoder,AntLLM等。同時也在持續更新和適配新的模型。
02
指令數據集構建
對于數據收集具有挑戰性的任務,我們采用Self-Instruct技術為MFTCoder中的下游代碼相關任務生成微調數據。這涉及向GPT-3.5或GPT-4提供定制的提示,明確描述我們的指令生成需求,從而生成指令數據。此外,我們從PHI-1/1.5工作(Gunasekar等,2023年)中受到啟發,進一步將Self-Instruct技術應用于為下游代碼相關任務生成高質量的代碼練習數據集。 在具體實現方面,我們有兩個選擇。
一種是借助Agents(例如Camel(Li等,2023c年))的自主多輪對話方法,另一種是通過直接調用ChatGPT API實現的單輪對話方法。在多輪對話方法中,我們使用Camel啟動兩個Agents,每個Agent被賦予特定的角色和任務目標,驅動它們之間相互對話以生成與給定主題相符的指令數據。例如,在生成Python練習數據時,我們將兩個Agents分別指定為“教師”(模擬ChatGPT的用戶角色)和“學生”(模擬ChatGPT的助理角色)角色,其中,教師的責任是向學生提供生成練習題的指令,而學生的任務則是提供相應指令的解決方案。
這個迭代過程會持續進行而生成多個練習問題,直到滿足任務要求或達到ChatGPT的最大輸入長度。值得一提的是,為了適應ChatGPT的輸入長度限制,我們不能直接使用較寬泛的題目作為任務主題。例如,當創建用于評估學生Python語言掌握程度的練習題時,我們需要將主題分解為較小而具體的Python知識點(例如二叉搜索樹),并為每個知識點單獨啟動Camel會話。
具體的示例如下圖2(摘自論文附錄Ahttps://arxiv.org/pdf/2311.02303.pdf)。

圖2: 通過Camel Agents生成代碼練習題系統及用戶提示設置示例
多輪對話方案提供了較高的自動化能力,但由于需要維護兩個Agents,并且每個代理都需要對ChatGPT API進行多輪會話調用,因此成本較高。為了緩解這一問題,我們提出了一種更經濟高效的單輪對話生成方法,其整體過程如圖3所示。我們首先創建一個初始種子集,種子集由數百個Python基礎知識點組成。然后將這些種子與準備好的固定Prompt模板組合,生成一組模式化的任務Prompt。
為了解決固定模板導致的多樣性減少問題,并確保準確的提示描述,我們利用Camel的任務Prompt細化功能來獲取精確且多樣的任務Prompt。每個任務Prompt用于生成與相應種子相關的一組指令(例如與二叉搜索樹相關的練習問題)。使用ChatGPT,我們生成相應的指令解決方案。最后,我們將指令及其相應的解決方案組裝和去重,以獲得一個練習數據集。我們已經開源了使用這種方法構建的Python Code Exercises數據集: https://huggingface
.co/datasets/codefuse-ai/CodeExercise-Python-27k??
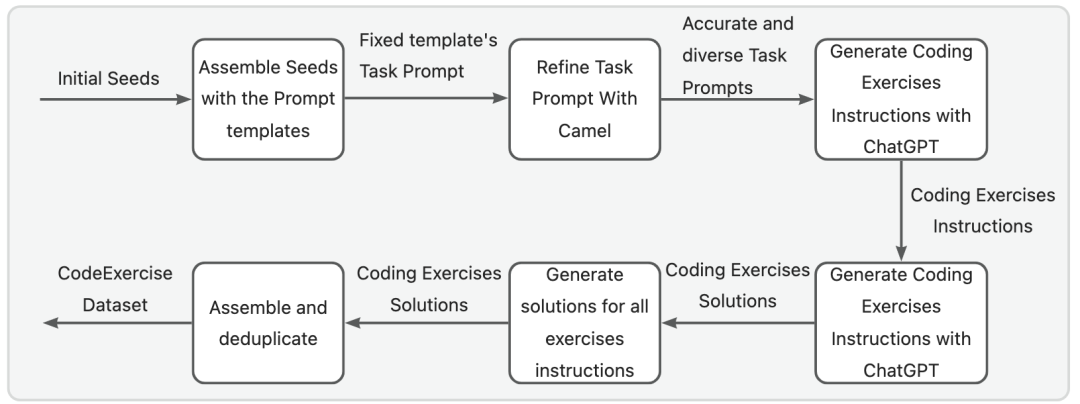
圖3: Code Exercises指令數據集單輪生成方案流程 03
高效Tokenization模式
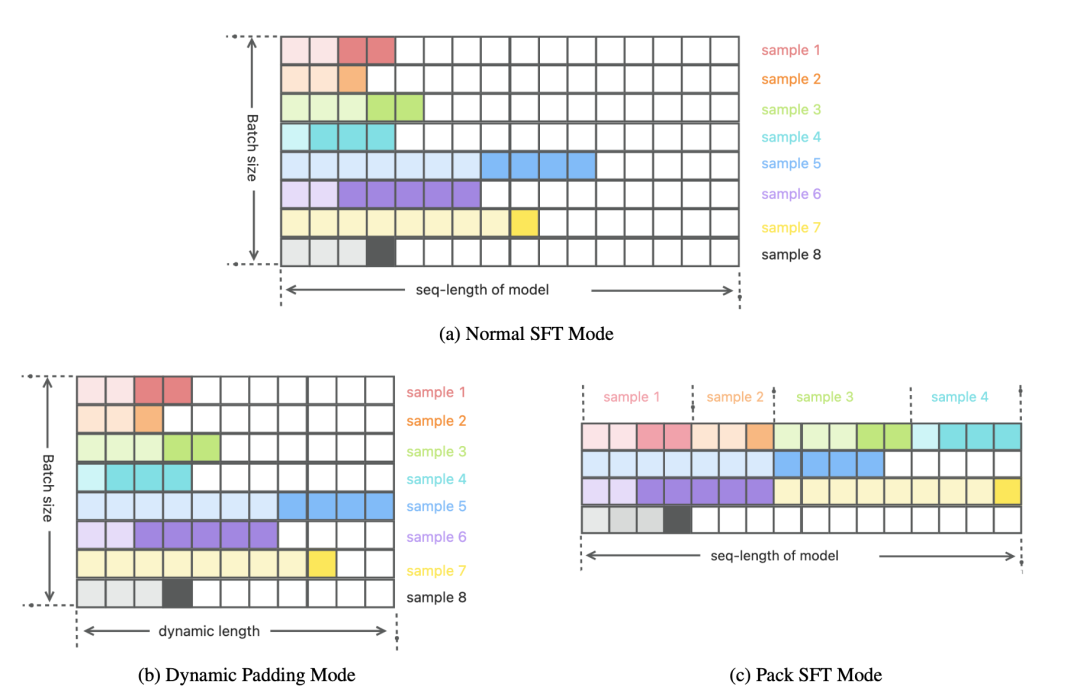
圖4: 三種Tokenization模式在一個Batch中的數據存在形式對比示意圖
在LLMs的預訓練和微調過程中,分詞(Tokenization)是一個關鍵步驟,在這個步驟中輸入和輸出文本被分割成較小的單元以供后續使用。Tokenization與訓練過程使用的損失函數一起定義了訓練過程中數據的使用方式,因此在模型的有效性和訓練效率上起著關鍵作用。在典型的SFT (Supervised Fine-Tuning) Tokenization方案中,同一batch中的樣本被統一對齊到模型的最大輸入長度(seq-length),對于長度不足的則使用額外的填充Tokens進行填充,如圖 4(a)所示。然而,在實踐中,我們發現這種方法會導致產生大量的填充Tokens。例如,當使用CodeFuse-13B(Di等,2023年)的Tokenizer處理35個下游任務數據時,填充Tokens的平均比例為92.22%(seq-length為4096)。
這意味著有大量的Tokens僅用于對齊,而對訓練過程沒有任何價值,這導致訓練效率降低,且浪費用于存儲離線Tokenization結果的存儲空間。為了解決這個問題,我們采用了兩種Tokenization模式,即動態填充(Dynamic Padding)模式和打包(Pack)模式,并對其進行了優化。 在動態填充模式中,每個GPU的micro batch窗口大小由其中的最大樣本長度確定。較短的樣本會使用額外的填充Tokens進行填充,以對齊到該大小,如圖 4(b)所示。
盡管填充Tokens不會影響模型的訓練效果,但它們會增加訓練過程中的計算開銷,從而影響訓練速度,而動態填充模式有效地減少了填充Tokens的使用比例,從而加快了訓練速度。根據我們的經驗,與傳統的SFT Tokenization模式相比,這種方法可以實現大約兩倍的速度提升(實際的增幅取決于數據集)。需要注意的是,該模式僅適用于在線Tokenization場景。 與動態填充模式通過減少了micro batch窗口大小來提高效率的角度不同,打包模式是從最大化模型允許的最大輸入窗口長度(seq-length)的利用率角度出發,這種模式與Llama 2的SFT Tokenization模式(Touvron等,2023b年)相似。
在打包模式中,多個微調樣本按順序打包到一個長度為seq-length的窗口中,兩個相鄰樣本通過一個EOS Token分隔,如圖 4(c)所示。在圖中,圖 4(a)的樣本1-4被組合并依次放置在一個窗口中。如果一個樣本無法完全放入當前窗口,它將被放置在下一個窗口,并用填充Tokens填充剩余的空間,例如,圖 4(c)中,樣本5被放置在第二個窗口中,并使用填充Tokens填充尾部空間,而樣本6則放置在第三個窗口中。與動態填充模式相比,打包模式進一步降低了的填充Tokens比例,從而可進一步提高訓練速度。我們的實踐經驗表明,在前面提到的35個任務中,該方法將填充Tokens的平均比例降低到不到10%,從而在保持訓練效果的同時大幅提升了訓練速度。需要強調的是,MFTCoder支持在線和離線的打包Tokenization場景,不僅服務于SFT階段,還適用于預訓練階段。 04
PEFT高效微調
目前流行的開源LLMs通常包含數十億乃至上百億個參數,而多任務學習場景又通常涉及大量的任務,這意味著會有大量的微調樣本參與訓練。如果我們選擇使用大量數據對這些大模型進行全量微調,將會面臨兩個挑戰:首先,需要大量的存儲和計算資源;其次,在訓練過程中可能面臨災難性遺忘的風險。為了解決這些問題,MFTCoder采用了PEFT(Parameter-efficient fine-tuning)技術(Houlsby等,2019年),使得能夠在短時間內以最小的資源需求實現高效的微調。
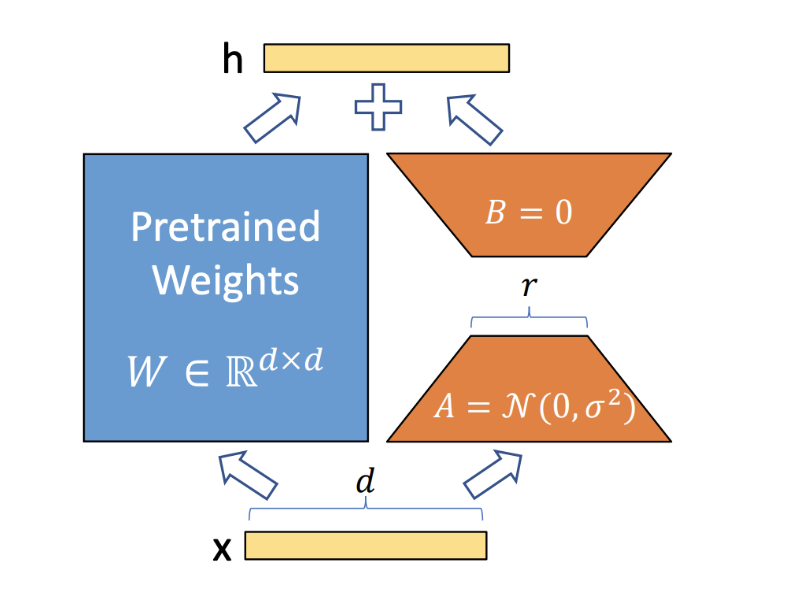
圖5: Lora核心思想示意
具體來說,MFTCoder支持兩種PEFT方法:Lora(Large-scale Language Model Low-Rank Adaptation)(Hu等,2021年)和QLora(Quantized Large-scale Language Model Low-Rank Adaptation)(Dettmers等,2023年)。 Lora的基本概念非常簡單,如圖 5所示。它會給原始模型添加一個旁路分支,在訓練過程中,原始訓練模型的參數W ∈ R(形狀為d x d)保持不變,只有旁路分支中的降維矩陣A ∈ R(形狀為d × r)和升維矩陣B ∈ R(形狀為r x d)的參數是可訓練的。
訓練完成后,矩陣乘積BA將被加到原始模型參數W中,從而得到新訓練的模型。由于r相對于d的規模顯著縮小,可訓練參數的數量因而大大減少。在Lora的基礎上,QLora采用了一種稱為NF4的新的高精度量化技術,并引入了雙重量化來將預訓練模型量化為4位(bits)。此外,它還引入了一組可學習的低秩適配器權重,通過優化量化權重的梯度,對這些權重進行微調。結果,QLoRA可以使用更少的GPU資源對較大的模型進行微調。例如,MFTCoder可以在單張Nvidia A100卡(80GB顯存)上對70B模型進行微調。
05
多任務均衡損失函數
作為一個多任務學習框架,MFTCoder面臨著任務間數據量不平衡、難易不一和收斂速度不同的重大挑戰。為了解決這些挑戰,MFTCoder采用了一組專門設計的損失函數,以緩解這些不平衡問題。 首先,為了解決數據量不平衡的問題,MFTCoder會確保在單個epoch內所有任務的每一個樣本都被使用且只使用一次。為了避免模型偏向具有較多數據的任務,我們在損失計算過程中引入了權重分配策略。
具體而言,我們支持兩種權重計算方案:一種基于任務樣本數量,另一種基于納入loss計算的的有效Tokens數量。前者更直接,但在處理樣本數量與有效Tokens數量具有極端差異的任務(例如"是"或"否"回答的二元分類任務或單項選擇考試任務)時可能表現不佳。而另一方面,基于納入loss計算的有效Tokens數量的權重分配方案可以緩解這個問題。帶權重的損失函數具體如公式 (1)所示。在公式1中,N代表任務的總數,M_i表示第i個任務的樣本數量,T_ij表示第i個任務的第j個樣本中的有效Token(即參與loss計算的Token)的數量,t_ijk表示第i個任務的第j個樣本的第k個有效Token。
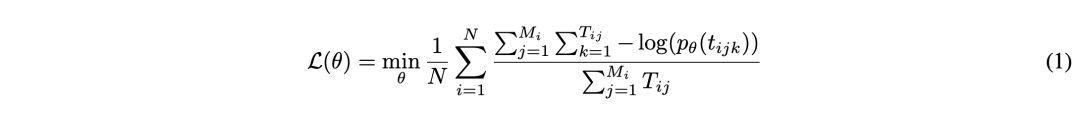
為了解決任務難易不一的問題,我們借鑒了Focal Loss的思想,并將其納入到MFTCoder中。我們實現了兩個不同層次的Focal Loss函數,以適應不同的細粒度。一個在樣本級別操作,如公式 (2)所示,另一個在任務級別操作,如公式 (3)所示。
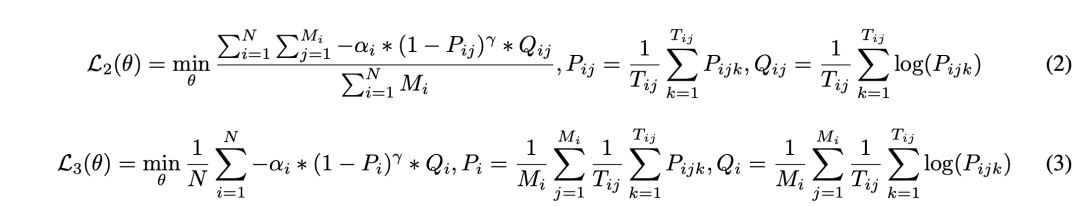
為了解決收斂速度不一致的問題,我們借鑒了FAMO(Fast Adaptation via Meta-Optimization)方法(Liu等,2023年)的思想,并創新地將其應用于計算validation loss。首先,我們假設每個任務(以索引i表示)都有自己的原始損失函數Li(θ)。在第t次迭代中,我們根據對應任務的validation loss的梯度來更新每個任務的權重,目標是最大化收斂速度最慢的任務的權重w_i,如公式 (4)所示。其中,g_t表示所有任務加權驗證損失的梯度,ci(α, g_t)表示第i個任務驗證損失的斜率(梯度),θ_t表示第t次迭代中網絡的參數,α是學習率,ε是一個小常數,用于防止除以零。此外,我們希望對如何實現收斂平衡進行進一步解釋。為了確保任務以相似的速度收斂,我們引入了一種動態平衡機制。
在每次迭代中,我們根據任務的驗證損失梯度更新任務特定的權重。該方法旨在給予收斂速度較慢的任務更多的關注,使其對整體優化過程產生更大的影響。通過動態調整任務權重,我們創造了一個平衡收斂的情景,所有任務以類似的速度向其最優解進展。這種機制有效地解決了不同收斂速度的問題,增強了MFTCoder框架的整體穩定性和性能。
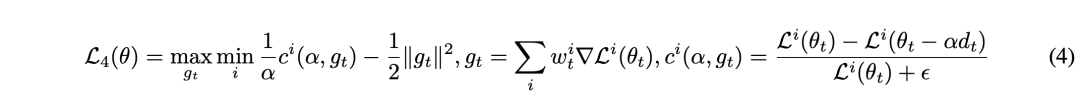
通過結合這些不同的損失函數,MFTCoder可有效地解決各種多任務場景的不同需求,并緩解現有大規模多任務學習研究中常遇到的任務數據不平衡、難易不一和收斂速度不一致等挑戰。MFTCoder作為一個靈活框架為這些問題提供了有效的解決方案,為開發更高效、更準確的多任務模型提供了支持。
實驗
在本節中,我們將使用MFTCoder進行多組實驗用于驗證MFT方法的有效性和優越性。具體而言,我們的目標是回答以下三個研究問題:
RQ1:通過使用MFT方法對多個任務進行微調得到的MFT模型是否優于單獨對每個任務進行微調而得到的SFT-S(單一任務)模型?
RQ2:MFT模型是否優于將多個任務組合并作為一個任務進行微調而得到的SFT-Mixed(混合任務)模型?
RQ3:在對未見任務的泛化能力上,MFT模型是否優于SFT-Mixed模型?
接下來,我們將首先介紹實驗設置。然后,我們將展示和深入探討實驗結果。最后,我們將總結并回答本節中提出的研究問題。 01
實驗設置
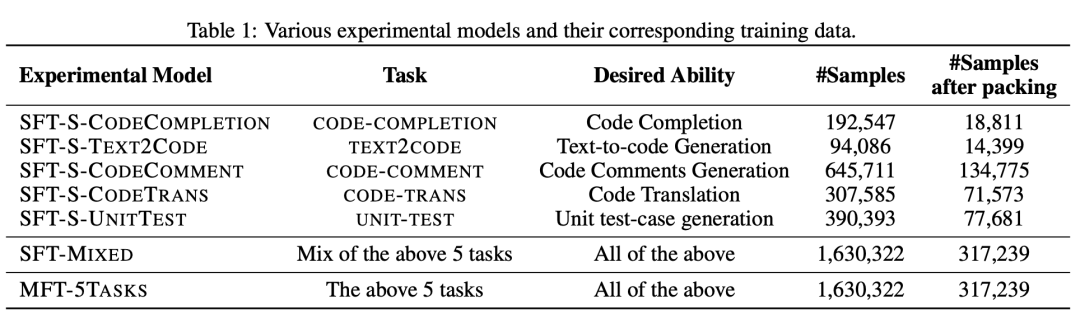
為了回答這三個研究問題,我們選擇了5個與代碼相關的下游任務,并準備了相應的微調數據,如表 1所示。表1展示了每個任務的目標能力(第III列)和樣本數量(第IV列)。例如,CODECOMPLETION-TASK旨在提高模型的代碼補全能力,包括192,547個微調樣本。CODETRANS-TASK旨在增強模型的代碼翻譯能力,包含307,585個微調樣本。因此,我們共訓練了7個模型(第I列),包括為每個下游任務單獨訓練的SFT-S-*模型、5個任務數據混合為一的SFT-MIXED模型,以及使用MFT方法訓練的MFT-5TASKS模型。
在實驗中,除訓練數據外,所有模型的配置都相同。所有模型的底座模型都是CodeLlama-13B-Python(Rozière等,2023年)。每個模型使用16張A100 GPU(80GB顯存),micro batch大小為8,全局batch大小為128進行訓練。使用Adam優化器(Kingma和Ba,2017年),初始學習率為2e-4,最小學習率為1e-5。我們使用MFTCoder的QLora-INT4模式進行微調,微調參數比例均為2.52%,且可訓練參數的位置和初始值也是相同的。
所有模型都采用數據均衡損失函數(即公式 (1))并使用打包Tokenization模式。值得注意的是,當只有一個任務時,這個損失函數與標準GPT模型預訓練中使用的傳統損失函數一致。為了使得每個模型盡可能收斂完全,我們會在模型連續兩個Epoch的validation loss均高于它們前面緊鄰的一個Epoch的validation loss時終止模型訓練,并選擇倒數第三個Epoch對應的模型檢查點作為評測對象。 02
評測集
在本文中,我們使用了公開可得且具有代表性的代碼評測集進行比較評估,包括:
HumanEval(Chen等,2021年)是一個廣泛使用的Python代碼補全評估數據集,由OpenAI的研究人員精心設計。
HumanEval-X(Zheng等,2023年)是通過翻譯方式將HumanEval擴展成多種編程語言,實現了多語言代碼補全評估。
DS-1000(Lai等,2022年)側重于評估模型使用Python代碼進行數據科學分析的能力,涵蓋了Numpy、Pandas、TensorFlow、Pytorch、Scipy、Sklearn和Matplotlib等重要庫。
MBPP(Austin等,2021年)包含1000個Python編程問題,通過眾包方式構建,主要評估模型對基礎Python的掌握能力。在本研究中,我們從MBPP中選擇了ID為11-510的500個問題來評估模型基于文本描述生成代碼的能力。
CodeFuseEval(https://github.com/codefuse-ai/codefuse-evaluation),在HumanEval和HumanEval-X的基礎上,進一步擴展評測范圍,新增中文代碼補全(docstring為中文)、代碼翻譯和單測用例生成能力評估,對應的子集分別稱為CodeFuseEval-CN、CodeFuseEval-CodeTrans和CodeFuseEval-UnitTest。
在以上評測集上,我們均采用“pass@1”作為本文中的評估指標。
實驗結果
接下來,我們將展示7個訓練模型的評估結果。對于每個單一任務SFT-S-*模型,我們重點測試它們的特定目標能力,例如,對于只用代碼補全數據集訓練的SFT-S-CODECOMPLETION模型,我們只測試其在代碼補全上的表現。另一方面,對于SFT-MIXED模型和MFT-5TASKS模型,我們將評估它們在每個任務上的表現,并將其與相應的SFT-S-*模型進行比較。具體而言,我們評估了7個模型在代碼補全、Text2Code、代碼注釋生成、代碼翻譯和單測用例生成等能力維度上的表現。 代碼補全 對于代碼補全任務,我們使用了HumanEval和HumanEval-X評估數據集來評估模型的性能,采用pass@1作為評估指標。我們評估了3個模型:SFT-S-CODECOMPLETION、SFT-MIXED和MFT-5TASKS。
這些模型在HumanEval數據集上的表現總結如表 2所示(第III列)。結果表明,使用MFT方法訓練的MFT-5TASKS模型優于其他兩個模型。相比于使用混合任務數據進行微調的SFT-MIXED模型,其性能提高了2.44%。值得注意的是,SFT-MIXED模型的性能不如SFT-S-CODECOMPLETION模型,后者是針對代碼補全任務進行單獨訓練的。
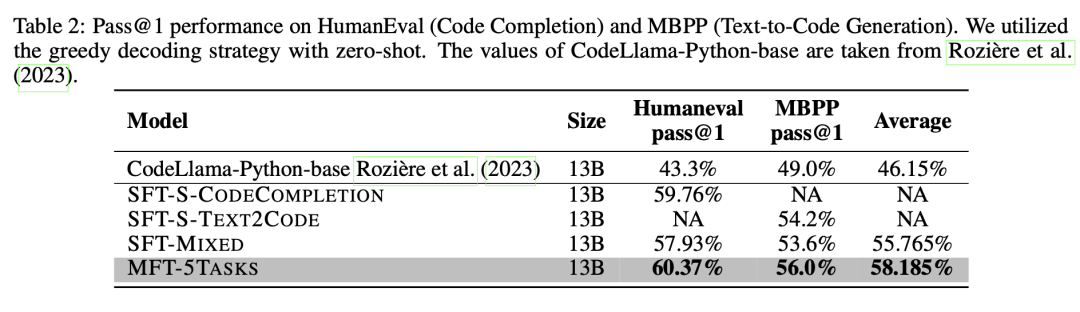
此外,我們還對3個模型在HumanEval-X數據集上進行了多語言代碼補全能力評估,如表 3所示。MFT-5TASKS模型在Java和Golang上表現出優異的性能,而SFT-MIXED模型在C++和JavaScript方面表現出色。總體而言,MFT-5TASKS模型表現優于其他2個模型,比SFT-MIXED模型上平均提高了1.22%。

總體而言,在代碼補全任務方面,使用MFT方法訓練的模型優于單獨進行微調的模型和將多個任務混合進行微調的模型。
Text2Code
為了評估模型根據描述生成代碼的能力,我們選擇了MBPP評估集,并使用pass@1作為評估指標。我們在MBPP數據集上測試并對比了3個模型:SFT-S-TEXT2CODE、SFT-MIXED和MFT-5TASKS,如表 2所示(第IV列)。在這些模型中,MFT-5TASKS表現出最高的性能,比SFT-MIXED模型高出2.4%。同樣,在文本到代碼生成任務中,將多個任務混合進行微調而得到的模型表現出較低的性能,不如這個任務單獨進行微調得到的模型。
總體而言,在文本到代碼生成任務方面,使用MFT方法訓練的模型優于單獨進行微調的模型和將多個任務混合進行微調的模型。
代碼注釋生成
代碼注釋生成任務的目標是使模型在不修改輸入代碼本身的要求下,為代碼添加必要的注釋,包括行注釋和接口注釋,使代碼更易讀和用戶友好。為了評估這個能力,我們基于500個MBPP測試集(id 11-510)構建了一個評測集。對于評測集中的每個問題,我們讓SFT-S-CODECOMMENT、SFT-MIXED和MFT-5TASKS模型為其生成注釋。隨后,我們使用已經被教導了好的代碼注釋標準的GPT-4作為裁判,來確定哪個模型表現最好,如果無法判別,則輸出UNKNOWN。
最后,我們統計了每個模型被確定為表現最好的問題的數量,并計算了相應的比例,如表 4所示。可以看到,38.8%的問題被確定為MFT-5TASKS模型表現最好,超過第二名的SFT-MIXED模型7.4%和第三名的SFT-S-CODECOMMENT模型10.8%。另外,有1.8%的問題被GPT-4標記為無法確定。
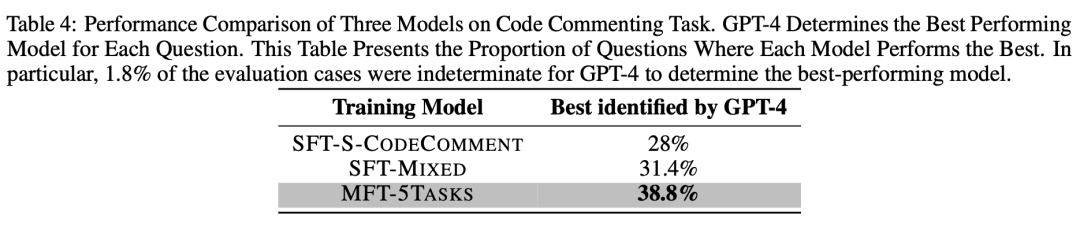
總體而言,在生成代碼注釋任務上,使用MFT方法訓練的模型展現出最佳性能。
代碼翻譯
代碼翻譯任務的目標是將給定的源代碼片段準確地翻譯成目標語言中等效的代碼片段,即確保兩種實現具有相同的功能。在這里,我們利用CODEFUSEEVAL評測集的代碼翻譯子集,該子集支持Java、Python和C++之間的雙向翻譯評估。為了評估翻譯結果的準確性和功能等效性,我們使用與源程序語義等效的測試用例用于驗證結果代碼是否能夠成功運行和通過,即符合pass@1標準。
3個模型的測試結果如表 5所示:MFT-5TASKS模型在Python到Java、Python到C++和C++到Java的翻譯中表現最好;SFT-MIXED模型在C++到Python的翻譯中表現出色,而SFT-S-CODETRANS模型在Java到Python和Java到C++的翻譯中表現最佳。總體而言,MFT-5TASKS模型展現出優越的性能,比SFT-MIXED模型平均高出0.93%,比SFT-S-CODETRANS模型平均高出10.9%。

總結而言,在代碼翻譯這個任務上,使用MFT方法訓練的模型優于其他兩種訓練方法得到的模型。
單測用例生成
單測用例生成任務是通過訓練模型為給定的代碼片段(如方法或類)生成一組單元測試用例,用以驗證提供的代碼實現是否正確。我們選擇使用CODEFUSEEVAL評測集中的UNITTEST子集作為我們的測試數據集。同樣地,使用pass@1指標作為評估指標,這意味著如果模型為輸入樣本(代碼片段)生成測試用例,并且輸入樣本通過了所有測試用例時,正確生成樣本個數加1。在評估過程中同樣采用貪心解碼策略。
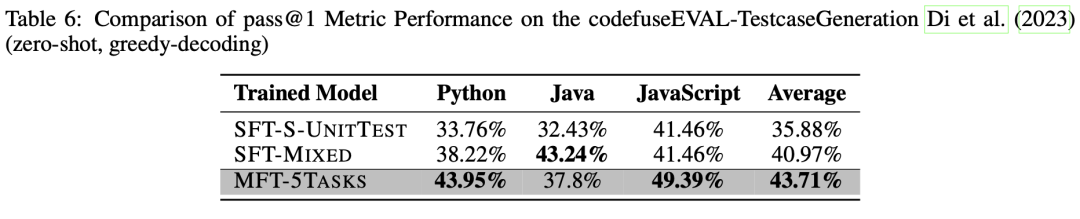
我們比較了3個模型在Python、Java和JavaScript上的單測用例生成能力,如表 6所示。結果表明,MFT-5TASKS模型在Python的單測用例生成方面優于其他模型,比第二名的SFT-MIXED模型上高出5.73%,比第三名的SFT-S-UNITTEST模型領先10.19%。在JavaScript中,MFT-5TASKS模型也表現出色,領先其他模型7.93%。然而,在Java中,MFT-5TASKS模型的性能比SFT-S-UNITTEST高出5.37%,但比SFT-MIXED低5.44%。總體而言,MFT-5TASKS模型依然現出最高的性能,相比SFT-MIXED模型平均提高了2.74%,相比SFT-S-UNITTEST模型提高了7.83%。
總結而言,使用MFT方法訓練的模型表現優于單一任務模型和混合任務模型。
在未見任務上的泛化表現
除了評估模型在具有訓練數據的任務上的表現來回答RQ1和RQ2之外,本文也測試并回答了MFT模型是否在未見任務上表現出比混合任務模型更好的泛化能力(即RQ3)。為了回答這一問題,文章選擇了Text-to-SQL生成任務作為測試目標。這個任務的數據不包含在7個現有模型的訓練中。此外,這個任務與現有的5個下游任務有著明顯的代碼相關性,但又有所不同。 文章選擇了兩個評估指標,BLEU分數和SQL語句的邏輯準確性。
BLEU評估生成的輸出與參考答案之間的文本相似度,另一方面,邏輯準確性指標用于應對含義正確但SQL語句表達不同的情況。具體來說,邏輯準確性衡量數據集中生成的SQL語句在句法上正確且在語義上與參考答案相等的測試樣本的比例。

文章選擇了5個代表性的Text2SQL數據集,包括WikiSQL(Zhong等,2017年)、Spider(Yu等,2019b年)、CSpider(Min等,2019年)、CoSQL(Yu等,2019a年)和BirdSQL(Li等,2023d年),并從每個數據集中隨機抽取了200個示例進行評估。測試用例示例如表 7所示,其中第一行展示了類似于OpenAI ChatML格式的微調數據格式。對于每個抽樣出來的數據集,文章均測試了SFT-MIXED和MFT-5TASKS模型的邏輯準確性和BLEU分數,如表 8所示。根據表8,MFT-5TASKS模型在每個數據集上的BLEU分數都高于SFT-MIXED模型,平均高出2.78倍。這表明MFT-5TASKS生成的結果與參考答案的文本更相似。這種相似性在表 7中也可以觀察到,MFT-5TASKS模型生成更干凈的結果,而SFT-MIXED模型則提供更多的解釋(這在某些情況下可能更受歡迎)。此外,MFT-5TASKS在邏輯準確性方面表現更好,整體準確性比SFT-MIXED模型高出2.18倍,并在WikiSQL數據集上高出4.67倍。
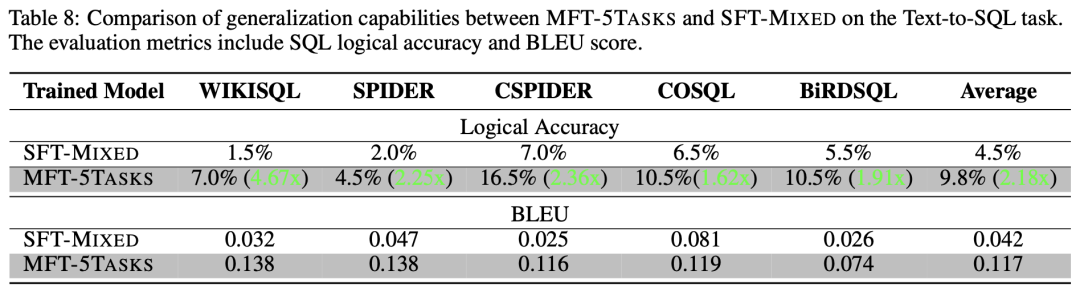
從數值上看,MFT-5TASKS相對于SFT-MIXED表現出更好的性能,表明MFT訓練的模型在未見任務上具有更強的泛化能力,而這個任務在訓練過程中是未見的。
04
實驗總結
本文選擇了與代碼相關的5個下游任務,總共訓練了7個模型,包括針對每個任務單獨進行微調的SFT-S-*模型、使用所有任務數據混合進行微調的SFT-MIXED模型,以及使用MFT方法訓練的MFT-5TASKS模型。文章比較和測試了每個模型在其目標能力方面的性能。此外,文章還對比評估了MFT方法和混合SFT方法在未見任務上的泛化性能。結論總結如下:
使用MFT方法訓練的模型優于針對每個任務單獨進行微調的模型,對RQ1給出了肯定的回答。
使用MFT方法訓練的模型優于使用多個任務混合進行微調的模型,對RQ2給出了肯定的回答。
使用MFT方法訓練的模型相比于使用多個任務混合進行微調的SFT模型,在新的未見任務上表現出更強的泛化能力。 ?
MFTCoder應用
鑒于MFT訓練方法的優異表現,我們已經將MFTCoder用于適配當前主流的開源LLMs,包括QWen、Baichuan 1/2、CodeGeex2、Llama 1/2、CodeLLama、StarCoder等。 MFTCoder支持Lora和QLora,這顯著減少了需要訓練的模型訓練參數數量。在適配這些模型并進行微調的過程中,我們將可訓練參數設置在總參數的0.1%到5%范圍內。大量實踐表明,隨著可訓練參數比例的增加,模型性能不會一直提升而是很快趨于飽和,實踐中觀察到可訓練參數比例不超過5%通常即可實現接近全量微調的性能水平。另外,在這些微調過程中,我們會配置使用3到7個代碼相關的任務。我們通常對20B以下的模型使用Lora模式,而對20B以上的模型使用QLora模式。微調完成后,我們評測了這些模型代碼補全和Text2Code任務上的表現,如表 9的第III列和第IV列所示。文章計算了MFT微調相對于基準模型在HumanEval和MBPP評測集上的平均指標提升幅度,如第5列所示,提升幅度從6.26%到12.75%不等,且在HumanEval上的提升幅度均超過MBPP上的幅度。
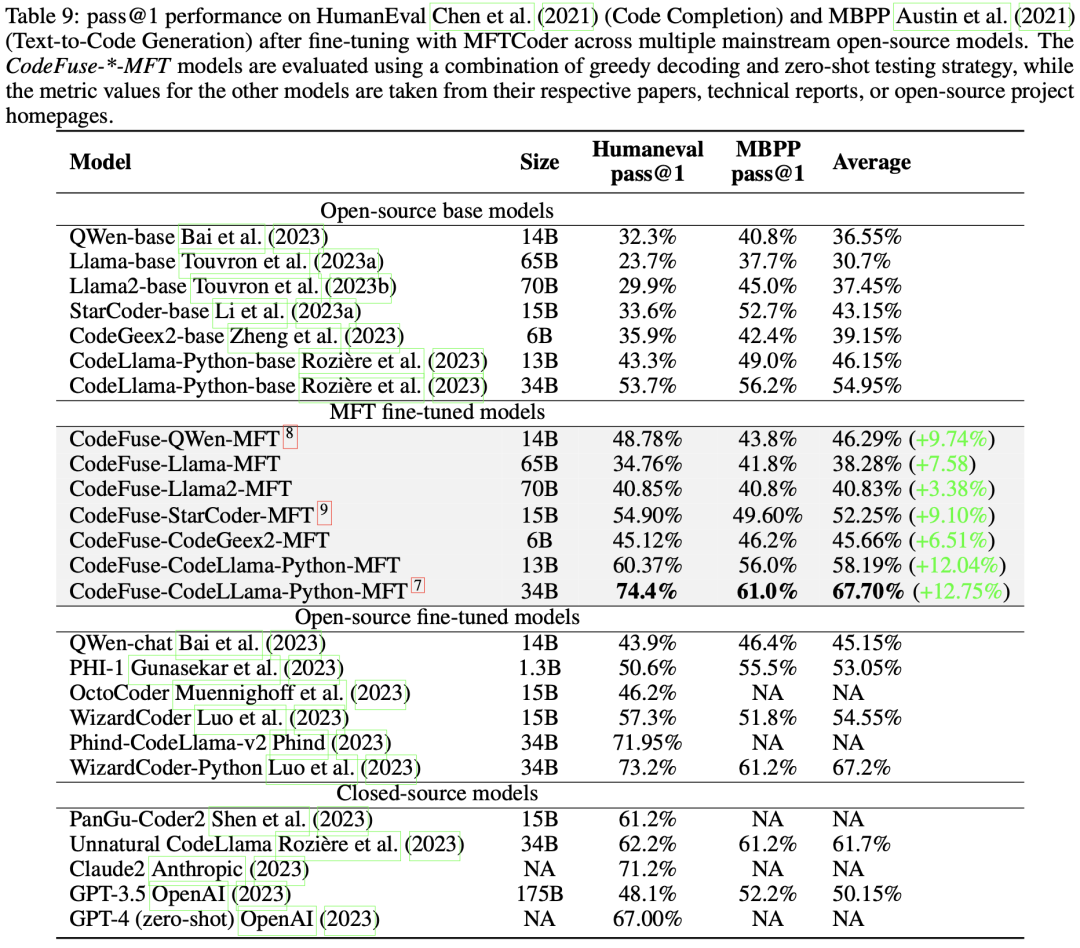
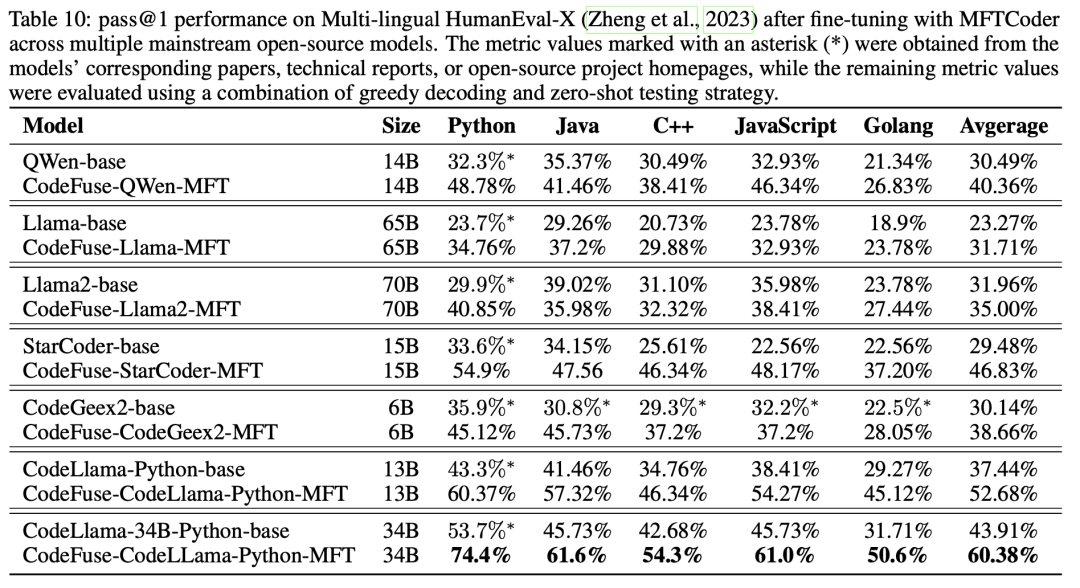
此外,文章還評估了經過MFTCoder微調的模型在多語言基準測試HumanEval-X上的代碼補全性能,如表 10所示。值得注意的是,經過微調的CodeFuse-CodeLLama-Python-MFT(34B)在四種語言(Java、C++、JavaScript和Golang)上的pass@1平均達到了56.88%。
特別地,表 9還展示了一些代表性的經過微調的開源模型(例如OctoPack和WizardCoder-Python)以及閉源模型(例如Claude2和GPT-4)在HumanEval和MBPP上的性能。值得注意的是,我們經過微調的CodeFuse-CodeLLama-34B模型,在HumanEval上取得了pass@1 74.4%的成績,超過了表中列出的所有模型,包括GPT-4(67.00%,zero-shot, 2023年3月)。
對于這個模型,文章還在其他基準測試中評估了它的表現,包括多語言HUMANEVAL-X 、MBPP、DS-1000和CODEFUSEEVAL,并與GPT-3.5和GPT-4進行了比較,如圖 6所示。CodeFuse-CodeLLama-34B在CODEFUSEEVAL-UNITTEST和HUMANEVAL上超越了GPT-4,在代碼翻譯能力上與其相當,但在中文代碼補全(CODEFUSEEVAL-CN)、多語言補全、數據科學分析(DS-1000)和文本到代碼生成(MBPP)能力方面略遜于GPT-4。然而,它在所有評估數據集上都不低于GPT-3.5。
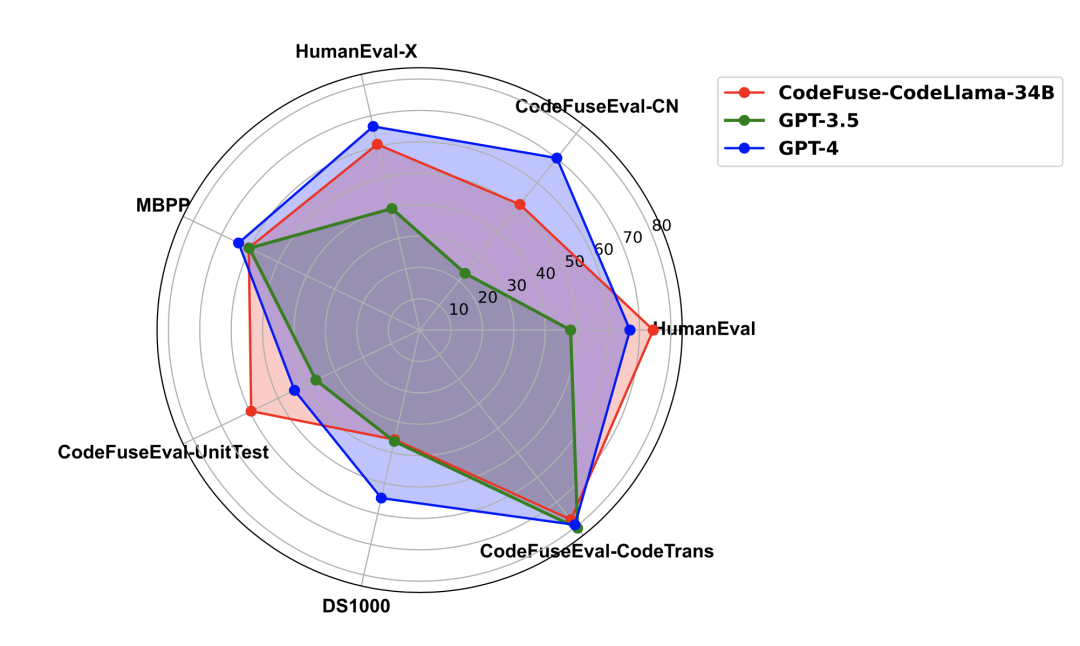
圖6: CodeFuse-CodeLLama-34B在多個代碼評測集上與GPT-3.5/GPT-4的表現對比雷達圖
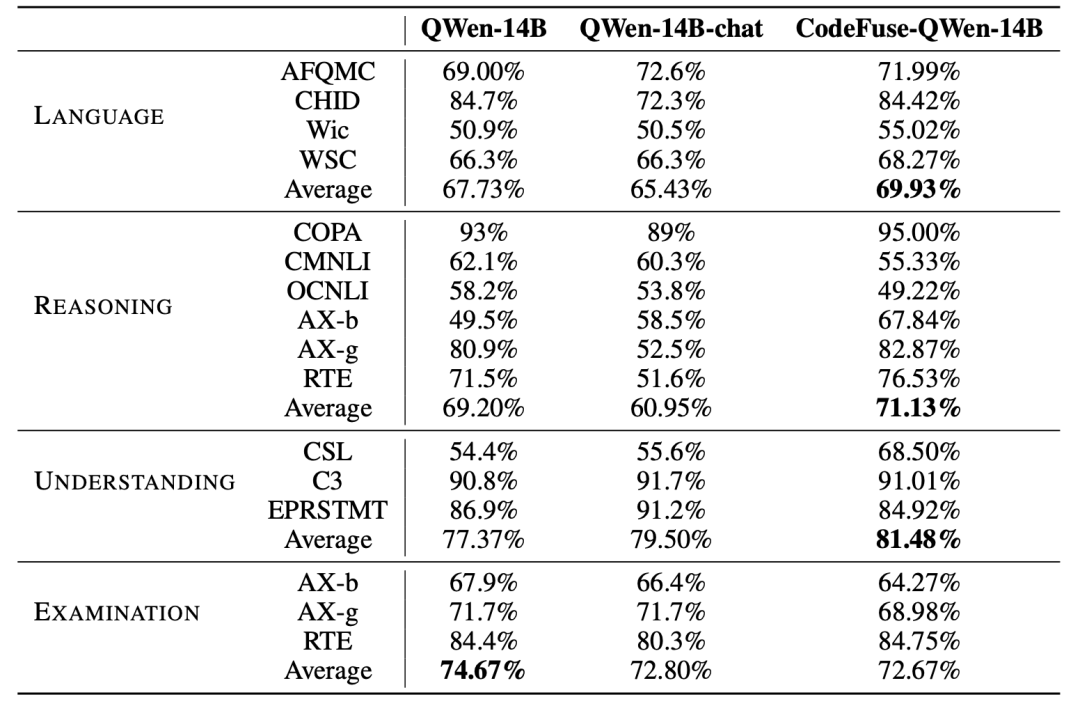
此外,我們進行了一項額外的評估,以評估使用MFTCoder和代碼相關數據微調后對模型在NLP任務上的性能影響。以CODEFUSE-QWEN-14B為案例,我們將其與基準模型QWEN-14B和阿里云官方微調的QWEN-14B-CHAT進行了NLP性能比較,如圖 7所示。顯然,CODEFUSE-QWEN-14B在NLP任務上的能力沒有下降,相反地,與其他兩個模型相比,它在語言(AFQMC, CHID, Wic, WSC)、推理(COPA, CMNLI, OCNLI, AX-b, AX-g, RTE)和理解能力(CSL, C3, EPRSTMT)方面表現出輕微的提升。
然而,與基準模型QWEN-14B相比,其學科綜合能力(MMLU, C-Eval, ARC-c)略有下降,類似的下降現象也出現在QWEN-14B-CHAT模型上,細節數據如表 11所示。多個任務(包括Coding)總體平均,CodeFuse-QWen-14B相比Qwen-14B和QWen-14B-chat分別提升了2.56%和4.82%,而QWen-14B-chat相比QWen-14B降低了2.26%。
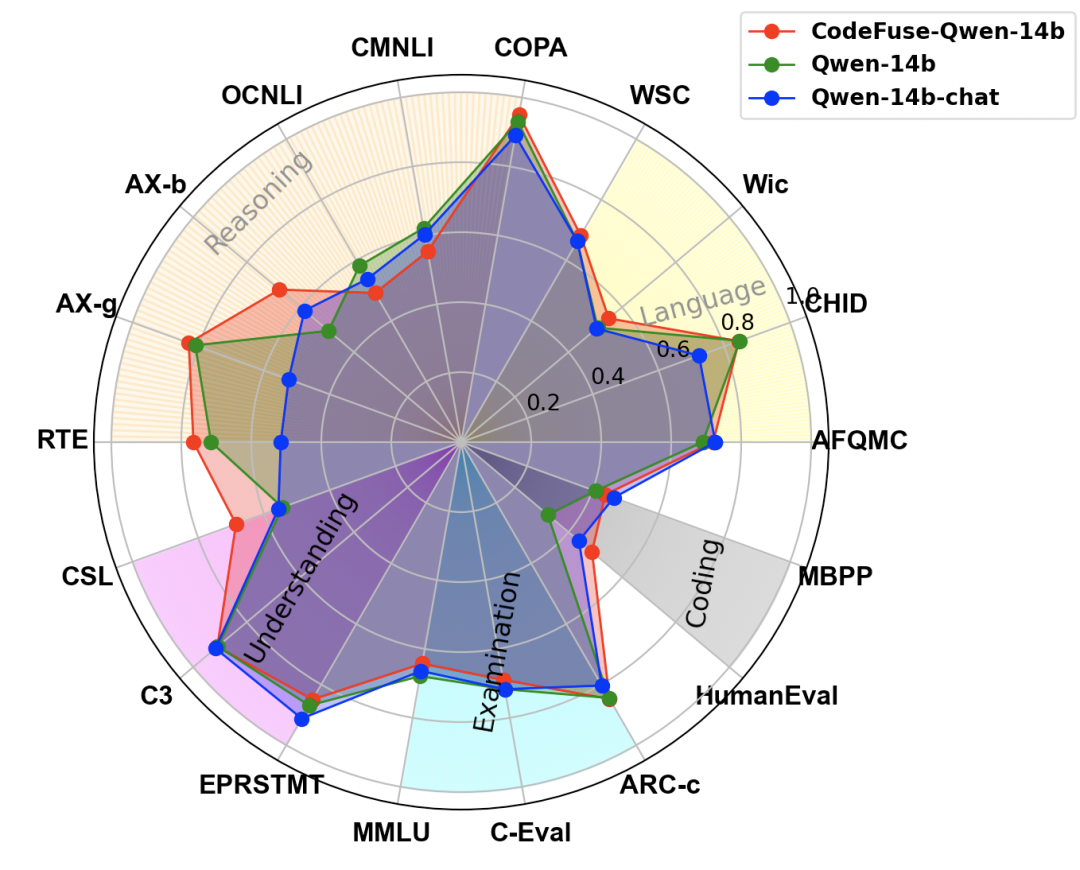
圖7:CodeFuse-QWen-14B與Qwen-14B、QWen-14B-chat在NLP與Coding評測任務上的表現對比雷達圖
Table 11: Comparasion of CodeFuse-QWen-14B, QWen-14B and QWen-14B-chat on NLP tasks.
總結
本文介紹了MFTCoder,它將多任務學習引入到(代碼)大模型微調階段,通過設計或應用多種均衡損失函數有效緩解多任務學習中數據量不均衡、難易不一、收斂速度不一致的挑戰性問題,大量實驗結果表明,多任務微調的模型比每個下游任務單獨微調的模型和多任務數據混合為一后微調的模型表現更好。MFTCoder提供了高效的訓練方案,包括高效的數據Tokenization模式和PEFT支持,并提供了高質量的指令數據集構建方案。此外,MFTCoder已經適配了許多目前流行的開源大模型,其中以CodeLLama-34B-Python為底座,使用MFTCoder微調得到的CodeFuse-CodeLLama-34B模型在HumanEval數據集上取得了74.4%的pass@1得分,超過了GPT-4(67%, zero-shot, 2023年3月)。
具體參考論文: https://arxiv.org/pdf/2311.02303.pdf,以下是本文引用到的論文。
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2023. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv:cs.LG/1910.10683
Armen Aghajanyan, Anchit Gupta, Akshat Shrivastava, Xilun Chen, Luke Zettlemoyer, and Sonal Gupta. 2021. Muppet: Massive Multi-task Representations with Pre-Finetuning. arXiv:cs.CL/2101.11038
Vamsi Aribandi, Yi Tay, Tal Schuster, Jinfeng Rao, Huaixiu Steven Zheng, Sanket Vaibhav Mehta, Honglei Zhuang, Vinh Q. Tran, Dara Bahri, Jianmo Ni, Jai Gupta, Kai Hui, Sebastian Ruder, and Donald Metzler. 2022. ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning. arXiv:cs.CL/2111.10952
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. LoRA: Low-Rank Adaptation of Large Language Models. arXiv:cs.CL/2106.09685
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. QLoRA: Efficient Finetuning of Quantized LLMs. arXiv:cs.LG/2305.14314
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2022. Self-instruct: Aligning language model with self generated instructions.arXiv preprint arXiv:2212.10560(2022).
Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio Ce?sar Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, et al. 2023. Textbooks Are All You Need.arXiv preprint arXiv:2306.11644(2023).
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. 2023c. CAMEL: Communicative Agents for "Mind" Exploration of Large Scale Language Model Society. arXiv:cs.AI/2303.17760
Peng Di, Jianguo Li, Hang Yu, Wei Jiang, Wenting Cai, Yang Cao, Chaoyu Chen, Dajun Chen, Hongwei Chen, Liang Chen, Gang Fan, Jie Gong, Zi Gong, Wen Hu, Tingting Guo, Zhichao Lei, Ting Li, Zheng Li, Ming Liang, Cong Liao, Bingchang Liu, Jiachen Liu, Zhiwei Liu, Shaojun Lu, Min Shen, Guangpei Wang, Huan Wang, Zhi Wang, Zhaogui Xu, Jiawei Yang, Qing Ye, Gehao Zhang, Yu Zhang, Zelin Zhao, Xunjin Zheng, Hailian Zhou, Lifu Zhu, and Xianying Zhu. 2023. CodeFuse-13B: A Pretrained Multi-lingual Code Large Language Model. arXiv:cs.SE/2310.06266
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023b. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023).
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-Efficient Transfer Learning for NLP. arXiv:cs.LG/1902.00751
Bo Liu, Yihao Feng, Peter Stone, and Qiang Liu. 2023. FAMO: Fast Adaptive Multitask Optimization. arXiv:cs.LG/2306.03792
Baptiste Rozie?re, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Je?re?my Rapin, et al. 2023. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950(2023).
Diederik P. Kingma and Jimmy Ba. 2017. Adam: A Method for Stochastic Optimization. arXiv:cs.LG/1412.6980
Qinkai Zheng, Xiao Xia, Xu Zou, Yuxiao Dong, Shan Wang, Yufei Xue, Zihan Wang, Lei Shen, Andi Wang, Yang Li, Teng Su, Zhilin Yang, and Jie Tang. 2023. CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Evaluations on HumanEval-X. InKDD.
Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Zettlemoyer, Scott Wen tau Yih, Daniel Fried, Sida Wang, and Tao Yu. 2022. DS-1000: A Natural and Reliable Benchmark for Data Science Code Generation.ArXivabs/2211.11501 (2022).
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program Synthesis with Large Language Models.arXiv preprint arXiv:2108.07732(2021).
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri and et al.. 2021. Evaluating Large Language Models Trained on Code. (2021). arXiv:cs.LG/2107.03374
編輯:黃飛
-
函數
+關注
關注
3文章
4344瀏覽量
62862 -
python
+關注
關注
56文章
4806瀏覽量
84933 -
GPT
+關注
關注
0文章
357瀏覽量
15461 -
ChatGPT
+關注
關注
29文章
1566瀏覽量
7917 -
大模型
+關注
關注
2文章
2524瀏覽量
2993
原文標題:干貨!MFTCoder論文多任務微調技術詳解
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
第29章 STemWin多任務(uCOS-III)
基于 stm32 的 FreeRTOS 的詳細移植步驟及其多任務應用 精選資料分享
多任務編程多任務處理是指什么
基于任務鏈的實時多任務軟件可靠性建模
基于消息驅動的多任務操作機制
基于Protothread的實時多任務系統設計
stm32基于FreeRTOS的多任務程序

一個大規模多任務學習框架μ2Net
PicoSem:Arduino框架下的Raspberry多任務





 工商網監
工商網監
評論