 Redis能夠勝任存儲工作嗎?
Redis能夠勝任存儲工作嗎?
大多數數據庫,由于經常和磁盤打交道,在高并發場景下,響應會非常的慢。為了解決這種速度差異,大多數系統都習慣性的加入一個緩存層,來加速數據的讀取。redis由于它優秀的處理能力和豐富的數據結構,已經成為了事實上的分布式緩存標準
但是,如果你以為redis只能做緩存的話,那就太小看它了。
redis豐富的數據結構,使得它的業務使用場景非常廣泛,加上rdb的持久化特性,它甚至能夠被當作落地的數據庫使用。在這種情況下,redis能夠撐起大多數互聯網公司,尤其是社交、游戲、直播類公司的半壁江山。
1. Redis能夠勝任存儲工作
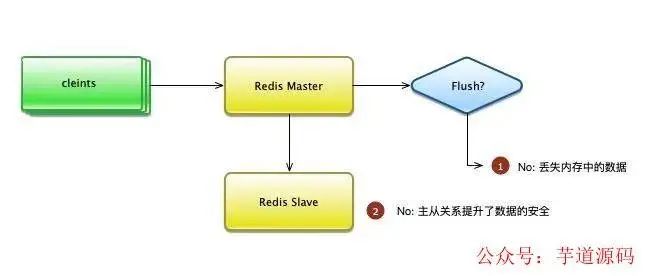
redis提供了非常豐富的集群模式:主從、哨兵、cluster,滿足服務高可用的需求。同時,redis提供了兩種持久化方式:aof和rdb,常用的是rdb。
通過bgsave指令,主進程會fork出新的進程,回寫磁盤。bgsave相當于做了一個快照,由于它并沒有WAL日志和checkpoint機制,是無法做到實時備份的。如果機器突然斷電,那就很容易丟失數據。
幸運的是,redis是內存型的數據庫,主叢同步的速度是非常快的。如果你的集群維護的好,內存分配的合理,那么除非機房斷電,否則redis的SLA,會一直保持在非常高的水平。
 img
img
聽起來不是絕對可靠啊,有丟失數據的可能!這在一般CRUD的業務中,是無法忍受的。但為什么redis能夠滿足大多數互聯網公司的需求?這也是由業務屬性所決定的。
在決定最大限度擁抱redis之前,你需要確認你的業務是否有以下特點:
除了核心業務,是否大多數業務對于數據的可靠性要求較低,丟失一兩條數據是可以忍受的?
面對的是C端用戶,可根據用戶ID快速定位到一類數據,數據集合普遍較小?無大量范圍查詢需求?
是否能忍受內存型數據的成本需求?
是否業務幾乎不需要事務操作?
很幸運的是,這類業務需求特別的多。比如常見的社交,游戲、直播、運營類業務,都是可以完全依賴Redis的。
2. Redis 應用場景
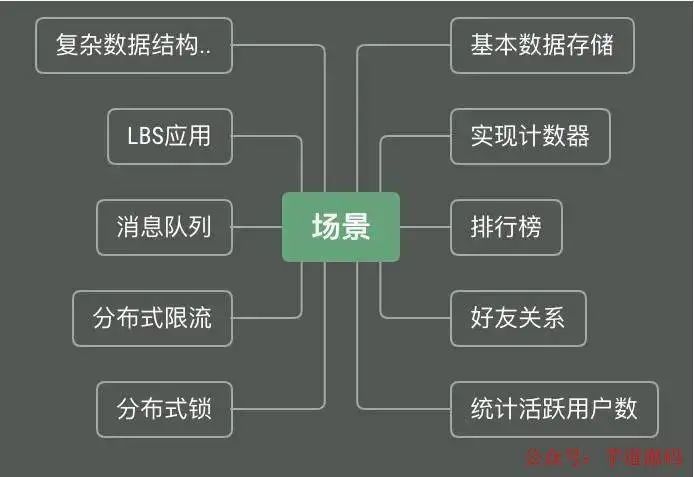
Redis具有松散的文檔結構,豐富的數據類型,能夠適應千變萬化的scheme變更需求,接下來我將介紹Redis除緩存外的大量的應用場景。
 img
img
2.1 基本用戶數據存儲
在傳統的數據庫設計中,用戶表是非常難以設計的,變更的時候會傷筋動骨。使用Redis的hash結構,可以實現松散的數據模型設計。某些不固定,驗證型的功能屬性,可以以JSON接口直接存儲在hash的value中。使用hash結構,可以采用HGET和HMGET等指令,只獲取自己所需要的數據,在使用上也是非常便捷的。
>HSETuser:199929sexm >HSETuser:199929age22 >HGETALLuser:199929 1)"sex" 2)"m" 3)"age" 4)"22"
這種非統計型的、讀多寫少的場景,是非常適合使用KV結構進行存儲的。Redis的hash結構提供了非常豐富的指令,某個屬性也可以使用HINCRBY進行遞增遞減,非常的方便。
2.2 實現計數器
上面稍微提了一下HINCRBY指令,而對于Redis的Key本身來說,也有INCRBY指令,實現某個值的遞增遞減。
比如以下場景:統計某個帖子的點贊數;存放某個話題的關注數;存放某個標簽的粉絲數;存儲一個大體的評論數;某個帖子熱度;紅點消息數;點贊、喜歡、收藏數等。
>INCRBYfeedlike1 >INCRBYfeedlike1 >GETfeedlike "2"
像微博這樣容易出現熱點的業務,傳統的數據庫,肯定是撐不住的,就要借助于內存數據庫。由于Redis的速度非常快,就不用再采用傳統DB非常慢的count操作,所有這種遞增操作都是毫秒級別的,而且效果都是實時的。
2.3 排行榜
排行榜能提高參與者的積極性,所以這項業務非常常見,它本質上是一個topn的問題。
Redis中有一個叫做zset的數據結構,使用跳表實現的有序列表,可以很容易實現排行榜一類的問題。當存入zset中的數據,達到千萬甚至是億的級別,依然能夠保持非常高的并發讀寫,且擁有非常棒的平均響應時間(5ms以內)。
使用zadd 可以添加新的記錄,我們會使用排行相關的分數,作為記錄的score值,然后使用zrevrange指令即可獲取實時的排行榜數據,而zrevrank則可以非常容易的獲取用戶的實時排名。
>ZADDsorted2021-0755dog0 >ZADDsorted2021-0789dog1 >ZADDsorted2021-0732dog2 >ZCARDsorted2021-07 >3 >ZREVRANGEsorted2021-070-10WITHSCORES#top10排行榜 1)"dog1" 2)"89" 3)"dog0" 4)"55" 5)"dog2" 6)"32"
2.4 好友關系
set結構,是一個沒有重復數據的集合,你可以將某個用戶的關注列表、粉絲列表、雙向關注列表、黑名單、點贊列表等,使用獨立的zset進行存儲。
使用ZADD、ZRANK等,將用戶的黑名單使用ZADD添加,ZRANK使用返回的sorce值判斷是否存在黑名單中。使用sinter指令,可以獲取A和B的共同好友。
除了好友關系,有著明確黑名單、白名單業務場景的數據,都可以使用set結構進行存儲。這種業務場景還有很多,比如某個用戶上傳的通訊錄,計算通訊錄的好友關系等等。
在實際使用中,使用zset存儲這類關系的更多一些。zset同set一樣,都不允許有重復值,但zset多了一個score字段,我們可以存儲一個時間戳,用來標明關系建立所發生的時間,有更明確的業務含義。
2.5 統計活躍用戶數
類似統計每天的活躍用戶、用戶簽到、用戶在線狀態,這種零散的需求,實在是太多了。如果為每一個用戶存儲一個bool變量,那占用的空間就太多了。這種情況下,我們可以使用bitmap結構,來節省大量的存儲空間。
>SETBITonline:2021-07-2338765203331 >SETBITonline:2021-07-2438765203331 >GETBITonline:2021-07-233876520333 1 >BITOPANDactiveonline:2021-07-23online:2021-07-24 >GETBITactive3876520333 1 >DEBUGOBJECTonline:2021-07-23 Valueat:0x7fdfde438bf0refcount:1encoding:rawserializedlength:5506446lru:16410558lru_seconds_idle:5 (0.96s)
注意,如果你的id很大,你需要先進行一次預處理,否則它會占用非常多的內存。
bitmap包含一串連續的2進制數字,使用1bit來表示真假問題。在bitmap上,可以使用and、or、xor等位操作(bitop)。
2.6 分布式鎖
Redis的分布式鎖,是一種輕量級的解決方案。雖然它的可靠性比不上Zookeeper之類的系統,但Redis分布式鎖有著極高的吞吐量。
一個最簡陋的加鎖動作,可以使用redis帶nx和px參數的set指令去完成。下面是一小段簡單的分布式樣例代碼。
publicStringlock(Stringkey,inttimeOutSecond){ for(;;){ Stringstamp=String.valueOf(System.nanoTime()); booleanexist=redisTemplate.opsForValue().setIfAbsent(key,stamp,timeOutSecond,TimeUnit.SECONDS); if(exist){ returnstamp; } } } publicvoidunlock(Stringkey,Stringstamp){ redisTemplate.execute(script,Arrays.asList(key),stamp); }
刪除操作的lua為。
localstamp=ARGV[1]
localkey=KEYS[1]
localcurrent=redis.call("GET",key)
ifstamp==currentthen
redis.call("DEL",key)
return"OK"
end
redisson的RedLock,是使用最普遍的分布式鎖解決方案,有讀寫鎖的差別,并處理了多redis實例情況下的異常問題。
2.7 分布式限流
使用計數器去實現簡單的限流,在Redis中是非常方便的,只需要使用incr配合expire指令即可。
incrkey expirekey1
這種簡單的實現,通常來說不會有問題,但在流量比較大的情況下,在時間跨度上會有流量突然飆升的風險。根本原因,就是這種時間切分方式太固定了,沒有類似滑動窗口這種平滑的過度方案。
同樣是redisson的RRateLimiter,實現了與guava中類似的分布式限流工具類,使用非常便捷。下面是一個簡短的例子:
RRateLimiterlimiter=redisson.getRateLimiter("xjjdogLimiter");
//只需要初始化一次
//每2秒鐘5個許可
limiter.trySetRate(RateType.OVERALL,5,2,RateIntervalUnit.SECONDS);
//沒有可用的許可,將一直阻塞
limiter.acquire(3);
2.8 消息隊列
redis可以實現簡單的隊列。在生產者端,使用LPUSH加入到某個列表中;在消費端,不斷的使用RPOP指令取出這些數據,或者使用阻塞的BRPOP指令獲取數據,適合小規模的搶購需求。
Redis還有PUB/SUB模式,不過pubsub更適合做消息廣播之類的業務。
在Redis5.0中,增加了stream類型的數據結構。它比較類似于Kafka,有主題和消費組的概念,可以實現多播以及持久化,已經能滿足大多數業務需求了。
2.9 LBS應用
早早在Redis3.2版本,就推出了GEO功能。通過GEOADD指令追加lat、lng經緯數據,可以實現坐標之間的距離計算、包含關系計算、附近的人等功能。
關于GEO功能,最強大的開源方案是基于PostgreSQL的PostGIS,但對于一般規模的GEO服務,redis已經足夠用了。
2.10 更多擴展應用場景
要看redis能干什么,就不得不提以下java的客戶端類庫redisson。redisson包含豐富的分布式數據結構,全部是基于redis進行設計的。
redisson提供了比如Set、 SetMultimap、 ScoredSortedSet、 SortedSet, Map、 ConcurrentMap、 List、 ListMultimap、 Queue、BlockingQueue等非常多的數據結構,使得基于redis的編程更加的方便。在github上,可以看到有上百個這樣的數據結構:https://github.com/redisson/redisson/tree/master/redisson/src/main/java/org/redisson/api。
對于某個語言來說,基本的數組、鏈表、集合等api,配合起來能夠完成大部分業務的開發。Redis也不例外,它擁有這些基本的api操作能力,同樣能夠組合成分布式的、線程安全的高并發應用。
由于Redis是基于內存的,所以它的速度非常快,我們也會把它當作一個中間數據的存儲地去使用。比如一些公用的配置,放到redis中進行分享,它就充當了一個配置中心的作用;比如把JWT的令牌存放到Redis中,就可以突破JWT的一些限制,做到安全登出。
3. 一站式Redis面臨的挑戰
redis的數據結構豐富,一般不會在功能性上造成困擾。但隨著請求量的增加,SLA要求的提高,我們勢必會對Redis進行一些改造和定制性開發。
3.1 高可用挑戰
redis提供了主從、哨兵、cluster等三種集群模式,其中cluster模式為目前大多數公司所采用的方式。
但是,redis的cluster模式,有不少的硬傷。redis cluster采用虛擬槽的概念,把所有的key映射到 0~16383個整數槽內,屬于無中心化的架構。但它的維護成本較高,slave也不能夠參與讀取操作。
它的主要問題,在于一些批量操作的限制。由于key被hash到多臺機器上,所以mget、hmset、sunion等操作就非常的不友好,經常發生性能問題。
redis的主從模式是最簡單的模式,但無法做到自動failover,通常在主從切換后,還需要修改業務代碼,這是不能忍受的。即使加上haproxy這樣的負載均衡組件,復雜性也是非常高的。
哨兵模式在主從數量比較多的時候,能夠顯著的體現它的價值。一個哨兵集群,能夠監控成百上千個集群,但是哨兵集群本身的維護是比較困難的。幸運的是,redis的文本協議非常簡單,在netty中,甚至直接提供了redis的codec。自研一套哨兵系統,加強它的功能,是可行的。
3.2 冷熱數據分離
redis的特點是,不管什么數據,都一股腦地搞到內存里做計算,這對于有時間序列概念,有冷熱數據之分的業務,造成了非常大的成本考驗。為什么大多數開發者喜歡把數據存放在MySQL中,而不是Redis中?除了事務性要求以外,很大原因是歷史數據的問題。
通常,這種冷熱數據的切換,是由中間件完成的。我們上面也談到了,Redis是一個文本協議,非常簡單。做一個中間件,或者做一個協議兼容的Redis模擬存儲,是比較容易的。
比如我們Redis中,只保留最近一年的活躍用戶。一個好幾年不活躍的用戶,突然間訪問了系統,這時候我們獲取數據的時候,就需要中間件進行轉換,從容量更大,速度更慢的存儲中查找。
這個時候,Redis的作用,更像是一個熱庫,更像是一個傳統cache層做的事情,發生在業務已經上規模的時候。但是注意,直到此時,我們的業務層代碼,一直都是操作的redis的api。它們使用這眾多的函數指令,并不關心數據到底是真正存儲在redis中,還是在ssdb中。
3.3 功能性需求
redis還能玩很多花樣。舉個例子,全文搜索。很多人都會首選es,但redis生態就提供了一個模塊:RediSearch,可以做查詢,可以做filter。
但我們通常還會有更多的需求,比如統計類、搜索類、運營效果分析等。這類需求與大數據相關,即使是傳統的DB也不能勝任。這時候,我們當然要把redis中的數據,導入到其他平臺進行計算啦。
如果你選擇的是redis數據庫,那么dba打交道的,就是rdb,而不是binlog。有很多的rdb解析工具(比如redis-rdb-tools),能夠定期把rdb解析成記錄,導入到hadoop等其他平臺。
此時,rdb成為所有團隊的中樞,成為基本的數據交換格式。導入到其他db后的業務,該怎么玩怎么玩,完全不會因為業務系統選用了redis就無法運轉。
4. 總結
大多數業務系統,跑在redis上,這是很多一直使用MySQL做業務系統的同學所不能想象的。看完了上面的介紹,相信你能夠對redis能夠實現的存儲功能有個大體的了解。打開你的社交app、游戲app、視頻app,看一下它們的功能,能夠涵蓋多少呢?
我這里要強調的是,某些數據,并不是一定要落地到RDBMS才算安全,它們并不是一個強需求。
那既然redis這么厲害,為什么還要有mysql、tidb這樣的存儲呢?關鍵還在于業務屬性上。
如果一個業務系統,每次交互的數據,都是一個非常大的結果集,并涉及到非常復雜的統計、過濾工作,那么RDBMS是必須的;但如果一個系統,能夠通過某個標識,快速定位到一類數據,這一類數據在可以預見的未來,是有限的,那就非常適合Redis存儲。
一個電商系統,選用redis做存儲就是作死,但一個社交系統就快活的多。在合適的場景選用合適的工具,才是我們應該做的。
但是一個系統,能否在產品驗證期,就能快速的響應變化,快速開發上線,才是成功的關鍵。這也是使用redis做數據庫,所能夠帶來的最大好處。千萬別被那概率極低的丟數據場景,給嚇怕了。比起產品成功,你的系統即使是牢如鋼鐵,也一文不值。
審核編輯:劉清
-
計數器
+關注
關注
32文章
2259瀏覽量
94863 -
SLA
+關注
關注
1文章
54瀏覽量
18299 -
Hash算法
+關注
關注
0文章
43瀏覽量
7407 -
Redis
+關注
關注
0文章
377瀏覽量
10905
原文標題:Redis只能做緩存?太out了!
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何使用Rust連接Redis
Redis Stream應用案例
redis概述
如何使得redis中的數據不再有
簡要分析Redis的特性
redis幾個認識誤區
Redis混合存儲產品與架構介紹
關于redis中數據存儲的機制解析
redis工作原理
Redis持久化機制的實現原理和使用技巧
如何使用Redis更節省內存?

Redis架構演化之路
Redis中的使用






 工商網監
工商網監
評論