 降低時序報告中邏輯延遲的方法
降低時序報告中邏輯延遲的方法
1. 引言
在FPGA邏輯電路設計中,FPGA設計能達到的最高性能往往由以下因素決定:
? 工作時鐘偏移和時鐘不確定性;
? 邏輯延遲:在一個時鐘周期內信號經過的邏輯量;
Vivado軟件完成布局布線后,我們可以打開時序分析報告,來查看時序沒有過的路徑是由哪些因素導致的時序違規。Vivado會通過列表形式展示每條時序違規路徑的信息,如下圖所示。

雙擊上面表中的其中一條路徑,會展開關于該路徑更詳細的時序報告,如下圖:
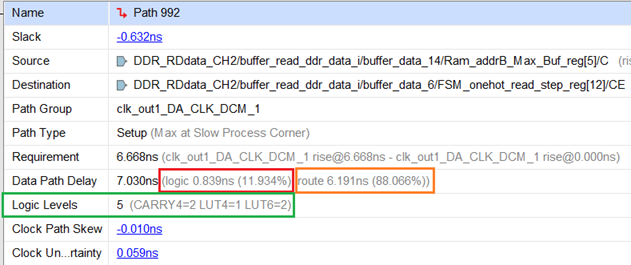
上圖這個時序違例的例子,可以看到,該路徑邏輯延遲貢獻了11.934%的延遲量、路徑延遲貢獻了88.066%延遲量。該路徑邏輯級數為5,經過了2個CARRY4、1個LUT4和2個LUT6。
2. 降低邏輯延遲的方法
如果邏輯延遲大,我們需要查看該路徑是不是只包含CLB器件,還是說該路徑還經過了如DSP、RAMB、URAM、FIFO或GT等器件。
2.1 路徑只包含CLB器件
常規布線路徑是在寄存器(FD*)或移位寄存器(SRL*)之間的路徑,它們經過一些 LUT、MUXF 和 CARRY 元件。通常會遇到以下幾種情形導致邏輯延遲過大:
(1)較高邏輯層數(logic levels)的組合電路。用戶在兩個寄存器之間插入的組合邏輯過于復雜,級聯了過多的LUT、CARRY等元件,導致邏輯延遲過高時序過不了。如下圖中,兩個寄存器之間有一個logic levels為5層的組合邏輯。
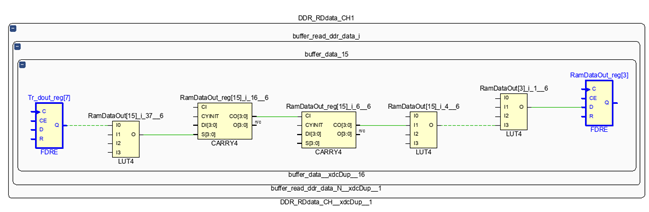
建議的解決方案: 在設計的早期階段,通過TCL命令“report_qor_assessment”,早些識別出邏輯層數較高組合邏輯,通過代碼優化手段來降低邏輯層次。或者,在綜合的時候,將“-retiming”全局變量勾選上。
(2)路徑上有很多小的級聯LUT(LUT1-LUT4)。這些多個小的級聯查找表是可以被合并成數量更少的LUT的。阻止這些級聯LUT合并的原因可能如下:
- 有些小的LUT表存在一些扇出(扇出為10,或者更高);
- 用戶使用了一些properties語法,比如:KEEP、KEEP_HIERARCHY、DON’T_TOUCH或MARK_DEBUG。
建議的解決方案: 移除掉這些properties語法,重新編譯綜合工程。
(3)路徑上有單個CARRY(非級聯)限制了LUT的優化,導致vivado布局也不是最優。
建議的解決方案: 在綜合的時候,使用“FewerCarryChains”綜合指令。或者對該CELL在opt_design階段設置CARRY_REMAP屬性。(具體使用方法可以查看UG904)
2.2 路徑包含其他復雜器件(DSP、RAM等)
如果時序路徑上會經過宏原語元件(macro primitives)如DSP、RAM、URAM、FIFO或GT_CHANNEL等元件,布局布線的難度會加大,也會導致更高的布局布線延遲。降低這些路徑的邏輯延遲方法如下:
(1)在進出宏原語元件電路周圍,增加額外的流水結構。比如:
- 原設計是用的一個大位寬RAM緩存數據,把這個大位寬RAM拆分成多個并行的小位寬RAM實現相同的功能。
- 原設計乘法器為2級流水乘法器,把它改為2級以上的流水乘法器。
- 數據進出宏原語元件時,都用寄存器打一拍等。
(2)在包含宏原語元件的路徑上減少邏輯層數,這點對改善整個設計的性能提升很明顯。
Tips: 在修改RTL之前,可以嘗試把DSP、RAM、URAM的自帶流水寄存器使能都打開,然后重新編譯工程,看時序是否能有改善。比如將下面這條路徑:

設置如下屬性:
set_property -dict {DOA_REG 1 DOB REG 1} [get_cells xx/ramb18_inst]
注意,由于使能這些寄存器后,邏輯時序會有變動,此時的RTL功能和你原先設計是有出入的,所以不用生成bitstream,這樣操作的目的只是為了看時序能如何改善。
3. 總結
本文主要介紹了如何減少時序報告中的邏輯延遲,下期文章我們將向大家介紹如何降低路徑延遲的方法。如果覺得我們原創或引用的文章寫的還不錯,幫忙點贊和推薦吧,謝謝您的關注。
-
FPGA
+關注
關注
1630文章
21796瀏覽量
605177 -
邏輯電路
+關注
關注
13文章
494瀏覽量
42677 -
FPGA設計
+關注
關注
9文章
428瀏覽量
26581 -
時序
+關注
關注
5文章
392瀏覽量
37387 -
Vivado
+關注
關注
19文章
815瀏覽量
66792
發布評論請先 登錄
相關推薦
FPGA實戰演練邏輯篇65:CMOS攝像頭接口時序設計5時序報告
在FPGA中何時用組合邏輯或時序邏輯
時序邏輯電路的分析方法





 工商網監
工商網監
評論