 TPU內存(二)
TPU內存(二)
我們知道,TPU中的數據結構是張量,可以看做是一個四維數組,形狀為(N,C,H,W)。
要描述一個張量在算能的TPU上是如何排列的,我們首先要知道一個概念。 那是Stride。
它用于衡量同一 NPU 中張量的兩個元素之間的距離。

例如,W_Stride 表示張量 n,c,h,w 和 n,c,h,w+1 之間有多少個元素
而H_stride表示從n,c,h,w到n,c,h+1,w我們需要經過的元素個數
同樣,我們可以得到C_stride和N_stride在Global memory上的含義。
但是對于local memory,我們可以看到是有所不同的,C_stride指的是從n,c,h,w到n,c+X,h,w的元素個數,其中X表示 NPU 的數量。

而在N_stride中我們還需要考慮我們開始存儲數據的local memory的索引。
稍后我將進一步解釋這一點。
有了tensor的shape和stride,我們基本上就可以得到這個tensor的每個元素在內存上的地址
但是步長的單位是張量中的單個元素,所以對于不同的數據類型,要計算它們的地址,我們還必須將它們的字節數考慮進去。
例如,在一個 F32 張量中,w 和 w+1 個元素之間的實際距離是 1 * 4。
在global memory中,數據以連續的方式存儲,

這很容易理解。 由于global memory是一個完整的DDR,我們把tensor的每個元素挨個存儲,所以w_stride等于1,h_stride等于w,對于c_stride來說,就是w的h倍,n_stride則是c_stride的c倍。
例如,對于形狀為 (2,2,3,2) 的張量,
w_stride為1,每2個元素后開始一個新的h,所以h_stride為2,每個通道包含3 * 2個元素,所以c_stride應該為6,同理,我們可以很容易地得到n_stride, 12。
但是對于本地內存,就變得有點復雜了,
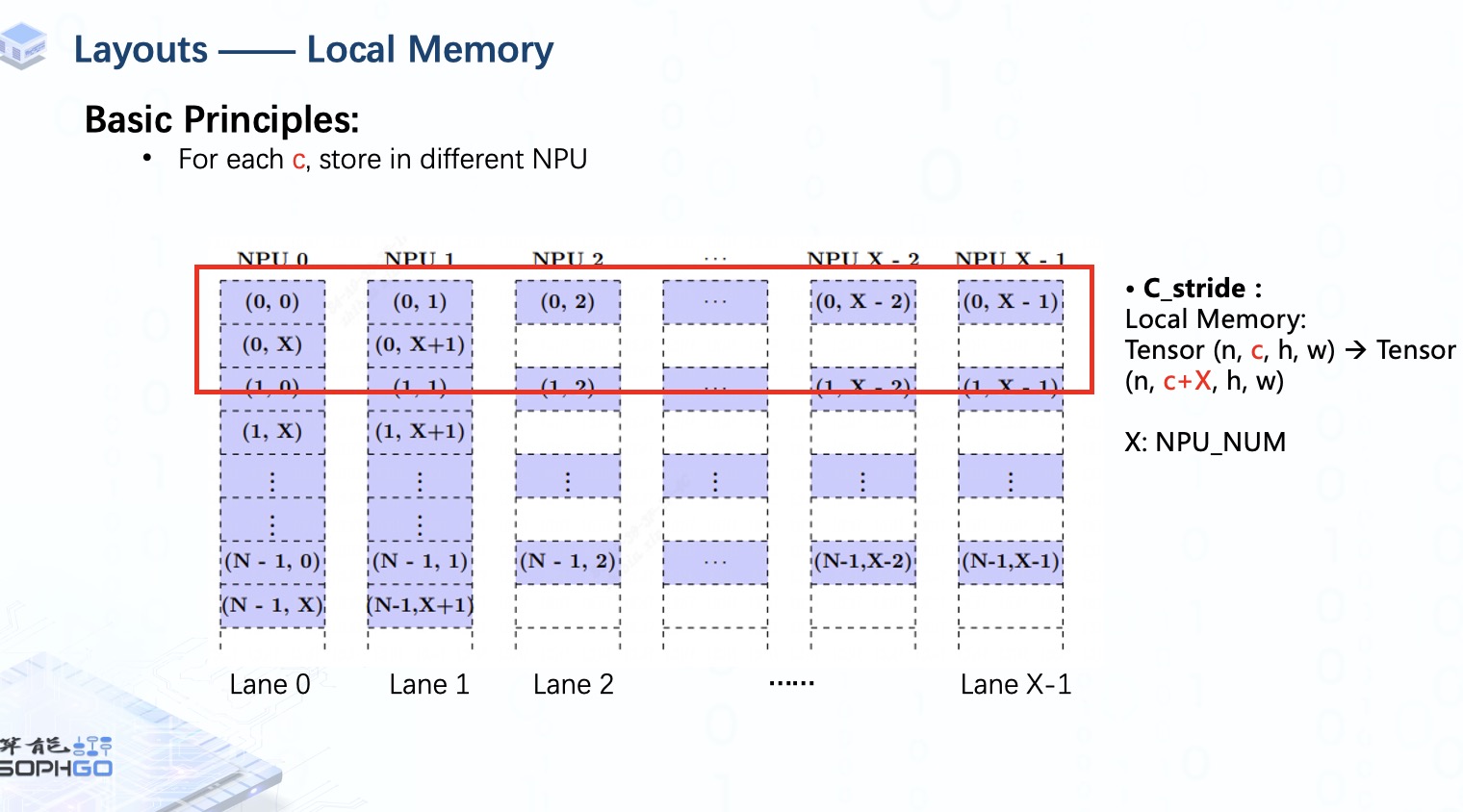
首先,張量的不同通道會被放到不同的NPU上。 如果通道大于 NPU 的數量,它將返回到第一個 NPU開始存放。
這就是為什么local memory的C_stride是n,c,h,w到n,c+X,h,w。 Stride僅衡量同一memory中的距離。
例如,我們使用 X個NPU 來存儲具有 X + 2 個通道的張量,我們將從第一個 NPU 到最后一個 NPU 放入每個通道的元素。 然后其余的通道再次從第一個 NPU 開始存放。
對于張量的每個batch,我們將從同一 NPU 上新的一行開始存儲。

像這個例子中,當我們完成第一批的存儲后,即使同一個bank中的剩余內存為空,我們也不會存儲任何東西,而是重新從NPU0開始。
這就解釋了為什么我們在計算 N_stride 時需要考慮local memory的起始索引。
基于上述原則,local memory中的張量以多種不同方式排布。
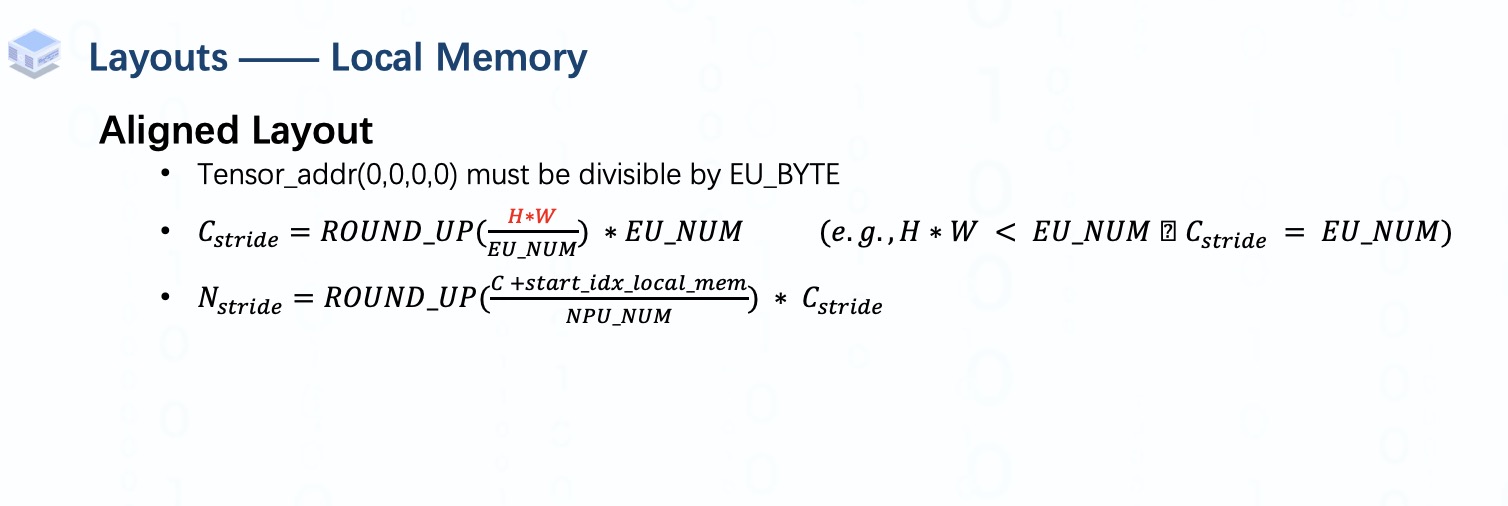
最常用的一種是對齊排布。
這意味著張量的起始地址應該可以被 EU_BYTE 整除。
另外,對于不同通道的數據,用于保存的區域大小應該是EU_NUM的倍數,
從數學角度看,C_stride的計算應該是這樣的(看PPT)。 當H * W小于EU_NUM時,C_stride為EU_NUM。 當大于EU_NUM但小于2倍EU_NUM時,C_stride應為EU_NUM的2倍。
關于N_stride,由于有時通道數大于NPU_NUM或者local memory的起始索引不為零,可能會導致不同通道的數據存儲在同一個NPU中,N_stride的公式也應該做round- up 操作,如PPT中所示。
例如,我們將在具有 64 EU_BYTE 的 TPU 上處理形狀為 (2,3,4,5) 的fp16張量。其中包含了4個NPU,而本地內存的起始索引設置為 0。
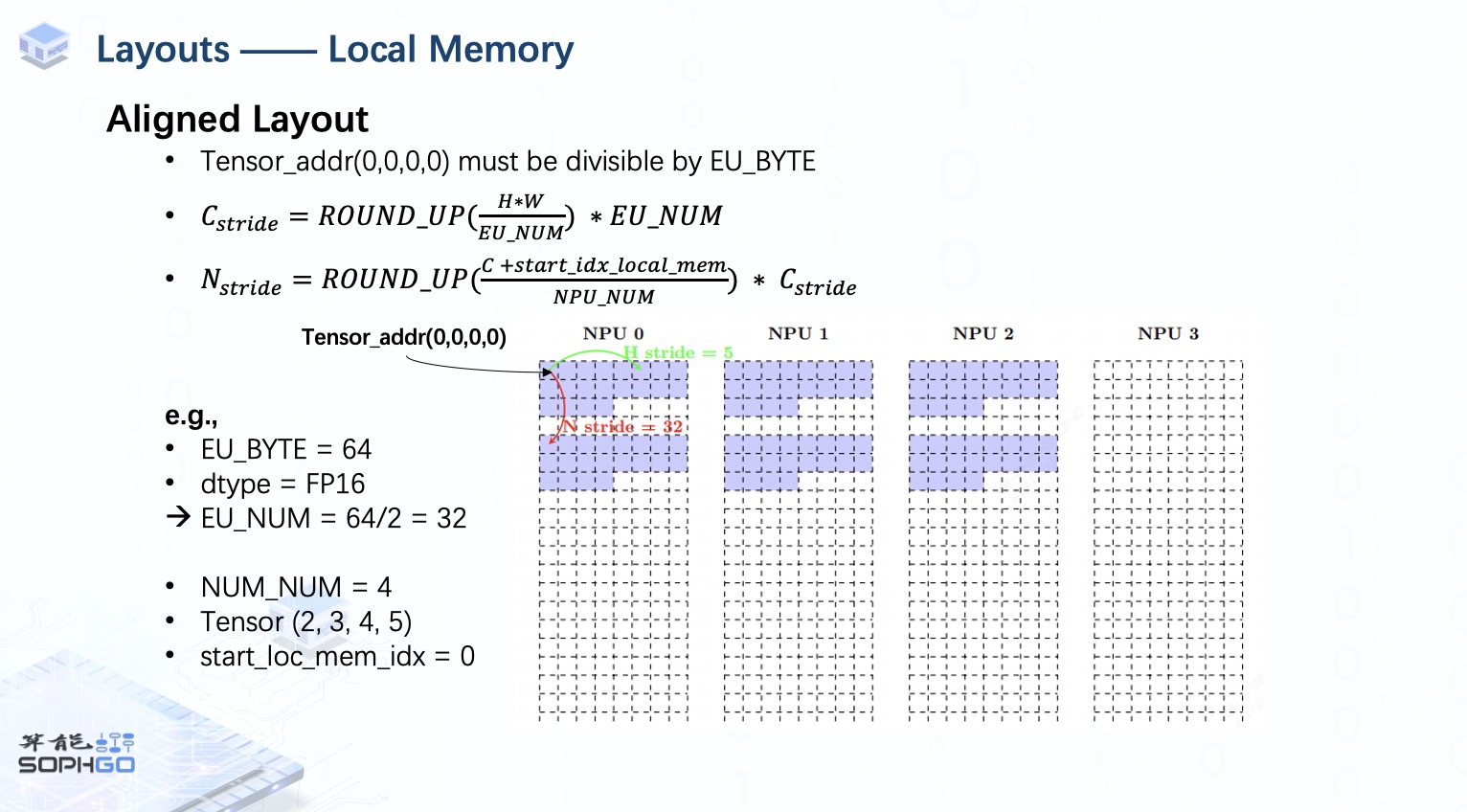
所以我們從NPU0開始存儲張量,W_stride和H_stride顯然是1和5。
對于C_stride,由于H * W小于EU_NUM,所以C_stride為32。
另外,因為這個張量的通道小于 NPU_NUM,所以N_stride 也是 32。
但是當起始索引設置為2時,情況會有點不同,C步長仍然是32,但是由于張量的最后一個通道被存到第一個NPU,下一batch中的數據應該從NPU2的下一行開始存儲,則 N_stride 應為 64。

另一個常見的排布類型就是緊密排布,除了C_stride部分,其余的與對齊排布方式相似。
-
DDR
+關注
關注
11文章
712瀏覽量
65387 -
內存
+關注
關注
8文章
3034瀏覽量
74132 -
數據結構
+關注
關注
3文章
573瀏覽量
40152 -
NPU
+關注
關注
2文章
286瀏覽量
18653
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論