") 基于生成模型的預訓練方法
基于生成模型的預訓練方法
I實驗
總結(jié)
參考
前言
 請?zhí)砑訄D片描述
請?zhí)砑訄D片描述
我們這次要介紹的文章被接收在 ICCV 2023 上,題為:DreamTeacher: Pretraining Image Backbones with Deep Generative Models,我認為是個挺強挺有趣的自監(jiān)督方面的工作。DreamTeacher 用于從預訓練的生成網(wǎng)絡向目標圖像 Backbone 進行知識蒸餾,作為一種通用的預訓練機制,不需要標簽。這篇文章中研究了特征蒸餾,并在可能有任務特定標簽的情況下進行標簽蒸餾,我們會在后文詳細介紹這兩種類型的知識蒸餾。
事實上,之前已經(jīng)在 GiantPandaCV 上介紹過一種 diffusion 去噪自監(jiān)督預訓練方法:DDeP,DDeP 的設計簡單,但去噪預訓練的方法很古老了。然而,DreamTeacher 開創(chuàng)了如何有效使用優(yōu)質(zhì)的生成式模型蒸餾獲得相應的知識。
補充:在 DDeP 這篇文章中,經(jīng)過讀者糾正,我們重新表述了加噪公式:
相關(guān)工作
Discriminative Representation Learning
最近比較流行的處理方法是對比表示學習方法,SimCLR 是第一個在線性探測和遷移學習方面表現(xiàn)出色的方法,而且沒有使用類標簽,相較于監(jiān)督預訓練方法。隨后的工作,如 MoCo,通過引入 memory bank 和梯度停止改進了孿生網(wǎng)絡設計。然而,這些方法依賴于大量的數(shù)據(jù)增強和啟發(fā)式方法來選擇負例,可能不太適用于像 ImageNet 這樣規(guī)模的數(shù)據(jù)集。關(guān)于 memory bank 的概念,memory bank 是 MoCo 中的一個重要組件,用于存儲模型的特征向量。在 MoCo 的訓練過程中,首先對一批未標記的圖像進行前向傳播,得到每個圖像的特征向量。然后,這些特征向量將被存儲到內(nèi)存庫中。內(nèi)存庫的大小通常會比較大,足夠存儲許多圖像的特征。訓練過程的關(guān)鍵部分是建立正負樣本對。對于每個樣本,其特征向量將被視為查詢向量(Query),而來自內(nèi)存庫的其他特征向量將被視為候選向量(Candidate)。通常情況下,查詢向量和候選向量來自同一張圖片的不同視角或數(shù)據(jù)增強的版本。然后,通過比較查詢向量與候選向量之間的相似性來構(gòu)建正負樣本對。此外,還有一些其他方法和概念,我們就不在這篇解讀文章中介紹了。
Generative Representation Learning
DatasetGAN 是最早展示預訓練 GAN 可以顯著改善感知任務表現(xiàn)的研究之一,特別是在數(shù)據(jù)標記較少的情況下。SemanticGAN 提出了對圖像和標簽的聯(lián)合建模。推理過程首先將測試圖像編碼為 StyleGAN 的潛在空間,然后使用任務頭部解碼標簽。DDPM-seg 沿著這一研究方向,但使用了去噪擴散概率模型(DDPMs)代替 StyleGAN。這篇文章繼續(xù)了這一研究方向,但重點放在從預訓練的生成模型中,特別是擴散模型,向下游圖像主干中提取知識,作為一種通用的預訓練方式。
關(guān)于相關(guān)工作部分中涉及到的方法,如果有疑惑的推薦閱讀原文(鏈接在文末)。
DreamTeacher 框架介紹
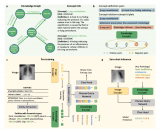
DreamTeacher 框架能在兩種場景下的工作:無監(jiān)督表示學習和半監(jiān)督學習。在無監(jiān)督表示學習中,預訓練階段沒有可用的標簽信息,而在半監(jiān)督學習中,只有部分數(shù)據(jù)擁有標簽。框架使用訓練好的生成模型 G 來傳遞其學到的表示知識到目標圖像主干 f。無論在哪種場景下,框架的訓練方法和所選的生成模型 G 與圖像主干 f 的選擇都是一樣的。首先,它創(chuàng)建一個包含圖像和相應特征的特征數(shù)據(jù)集 。然后,通過將生成模型的特征傳遞到圖像主干 f 的中間特征中來訓練圖像主干 f。作者特別關(guān)注使用卷積主干 f 的情況,而對 Transformer 的探索留給未來的研究。
Unsupervised Representation Learning
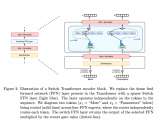
對于無監(jiān)督表示學習,給定一個特征數(shù)據(jù)集 D,在圖像主干 f 的不同層次上附加特征回歸器,以回歸出對應的生成特征 從圖像 中。我們首先如何討論創(chuàng)建特征數(shù)據(jù)集,然后設計特征回歸器,最后介紹蒸餾目標。創(chuàng)建特征數(shù)據(jù)集 D 的方法有兩種。一種是通過從生成模型 G 中采樣圖像,并記錄生成過程中提取的中間特征來創(chuàng)建合成數(shù)據(jù)集。這種方法可以合成無限大小的數(shù)據(jù)集,但可能會出現(xiàn) mode dropping(生成模型可能沒有學習到分布的某些部分)的問題。另一種方法是將實際圖像通過編碼過程編碼到生成模型 G 的潛在空間中,然后記錄生成過程中提取的中間特征,創(chuàng)建編碼數(shù)據(jù)集。合成數(shù)據(jù)集適用于采樣速度快、無法編碼真實圖像的生成模型(如 GAN),而編碼數(shù)據(jù)集適用于具有編碼器網(wǎng)絡的生成模型(如 VAE)和擴散模型。這兩種方法的特征數(shù)據(jù)集可以在離線預先計算,也可以在訓練過程中在線創(chuàng)建,以實現(xiàn)快速的內(nèi)存訪問和高效的樣本生成和刪除,從而適用于任何大小的數(shù)據(jù)集和特征預訓練,同時增加下游Backbone 網(wǎng)絡的魯棒性。DreamTeacher 框架的整體流程如下圖所示,圖里表示創(chuàng)建特征數(shù)據(jù)集 D 使用的是第二種方法。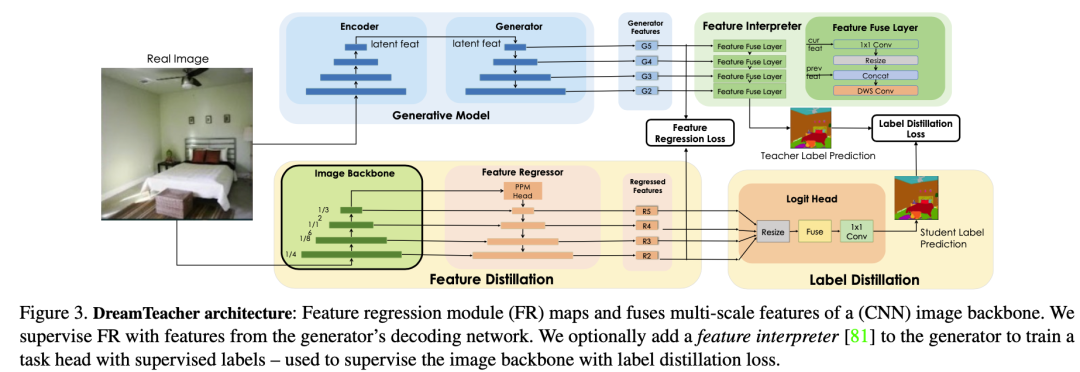 為了將生成式表示 ? 蒸餾到通用主干 f 中,設計了一個特征回歸器模塊,將圖像主干的多層特征映射并對齊到生成式特征上。受到 Feature Pyramid Network(FPN)的設計啟發(fā),特征回歸器采用自頂向下的架構(gòu),并使用側(cè)向跳線連接來融合主干特征,并輸出多尺度特征。在圖像主干的最后一層之前應用了類似于 PSPNet 中的金字塔池化模塊(PPM),上圖(底部)直觀地描述了這個架構(gòu)。接下來,我們關(guān)注如何做特征蒸餾的。將編碼器 f 的不同級別的中間特征表示為 ,對應的特征回歸器輸出為 。使用一個 1×1 的卷積來匹配 和 的通道數(shù),如果它們不同的話。特征回歸損失非常簡單,受到 FitNet 的啟發(fā),它提出了通過模擬中間特征激活將教師網(wǎng)絡上的知識蒸餾到學生網(wǎng)絡上:
為了將生成式表示 ? 蒸餾到通用主干 f 中,設計了一個特征回歸器模塊,將圖像主干的多層特征映射并對齊到生成式特征上。受到 Feature Pyramid Network(FPN)的設計啟發(fā),特征回歸器采用自頂向下的架構(gòu),并使用側(cè)向跳線連接來融合主干特征,并輸出多尺度特征。在圖像主干的最后一層之前應用了類似于 PSPNet 中的金字塔池化模塊(PPM),上圖(底部)直觀地描述了這個架構(gòu)。接下來,我們關(guān)注如何做特征蒸餾的。將編碼器 f 的不同級別的中間特征表示為 ,對應的特征回歸器輸出為 。使用一個 1×1 的卷積來匹配 和 的通道數(shù),如果它們不同的話。特征回歸損失非常簡單,受到 FitNet 的啟發(fā),它提出了通過模擬中間特征激活將教師網(wǎng)絡上的知識蒸餾到學生網(wǎng)絡上:
在這里,W 是一個不可學習的白化算子,使用 LayerNorm 實現(xiàn),用于對不同層次上的特征幅值進行歸一化。層數(shù) l = {2, 3, 4, 5},對應于相對于輸入分辨率的 步長處的特征。
此外,這篇文章還探索了基于激活的注意力轉(zhuǎn)移(AT)目標。AT 使用一個運算符 ,對空間特征的每個維度生成一個一維的“注意力圖”,其中 |Ai| 表示特征激活 A 在通道維度 C 上的絕對值和。這種方法相比直接回歸高維特征可以提高收斂速度。具體來說,AT 損失函數(shù)如下:
其中分別是回歸器和生成模型在第 l 層中的特征的矢量形式中的第 j 對。
最后,綜合特征回歸損失為:
Label-Guided Representation Learning
 在這里插入圖片描述
在這里插入圖片描述
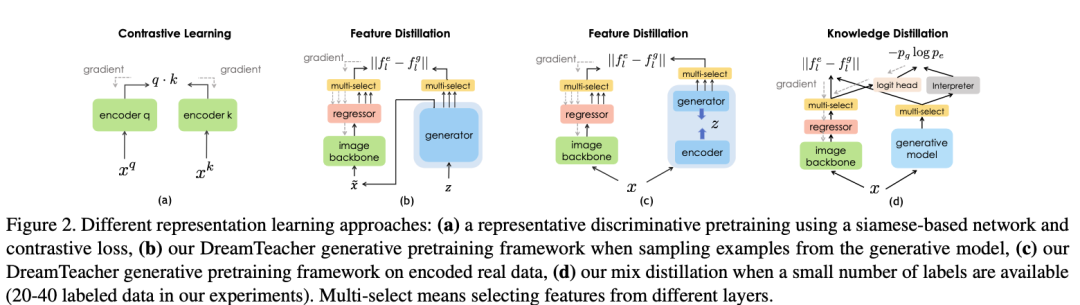
在半監(jiān)督設置中,在預訓練階段在凍結(jié)的生成網(wǎng)絡 G 之上訓練了一個任務相關(guān)的分支,稱為特征解釋器,采用 DatasetGAN 的方法進行監(jiān)督訓練。與 DatasetGAN 合成用于訓練下游任務網(wǎng)絡的帶標簽數(shù)據(jù)集不同,DreamTeacher 改用軟標簽蒸餾,即在編碼和合成的數(shù)據(jù)集中都包含了預測的軟標簽,也就是特征數(shù)據(jù)集 D 中包含了軟標簽。這在上圖(d)中進行了可視化。
這篇文章探索了使用分割標簽對解釋器分支進行訓練(半監(jiān)督情景下),并使用交叉熵和 Dice 目標的組合來訓練:
其中是特征解釋器的權(quán)重,y 是任務標簽。H(·, ·) 表示像素級的交叉熵損失,D(·, ·) 表示 Dice Loss。
對于標簽蒸餾,使用以下?lián)p失函數(shù):
其中 和 分別是特征解釋器和目標圖像主干 f 的 logits。H 是交叉熵損失,而 τ 是溫度參數(shù)。
將標簽蒸餾目標與特征蒸餾目標相結(jié)合,得到混合損失函數(shù):
使用混合蒸餾損失對預訓練數(shù)據(jù)集中的所有圖像進行預訓練,無論是帶標簽還是無標簽的。帶標簽的標簽僅用于訓練特征解釋器,而 DreamTeacher 只使用特征解釋器生成的軟標簽對圖像主干 f 進行蒸餾預訓練。
實驗
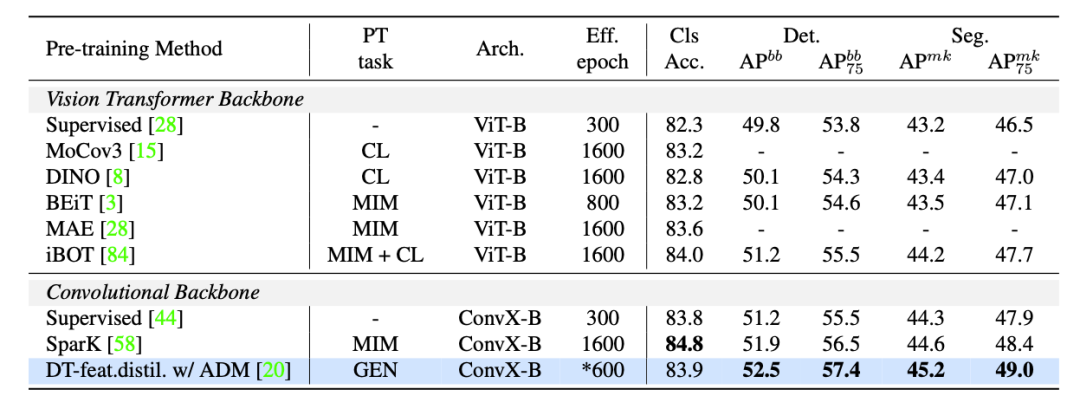
在實驗中,使用的生成模型包含:unconditional BigGAN、ICGAN、StyleGAN2;對于基于擴散的模型,使用了 ADM 和 stable diffusion 模型。使用的數(shù)據(jù)集包含:bdd100k、ImageNet-1k(IN1k-1M)、LSUN 和 ffhq。下表將 DreamTeacher 與 ImageNet 和 COCO 上的自監(jiān)督學習的 SOTA 方法進行比較:
 在這里插入圖片描述
在這里插入圖片描述
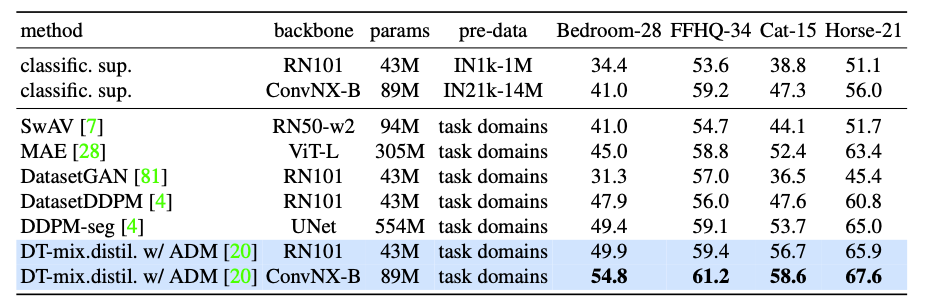
對于 Label-efficient 的語義分割 benchmark。下表將 DreamTeacher與各種表示學習基線進行比較。
 下圖是使用 DreamTeacher 特征蒸餾預訓練的 ConvNX-B 模型在 LSUN-cat 無標簽圖像上的定性結(jié)果。
下圖是使用 DreamTeacher 特征蒸餾預訓練的 ConvNX-B 模型在 LSUN-cat 無標簽圖像上的定性結(jié)果。
在這里插入圖片描述
總結(jié)
這篇文章的研究聚焦于提出一種名為 DreamTeacher 的框架,旨在從生成模型向目標圖像 Backbone 傳遞知識(知識蒸餾)。在這個框架下,進行了多個實驗,涵蓋了不同的 settings ,包括生成模型、目標圖像 Backbone 和評估 benchmark。其目標是探究生成式模型在大規(guī)模無標簽數(shù)據(jù)集上學習語義上有意義特征的能力,并將這些特征成功地傳遞到目標圖像 Backbone 上。
通過實驗,這篇文章發(fā)現(xiàn)使用生成目標的生成網(wǎng)絡能夠?qū)W習到具有意義的特征,這些特征可以有效地應用于目標圖像主干。與現(xiàn)有自監(jiān)督學習方法相比,這篇文章基于生成模型的預訓練方法表現(xiàn)更為優(yōu)異,這些 benchmark 測試包括 COCO、ADE20K 和 BDD100K 等。
這篇文章的工作為生成式預訓練提供了新的視角和方法,并在視覺任務中充分利用了生成模型。在近兩年的論文中,生成式預訓練技術(shù)是一個比較有趣的方向。
責任編輯:彭菁
-
圖像
+關(guān)注
關(guān)注
2文章
1089瀏覽量
40535 -
模型
+關(guān)注
關(guān)注
1文章
3298瀏覽量
49065 -
網(wǎng)絡設計
+關(guān)注
關(guān)注
0文章
14瀏覽量
7808 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1209瀏覽量
24792
原文標題:ICCV 2023:探索基于生成模型的 Backbone 預訓練
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
【大語言模型:原理與工程實踐】大語言模型的預訓練
微軟在ICML 2019上提出了一個全新的通用預訓練方法MASS

新的預訓練方法——MASS!MASS預訓練幾大優(yōu)勢!

檢索增強型語言表征模型預訓練
一種側(cè)重于學習情感特征的預訓練方法

介紹幾篇EMNLP'22的語言模型訓練方法優(yōu)化工作
什么是預訓練 AI 模型?
基于醫(yī)學知識增強的基礎(chǔ)模型預訓練方法
基礎(chǔ)模型自監(jiān)督預訓練的數(shù)據(jù)之謎:大量數(shù)據(jù)究竟是福還是禍?

混合專家模型 (MoE)核心組件和訓練方法介紹





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論