 混合專家模型 (MoE)核心組件和訓練方法介紹
混合專家模型 (MoE)核心組件和訓練方法介紹
隨著 Mixtral 8x7B (announcement, model card) 的推出,一種稱為混合專家模型 (Mixed Expert Models,簡稱 MoEs) 的 Transformer 模型在開源人工智能社區引起了廣泛關注。在本篇博文中,我們將深入探討 MoEs 的核心組件、訓練方法,以及在推理過程中需要考量的各種因素。
讓我們開始吧!
簡短總結
混合專家模型 (MoEs):
與稠密模型相比,預訓練速度更快
與具有相同參數數量的模型相比,具有更快的推理速度
需要大量顯存,因為所有專家系統都需要加載到內存中
在微調方面存在諸多挑戰,但 近期的研究 表明,對混合專家模型進行指令調優具有很大的潛力。
讓我們開始吧!
什么是混合專家模型?
模型規模是提升模型性能的關鍵因素之一。在有限的計算資源預算下,用更少的訓練步數訓練一個更大的模型,往往比用更多的步數訓練一個較小的模型效果更佳。
混合專家模型 (MoE) 的一個顯著優勢是它們能夠在遠少于稠密模型所需的計算資源下進行有效的預訓練。這意味著在相同的計算預算條件下,您可以顯著擴大模型或數據集的規模。特別是在預訓練階段,與稠密模型相比,混合專家模型通常能夠更快地達到相同的質量水平。
那么,究竟什么是一個混合專家模型 (MoE) 呢?作為一種基于 Transformer 架構的模型,混合專家模型主要由兩個關鍵部分組成:
稀疏 MoE 層: 這些層代替了傳統 Transformer 模型中的前饋網絡 (FFN) 層。MoE 層包含若干“專家”(例如 8 個),每個專家本身是一個獨立的神經網絡。在實際應用中,這些專家通常是前饋網絡 (FFN),但它們也可以是更復雜的網絡結構,甚至可以是 MoE 層本身,從而形成層級式的 MoE 結構。
門控網絡或路由: 這個部分用于決定哪些令牌 (token) 被發送到哪個專家。例如,在下圖中,“More”這個令牌可能被發送到第二個專家,而“Parameters”這個令牌被發送到第一個專家。有時,一個令牌甚至可以被發送到多個專家。令牌的路由方式是 MoE 使用中的一個關鍵點,因為路由器由學習的參數組成,并且與網絡的其他部分一同進行預訓練。
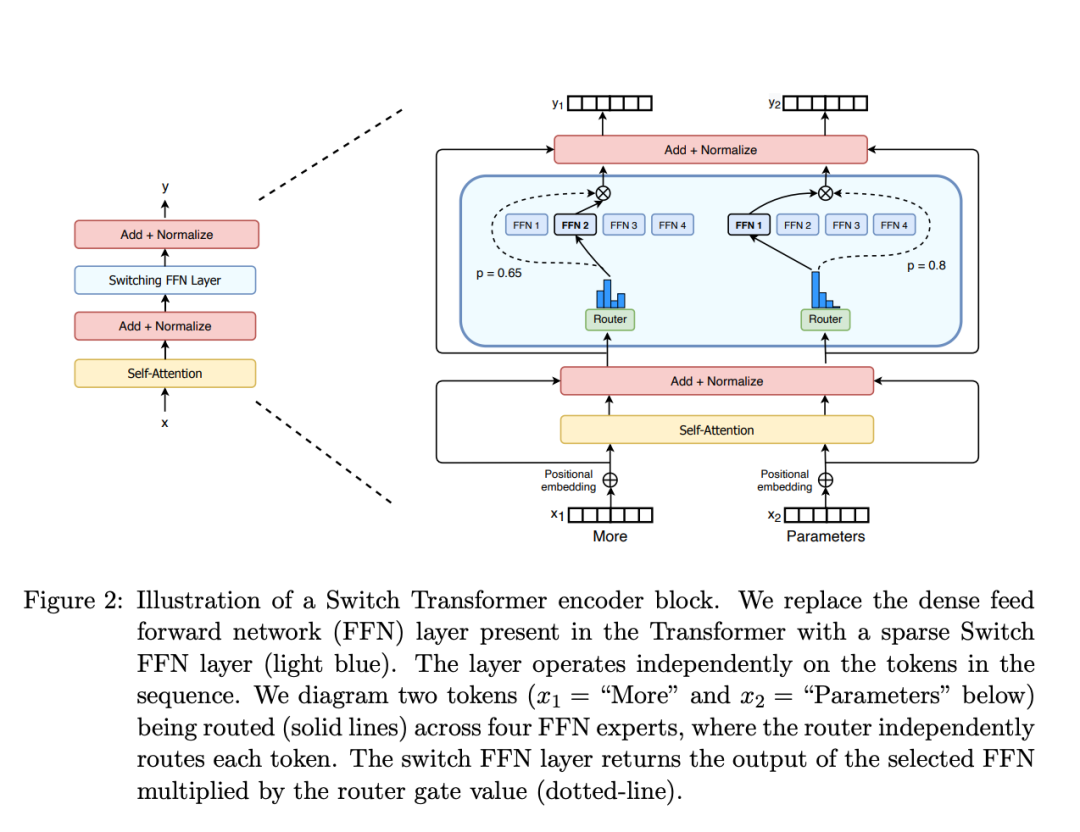
Switch Transformers paper 論文中的 MoE layer
總結來說,在混合專家模型 (MoE) 中,我們將傳統 Transformer 模型中的每個前饋網絡 (FFN) 層替換為 MoE 層,其中 MoE 層由兩個核心部分組成: 一個門控網絡和若干數量的專家。
盡管混合專家模型 (MoE) 提供了若干顯著優勢,例如更高效的預訓練和與稠密模型相比更快的推理速度,但它們也伴隨著一些挑戰:
訓練挑戰: 雖然 MoE 能夠實現更高效的計算預訓練,但它們在微調階段往往面臨泛化能力不足的問題,長期以來易于引發過擬合現象。
推理挑戰: MoE 模型雖然可能擁有大量參數,但在推理過程中只使用其中的一部分,這使得它們的推理速度快于具有相同數量參數的稠密模型。然而,這種模型需要將所有參數加載到內存中,因此對內存的需求非常高。以 Mixtral 8x7B 這樣的 MoE 為例,需要足夠的 VRAM 來容納一個 47B 參數的稠密模型。之所以是 47B 而不是 8 x 7B = 56B,是因為在 MoE 模型中,只有 FFN 層被視為獨立的專家,而模型的其他參數是共享的。此外,假設每個令牌只使用兩個專家,那么推理速度 (以 FLOPs 計算) 類似于使用 12B 模型 (而不是 14B 模型),因為雖然它進行了 2x7B 的矩陣乘法計算,但某些層是共享的。
了解了 MoE 的基本概念后,讓我們進一步探索推動這類模型發展的研究。
混合專家模型簡史
混合專家模型 (MoE) 的理念起源于 1991 年的論文 Adaptive Mixture of Local Experts。這個概念與集成學習方法相似,旨在為由多個單獨網絡組成的系統建立一個監管機制。在這種系統中,每個網絡 (被稱為“專家”) 處理訓練樣本的不同子集,專注于輸入空間的特定區域。那么,如何選擇哪個專家來處理特定的輸入呢?這就是門控網絡發揮作用的地方,它決定了分配給每個專家的權重。在訓練過程中,這些專家和門控網絡都同時接受訓練,以優化它們的性能和決策能力。
在 2010 至 2015 年間,兩個獨立的研究領域為混合專家模型 (MoE) 的后續發展做出了顯著貢獻:
組件專家: 在傳統的 MoE 設置中,整個系統由一個門控網絡和多個專家組成。在支持向量機 (SVMs) 、高斯過程和其他方法的研究中,MoE 通常被視為整個模型的一部分。然而,Eigen、Ranzato 和 Ilya 的研究 探索了將 MoE 作為更深層網絡的一個組件。這種方法允許將 MoE 嵌入到多層網絡中的某一層,使得模型既大又高效。
條件計算: 傳統的神經網絡通過每一層處理所有輸入數據。在這一時期,Yoshua Bengio 等研究人員開始探索基于輸入令牌動態激活或停用網絡組件的方法。
這些研究的融合促進了在自然語言處理 (NLP) 領域對混合專家模型的探索。特別是在 2017 年,Shazeer 等人 (團隊包括 Geoffrey Hinton 和 Jeff Dean,后者有時被戲稱為 “谷歌的 Chuck Norris”) 將這一概念應用于 137B 的 LSTM (當時被廣泛應用于 NLP 的架構,由 Schmidhuber 提出)。通過引入稀疏性,這項工作在保持極高規模的同時實現了快速的推理速度。這項工作主要集中在翻譯領域,但面臨著如高通信成本和訓練不穩定性等多種挑戰。
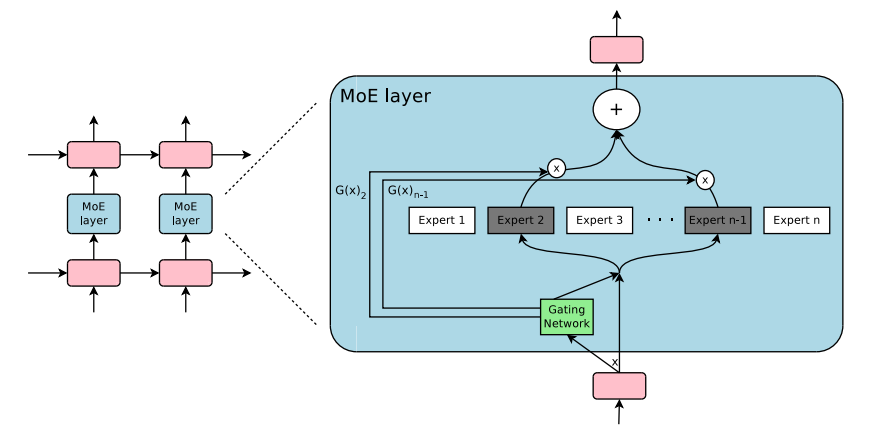
Outrageously Large Neural Network 論文中的 MoE layer
混合專家模型 (MoE) 的引入使得訓練具有數千億甚至萬億參數的模型成為可能,如開源的 1.6 萬億參數的 Switch Transformers 等。這種技術不僅在自然語言處理 (NLP) 領域得到了廣泛應用,也開始在計算機視覺領域進行探索。然而,本篇博客文章將主要聚焦于自然語言處理領域的應用和探討。
什么是稀疏性?
稀疏性的概念采用了條件計算的思想。在傳統的稠密模型中,所有的參數都會對所有輸入數據進行處理。相比之下,稀疏性允許我們僅針對整個系統的某些特定部分執行計算。這意味著并非所有參數都會在處理每個輸入時被激活或使用,而是根據輸入的特定特征或需求,只有部分參數集合被調用和運行。
讓我們深入分析 Shazeer 對混合專家模型 (MoE) 在翻譯應用中的貢獻。條件計算的概念 (即僅在每個樣本的基礎上激活網絡的不同部分) 使得在不增加額外計算負擔的情況下擴展模型規模成為可能。這一策略在每個 MoE 層中實現了數以千計甚至更多的專家的有效利用。
這種稀疏性設置確實帶來了一些挑戰。例如,在混合專家模型 (MoE) 中,盡管較大的批量大小通常有利于提高性能,但當數據通過激活的專家時,實際的批量大小可能會減少。比如,假設我們的輸入批量包含 10 個令牌,可能會有五個令牌被路由到同一個專家,而剩下的五個令牌分別被路由到不同的專家。這導致了批量大小的不均勻分配和資源利用效率不高的問題。在接下來的部分中,將會討論讓 MoE 高效運行的其他挑戰以及相應的解決方案。
那我們應該如何解決這個問題呢?一個可學習的門控網絡 (G) 決定將輸入的哪一部分發送給哪些專家 (E):
在這種設置下,雖然所有專家都會對所有輸入進行運算,但通過門控網絡的輸出進行加權乘法操作。但是,如果 G (門控網絡的輸出) 為 0 會發生什么呢?如果是這種情況,就沒有必要計算相應的專家操作,因此我們可以節省計算資源。那么一個典型的門控函數是什么呢?一個典型的門控函數通常是一個帶有 softmax 函數的簡單的網絡。這個網絡將學習將輸入發送給哪個專家。
Shazeer 等人的工作還探索了其他的門控機制,其中包括帶噪聲的 TopK 門控 (Noisy Top-K Gating)。這種門控方法引入了一些可調整的噪聲,然后保留前 k 個值。具體來說:
添加一些噪聲
選擇保留前 K 個值
應用 Softmax 函數
這種稀疏性引入了一些有趣的特性。通過使用較低的 k 值 (例如 1 或 2),我們可以比激活多個專家時更快地進行訓練和推理。為什么不僅選擇最頂尖的專家呢?最初的假設是,需要將輸入路由到不止一個專家,以便門控學會如何進行有效的路由選擇,因此至少需要選擇兩個專家。Switch Transformers 就這點進行了更多的研究。
我們為什么要添加噪聲呢?這是為了專家間的負載均衡!
混合專家模型中令牌的負載均衡
正如之前討論的,如果所有的令牌都被發送到只有少數幾個受歡迎的專家,那么訓練效率將會降低。在通常的混合專家模型 (MoE) 訓練中,門控網絡往往傾向于主要激活相同的幾個專家。這種情況可能會自我加強,因為受歡迎的專家訓練得更快,因此它們更容易被選擇。為了緩解這個問題,引入了一個輔助損失,旨在鼓勵給予所有專家相同的重要性。這個損失確保所有專家接收到大致相等數量的訓練樣本,從而平衡了專家之間的選擇。接下來的部分還將探討專家容量的概念,它引入了一個關于專家可以處理多少令牌的閾值。在 transformers 庫中,可以通過 aux_loss 參數來控制輔助損失。
MoEs and Transformers
Transformer 類模型明確表明,增加參數數量可以提高性能,因此谷歌使用 GShard 嘗試將 Transformer 模型的參數量擴展到超過 6000 億并不令人驚訝。
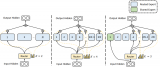
GShard 將在編碼器和解碼器中的每個前饋網絡 (FFN) 層中的替換為使用 Top-2 門控的混合專家模型 (MoE) 層。下圖展示了編碼器部分的結構。這種架構對于大規模計算非常有效: 當擴展到多個設備時,MoE 層在不同設備間共享,而其他所有層則在每個設備上復制。我們將在 “讓 MoE 起飛”部分對這一點進行更詳細的討論。
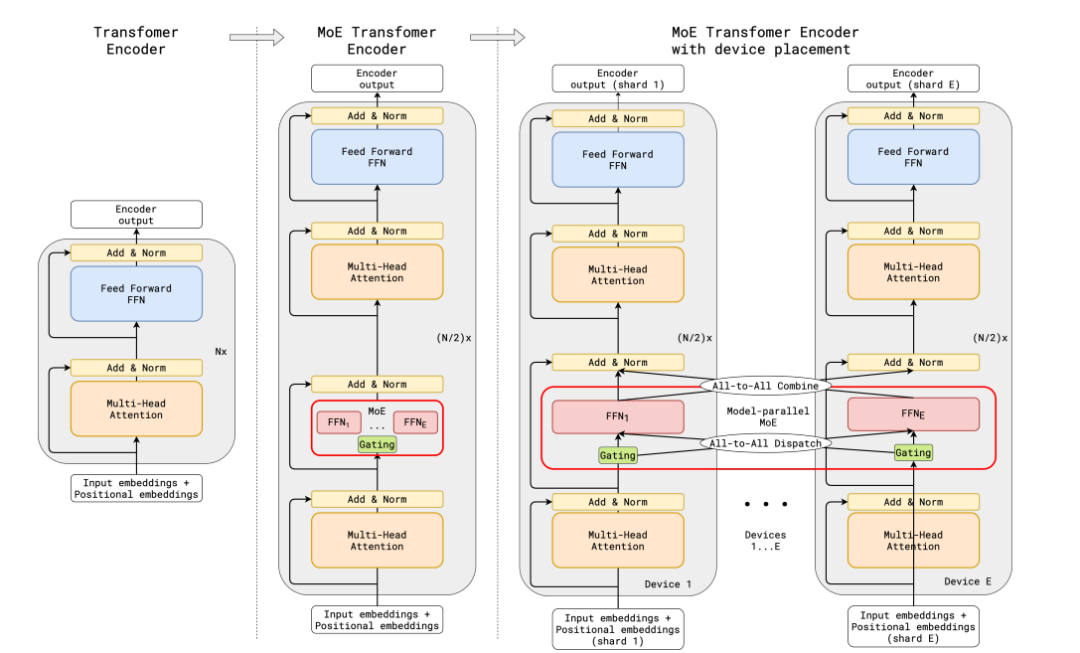
GShard 論文中的 MoE Transformer Encoder
為了保持負載平衡和訓練效率,GShard 的作者除了引入了上一節中討論的類似輔助損失外,還引入了一些關鍵變化:
隨機路由: 在 Top-2 設置中,我們始終選擇排名最高的專家,但第二個專家是根據其權重比例隨機選擇的。
專家容量: 我們可以設定一個閾值,定義一個專家能處理多少令牌。如果兩個專家的容量都達到上限,令牌就會溢出,并通過殘差連接傳遞到下一層,或在某些情況下被完全丟棄。專家容量是 MoE 中最重要的概念之一。為什么需要專家容量呢?因為所有張量的形狀在編譯時是靜態確定的,我們無法提前知道多少令牌會分配給每個專家,因此需要一個固定的容量因子。
GShard 的工作對適用于 MoE 的并行計算模式也做出了重要貢獻,但這些內容的討論超出了這篇博客的范圍。
注意: 在推理過程中,只有部分專家被激活。同時,有些計算過程是共享的,例如自注意力 (self-attention) 機制,它適用于所有令牌。這就解釋了為什么我們可以使用相當于 12B 稠密模型的計算資源來運行一個包含 8 個專家的 47B 模型。如果我們采用 Top-2 門控,模型會使用高達 14B 的參數。但是,由于自注意力操作 (專家間共享) 的存在,實際上模型運行時使用的參數數量是 12B。
Switch Transformers
盡管混合專家模型 (MoE) 顯示出了很大的潛力,但它們在訓練和微調過程中存在穩定性問題。Switch Transformers 是一項非常激動人心的工作,它深入研究了這些話題。作者甚至在 Hugging Face 上發布了一個 1.6 萬億參數的 MoE,擁有 2048 個專家,你可以使用 transformers 庫來運行它。Switch Transformers 實現了與 T5-XXL 相比 4 倍的預訓練速度提升。
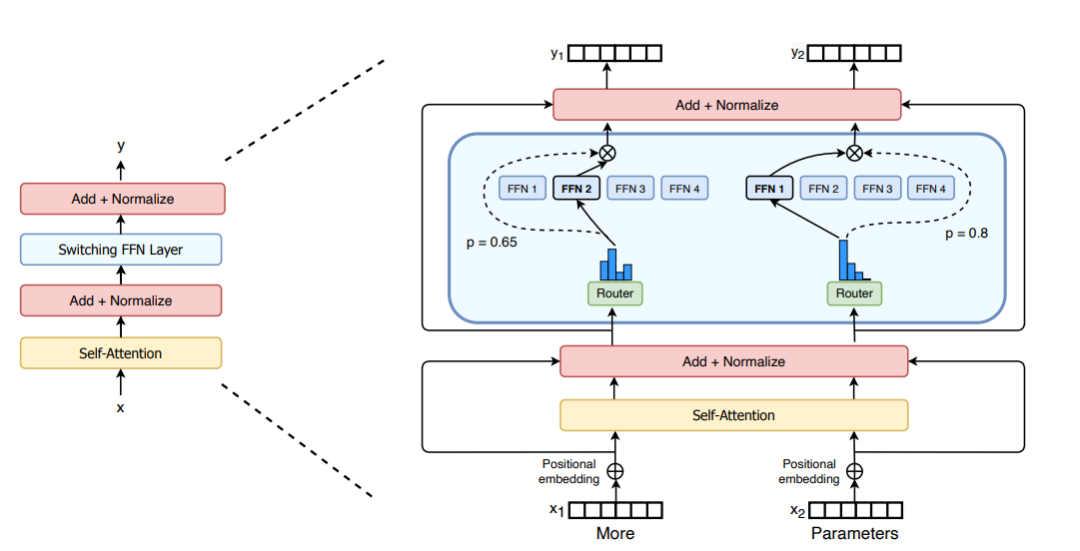
Switch Transformer 論文中的 Switch Transformer Layer
就像在 GShard 中一樣,作者用混合專家模型 (MoE) 層替換了前饋網絡 (FFN) 層。Switch Transformers 提出了一個 Switch Transformer 層,它接收兩個輸入 (兩個不同的令牌) 并擁有四個專家。
與最初使用至少兩個專家的想法相反,Switch Transformers 采用了簡化的單專家策略。這種方法的效果包括:
減少門控網絡 (路由) 計算負擔
每個專家的批量大小至少可以減半
降低通信成本
保持模型質量
Switch Transformers 也對專家容量這個概念進行了研究。
上述建議的容量是將批次中的令牌數量均勻分配到各個專家。如果我們使用大于 1 的容量因子,我們為令牌分配不完全平衡時提供了一個緩沖。增加容量因子會導致更高的設備間通信成本,因此這是一個需要考慮的權衡。特別值得注意的是,Switch Transformers 在低容量因子 (例如 1 至 1.25) 下表現出色。
Switch Transformer 的作者還重新審視并簡化了前面章節中提到的負載均衡損失。在訓練期間,對于每個 Switch 層的輔助損失被添加到總模型損失中。這種損失鼓勵均勻路由,并可以使用超參數進行加權。
作者還嘗試了混合精度的方法,例如用 bfloat16 精度訓練專家,同時對其余計算使用全精度進行。較低的精度可以減少處理器間的通信成本、計算成本以及存儲張量的內存。然而,在最初的實驗中,當專家和門控網絡都使用 bfloat16 精度訓練時,出現了不穩定的訓練現象。這種不穩定性特別是由路由計算引起的,因為路由涉及指數函數等操作,這些操作對精度要求較高。因此,為了保持計算的穩定性和精確性,保持更高的精度是重要的。為了減輕不穩定性,路由過程也使用了全精度。
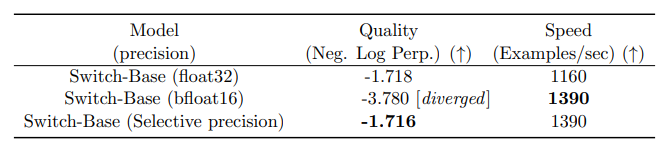
使用混合精度不會降低模型質量并可實現更快的訓練
這個 Jupyter Notebook 展示了如何對 Switch Transformers 進行微調以進行摘要生成的詳細指南。然而,在開始微調 Switch Transformers 之前,強烈建議您先閱讀關于微調混合專家模型部分的內容。
Switch Transformers 采用了編碼器 - 解碼器的架構,實現了與 T5 類似的混合專家模型 (MoE) 版本。GLaM 這篇工作探索了如何使用僅為原來 1/3 的計算資源 (因為 MoE 模型在訓練時需要的計算量較少,從而能夠顯著降低碳足跡) 來訓練與 GPT-3 質量相匹配的模型來提高這些模型的規模。作者專注于僅解碼器 (decoder-only) 的模型以及少樣本和單樣本評估,而不是微調。他們使用了 Top-2 路由和更大的容量因子。此外,他們探討了將容量因子作為一個動態度量,根據訓練和評估期間所使用的計算量進行調整。
用 Router z-loss 穩定模型訓練
之前討論的平衡損失可能會導致穩定性問題。我們可以使用許多方法來穩定稀疏模型的訓練,但這可能會犧牲模型質量。例如,引入 dropout 可以提高穩定性,但會導致模型質量下降。另一方面,增加更多的乘法分量可以提高質量,但會降低模型穩定性。
ST-MoE 引入的 Router z-loss 在保持了模型性能的同時顯著提升了訓練的穩定性。這種損失機制通過懲罰門控網絡輸入的較大 logits 來起作用,目的是促使數值的絕對大小保持較小,這樣可以有效減少計算中的舍入誤差。這一點對于那些依賴指數函數進行計算的門控網絡尤其重要。為了深入了解這一機制,建議參考原始論文以獲得更全面的細節。
專家如何學習?
ST-MoE 的研究者們發現,編碼器中不同的專家傾向于專注于特定類型的令牌或淺層概念。例如,某些專家可能專門處理標點符號,而其他專家則專注于專有名詞等。與此相反,解碼器中的專家通常具有較低的專業化程度。此外,研究者們還對這一模型進行了多語言訓練。盡管人們可能會預期每個專家處理一種特定語言,但實際上并非如此。由于令牌路由和負載均衡的機制,沒有任何專家被特定配置以專門處理某一特定語言。

ST-MoE 論文中顯示了哪些令牌組被發送給了哪個專家的表格
專家的數量對預訓練有何影響?
增加更多專家可以提升處理樣本的效率和加速模型的運算速度,但這些優勢隨著專家數量的增加而遞減 (尤其是當專家數量達到 256 或 512 之后更為明顯)。同時,這也意味著在推理過程中,需要更多的顯存來加載整個模型。值得注意的是,Switch Transformers 的研究表明,其在大規模模型中的特性在小規模模型下也同樣適用,即便是每層僅包含 2、4 或 8 個專家。
微調混合專家模型
4.36.0 版本的 transformers 庫支持 Mixtral 模型。你可以用以下命令進行安裝: pip install "transformers==4.36.0 --upgrade
稠密模型和稀疏模型在過擬合的動態表現上存在顯著差異。稀疏模型更易于出現過擬合現象,因此在處理這些模型時,嘗試更強的內部正則化措施是有益的,比如使用更高比例的 dropout。例如,我們可以為稠密層設定一個較低的 dropout 率,而為稀疏層設置一個更高的 dropout 率,以此來優化模型性能。
在微調過程中是否使用輔助損失是一個需要決策的問題。ST-MoE 的作者嘗試關閉輔助損失,發現即使高達 11% 的令牌被丟棄,模型的質量也沒有顯著受到影響。令牌丟棄可能是一種正則化形式,有助于防止過擬合。
Switch Transformers 的作者觀察到,在相同的預訓練困惑度下,稀疏模型在下游任務中的表現不如對應的稠密模型,特別是在重理解任務 (如 SuperGLUE) 上。另一方面,對于知識密集型任務 (如 TriviaQA),稀疏模型的表現異常出色。作者還觀察到,在微調過程中,較少的專家的數量有助于改善性能。另一個關于泛化問題確認的發現是,模型在小型任務上表現較差,但在大型任務上表現良好。
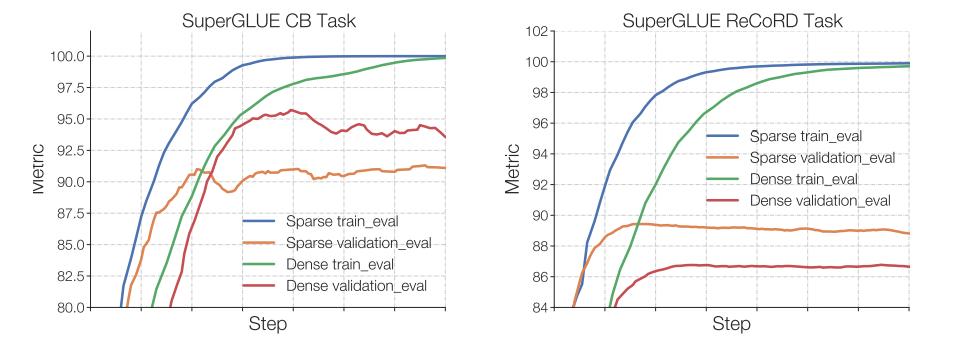
在小任務 (左圖) 中,我們可以看到明顯的過擬合,因為稀疏模型在驗證集中的表現要差得多。在較大的任務 (右圖) 中,MoE 則表現良好。該圖來自 ST-MoE 論文
一種可行的微調策略是嘗試凍結所有非專家層的權重。實踐中,這會導致性能大幅下降,但這符合我們的預期,因為混合專家模型 (MoE) 層占據了網絡的主要部分。我們可以嘗試相反的方法: 僅凍結 MoE 層的參數。實驗結果顯示,這種方法幾乎與更新所有參數的效果相當。這種做法可以加速微調過程,并降低顯存需求。
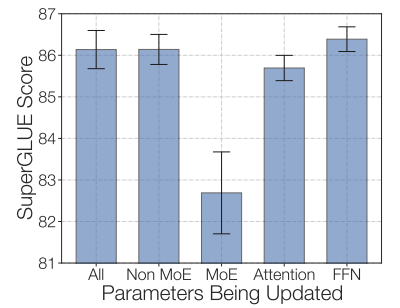
通過僅凍結 MoE 層,我們可以在保持質量的同時加快訓練速度。該圖來自 ST-MoE 論文
在微調稀疏混合專家模型 (MoE) 時需要考慮的最后一個問題是,它們有特別的微調超參數設置——例如,稀疏模型往往更適合使用較小的批量大小和較高的學習率,這樣可以獲得更好的訓練效果。
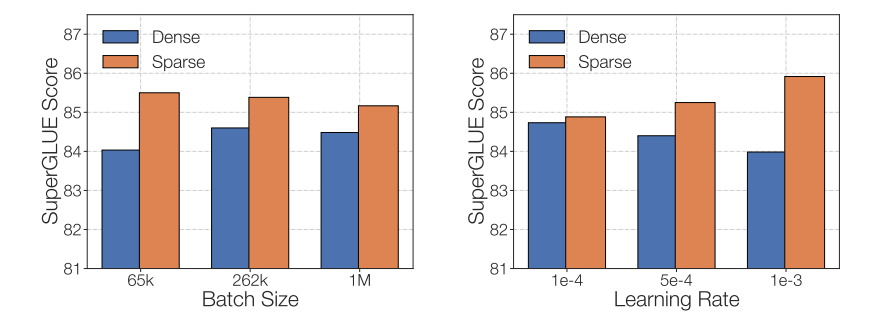
降低學習率和調大批量可以提升稀疏模型微調質量。該圖來自 ST-MoE 論文
此時,您可能會對人們微調 MoE 中遇到的這些挑戰而感到沮喪,但最近的一篇論文 《MoEs Meets Instruction Tuning》 (2023 年 7 月) 帶來了令人興奮的發現。這篇論文進行了以下實驗:
單任務微調
多任務指令微調
多任務指令微調后接單任務微調
當研究者們對 MoE 和對應性能相當的 T5 模型進行微調時,他們發現 T5 的對應模型表現更為出色。然而,當研究者們對 Flan T5 (一種 T5 的指令優化版本) 的 MoE 版本進行微調時,MoE 的性能顯著提升。更值得注意的是,Flan-MoE 相比原始 MoE 的性能提升幅度超過了 Flan T5 相對于原始 T5 的提升,這意味著 MoE 模型可能從指令式微調中獲益更多,甚至超過了稠密模型。此外,MoE 在多任務學習中表現更佳。與之前關閉輔助損失函數的做法相反,實際上這種損失函數可以幫助防止過擬合。
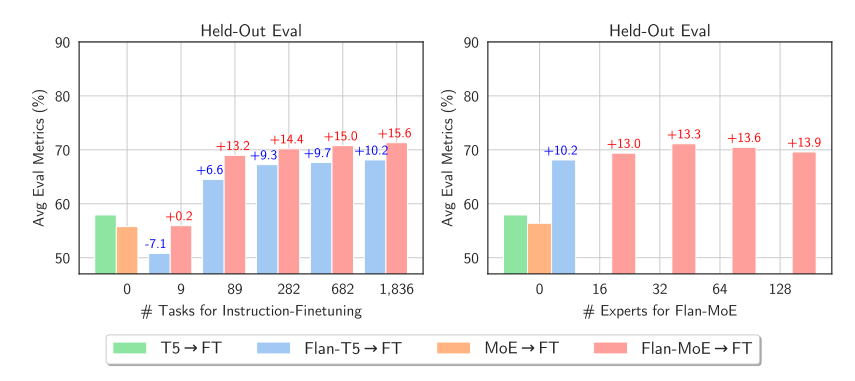
與稠密模型相比,稀疏模型從指令微調中受益更多。該圖來自 MoEs Meets instructions Tuning 論文
稀疏 VS 稠密,如何選擇?
稀疏混合專家模型 (MoE) 適用于擁有多臺機器且要求高吞吐量的場景。在固定的預訓練計算資源下,稀疏模型往往能夠實現更優的效果。相反,在顯存較少且吞吐量要求不高的場景,稠密模型則是更合適的選擇。
注意: 直接比較稀疏模型和稠密模型的參數數量是不恰當的,因為這兩類模型基于的概念和參數量的計算方法完全不同。
讓 MoE 起飛
最初的混合專家模型 (MoE) 設計采用了分支結構,這導致了計算效率低下。這種低效主要是因為 GPU 并不是為處理這種結構而設計的,而且由于設備間需要傳遞數據,網絡帶寬常常成為性能瓶頸。在接下來的討論中,我們會討論一些現有的研究成果,旨在使這些模型在預訓練和推理階段更加高效和實用。我們來看看如何優化 MoE 模型,讓 MoE 起飛。
并行計算
讓我們簡要回顧一下并行計算的幾種形式:
數據并行: 相同的權重在所有節點上復制,數據在節點之間分割。
模型并行: 模型在節點之間分割,相同的數據在所有節點上復制。
模型和數據并行: 我們可以在節點之間同時分割模型和數據。注意,不同的節點處理不同批次的數據。
專家并行: 專家被放置在不同的節點上。如果與數據并行結合,每個節點擁有不同的專家,數據在所有節點之間分割。
在專家并行中,專家被放置在不同的節點上,每個節點處理不同批次的訓練樣本。對于非 MoE 層,專家并行的行為與數據并行相同。對于 MoE 層,序列中的令牌被發送到擁有所需專家的節點。
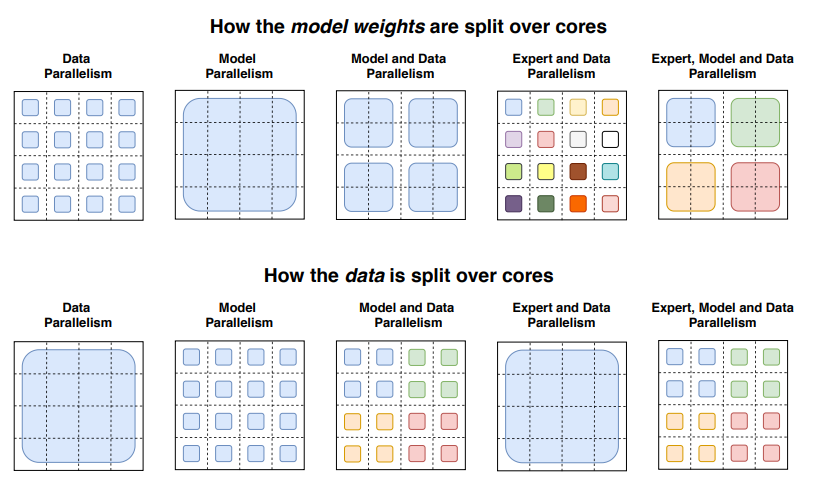
Switch Transformers 論文中展示如何使用不同的并行技術在節點上分割數據和模型的插圖
容量因子和通信開銷
提高容量因子 (Capacity Factor, CF) 可以增強模型的性能,但這也意味著更高的通信成本和對保存激活值的顯存的需求。在設備通信帶寬有限的情況下,選擇較小的容量因子可能是更佳的策略。一個合理的初始設置是采用 Top-2 路由、1.25 的容量因子,同時每個節點配置一個專家。在評估性能時,應根據需要調整容量因子,以在設備間的通信成本和計算成本之間找到一個平衡點。
部署技術
您可以在 Inference Endpoints 部署 mistralai/Mixtral-8x7B-Instruct-v0.1。
部署混合專家模型 (MoE) 的一個關鍵挑戰是其龐大的參數規模。對于本地使用情況,我們可能希望使用更小的模型。為了使模型更適合部署,下面是幾種有用的技術:
預先蒸餾實驗: Switch Transformers 的研究者們進行了預先蒸餾的實驗。他們通過將 MoE 模型蒸餾回其對應的稠密模型,成功保留了 30-40%的由稀疏性帶來的性能提升。預先蒸餾不僅加快了預訓練速度,還使得在推理中使用更小型的模型成為可能。
任務級別路由: 最新的方法中,路由器被修改為將整個句子或任務直接路由到一個專家。這樣做可以提取出一個用于服務的子網絡,有助于簡化模型的結構。
專家網絡聚合: 這項技術通過合并各個專家的權重,在推理時減少了所需的參數數量。這樣可以在不顯著犧牲性能的情況下降低模型的復雜度。
高效訓練
FasterMoE (2022 年 3 月) 深入分析了 MoE 在不同并行策略下的理論性能極限,并且探索了一系列創新技術,包括用于專家權重調整的方法、減少延遲的細粒度通信調度技術,以及一個基于最低延遲進行專家選擇的拓撲感知門控機制。這些技術的結合使得 MoE 運行速度提升高達 17 倍。
Megablocks (2022 年 11 月) 則專注于通過開發新的 GPU kernel 來處理 MoE 模型中的動態性,以實現更高效的稀疏預訓練。其核心優勢在于,它不會丟棄任何令牌,并能高效地適應現代硬件架構 (支持塊稀疏矩陣乘),從而達到顯著的加速效果。Megablocks 的創新之處在于,它不像傳統 MoE 那樣使用批量矩陣乘法 (這通常假設所有專家形狀相同且處理相同數量的令牌),而是將 MoE 層表示為塊稀疏操作,可以靈活適應不均衡的令牌分配。
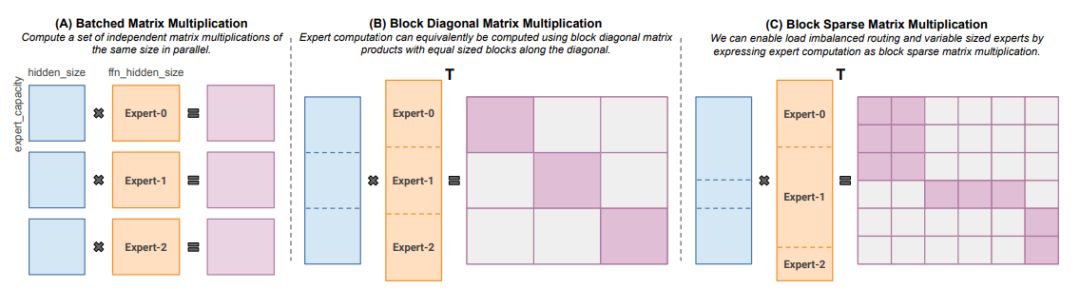
針對不同規模的專家和令牌數量的塊稀疏矩陣乘法。該圖來自 MegaBlocks 論文
開源混合專家模型
目前,下面這些開源項目可以用于訓練混合專家模型 (MoE):
Megablocks: https://github.com/stanford-futuredata/megablocks
Fairseq: https://github.com/facebookresearch/fairseq/tree/main/examples/moe_lm
OpenMoE: https://github.com/XueFuzhao/OpenMoE
對于開源的混合專家模型 (MoE),你可以關注下面這些:
Switch Transformers (Google): 基于 T5 的 MoE 集合,專家數量從 8 名到 2048 名。最大的模型有 1.6 萬億個參數。
NLLB MoE (Meta): NLLB 翻譯模型的一個 MoE 變體。
OpenMoE: 社區對基于 Llama 的模型的 MoE 嘗試。
Mixtral 8x7B (Mistral): 一個性能超越了 Llama 2 70B 的高質量混合專家模型,并且具有更快的推理速度。此外,還發布了一個經過指令微調的模型。有關更多信息,可以在 Mistral 的 公告博客文章 中了解。
一些有趣的研究方向
首先是嘗試將稀疏混合專家模型 (SMoE)蒸餾回到具有更少實際參數但相似等價參數量的稠密模型。
MoE 的量化也是一個有趣的研究領域。例如,QMoE (2023 年 10 月) 通過將 MoE 量化到每個參數不到 1 位,將 1.6 萬億參數的 Switch Transformer 所需的存儲從 3.2TB 壓縮到僅 160GB。
簡而言之,一些值得探索的有趣領域包括:
將 Mixtral 蒸餾成一個稠密模型。
探索合并專家模型的技術及其對推理時間的影響。
嘗試對 Mixtral 進行極端量化的實驗。
-
人工智能
+關注
關注
1794文章
47642瀏覽量
239688 -
開源
+關注
關注
3文章
3398瀏覽量
42649 -
模型
+關注
關注
1文章
3298瀏覽量
49075
原文標題:混合專家模型 (MoE) 詳解
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【大語言模型:原理與工程實踐】大語言模型的預訓練
Pytorch模型訓練實用PDF教程【中文】
微軟在ICML 2019上提出了一個全新的通用預訓練方法MASS

新的預訓練方法——MASS!MASS預訓練幾大優勢!

一種側重于學習情感特征的預訓練方法

時識科技提出新脈沖神經網絡訓練方法 助推類腦智能產業落地
介紹幾篇EMNLP'22的語言模型訓練方法優化工作
對標OpenAI GPT-4,MiniMax國內首個MoE大語言模型全量上線
谷歌模型訓練軟件有哪些功能和作用
基于NVIDIA Megatron Core的MOE LLM實現和訓練優化

MOE與MOT:提升LLM效能的關鍵策略比較





 工商網監
工商網監
評論