

我們一篇關于人體動作預測的研究工作被計算機視覺國際頂級會議ICCV 2023錄用,代碼[1]開源,demo講解[2]、項目主頁[3]、中文文檔[4]開放。

HumanMAC: Masked Motion Completion for Human Motion Prediction 主頁:https://lhchen.top/Human-MAC 論文:https://arxiv.org/abs/2302.03665 代碼:https://github.com/LinghaoChan/HumanMAC
人體動作預測是計算機視覺和圖形學中的一個經典問題,旨在提升預測結果的多樣性、準確性,并在自動駕駛、動畫制作等多領域有非常多具體的應用。本研究梳理了今年來大家對于該問題的建模方式,認為以往的大多數工作對于動作預測任務都是使用一種encoding-decoding的范式。這類范式大多是將觀測幀編碼進隱空間,然后從隱空間解碼出預測幀。我們認為這種方式存在三個缺點:
大多數SOTA的方法需要多個loss作為目標約束,需要精細化地調節多個loss之間的權重,需要極其繁重的調參工程。
大多數SOTA的方法需要多階段訓練,特別是需要預訓練encoder和decoder,這使得預測結果非常依賴于預訓練的質量。
對于這些方法來說,很難實現不同類別運動的切換,例如從“WalkDog”到“Sitting”的切換,這對于結果多樣性至關重要。出現這個現象的原因是這些方法所使用的訓練數據包括很少這樣的切換。
為克服上述問題,我們提出了一種建模動作預測問題的全新范式:掩碼動作補全。如圖1(b)所示,我們認為預測問題就是一種特殊的補全問題,可以借助diffusion model的補全能力解決上述挑戰。如果使用這種范式,我們是需要一個loss、訓練一個階段就可以實現預測,可以說是“大道至簡”。并且由于我們建模了全局的動作,模型很容易學習到平滑性,就能自動實現動作的切換。
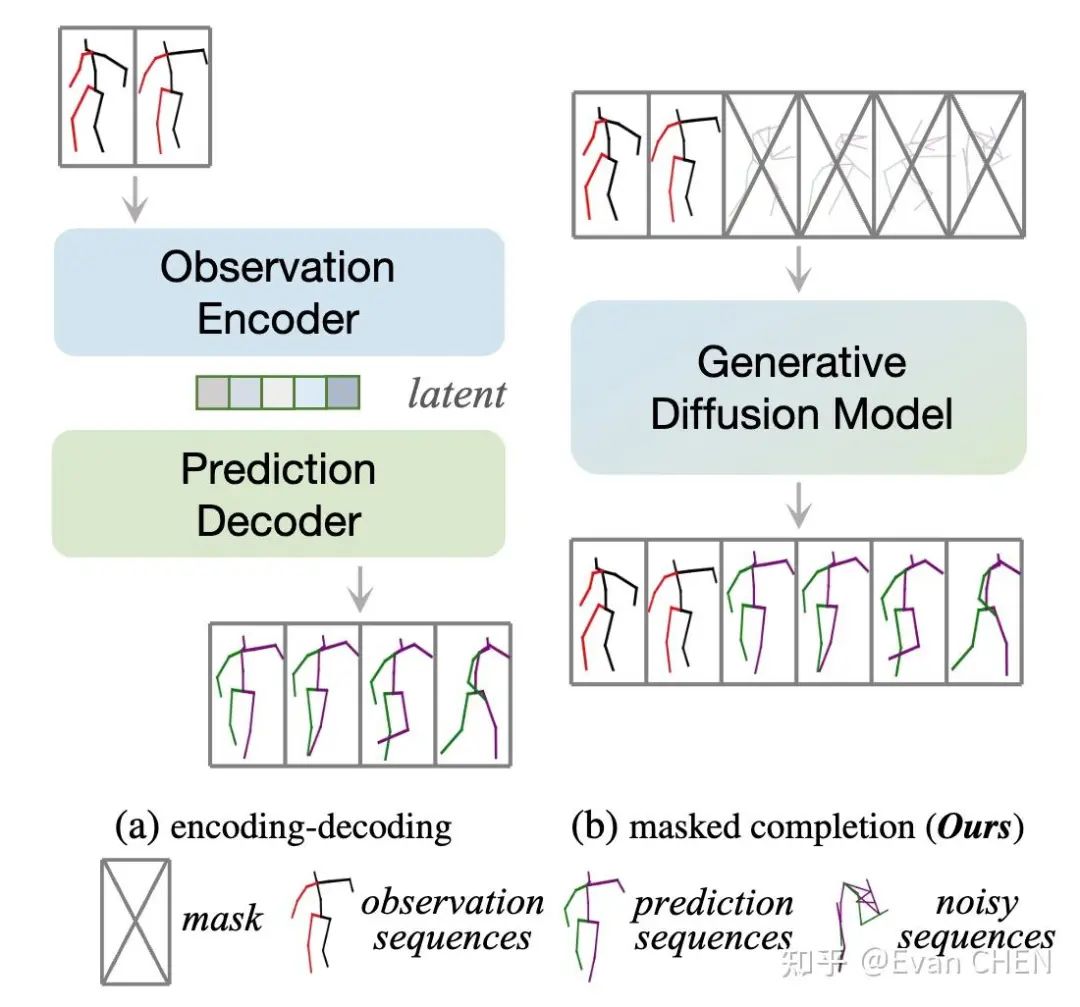
encoding-decoding方式與掩碼運動補全的比較。(a)encoding-decoding的方法將觀測幀顯式地編碼到隱空間,然后將隱空間變量解碼為預測結果。(b)HumanMAC在訓練階段由噪聲生成運動。在推理階段完成補全動作的任務。
為了解決動作抖動等問題,我們借鑒了以往工作在頻域建模的思路[5][6],通過DCT變換,對數據在頻域進行訓練。也就是說,我們的diffusion model是動作頻譜的生成模型,在輸出結果的時候只需要做iDCT變換即可復原動作。為此,我們設計了一個補全算法:DCT-Completion。算法流程和示意圖如下。

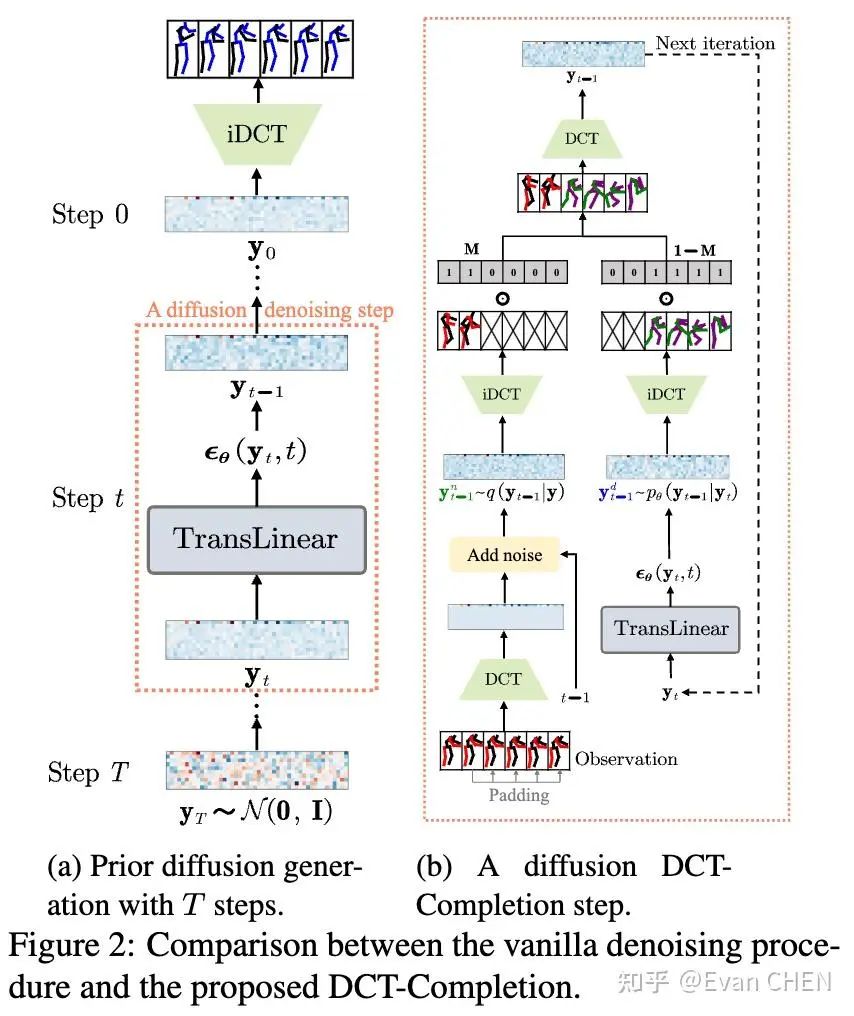
由于動作預測的問題只是一個特殊的掩碼補全問題,我們可以靈活地使用mask實現各種“花式”可控動作補全:
動作切換
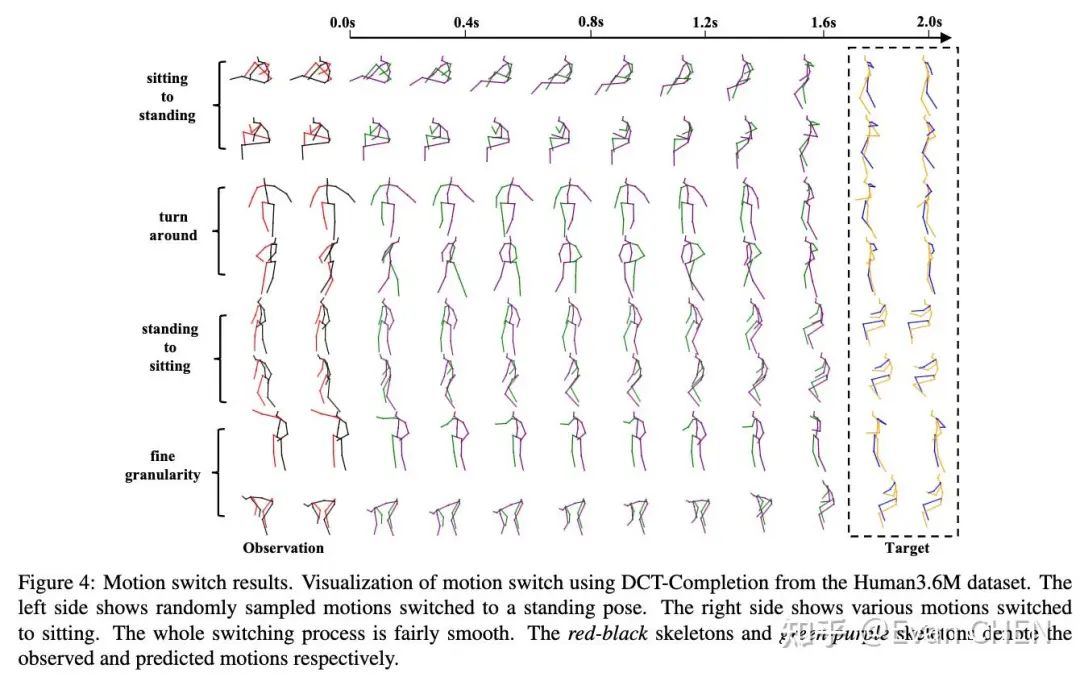
動作切換
特定軀體可控動作編輯
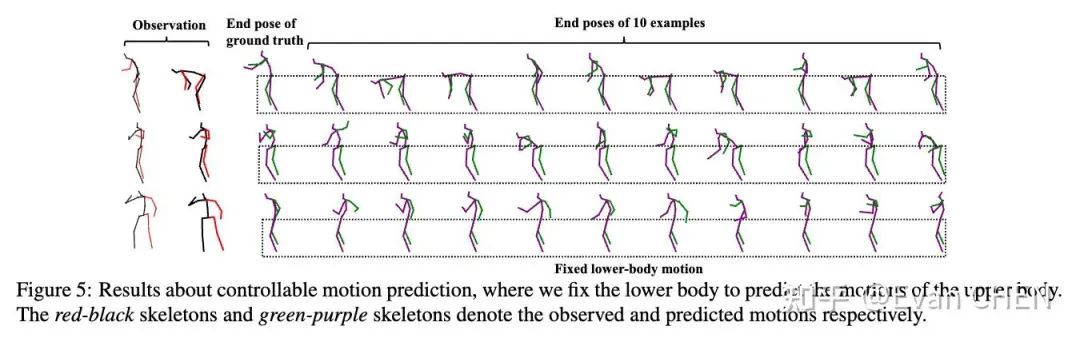
特定軀體可控動作編輯
在量化指標上我們僅僅通過一個loss、一階段訓練就可以和以往的工作不相上下了(我們還比較了最新的arxiv算法)。多樣性的指標遜色于baseline方法的原因,主要來自于baseline方法生成的“多樣”結果存在大量的failure cases,詳情可以見論文和demo中的可視化結果比較。
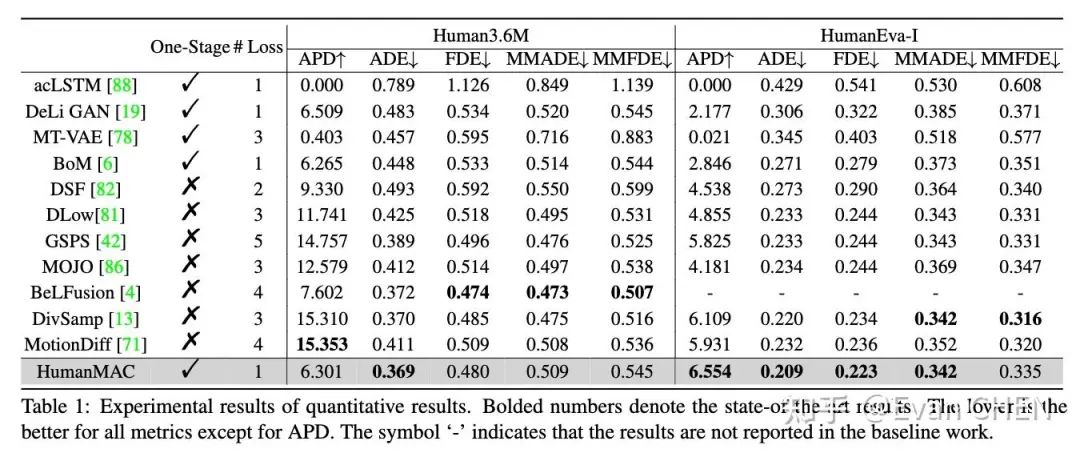
主實驗結果
在正文中,我們對網絡結構、DCT設計、頻譜頻段選擇、網絡結構、采樣步數、噪聲建模等進行了精細的消融驗證。同時,由于以往研究的codebase計算效率太低,我們重新優化了評估代碼并開源(加速上千倍),為后續研究者提供便利。
為了探究模型的泛化性能,我們還做了在H3.6M數據訓練,在AMASS上做zero-shot預測實驗的研究,效果也特別好。
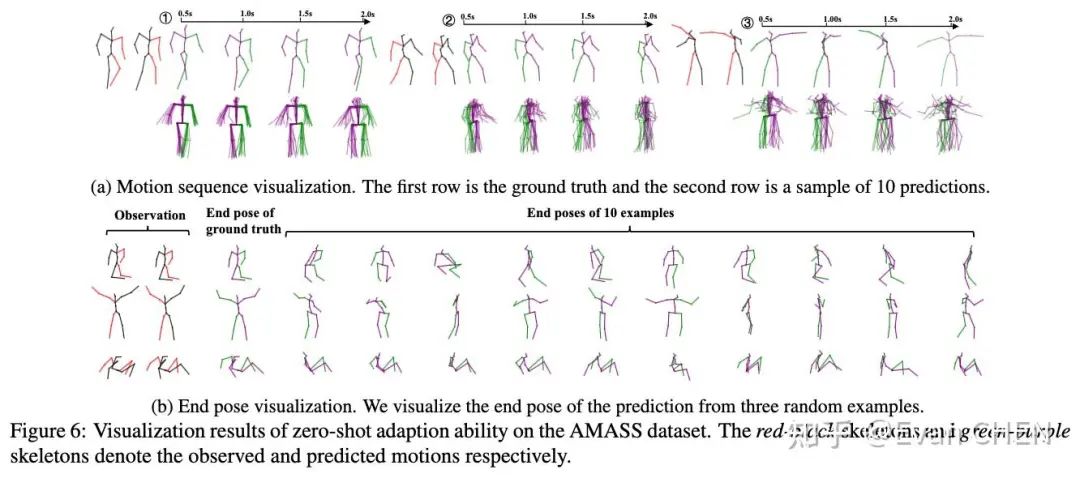
AMASS上的zero-shot預測實驗
這是我們基于對動作生成任務全新理解,在動作預測問題上的一個探索性工作。我們的大量實驗表明這種框架的擴展性非常好,還有很大的擴展空間,歡迎大家關注我們的后續工作。
該研究是我和原來本科的同學多次交流獲得的靈感,在此也感謝一下母校。衷心感謝所有合作者,特別是Xiaobo全方位的指導,讓我獲益匪淺(^_^)。P.S.: 該工作做完剛剛掛出arxiv的時候就有很多工業界的同行發郵件來交流,甚至希望部署到他們的產品線中,給予了我們極大的鼓舞,在此也向他們表示感謝。
-
模型
+關注
關注
1文章
3461瀏覽量
49775 -
DCT
+關注
關注
1文章
56瀏覽量
20086 -
計算機視覺
+關注
關注
8文章
1705瀏覽量
46452
原文標題:ICCV 2023 | 清華&西電提出HumanMAC:人體動作預測新范式
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
R&S FSL6臺式信號分析儀的功能特點及應用范圍
歐拉 Summit 2021 安全&可靠性&運維專場:主流備份技術探討

485&&Modbus協議

存儲類&作用域&生命周期&鏈接屬性
2021 Kubernetes on AI &amp;amp;amp; Edge Day圓滿舉行 共探邊緣云融合

如何區分Java中的&amp;和&amp;&amp;
if(a==1 &amp;&amp; a==2 &amp;&amp; a==3),為true,你敢信?

HarmonyOS &amp;amp;amp;潤和HiSpark 實戰開發,“碼”上評選活動,邀您來賽!!!

你使用shell腳本中的2&gt;&amp;1了嗎?
攝像機&amp;amp;雷達對車輛駕駛的輔助
FS201資料(pcb &amp; DEMO &amp; 原理圖)
onsemi LV/MV MOSFET 產品介紹 &amp;amp; 行業應用






 工商網監
工商網監

評論