") 不同語言運(yùn)行100萬個并發(fā)任務(wù)需要多少內(nèi)存?
不同語言運(yùn)行100萬個并發(fā)任務(wù)需要多少內(nèi)存?
來自:博客園,譯者:InCerry
正文
在這篇博客文章中,我深入探討了異步和多線程編程在內(nèi)存消耗方面的比較,跨足了如Rust、Go、Java、C#、Python、Node.js 和 Elixir等流行語言。
不久前,我不得不對幾個計算機(jī)程序進(jìn)行性能比較,這些程序旨在處理大量的網(wǎng)絡(luò)連接。我發(fā)現(xiàn)那些程序在內(nèi)存消耗方面有巨大的差異,甚至超過20倍。有些程序在10000個連接中僅消耗了略高于100MB的內(nèi)存,但另一些程序卻達(dá)到了接近3GB。
不幸的是,這些程序相當(dāng)復(fù)雜,功能也不盡相同,因此很難直接進(jìn)行比較并得出有意義的結(jié)論,因?yàn)檫@不是一個典型的蘋果到蘋果的比較。這促使我想出了創(chuàng)建一個綜合性基準(zhǔn)測試的想法。
基準(zhǔn)測試
我使用各種編程語言創(chuàng)建了以下程序:
啟動N個并發(fā)任務(wù),每個任務(wù)等待10秒鐘,然后在所有任務(wù)完成后程序就退出。任務(wù)的數(shù)量由命令行參數(shù)控制。
在ChatGPT的小小幫助下,我可以在幾分鐘內(nèi)用各種編程語言編寫出這樣的程序,甚至包括那些我不是每天都在用的編程語言。為了方便起見,所有基準(zhǔn)測試代碼都可以在我的GitHub上找到。
Rust
我用Rust編寫了3個程序。第一個程序使用了傳統(tǒng)的線程。以下是它的核心部分:
letmuthandles=Vec::new(); for_in0..num_threads{ lethandle=thread::spawn(||{ thread::from_secs(10)); }); handles.push(handle); } forhandleinhandles{ handle.join().unwrap(); }
另外兩個版本使用了async,一個使用tokio,另一個使用async-std。以下是使用tokio的版本的核心部分:
letmuttasks=Vec::new();
for_in0..num_tasks{
tasks.push(task::spawn(async{
time::from_secs(10)).await;
}));
}
fortaskintasks{
task.await.unwrap();
}
async-std版本與此非常相似,因此我在這里就不再引用了。
Go
在Go語言中,goroutine是實(shí)現(xiàn)并發(fā)的基本構(gòu)建塊。我們不需要分開等待它們,而是使用WaitGroup來代替:
varwgsync.WaitGroup fori:=0;i
Java
Java傳統(tǒng)上使用線程,但JDK 21提供了虛擬線程的預(yù)覽,這是一個類似于goroutine的概念。因此,我創(chuàng)建了兩個版本的基準(zhǔn)測試。我也很好奇Java線程與Rust線程的比較。
Listthreads=newArrayList<>(); for(inti=0;i{ try{ Thread.sleep(Duration.ofSeconds(10)); }catch(InterruptedExceptione){ } }); thread.start(); threads.add(thread); } for(Threadthread:threads){ thread.join(); }
下面是使用虛擬線程的版本。注意看它是多么的相似!幾乎一模一樣!
Listthreads=newArrayList<>(); for(inti=0;i{ try{ Thread.sleep(Duration.ofSeconds(10)); }catch(InterruptedExceptione){ } }); threads.add(thread); } for(Threadthread:threads){ thread.join(); }
C#
與Rust類似,C#對async/await也有一流的支持:
Listtasks=newList (); for(inti=0;i { awaitTask.Delay(TimeSpan.FromSeconds(10)); }); tasks.Add(task); } awaitTask.WhenAll(tasks);
Node.JS
下面是 Node.JS:
constdelay=util.promisify(setTimeout); consttasks=[]; for(leti=0;i
Python
還有Python 3.5版本中加入了async/await,所以可以這樣寫:
asyncdefperform_task(): awaitasyncio.sleep(10) tasks=[] fortask_idinrange(num_tasks): task=asyncio.create_task(perform_task()) tasks.append(task) awaitasyncio.gather(*tasks)
Elixir
Elixir 也因其異步功能而聞名:
tasks= for_<-?1..num_tasks?do ????????Task.async(fn?-> :timer.sleep(10000) end) end Task.await_many(tasks,:infinity)
測試環(huán)境
硬件: Intel(R) Xeon(R) CPU E3-1505M v6 @ 3.00GHz
操作系統(tǒng): Ubuntu 22.04 LTS, Linux p5520 5.15.0-72-generic
Rust: 1.69
Go: 1.18.1
Java: OpenJDK “21-ea” build 21-ea+22-1890
.NET: 6.0.116
Node.JS: v12.22.9
Python: 3.10.6
Elixir: Erlang/OTP 24 erts-12.2.1, Elixir 1.12.2
所有程序在可用的情況下都使用發(fā)布模式(release mode)進(jìn)行運(yùn)行。其他選項(xiàng)保持為默認(rèn)設(shè)置。
結(jié)果
最小內(nèi)存占用
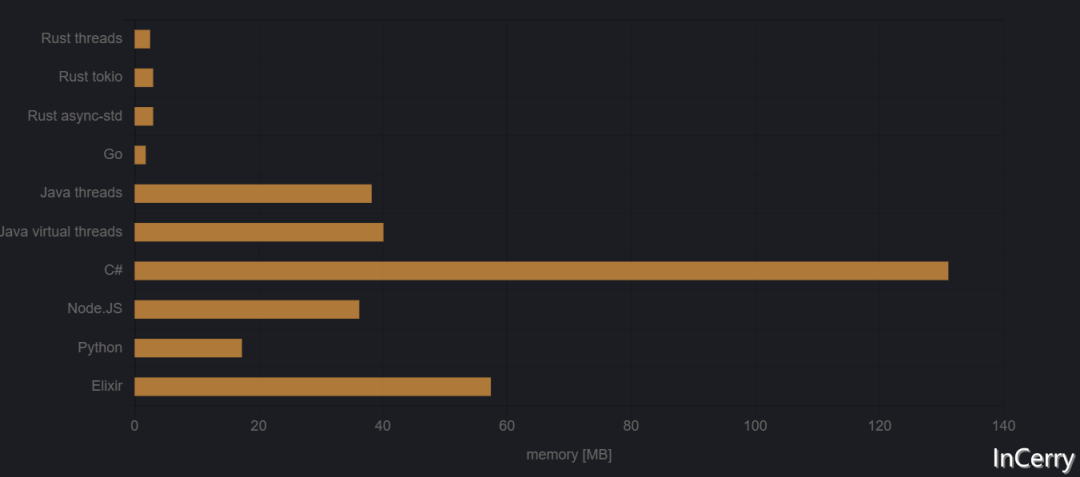
讓我們從一些小的任務(wù)開始。因?yàn)槟承┻\(yùn)行時需要為自己分配一些內(nèi)存,所以我們首先只啟動一個任務(wù)。
圖1:啟動一個任務(wù)所需的峰值內(nèi)存
我們可以看到,這些程序確實(shí)分為兩組。Go和Rust程序,靜態(tài)編譯為本地可執(zhí)行文件,需要很少的內(nèi)存。其他在托管平臺上運(yùn)行或通過解釋器消耗更多內(nèi)存的程序,盡管在這種情況下Python表現(xiàn)得相當(dāng)好。這兩組之間的內(nèi)存消耗差距大約有一個數(shù)量級。
讓我感到驚訝的是,.NET某種程度上具有最差的內(nèi)存占用,但我猜這可以通過某些設(shè)置進(jìn)行調(diào)整。如果有任何技巧,請在評論中告訴我。在調(diào)試模式和發(fā)布模式之間,我沒有看到太大的區(qū)別。
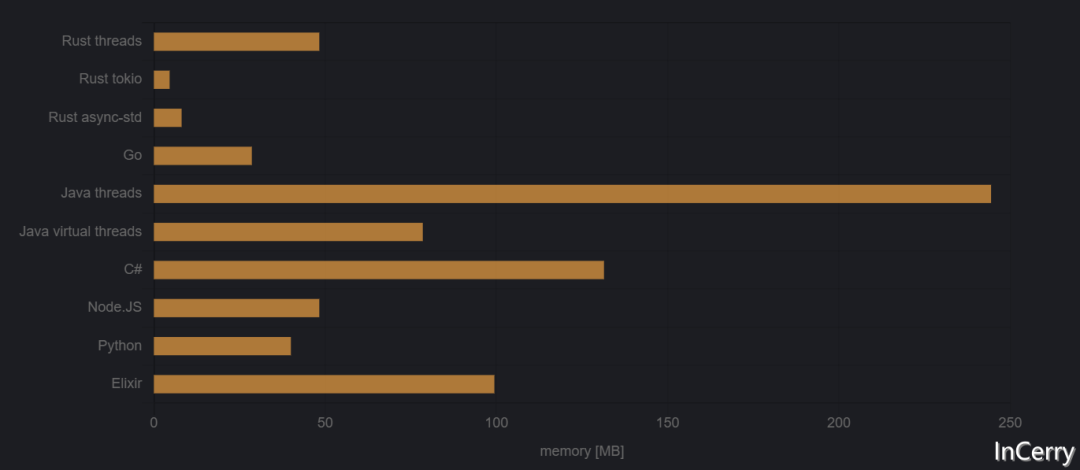
10k 任務(wù)
圖2:啟動10,000個任務(wù)所需的峰值內(nèi)存
這里有一些意外發(fā)現(xiàn)!大家可能都預(yù)計線程將成為這個基準(zhǔn)測試的大輸家。這對于Java線程確實(shí)如此,實(shí)際上它們消耗了將近250MB的內(nèi)存。但是從Rust中使用的原生Linux線程似乎足夠輕量級,在10000個線程時,內(nèi)存消耗仍然低于許多其他運(yùn)行時的空閑內(nèi)存消耗。異步任務(wù)或虛擬(綠色)線程可能比原生線程更輕,但我們在只有10000個任務(wù)時看不到這種優(yōu)勢。我們需要更多的任務(wù)。
另一個意外之處是Go。Goroutines應(yīng)該非常輕量,但實(shí)際上,它們消耗的內(nèi)存超過了Rust線程所需的50%。坦率地說,我本以為Go的優(yōu)勢會更大。因此,我認(rèn)為在10000個并發(fā)任務(wù)中,線程仍然是相當(dāng)有競爭力的替代方案。Linux內(nèi)核在這方面肯定做得很好。
Go也失去了它在上一個基準(zhǔn)測試中相對于Rust異步所占據(jù)的微小優(yōu)勢,現(xiàn)在它比最好的Rust程序消耗的內(nèi)存多出6倍以上。它還被Python超越。
最后一個意外之處是,在10000個任務(wù)時,.NET的內(nèi)存消耗并沒有從空閑內(nèi)存使用中顯著增加。可能它只是使用了預(yù)分配的內(nèi)存。或者它的空閑內(nèi)存使用如此高,10000個任務(wù)太少以至于不重要。
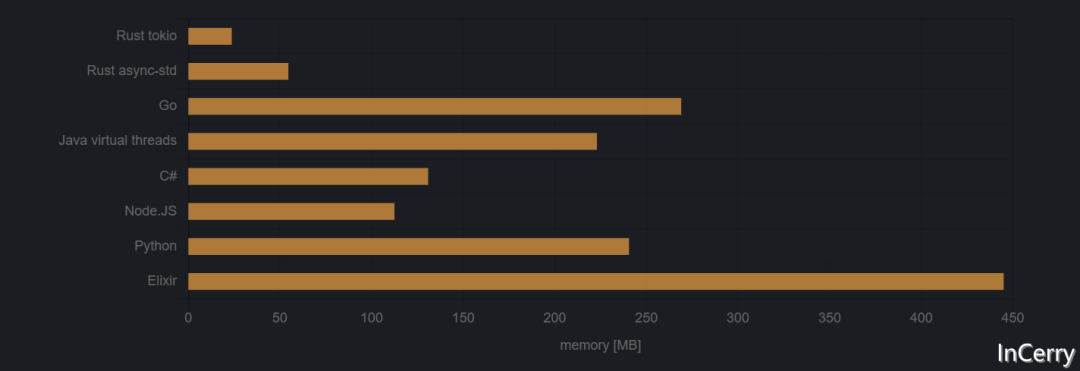
100k 任務(wù)
我無法在我的系統(tǒng)上啟動100,000個線程,所以線程基準(zhǔn)測試必須被排除。可能這可以通過某種方式調(diào)整系統(tǒng)設(shè)置來實(shí)現(xiàn),但嘗試了一個小時后,我放棄了。所以在100,000個任務(wù)時,你可能不想使用線程。
在這一點(diǎn)上,Go程序不僅被Rust擊敗,還被Java、C#和Node.JS擊敗。
而Linux .NET可能有作弊,因?yàn)樗膬?nèi)存使用仍然沒有增加。 我不得不仔細(xì)檢查一下是否確實(shí)啟動了正確數(shù)量的任務(wù),果然,它確實(shí)做到了。而且它在大約10秒后仍然可以退出,所以它沒有阻塞主循環(huán)。神奇!.NET干得好。
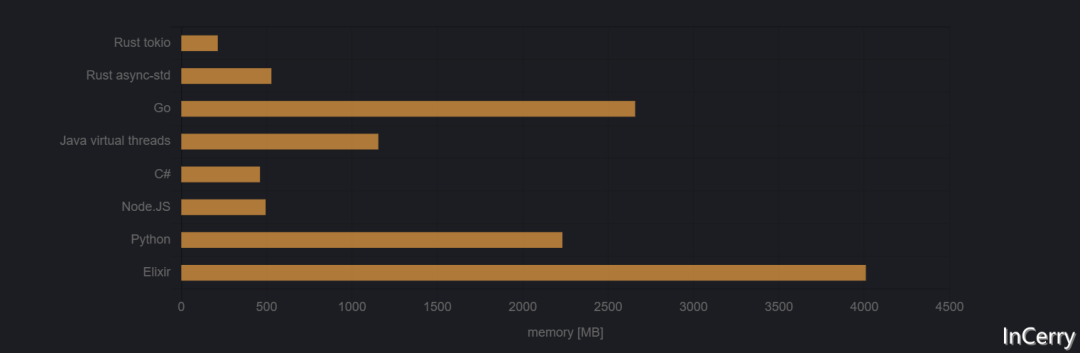
100萬任務(wù)
現(xiàn)在我們來試試極限場景。
在100萬個任務(wù)時,Elixir放棄了,提示 ** (SystemLimitError) a system limit has been reached。編輯:有些評論者指出我可以增加進(jìn)程限制。在elixir啟動參數(shù)中添加--erl '+P 1000000'后,它運(yùn)行得很好。
圖4:啟動100萬個任務(wù)所需的峰值內(nèi)存
終于我們看到了C#程序內(nèi)存消耗的增加。但它仍然非常具有競爭力。它甚至成功地稍稍擊敗了Rust的一個運(yùn)行時!
Go與其他程序之間的差距擴(kuò)大了。現(xiàn)在Go在勝利者面前輸?shù)袅顺^12倍。它還輸給了Java 2倍以上,這與人們普遍認(rèn)為JVM是內(nèi)存大戶,而Go輕量的觀念相矛盾。
Rust的tokio依然無可匹敵。在看過它在100k任務(wù)下的表現(xiàn)后,這并不令人驚訝。
最后的話
正如我們觀察到的,大量的并發(fā)任務(wù)可能會消耗大量的內(nèi)存,即使它們不執(zhí)行復(fù)雜的操作。不同的編程語言運(yùn)行時具有不同的取舍,有些在少量任務(wù)中表現(xiàn)輕量和高效,但在數(shù)十萬個任務(wù)中的擴(kuò)展性表現(xiàn)差。相反,其他一些具有高初始開銷的運(yùn)行時可以毫不費(fèi)力地應(yīng)對高負(fù)載。值得注意的是,并非所有運(yùn)行時都能在默認(rèn)設(shè)置下處理大量的并發(fā)任務(wù)。
這個比較僅關(guān)注內(nèi)存消耗,而任務(wù)啟動時間和通信速度等其他因素同樣重要。值得注意的是,在100萬個任務(wù)時,我觀察到啟動任務(wù)的開銷變得明顯,大多數(shù)程序需要超過12秒才能完成。敬請期待即將到來的基準(zhǔn)測試,我將深入探討其他方面。
評論區(qū)
評論區(qū)也有很多大佬給出了建議,比較有意思,所以也翻譯了放在下方
JB-Dev
在C#實(shí)現(xiàn)中,你不需要調(diào)用Task.Run(...)。這會增加第二個任務(wù)延續(xù)的開銷。
在沒有額外開銷的情況下,我觀察到1M基準(zhǔn)測試的內(nèi)存使用量減少了一半以上,從428MB降到183MB(代碼在這里:https://github.com/J-Bax/CS...
例如,不要使用Task.Run(...)而是這樣做:
tasks.Add(Task.Delay(TimeSpan.FromMilliseconds(delayMillisec)));
Christoph Berger
Go的結(jié)果并不特別令人驚訝。
每個goroutine開始時的預(yù)分配棧為2KiB,所以一百萬個goroutine消耗大約2GB(2,048 * 1,000,000字節(jié))。
這與我使用go build&& /usr/bin/time -l ./goroutinememorybenchmark運(yùn)行測試代碼時得到的數(shù)字非常接近:
2044968960的最大常駐集大小
(我不確定圖中的2,658 GB是如何測量出來的,但數(shù)量級是相同的。)
毫無疑問,為每個goroutine預(yù)分配一個棧使Go在與那些在真正需要時才分配任何線程本地內(nèi)存的并發(fā)系統(tǒng)的語言相比處于劣勢。(附注:在這特定的上下文中,我將“線程”作為綠色或虛擬線程和goroutine的同義詞。)
我想,在線程做有實(shí)質(zhì)性工作的測試中,各種語言之間的差異可能會大大縮小。
D. Christoph Berge
我不完全了解后面發(fā)生了什么,但對于1000個Goroutine,Go只消耗每個goroutine約300字節(jié)。只有當(dāng)它增加到每個3000 Goroutine時,它才開始每個Goroutine使用2KB。
Berger D.
你是如何得到這些測量結(jié)果的?
不幸的是,我無法復(fù)制你的發(fā)現(xiàn)。
為了獲得較小數(shù)量的goroutine的更準(zhǔn)確結(jié)果,我決定在每次測試運(yùn)行結(jié)束后讀取runtime.MemStats.StackInuse。
結(jié)果:
所有1000個goroutines完成。StackInuse:2,359,296(每個goroutine 2KB)
所有3000個goroutines完成。StackInuse:6,586,368(每個goroutine 2KB)
所有10000個goroutines完成。StackInuse:21,037,056(每個goroutine 2KB)
所有100000個goroutines完成。StackInuse:205,127,680(每個goroutine 2KB)
所有1000000個goroutines完成。StackInuse:2,048,622,592(每個goroutine 2KB)
Witek
對于Elixir / Erlang,默認(rèn)進(jìn)程限制為32k pids。可以通過解釋器標(biāo)志將其增加到20億。例如:erl +P 4000000,我編寫了一個小的Erlang程序來做你所做的事情(但確保在循環(huán)中不分配不必要的內(nèi)存),并且在1百萬個進(jìn)程中峰值RSS使用量為2.7GiB。然而,這仍然非常人工和合成。Erlang默認(rèn)為每個進(jìn)程分配額外的堆,因?yàn)樵诂F(xiàn)實(shí)生活中,您實(shí)際上會在進(jìn)程中執(zhí)行一些操作并需要一點(diǎn)內(nèi)存,因此預(yù)先分配比以后分配更快。如果您真的想在這個愚蠢的基準(zhǔn)測試中減少內(nèi)存使用量,您可以傳遞選項(xiàng)以spawn_opt,或使用自定義+h選項(xiàng)啟動解釋器,例如。+h 10,或者+hms10(默認(rèn)值為?356)。這將將峰值RSS使用率從2.7 GiB降低到1.1 GiB。
審核編輯:湯梓紅
-
計算機(jī)
+關(guān)注
關(guān)注
19文章
7532瀏覽量
88420 -
內(nèi)存
+關(guān)注
關(guān)注
8文章
3047瀏覽量
74207 -
編程語言
+關(guān)注
關(guān)注
10文章
1949瀏覽量
34893 -
程序
+關(guān)注
關(guān)注
117文章
3794瀏覽量
81281 -
多線程
+關(guān)注
關(guān)注
0文章
278瀏覽量
20049
原文標(biāo)題:不同語言運(yùn)行100萬個并發(fā)任務(wù)需要多少內(nèi)存?
文章出處:【微信號:TheAlgorithm,微信公眾號:算法與數(shù)據(jù)結(jié)構(gòu)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
鴻蒙原生應(yīng)用開發(fā)-ArkTS語言基礎(chǔ)類庫多線程并發(fā)概述
鴻蒙原生應(yīng)用開發(fā)-ArkTS語言基礎(chǔ)類庫多線程并發(fā)概述
為何Python運(yùn)行效率低?python語言入門
并發(fā)、并行、進(jìn)程、線程和協(xié)程的區(qū)別
C語言內(nèi)存運(yùn)行時不同變量是怎樣分配的
Lite Actor:方舟Actor并發(fā)模型的輕量級優(yōu)化
ATC'22頂會論文RunD:高密高并發(fā)的輕量級 Serverless 安全容器運(yùn)行時 | 龍蜥技術(shù)
移動應(yīng)用高級語言開發(fā)——并發(fā)探索
HarmonyOS使用多線程并發(fā)能力開發(fā)
高并發(fā)內(nèi)存池項(xiàng)目實(shí)現(xiàn)
接口調(diào)用并發(fā)執(zhí)行十個任務(wù)總結(jié)
C語言運(yùn)行環(huán)境是什么
“本源悟空”全球訪問量突破100萬,已完成14萬個運(yùn)算任務(wù)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論