 華為云應用運維管理平臺獲評中國信通院可觀測性評估先進級
華為云應用運維管理平臺獲評中國信通院可觀測性評估先進級
近日,華為云應用運維管理平臺參與了中國信息通信研究院(以下簡稱“中國信通院”)主辦的“穩保行動”的可觀測性平臺能力評估。經過中國信通院的檢驗,華為云應用運維管理平臺滿足云上軟件系統穩定-可觀測性平臺技術要求,達到了可觀測性平臺技術檢驗的先進級水平。
作為云計算和軟件的權威評估機構,中國信通院在可觀測性平臺和工具的評測中,以通信行業標準《可觀測性平臺技術要求》為依據,客觀真實地評估了廠商的可觀測能力水平。經中國信通院的細致評估,華為云應用運維管理平臺在數據采集、數據處理、數據應用、平臺運維這 4 項檢驗中,滿足了可觀測性平臺先進級能力要求,這也意味著華為云在可觀測性領域已經達到業內領先水平。
華為云應用運維管理平臺是云上應用的一站式立體化運維管理平臺,實時監控應用及相關云資源,采集并關聯資源的各項指標、日志及事件等數據共同分析應用健康狀態,提供靈活的告警及豐富的數據可視化功能,幫助用戶及時發現故障,全面掌握應用、資源及業務的實時運行狀況。
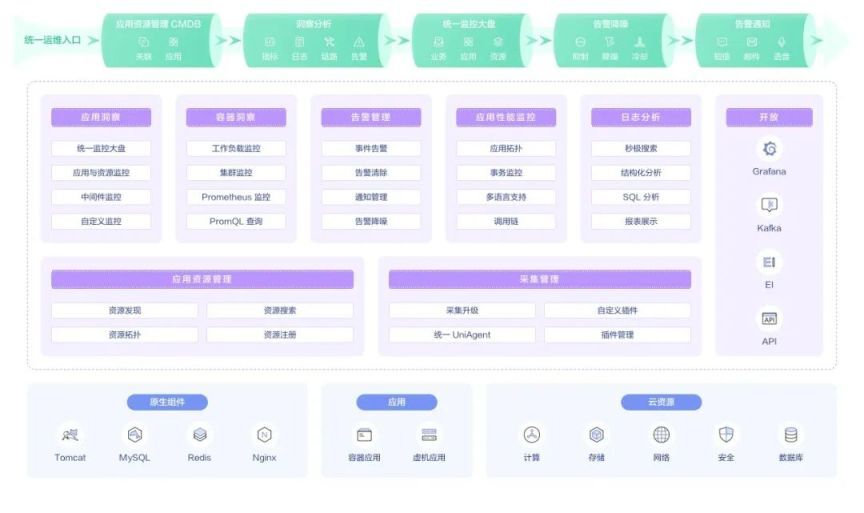
圖 2華為云應用運維管理平臺
一、牢固的基石——應用資源管理和采集管理
應用資源管理
傳統信息技術基礎設施庫(InformationTechnologyInfrastructureLibrary,簡稱 ITIL)流程中面向基礎設施資源的管理方式,易造成各運維服務之間數據割裂、信息不一致等問題。華為云應用運維管理平臺的應用資源管理(簡稱 CMDB)是基于 DevOps 理念打造的面向應用全生命周期的資源管理平臺,是現代自動化運維的基石服務,統一集中管理資源對象與應用之間的關系。
應用資源管理 CMDB 以應用為中心,實現多層級應用、子應用、組件到環境的模型管理,建立應用與云資源依賴關系。通過應用資源管理,可以找到應用與下級微服務以及部署在不同環境(開發環境、測試環境或生產環境等)下的資源實例,包括 ECS、RDS、ELB、CCE 等云服務實例,為應用監控、告警關聯分析以及自動化運維提供配置數據。同時也支持通過開放配置數據接口,輔助第三方系統運維場景建設。
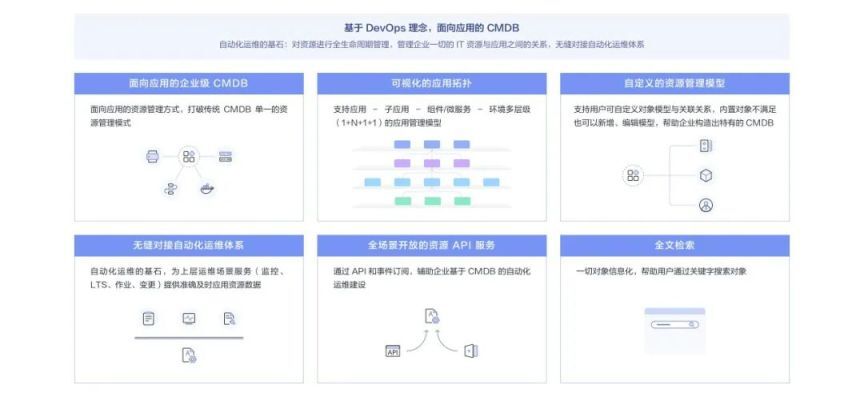
圖 3應用資源管理能力示意
采集管理
作為數據的來源,采集插件至關重要。華為云應用運維管理平臺提供無侵入式采集插件,用戶無需修改應用代碼,只需要部署探針包,修改相應的應用啟動參數,就能對應用進行全方位的數據采集,以便全面掌握應用的運行情況,采集范圍包括但不限于:
1.基礎資源:包含云主機、容器、網絡等;
2 中間件:包含數據庫、消息隊列、應用容器、存儲、日志等;
3.IOT 設備:包含各種邊緣設備、采集的數據范圍包括指標等;
4.前端組件:包含 H5、ios、android、小程序等;
5.后端組件:包含 java、python、nodejs、c#、go 等。
另外華為云應用運維管理平臺還提供插件生命周期管理能力,不同的插件分工采集不同的數據,用戶可以按需安裝、升級、卸載各類插件。
二、強大的核心——指標監控、云日志、應用性能管理
隨著云原生技術逐漸普及,傳統監控系統正朝可觀測性系統演進,業界對可觀測性的共識,是基于可觀測性的三大支柱“metrics、logging、tracing”。
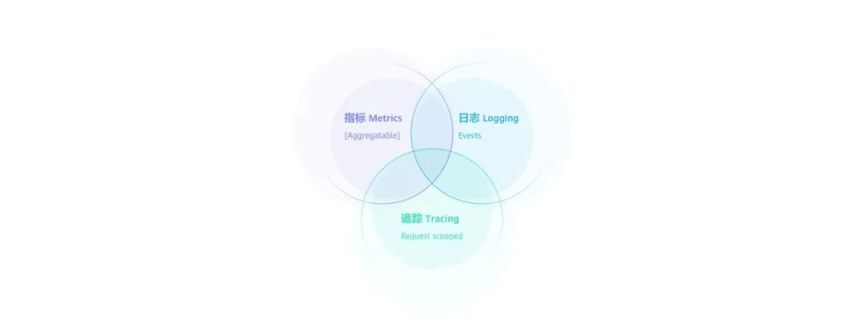
華為云應用運維管理平臺將云監控服務(CloudEye,簡稱 CES)的指標數據、云日志服務(LogTankService,簡稱 LTS)的日志數據、應用性能管理服務(ApplicationPerformanceManagement,簡稱 APM)的性能分析數據進行統一監控,從而提供了對云資源、應用和性能的全面監控和診斷。
指標——云監控服務 CES
云監控 CES 是華為云上資源監控的服務,提供 80 多種云服務、上千類資源指標,涵蓋彈性云服務器、帶寬、數據庫等服務,滿足用戶各類云上資源監控需求。CES 可提供多聚合方式、最長六個月的歷史監控圖表,方便用戶查看近半年業務監控數據。
除了云監控提供的云服務指標外,用戶還可以自定義上報業務指標,通過 OpenAPI、SDK 方式上報,可更全面、深入地監控業務運行狀況。
日志——云日志服務 LTS
在海量數據的時代,讓寶貴的原始日志數據躺在磁盤里日漸沉寂,無法在云時代“一展宏圖”,完全是埋沒了日志數據的價值。而使用華為云日志服務就可以從項目初始便賦予日志數據搜索、分析和探索能力,讓日志數據活起來、變有用。華為云日志服務提供日志采集、秒級搜索、海量存儲、結構化處理、轉儲和可視化圖表等各項能力,可滿足應用運維、可視化分析、等保合規等各類應用場景。
場景 1
日志分析、保障系統安全:實時收集系統產生的日志數據,對日志數據進行分析、歸檔,支持每天百 TB 級日志的接入,十億級日志秒級搜索
場景 2
日志審計:通過實時收集日志,避免數據被誤刪和被非法入侵者刪除的可能性,同時將日志轉儲長期存儲,滿足合規要求
場景 3
問題診斷:系統出現問題或故障時,通過日志快速查詢、精準定位問題所在
場景 4
系統改進:通過阻塞記錄發現站點性能瓶頸,優化緩存策略、數據傳輸策略
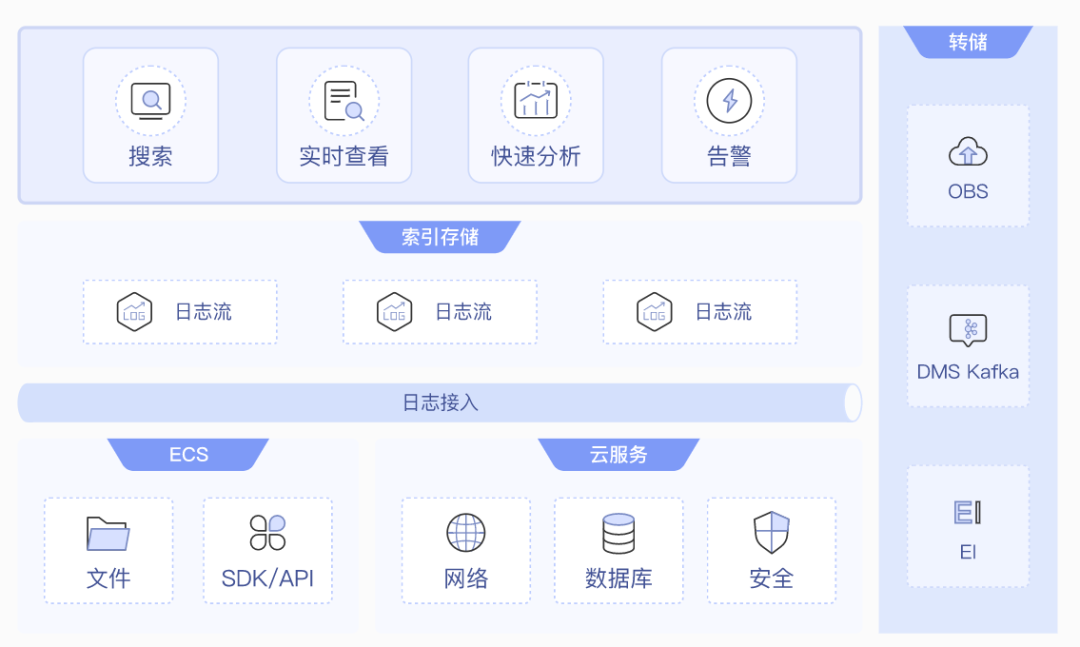
圖 4日志服務示意圖
性能——應用性能管理服務 APM
在華為內部,有上百萬微服務使用著應用性能管理服務 APM,在日常性能診斷、故障定位和排查等場景中,通過使用 APM 實現故障 1 分鐘感知、5 分鐘定界、10 分鐘恢復能力的構筑。APM 有力地支撐了華為云、終端、車、能源等各類型產品的應用性能管理和日常運維保障。
現在,華為云將內部多年積累的應用性能管理能力沉淀到華為云應用性能管理服務 APM 上,向云上用戶提供端到端的全鏈路性能管理服務,包含前端監控、應用性能監控、全面擁抱開源生態,幫助用戶在復雜的業務環境下快速發現應用性能問題,降低 MTTR(平均故障恢復時長),全面掌控應用的性能健康狀況。
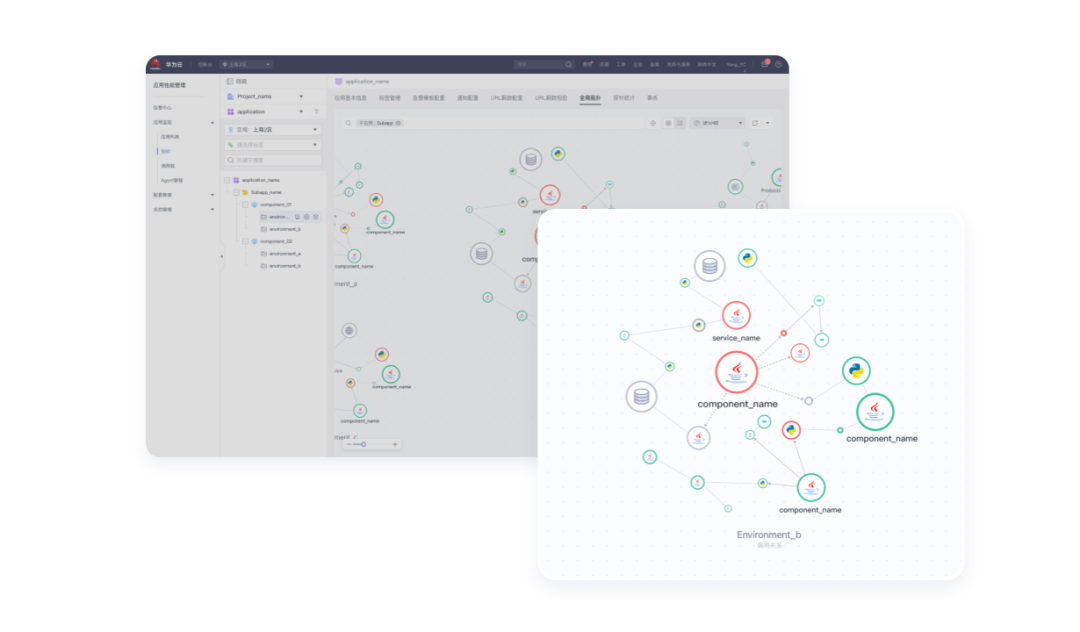
圖 5應用性能管理拓撲示意
三、豐富的周邊能力——統一監控大盤、容器洞察、告警降噪
華為云應用運維管理平臺除了牢固的基石及強大的核心,還提供了豐富的周邊能力。
統一監控大盤
集中管理云監控、云日志、性能、Prometheus 等多維度可觀測性數據源,提供統一監控與分析,用戶可以將來自不同數據源定義在一張監控大屏中顯示,統一管理告警等。
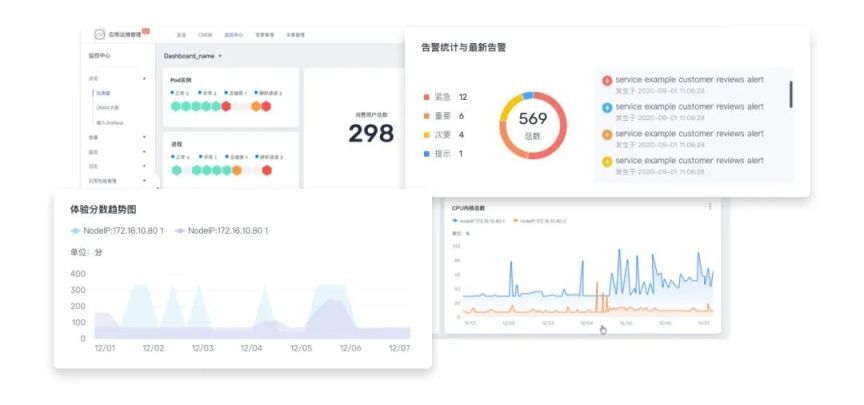
圖 6統一監控大盤示意
容器洞察
無縫對接華為云云容器引擎 CCE,基于原生 Kubernetes 容器和集群模型,用戶可通過 Cluster、Namespace、Deployment、POD 和 Container 進行逐步運維分析,包括 Prometheus 監控、日志和性能管理等;支持將 Promethues 服務器遠程接入(Remote-Write)到華為云應用運維管理平臺,還可通過 PromQL 查詢原生指標并配置告警。
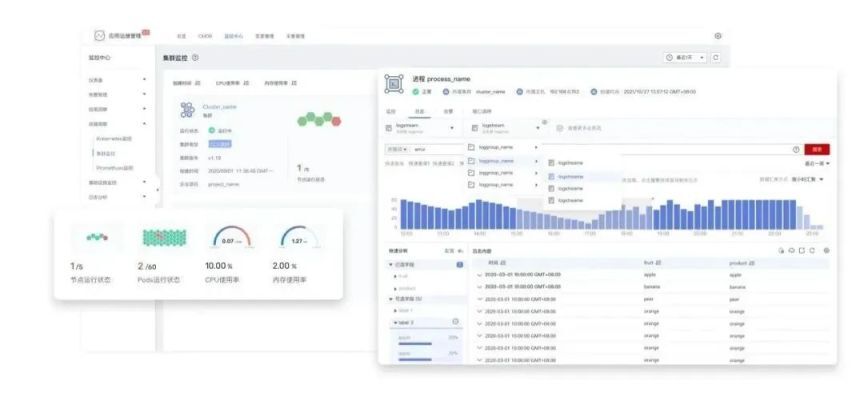
圖 7容器洞察示意
告警降噪
華為云應用運維管理平臺的告警降噪功能,提供分組、抑制和屏蔽告警降噪策略,大大減少了運維人員需要關注的告警量,增加了關鍵告警、高優先級問題的關注度,突出告警的重點問題,提高告警的可靠性,減少誤判和漏警的情況,節省了人力和時間成本,提高了工作效率,有效保障系統的穩定性和安全性。
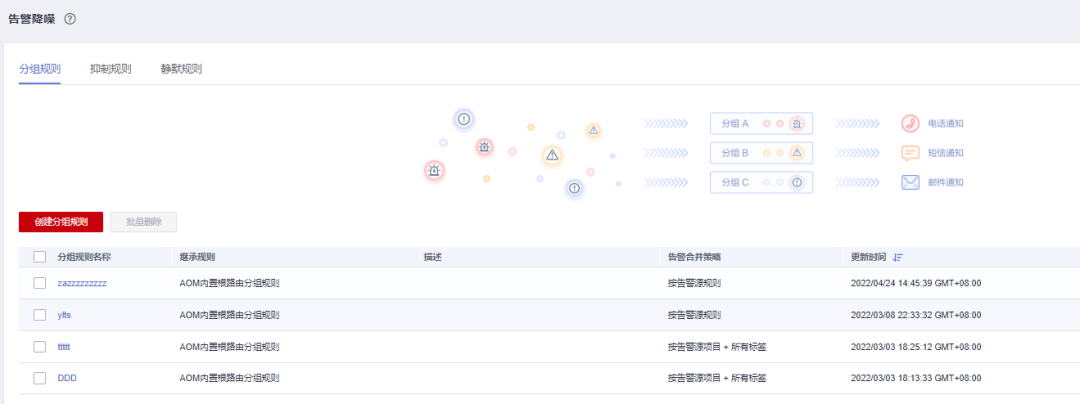
圖 8告警降噪示意圖
如果軟件系統內部情況都不可觀測,更無從談起故障分析和系統改進等穩定性保障手段。依托牢固的基石、強大的核心及豐富的周邊能力,華為云應用運維管理平臺助力企業提高軟件系統的質量和效率,提升用戶體驗和關鍵業務的穩定性,優化業務流程和方向,提高業務決策的質量。
審核編輯 黃宇
-
華為云
+關注
關注
3文章
2605瀏覽量
17473
發布評論請先 登錄
相關推薦
華為云云原生中間件 DCS?&?DMS?通過中國信通院與全球 IPv6 測試中心雙重能力檢測

優刻得獲評信通院“AI云典型案例”,助力大模型場景化和工程化落地


破局新生丨基調聽云可觀測性與應用安全技術研討會在平潭圓滿舉辦

華為云發布全棧可觀測平臺 AOM,以 AI 賦能應用運維可觀測

設備數據接入運維管理云平臺實現什么功能

華為云應用管理和運維平臺ServiceStage全新上線
首家!數勢科技通過中國信通院數據指標管理平臺技術要求專項測試






 工商網監
工商網監
評論