 數據中心到數據中心的復制流程
數據中心到數據中心的復制流程
每家公司都需要為所有重要系統制定災難恢復計劃。從像在某個容器中運行的單個進程這樣的小單元到最大的分布式架構都是如此。特別是對于數據庫,這通常涉及容錯、冗余、定期備份和應急計劃的混合。數據存儲越大,制定好的策略就越困難。
因此,希望能夠在一個數據中心運行分布式數據庫,并以某種方式將所有事務復制到另一個數據中心。通常,事務日志通過網絡傳送,以便在另一個數據中心的另一個相同系統中復制所有內容。一些分布式數據存儲具有對多數據中心感知的內置支持,并且可以以全自動方式在數據中心之間復制。
ArangoDB3.3通過引入多數據中心支持向前邁出了進化的一步,即數據中心到數據中心的復制。我們的解決方案是異步的,并且可以擴展到任意集群大小,前提是您的數據中心之間的網絡鏈接有足夠的帶寬。它是容錯的,沒有單點故障,并且包含許多用于在生產場景中監控的指標。
它能做什么
此功能允許您在兩個不同的數據中心A和B中運行兩個ArangoDB集群,并設置從A到B的異步復制。這意味著數據中心A中的集群A可以照常用于讀取和寫入操作,所有更改為數據通過網絡復制到數據中心B中的另一個集群B。復制是異步的,也就是說,更改會在短暫的延遲后出現在另一端,通常在幾秒鐘內。
在數據中心A發生災難(例如網絡連接完全中斷)的情況下,可以快速停止復制并開始使用數據中心B中的集群B作為集群A的替代品。稍后,當災難結束時,可以要么使用集群A作為集群B的異步副本,要么切換回A并繼續復制到集群A。
挑戰
在本節中,我們不想讓您厭煩技術細節,我們將在適當的時候發布一份白皮書。相反,我們想強調這種方法的挑戰,并概述我們為克服這些挑戰而采取的措施。
單個ArangoDB集群是一個具有良好水平可擴展性的分布式系統。數據容量和查詢性能(讀取和寫入)都與使用的服務器數量呈線性關系。自動分片導致數據的實際更改同時發生在所有服務器的各處。特別是,這意味著——按照設計——沒有一個地方可以建立所有變化的總順序。也就是說,我們正在處理大量數據同時發生更新的分布式混亂。變化率可能會有很大差異,我們將不得不處理大量的寫入突發。
同時,ArangoDB集群是容錯的。例如,如果數據中心中的單個服務器發生故障,ArangoDB集群可以輕松容忍這種損失,并且假設用戶已將復制因子設置為至少2,既不會丟失任何數據,也不會損失可用性. 系統只需切換到使用另一臺服務器,重新分配數據并繼續前進,而不會影響查詢性能。因此,任何適當的復制解決方案都必須滿足集群A中的這些透明故障轉移。
另一方面,安全問題和防火墻維護意味著我們不能輕易地讓許多不同的進程與另一個數據中心中的許多不同進程通信,但同樣,我們也不能輕易地通過兩個進程之間的單個網絡連接的瓶頸移動所有更新在不同的數據中心。
顯然,整個復制系統是分布式系統的分布式系統,因此必須具有可擴展性和容錯性,沒有單點故障。
所有這些挑戰都決定并影響了我們解決方案的設計。
怎么運行的
在數據中心A中,ArangoDB集群A照常運行,無需修改其代碼庫和API,并提供其通常的負載。同樣,在數據中心B中,第二個ArangoDB集群B已部署,但最初處于空閑狀態。
在這兩個數據中心中,我們部署了一個Kafka消息代理,這是一個標準的高性能和容錯隊列系統,能夠在其消息隊列中緩沖大量數據。單個隊列在Kafka中稱為“主題”。這些主題可能會從其他數據中心消費。Kafka有一定的保證,因此在出現網絡問題、個別中斷等情況時,不會丟失任何消息,并且遠程數據中心將始終保持一致的狀態。
此外,在每個數據中心,都有幾個名為“ArangoDBSyncMaster”的程序實例。在每個數據中心,SyncMasters選舉一個領導者,該領導者與另一個數據中心的SyncMaster對話以組織復制。“組織”在這里意味著它計劃必須在兩個數據中心中執行的單個任務以進行復制。本質上,必須復制元信息,例如存在哪些數據庫、集合和用戶,以及分片集合中的實際數據。
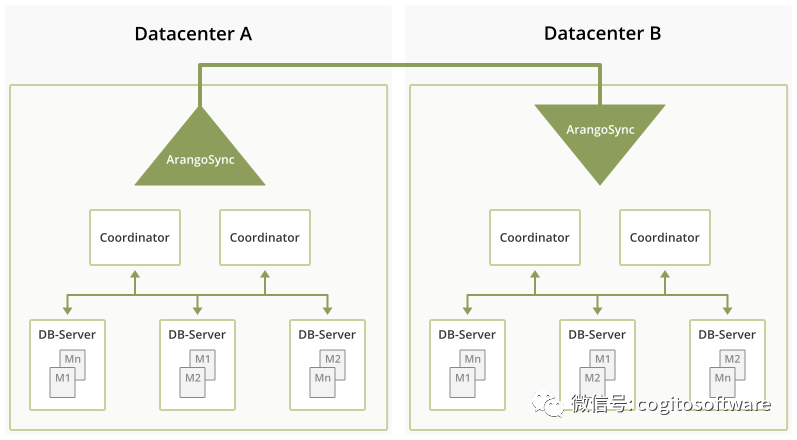
在每個數據中心,領先的SyncMaster指揮一小群SyncWorker,它們執行實際的復制任務。例如,對于一個集合的每個分片,在數據中心A中有一個“發送分片”任務,在數據中心B有一個“接收分片”任務,所有這些分片都由SyncMaster分配給某個SyncWorker。
這些任務負責初始增量同步階段(運行我們在ArangoDB中已有的現有分片同步協議),以及后期更新階段,其中對分片的所有更新都復制到另一個數據中心(使用WALtailing in數據中心A)。
數據流如下:它從ArangoDB集群的某個DBserver開始,到達數據中心A中的一個SyncWorker,然后進入數據中心A中的Kafka。從那里它將被寫入它的數據中心B的SyncWorker使用進入數據中心B中的協調器。顯然,有一些控制消息以相反的方向流動。這些控制消息將由數據中心A從數據中心B的Kafka服務器中獲取。
這對管理員來說意味著,在初始部署后,只需告訴數據中心B中的SyncMaster它應該開始跟隨數據中心A中的集群A,就可以使用一個命令設置異步復制。從那時起,一切都是全自動的,所有數據庫、集合、用戶和權限都會自動復制到另一個數據中心。顯然,有監控和配置工具,但本質上就是這樣。
限制
這是邁向多數據中心意識的第一步,因此自然會受到限制。首先,復制是異步的,所以它總是落后于DatacenterA中的實際事件。通常情況下,連接性好,寫入速率小于跨數據中心鏈路的容量,這個延遲非常小. 然而,應該注意,在復制突然停止并手動切換到集群B的情況下,一些最近寫入的更新可能會丟失。
整個設置是手動配置的,并在兩個數據中心之間工作。此階段不允許寫入副本集群。然而,一個副本集群可以同時是另一個數據中心的源,一個源集群可以有多個副本。也就是說,您可以形成數據中心樹。
最后,關閉復制并開始使用副本到目前為止是一項手動操作,需要管理員做出決定和采取行動。
責任編輯:彭菁
-
服務器
+關注
關注
12文章
9225瀏覽量
85616 -
數據中心
+關注
關注
16文章
4802瀏覽量
72206 -
網絡連接
+關注
關注
0文章
89瀏覽量
10887
原文標題:ArangoDB Enterprise:數據中心到數據中心的復制
文章出處:【微信號:哲想軟件,微信公眾號:哲想軟件】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論