 一文徹底搞懂YOLOv8【網絡結構+代碼+實操】
一文徹底搞懂YOLOv8【網絡結構+代碼+實操】
文章導讀
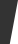

本文概述了YOLOv8算法的核心特性及改進點,詳細介紹了網絡結構、Loss計算、數據增強手段、訓練策略、模型推理,對網絡結構進行了詳盡的分析,最后給出實操步驟。
0.引言
Section Name
Yolo系列對比:

1.概述
Section Name
YOLOv8 算法的核心特性和改動可以歸結為如下:
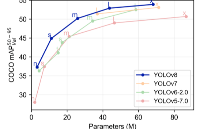
提供了一個全新的 SOTA 模型,包括 P5 640 和 P6 1280 分辨率的目標檢測網絡和基于 YOLACT 的實例分割模型。和 YOLOv5 一樣,基于縮放系數也提供了 N/S/M/L/X 尺度的不同大小模型,用于滿足不同場景需求
01
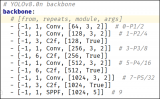
Backbone
骨干網絡和 Neck 部分可能參考了 YOLOv7 ELAN 設計思想,將 YOLOv5 的 C3 結構換成了梯度流更豐富的 C2f 結構,并對不同尺度模型調整了不同的通道數。
屬于對模型結構精心微調,不再是無腦一套參數應用所有模型,大幅提升了模型性能。不過這個 C2f 模塊中存在 Split 等操作對特定硬件部署沒有之前那么友好了
02
Head
Head部分較yolov5而言有兩大改進:1)換成了目前主流的解耦頭結構(Decoupled-Head),將分類和檢測頭分離 2)同時也從 Anchor-Based 換成了 Anchor-Free
03
Loss
1) YOLOv8拋棄了以往的IOU匹配或者單邊比例的分配方式,而是使用了Task-Aligned Assigner正負樣本匹配方式。2)并引入了 Distribution Focal Loss(DFL)
04
Train
訓練的數據增強部分引入了 YOLOX 中的最后 10 epoch 關閉 Mosiac 增強的操作,可以有效地提升精度
從上面可以看出,YOLOv8 主要參考了最近提出的諸如 YOLOX、YOLOv6、YOLOv7 和 PPYOLOE 等算法的相關設計,本身的創新點不多,偏向工程實踐,主推的還是 ultralytics 這個框架本身。
下面將按照模型結構設計、Loss 計算、訓練數據增強、訓練策略和模型推理過程共 5 個部分詳細介紹 YOLOv8 目標檢測的各種改進,實例分割部分暫時不進行描述。
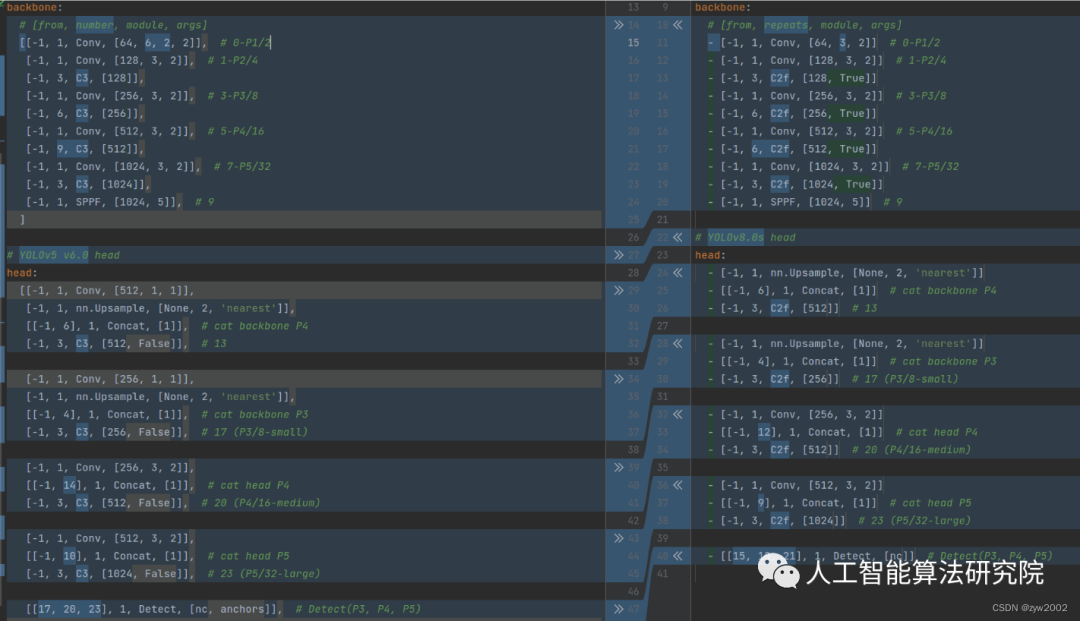
2.模型結構
Section Name
如下圖, 左側為 YOLOv5-s,右側為 YOLOv8-s。
在暫時不考慮 Head 情況下,對比 YOLOv5 和 YOLOv8 的 yaml 配置文件可以發現改動較小。
01
Backbone和Neck的具體變化
a)第一個卷積層的 kernel 從 6x6 變成了 3x3
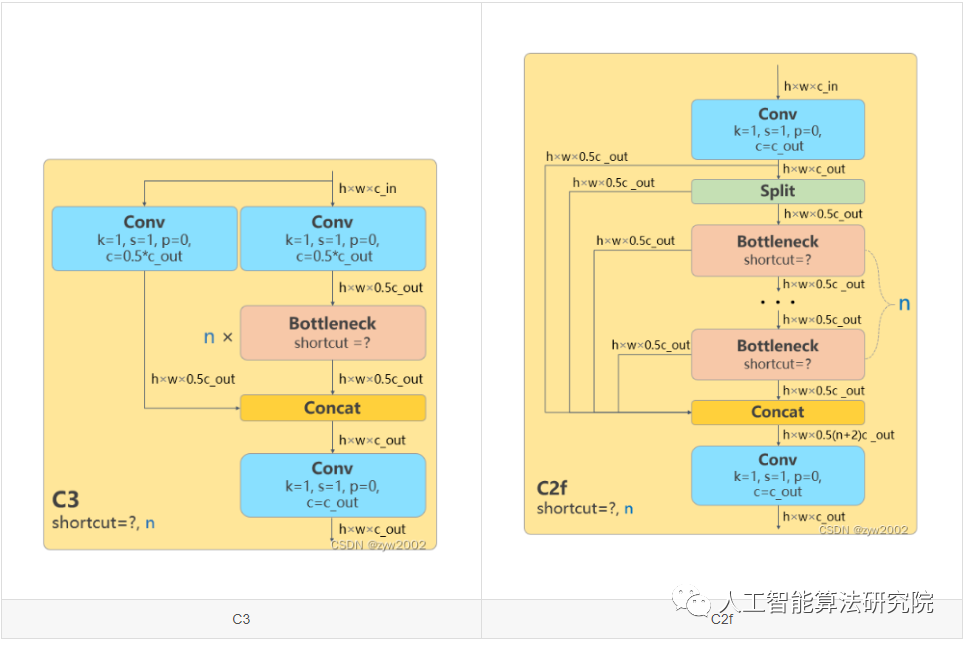
b)所有的 C3 模塊換成 C2f,結構如下所示,可以發現多了更多的跳層連接和額外的 Split 操作
c)去掉了 Neck 模塊中的 2 個卷積連接層
d) Backbone 中 C2f 的 block 數從 3-6-9-3 改成了 3-6-6-3
e) 查看 N/S/M/L/X 等不同大小模型,可以發現 N/S 和 L/X 兩組模型只是改了縮放系數,但是 S/M/L 等骨干網絡的通道數設置不一樣,沒有遵循同一套縮放系數。如此設計的原因應該是同一套縮放系數下的通道設置不是最優設計,YOLOv7 網絡設計時也沒有遵循一套縮放系數作用于所有模型
02
Head的具體變化
從原先的耦合頭變成了解耦頭,并且從 YOLOv5 的 Anchor-Based 變成了 Anchor-Free。
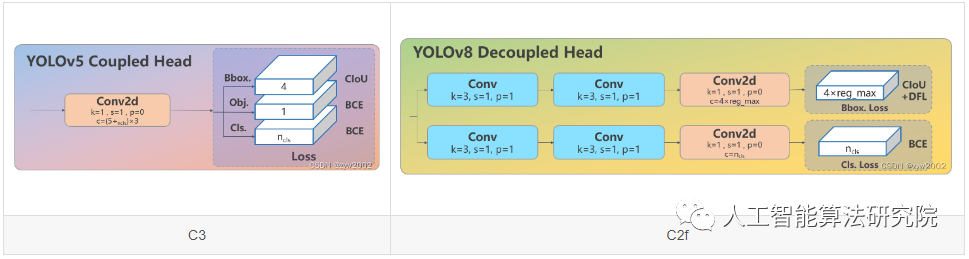
從上圖可以看出,不再有之前的 objectness 分支,只有解耦的分類和回歸分支,并且其回歸分支使用了 Distribution Focal Loss 中提出的積分形式表示法。
3.Loss 計算
Section Name
Loss 計算過程包括 2 個部分:正負樣本分配策略和 Loss 計算。
01
正負樣本分配策略
現代目標檢測器大部分都會在正負樣本分配策略上面做文章,典型的如 YOLOX 的 simOTA、TOOD 的 TaskAlignedAssigner 和 RTMDet 的 DynamicSoftLabelAssigner,這類 Assigner 大都是動態分配策略,而 YOLOv5 采用的依然是靜態分配策略。考慮到動態分配策略的優異性,YOLOv8 算法中則直接引用了 TOOD 的 TaskAlignedAssigner。
TaskAlignedAssigner 的匹配策略簡單總結為:根據分類與回歸的分數加權的分數選擇正樣本。
02
Loss計算
Loss 計算包括 2 個分支:分類和回歸分支,沒有了之前的 objectness 分支。
分類分支依然采用 BCE Loss。回歸分支需要和 Distribution Focal Loss 中提出的積分形式表示法綁定,因此使用了 Distribution Focal Loss, 同時還使用了 CIoU Loss。3 個 Loss 采用一定權重比例加權即可。
4.訓練數據增強
Section Name
數據增強方面和 YOLOv5 差距不大,只不過引入了 YOLOX 中提出的最后 10 個 epoch 關閉 Mosaic 的操作。假設訓練 epoch 是 500,其示意圖如下所示:
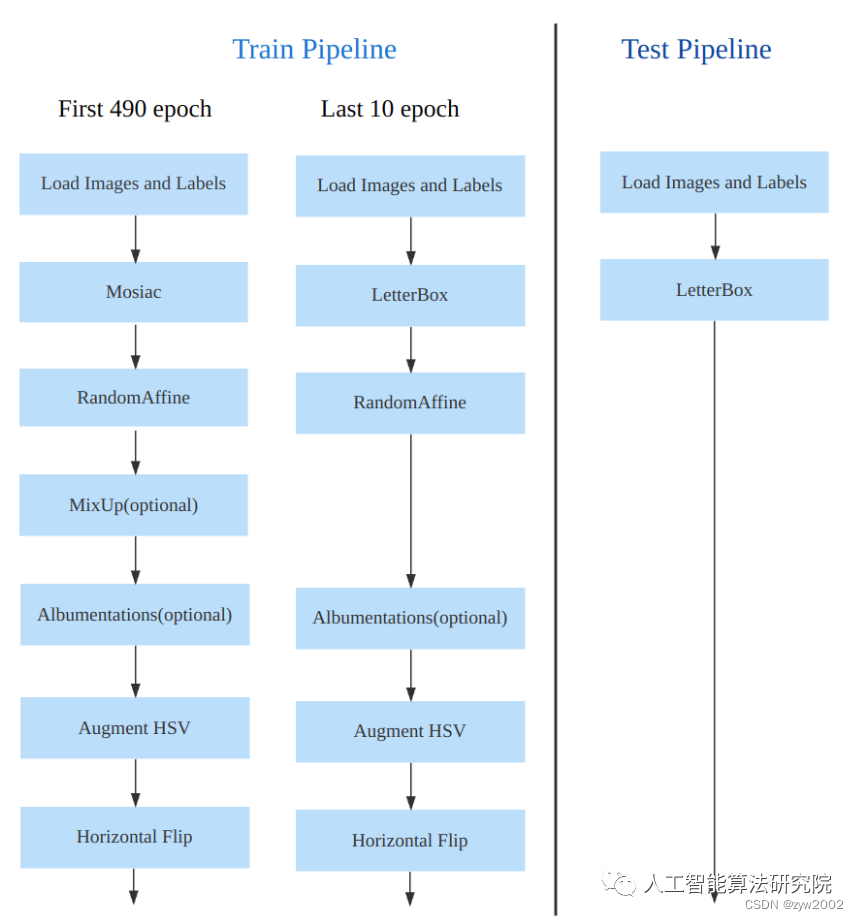
考慮到不同模型應該采用的數據增強強度不一樣,因此對于不同大小模型,有部分超參會進行修改,典型的如大模型會開啟 MixUp 和 CopyPaste。數據增強后典型效果如下所示:

5.訓練策略
Section Name
YOLOv8 的訓練策略和 YOLOv5 沒有啥區別,最大區別就是模型的訓練總 epoch 數從 300 提升到了 500,這也導致訓練時間急劇增加。以 YOLOv8-S 為例,其訓練策略匯總如下:

6.模型推理過程
Section Name
YOLOv8 的推理過程和 YOLOv5 幾乎一樣,唯一差別在于前面需要對 Distribution Focal Loss 中的積分表示 bbox 形式進行解碼,變成常規的 4 維度 bbox,后續計算過程就和 YOLOv5 一樣了。
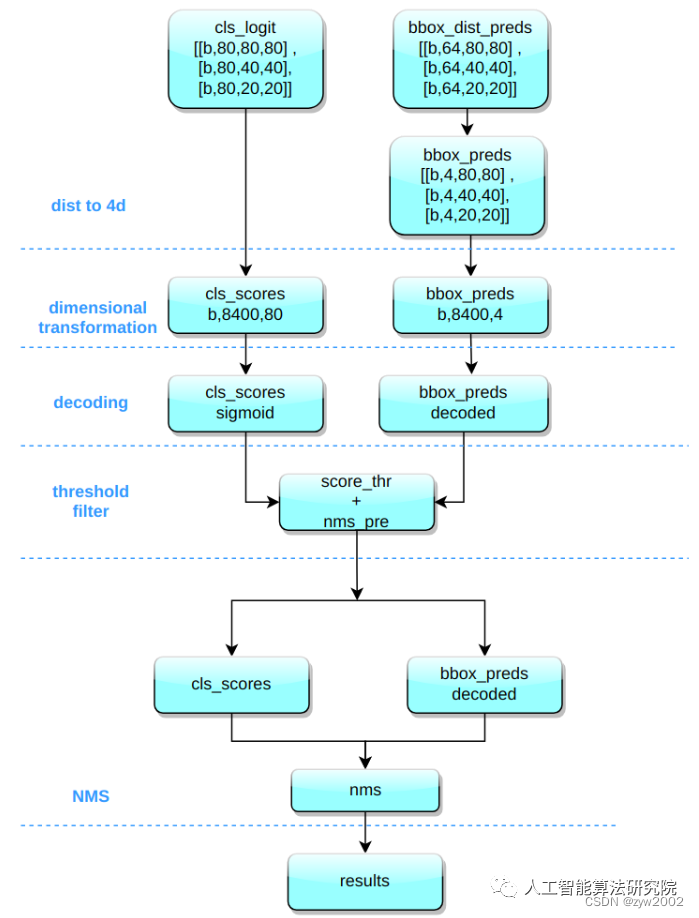
其推理和后處理過程為:
(1) bbox 積分形式轉換為 4d bbox 格式
對 Head 輸出的 bbox 分支進行轉換,利用 Softmax 和 Conv 計算將積分形式轉換為 4 維 bbox 格式
(2) 維度變換
YOLOv8 輸出特征圖尺度為 80x80、40x40 和 20x20 的三個特征圖。Head 部分輸出分類和回歸共 6 個尺度的特征圖。將 3 個不同尺度的類別預測分支、bbox 預測分支進行拼接,并進行維度變換。為了后續方便處理,會將原先的通道維度置換到最后,類別預測分支 和 bbox 預測分支 shape 分別為 (b, 80x80+40x40+20x20, 80)=(b,8400,80),(b,8400,4)。
(3) 解碼還原到原圖尺度
分類預測分支進行 Sigmoid 計算,而 bbox 預測分支需要進行解碼,還原為真實的原圖解碼后 xyxy 格式。
(4) 閾值過濾
遍歷 batch 中的每張圖,采用 score_thr 進行閾值過濾。在這過程中還需要考慮 multi_label 和 nms_pre,確保過濾后的檢測框數目不會多于 nms_pre。
(5) 還原到原圖尺度和 nms
基于前處理過程,將剩下的檢測框還原到網絡輸出前的原圖尺度,然后進行 nms 即可。最終輸出的檢測框不能多于 max_per_img。
有一個特別注意的點:YOLOv5 中采用的 Batch shape 推理策略,在 YOLOv8 推理中暫時沒有開啟,不清楚后面是否會開啟,在 MMYOLO 中快速測試了下,如果開啟 Batch shape 會漲大概 0.1~0.2。
7.網絡模型解析
Section Name
01
卷積神經單元(model.py)
在ultralytics/nn/modules.py文件中定義了yolov8網絡中的卷積神經單元。
01
autopad
功能:返回pad的大小,使得padding后輸出張量的大小不變。
參數:
k: 卷積核(kernel)的大小。類型可能是一個int也可能是一個序列。
p: 填充(padding)的大小。默認為None。
d: 擴張率(dilation rate)的大小, 默認為1 。普通卷積的擴張率為1,空洞卷積的擴張率大于1。
假設k為原始卷積核大小,d為卷積擴張率(dilation rate),加入空洞之后的實際卷積核尺寸與原始卷積核尺寸之間的關系:k =d(k-1)+1

def autopad(k, p=None, d=1): # kernel(卷積核), padding(填充), dilation(擴張)
# 返回pad的大小,使得padding后輸出張量的shape不變
if d > 1: # 如果采用擴張卷積,則計算擴張后實際的kernel大小
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] #
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # 自動pad
returnp
02
Conv
-
功能:標準的卷積
-
參數:輸入通道數(
c1), 輸出通道數(c2), 卷積核大小(k,默認是1), 步長(s,默認是1), 填充(p,默認為None), 組(g, 默認為1), 擴張率(d,默認為1), 是否采用激活函數(act,默認為True, 且采用SiLU為激活函數)
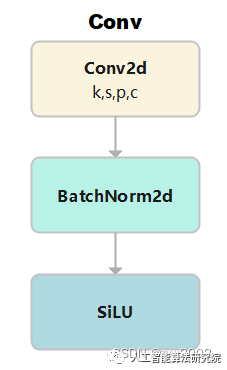
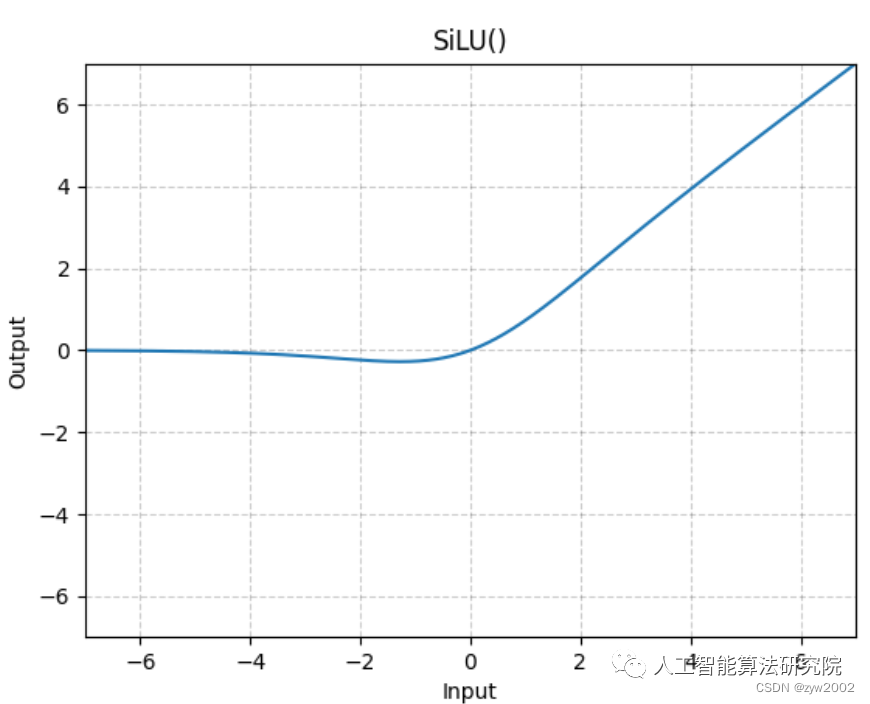
激活函數采用的是SiLU。
class Conv(nn.Module):
# 標準的卷積 參數(輸入通道數, 輸出通道數, 卷積核大小, 步長, 填充, 組, 擴張, 激活函數)
default_act = nn.SiLU() # 默認的激活函數
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False) # 2維卷積,其中采用了自動填充函數。
self.bn = nn.BatchNorm2d(c2) # 使得每一個batch的特征圖均滿足均值為0,方差為1的分布規律
# 如果act=True 則采用默認的激活函數SiLU;如果act的類型是nn.Module,則采用傳入的act; 否則不采取任何動作 (nn.Identity函數相當于f(x)=x,只用做占位,返回原始的輸入)。
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x): # 前向傳播
return self.act(self.bn(self.conv(x))) # 采用BatchNorm
def forward_fuse(self, x): # 用于Model類的fuse函數融合 Conv + BN 加速推理,一般用于測試/驗證階段
returnself.act(self.conv(x))#不采用BatchNorm
03
DWConv
深度可分離卷積,繼承自Conv。g=math.gcd(c1, c2)分組數是輸入通道(c1)和輸出通道(c2)的最大公約數。(因為分組卷積時,分組數需要能夠整除輸入通道和輸出通道)
class DWConv(Conv):
# 深度可分離卷積
def __init__(self, c1, c2, k=1, s=1, d=1, act=True): # ch_in, ch_out, kernel, stride, dilation, activation
super().__init__(c1,c2,k,s,g=math.gcd(c1,c2),d=d,act=act)
04
DWConvTranspose2d
帶有深度分離的轉置卷積,繼承自nn.ConvTranspose2dgroups=math.gcd(c1, c2)分組數是輸入通道(c1)和輸出通道(c2)的最大公約數。(因為分組卷積時,分組數需要能夠整除輸入通道和輸出通道)
class DWConvTranspose2d(nn.ConvTranspose2d):
# Depth-wise transpose convolution
def __init__(self, c1, c2, k=1, s=1, p1=0, p2=0): # 輸入通道, 輸出通道, 卷積核大小, 步長, padding, padding_out
super().__init__(c1,c2,k,s,p1,p2,groups=math.gcd(c1,c2))
05
ConvTranspose
和Conv類似,只是把Conv2d換成了ConvTranspose2d。
class ConvTranspose(nn.Module):
# Convolution transpose 2d layer
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=2, s=2, p=0, bn=True, act=True):
super().__init__()
self.conv_transpose = nn.ConvTranspose2d(c1, c2, k, s, p, bias=not bn)
self.bn = nn.BatchNorm2d(c2) if bn else nn.Identity()
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
returnself.act(self.bn(self.conv_transpose(x)))
06
DFL(Distribution Focal Loss)
本篇文章(https://ieeexplore.ieee.org/document/9792391)提出了GFL(了Generalized Focal Loss)。GFL具體又包括Quality Focal Loss(QFL)和Distribution Focal Loss(DFL),其中QFL用于優化分類和質量估計聯合分支,DFL用于優化邊框分支。
class DFL(nn.Module):
# Integral module of Distribution Focal Loss (DFL) proposed in Generalized Focal Loss
def __init__(self, c1=16):
super().__init__()
self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)
x = torch.arange(c1, dtype=torch.float)
self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1))
self.c1 = c1
def forward(self, x):
b, c, a = x.shape # batch, channels, anchors
return self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a)
# return self.conv(x.view(b, self.c1, 4, a).softmax(1)).view(b, 4, a)
07
TransformerLayer

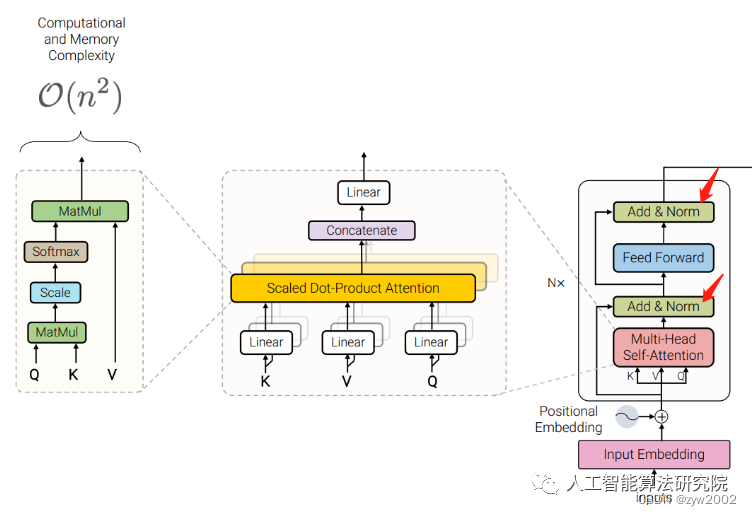
我們可以發現它和yolo中的TransformerLayer部分只是少了層規范化(LayerNorm),以及在Feed-Forward Networks 中只采用了兩個不帶偏置線性層,且沒有采用激活函數。
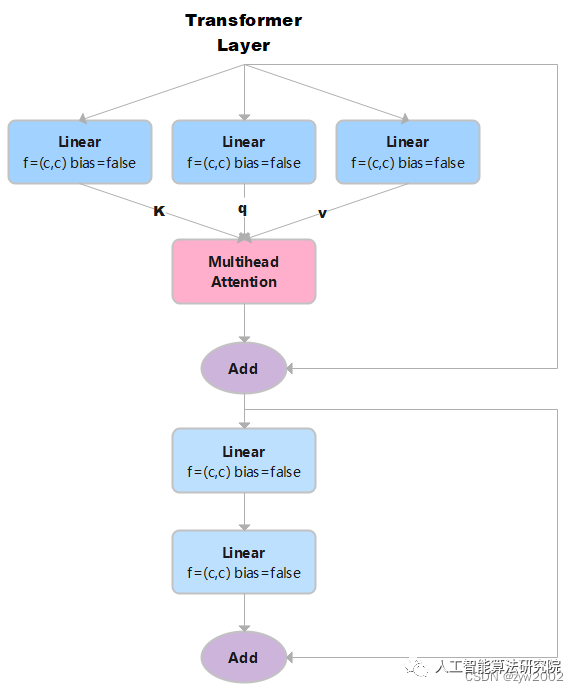
TransformerLayer代碼實現如下:
class TransformerLayer(nn.Module):
# Transformer layer (LayerNorm layers removed for better performance)
def __init__(self, c, num_heads): # c: 詞特征向量的大小 num_heads 檢測頭的個數。
super().__init__()
self.q = nn.Linear(c, c, bias=False)# 計算query, in_features=out_features=c
self.k = nn.Linear(c, c, bias=False)# 計算key
self.v = nn.Linear(c, c, bias=False)# 計算value
self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads) # 多頭注意力機制
self.fc1 = nn.Linear(c, c, bias=False)
self.fc2 = nn.Linear(c, c, bias=False)
def forward(self, x):
x = self.ma(self.q(x), self.k(x), self.v(x))[0] + x # 多頭注意力機制+殘差連接
x = self.fc2(self.fc1(x)) + x # 兩個全連接層+ 殘差連接
returnx
如果輸入是x,x的大小是(s,n,c) 。其中n是batch size, s是源序列長度,c是詞特征向量的大小(embed_dim)。
然后x分別通過3個Linear層 (線性層的結構相同,但是可學習參數不同)計算得到鍵k、查詢q、值v。因為線性層的輸入特征數和輸出特征數均等于c, 所以k,q,v的大小也是(s,n,c)。
接著,把k、q、v作為參數輸入到多頭注意力ma中,返回兩個結果attn_output(注意力機制的輸出)和attn_output_weights(注意力機制的權重)。在這里,我們只需要注意力機制的輸出就可以,因此,我們取索引0 self.ma(self.q(x), self.k(x), self.v(x))[0],它的大小是(s,n,c)。+x 表示殘差連接,不改變x的形狀。
self.fc2(self.fc1(x)) 表示經過兩個全連接層,輸出大小是(s,n,c)。+x 表示殘差連接,不改變x的形狀。因此最終輸出的形狀大小和輸入的形狀一樣。
08
Transformer Block
TransformerBlock是把若干個TransformerLayer串聯起來。
對于圖像數據而言,輸入數據形狀是 [batch, channel, height, width],變換成 [height × width, batch, channel]。height × width把圖像中各個像素點看作一個單詞,其對應通道的信息連在一起就是詞向量。channel就是詞向量的長度。
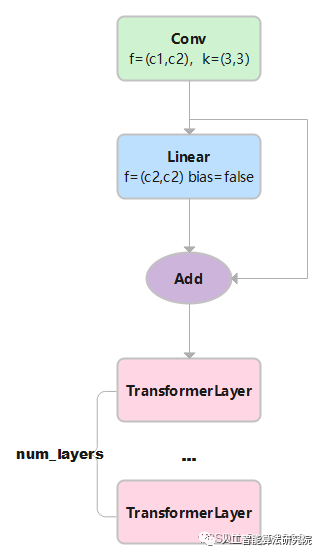
TransformerBlock的實現代碼如下:
class TransformerBlock(nn.Module):
def __init__(self, c1, c2, num_heads, num_layers):
super().__init__()
self.conv = None
if c1 != c2:
self.conv = Conv(c1, c2)
self.linear = nn.Linear(c2, c2) # learnable position embedding
self.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers)))
self.c2 = c2
def forward(self, x): # x:(b,c1,w0,h0)
if self.conv is not None:
x = self.conv(x) # x:(b,c2,w,h)
b, _, w, h = x.shape
p = x.flatten(2).permute(2, 0, 1) # flatten后:(b,c2,w*h) p: (w*h,b,c2)
# linear后: (w*h,b,c2) tr后: (w*h,b,c2) permute后: (b,c2,w*h) reshape后:(b,c2,w,h)
returnself.tr(p+self.linear(p)).permute(1,2,0).reshape(b,self.c2,w,h)
1)輸入的x大小為(b,c1,w,h)。其中b為batch size, c1 是輸入通道數大小, w 和h 分別表示圖像的寬和高。
2)經過Conv層:Conv層中的2d卷積,卷積核大小是1x1, 步長為1,無填充,擴張率為1。因此不改變w和h, 只改變輸出通道數,形狀變為(b,c2,w,h)。Conv層中的BN和SiLU不改變形狀大小。輸出的x大小為(b,c2,w,h)
3)對x進行變換得到p: x.flatten(2)后,大小變為 (b,c2,w*h) permute(2, 0, 1)后,p的大小為(w*h,b,c2)
4) 將p輸入到線性層后,因為線性層的輸入特征數和輸出特征數相等,因此輸出的大小為(w*h,b,c2)。
+p 進行殘差連接后,大小不變,仍為(w*h,b,c2)
5) 然后將上一步的結果輸入到num_layers個TransformerLayer中。w*h 相當于序列長度,b是批量的大小,c2相當于詞嵌入特征長度。每個TransformerLayer的輸入和輸出的大小不變。經過若干個TransformerLayer后,大小是(w*h,b,c2)。
6)permute(1, 2, 0)后: 形狀變為(b,c2,w*h) reshape(b, self.c2, w, h)后:(b,c2,w,h)
09
Bottleneck
先使用 3x3 卷積降維,剔除冗余信息;再使用 3×3 卷積升維。
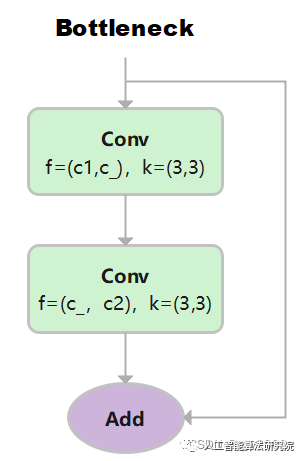
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expand
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1) # 輸入通道: c1, 輸出通道:c_ , 卷積核:3x3, 步長1
self.cv2 = Conv(c_, c2, k[1], 1, g=g) # 輸入通道:c_ , 輸出通道c2, 卷積核:3x3, 步長1
self.add = shortcut and c1 == c2 # 當傳入的shortcut參數為true,且c1和c2相等時,則使用殘差連接。
def forward(self, x):
returnx+self.cv2(self.cv1(x))ifself.addelseself.cv2(self.cv1(x))
第一層卷積,輸入通道: c1, 輸出通道:c_ , 卷積核:3x3, 步長1
第一層卷積,輸入通道: c_, 輸出通道:c2 , 卷積核:3x3, 步長1
其中c _ = c2/2。當c1和c2相等時,采用殘差連接。
10
BottleneckCSP
詳細請參考CSPNet的論文和源碼。論文《CSPNet: A New Backbone that can Enhance Learning Capability of CNN》
源碼https://github.com/WongKinYiu/CrossStagePartialNetworks
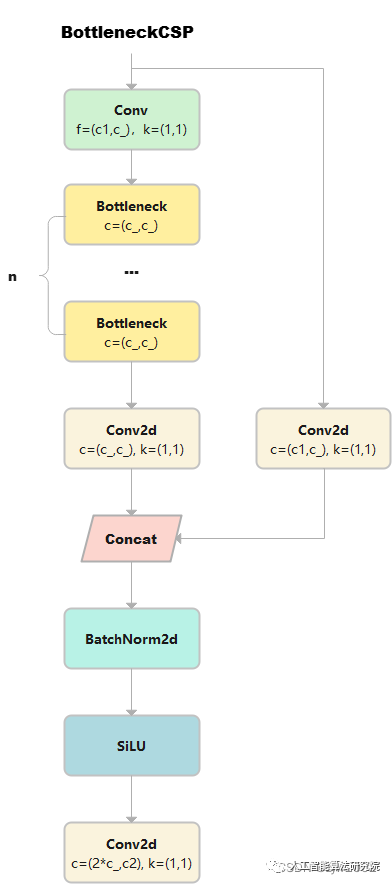
class BottleneckCSP(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
# 輸出x的大小是(b,c1,w,h)
self.cv1 = Conv(c1, c_, 1, 1) # cv1的大小為(b,c_,w,h)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False) # cv2的大小為(b,c_,w,h)
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False) # m通過Conv2d,變成cv3,大小是(b,c_,w,h)
self.cv4 = Conv(2 * c_, c2, 1, 1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.SiLU()
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
# cv1通過n個串聯的bottleneck,變成m,大小為(b,c_,w,h)
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x))) # (b,c_,w,h)
y2 = self.cv2(x) # (b,c_,w,h)
return self.cv4(self.act(self.bn(torch.cat((y1, y2), 1))))
# cat后:(b,2*c_,w,h) 返回cv4: (b,c2,w,h)
1)輸出x的大小是(b,c1,w,h), 然后有兩條計算路徑分別計算得到y1和y2。
y1的計算路徑:先x通過cv1,大小變成(b,c_,w,h) 。cv1通過n個串聯的bottleneck,變成m,大小為(b,c_,w,h)。m通過cv3, 得到y1, 大小是(b,c_,w,h)
y2的計算路徑:x通過cv2得到y2,大小是(b,c_,w,h)
2)y1和y2在dim=1處連接, 大小是(b,2*c_,w,h), 然后再通過BN和SiLU,大小不變。
3)最終,通過cv4, 返回結果的大小是(b,c2,w,h)
11
C3
與 BottleneckCSP 類似,但少了 1 個 Conv、1 個 BN、1 個 Act,運算量更少。總共只有3次卷積(cv1,cv2,cv3)。
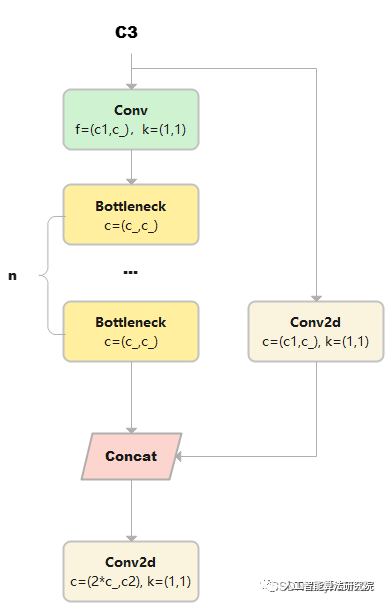
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
returnself.cv3(torch.cat((self.m(self.cv1(x)),self.cv2(x)),1))
12
C2
C2只有兩個卷積(cv1,cv2)的CSP Bottleneck。
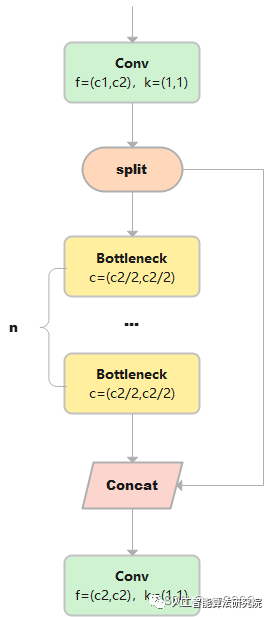
class C2(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
# 假設輸入的x大小是(b,c1,w,h)
self.c = int(c2 * e) # hidden channels e=0.5,對輸出通道進行平分。
self.cv1 = Conv(c1, 2 * self.c, 1, 1) # cv1的大小是(b,c2,w,h)
self.cv2 = Conv(2 * self.c, c2, 1) # optional act=FReLU(c2)
# self.attention = ChannelAttention(2 * self.c) # or SpatialAttention() #此處可以使用空間注意力或者跨通道的注意力機制。
self.m = nn.Sequential(*(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))) # a通過n個串聯的Bottleneck后的到m,m的大小是(b,c,w,h)
def forward(self, x):
a, b = self.cv1(x).split((self.c, self.c), 1)# 對cv進行在維度1進行平分,a和b的大小都是(b,c,w,h)
returnself.cv2(torch.cat((self.m(a),b),1))#把m和b在維度1進行cat后,大小是(b,c2,w,h)。最終通過cv2,大小是(b,c2,w,h)
1)輸出x的大小是(b,c1,w,h), 通過Conv層,得到cv1, cv1的大小是(b,c2,w,h)
2) 然后再dim=1的維度上對cv1進行分割,a和b的大小都是(b,c2/2,w,h)。
3) a通過n個串聯的Bottleneck后的到m,m的大小是(b,c,w,h)
4) 把m和b在維度1進行cat后,大小是(b,c2,w,h)。最終m通過cv2,輸出的大小是(b,c2,w,h)
13
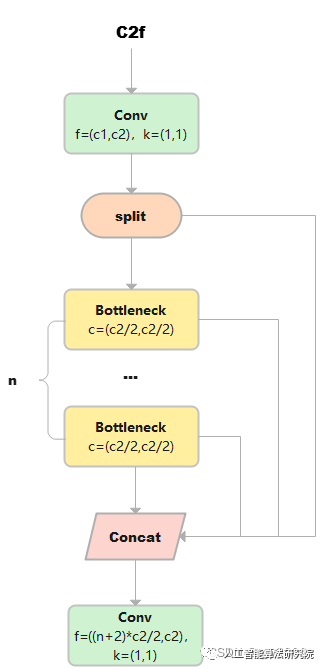
C2f
C2f與C2相比,每個Bottleneck的輸出都會被Concat到一起。
class C2f(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
# 假設輸入的x大小是(b,c1,w,h)
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1) # cv1的大小是(b,c2,w,h)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n)) # n個Bottleneck組成的ModuleList,可以把m看做是一個可迭代對象
def forward(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
# cv1的大小是(b,c2,w,h),對cv1在維度1等分成兩份(假設分別是a和b),a和b的大小均是(b,c2/2,w,h)。此時y=[a,b]。
y.extend(m(y[-1]) for m in self.m)
# 然后對列表y中的最后一個張量b輸入到ModuleList中的第1個bottleneck里,得到c,c的大小是(b,c2/2,w,h)。然后把c也加入y中。此時y=[a,b,c]
# 重復上述操作n次(因為是n個bottleneck),最終得到的y列表中一共有n+2個元素。
return self.cv2(torch.cat(y, 1))
# 對列表y中的張量在維度1進行連接,得到的張量大小是(b,(n+2)*c2/2,w,h)。
#最終通過cv2,輸出張量的大小是(b,c2,w,h)
1)cv1的大小是(b,c2,w,h),對cv1在維度1等分成兩份(假設分別是a和b),a和b的大小均是(b,c2/2,w,h)。此時y=[a,b]。
2)然后對列表y中的最后一個張量b輸入到ModuleList中的第1個bottleneck里,得到c,c的大小是(b,c2/2,w,h)。然后把c也加入y中。此時y=[a,b,c]。
3)上述步驟重復上述操作n次(因為是n個bottleneck),最終得到的y列表中一共有n+2個元素。
4)對列表y中的張量在維度1進行連接,得到的張量大小是(b,(n+2)*c2/2,w,h)。
5)最終通過cv2,輸出張量的大小是(b,c2,w,h)
14
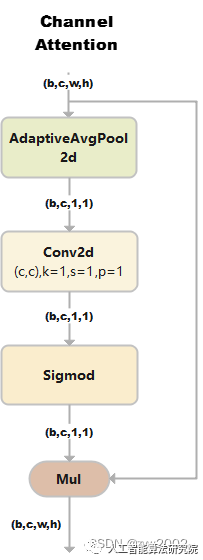
ChannelAttention
通道注意力模型: 通道維度不變,壓縮空間維度。該模塊關注輸入圖片中有意義的信息。
class ChannelAttention(nn.Module):
# Channel-attention module https://github.com/open-mmlab/mmdetection/tree/v3.0.0rc1/configs/rtmdet
def __init__(self, channels: int) -> None:
super().__init__()
self.pool = nn.AdaptiveAvgPool2d(1) # 自適應平均池化后,大小為(b,c,1,1)
self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True)
self.act = nn.Sigmoid()
def forward(self, x: torch.Tensor) -> torch.Tensor:
returnx*self.act(self.fc(self.pool(x)))
1)假設輸入的數據大小是(b,c,w,h)
2)通過自適應平均池化使得輸出的大小變為(b,c,1,1)
3)通過2d卷積和sigmod激活函數后,大小是(b,c,1,1)
4)將上一步輸出的結果和輸入的數據相乘,輸出數據大小是(b,c,w,h)。
15
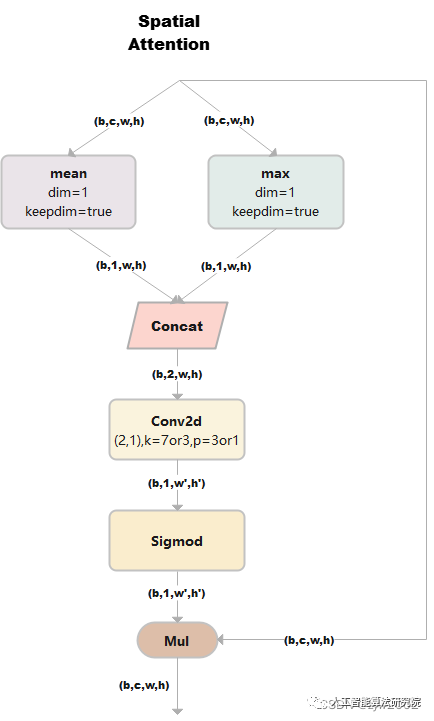
SpatialAttention
空間注意力模塊:空間維度不變,壓縮通道維度。該模塊關注的是目標的位置信息。
class SpatialAttention(nn.Module):
# Spatial-attention module
def __init__(self, kernel_size=7):
super().__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7' # kernel size 的大小必須是3或者7
padding = 3 if kernel_size == 7 else 1 # 當kernel_size是7時,padding=3; 當kernel_size是3時,padding=1
self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.act = nn.Sigmoid()
def forward(self, x):
returnx*self.act(self.cv1(torch.cat([torch.mean(x,1,keepdim=True),torch.max(x,1,keepdim=True)[0]],1)))
1) 假設輸入的數據x是(b,c,w,h),并進行兩路處理。
2)其中一路在通道維度上進行求平均值,得到的大小是(b,1,w,h);另外一路也在通道維度上進行求最大值,得到的大小是(b,1,w,h)。
3) 然后對上述步驟的兩路輸出進行連接,輸出的大小是(b,2,w,h)
4)經過一個二維卷積網絡,把輸出通道變為1,輸出大小是(b,1,w,h)
4)將上一步輸出的結果和輸入的數據x相乘,最終輸出數據大小是(b,c,w,h)。
16
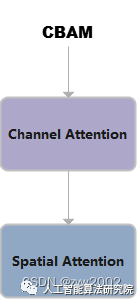
CBAM
CBAM就是把ChannelAttention和SpatialAttention串聯在一起。
class CBAM(nn.Module):
# Convolutional Block Attention Module
def __init__(self, c1, kernel_size=7): # ch_in, kernels
super().__init__()
self.channel_attention = ChannelAttention(c1)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
return self.spatial_attention(self.channel_attention(x))
17
C1
總共只有3次卷積(cv1,cv2,cv3)的Bottleneck。
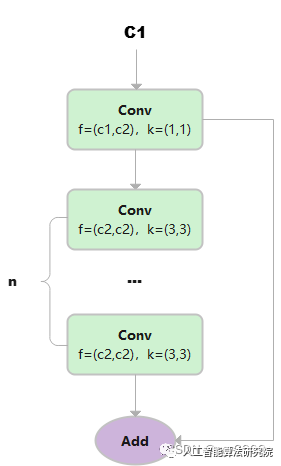
class C1(nn.Module):
# CSP Bottleneck with 1 convolution
def __init__(self, c1, c2, n=1): # ch_in, ch_out, number
super().__init__()
self.cv1 = Conv(c1, c2, 1, 1)
self.m = nn.Sequential(*(Conv(c2, c2, 3) for _ in range(n)))
def forward(self, x):
y = self.cv1(x)
returnself.m(y)+y
1)假設輸入的數據是(b,c1,w,h)
2) 首先通過一個Conv塊,得到y, 大小為(b,c2,w,h)
3) 然后讓y通過n個3x3的Conv塊,得到m
4) 最后讓m和y相加。
18
C3x
C3x 繼承自C3, 變換是Bottleneck中的卷積核大小變為(1,3)和(3,3)
class C3x(C3):
# C3 module with cross-convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
self.c_ = int(c2 * e)
self.m=nn.Sequential(*(Bottleneck(self.c_,self.c_,shortcut,g,k=((1,3),(3,1)),e=1)for_inrange(n)))
19
C3TR
C3TR繼承自C3, n 個 Bottleneck 更換為 1 個 TransformerBlock。
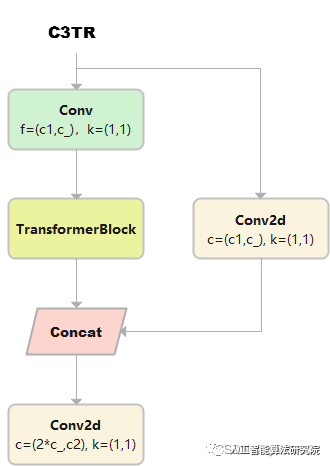
class C3TR(C3):
# C3 module with TransformerBlock()
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e)
self.m = TransformerBlock(c_, c_, 4, n)# num_heads=4, num_layers=n
20
SPP
《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
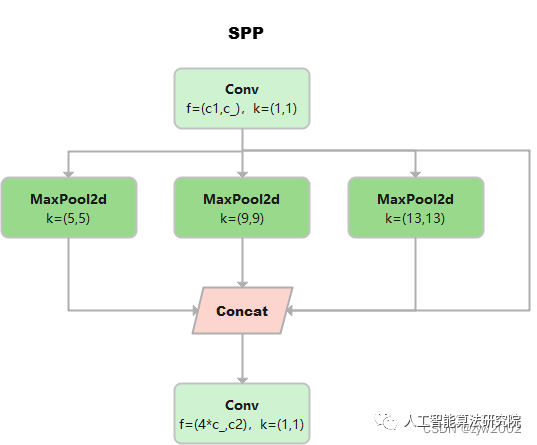
class SPP(nn.Module):
# Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
def __init__(self, c1, c2, k=(5, 9, 13)):
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
returnself.cv2(torch.cat([x]+[m(x)forminself.m],1))
21
SPPF
這個是YOLOv5作者Glenn Jocher基于SPP提出的,速度較SPP快很多,所以叫SPP-Fast。
三個MaxPool 串行連接,kerner size都是5*5。效果等價于SPP,但是運算量從原來的5^2 + 9^2 + 13^2 = 275減少到3* 5^2 =75
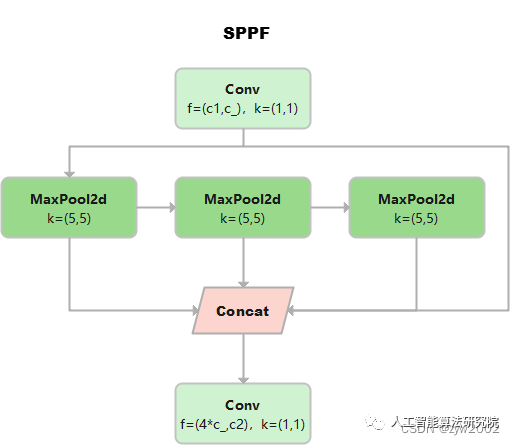
池化尺寸等價于SPP中kernel size分別為5 * 5,9 * 9和13 * 13的池化層并行連接。
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
returnself.cv2(torch.cat((x,y1,y2,self.m(y2)),1))
22
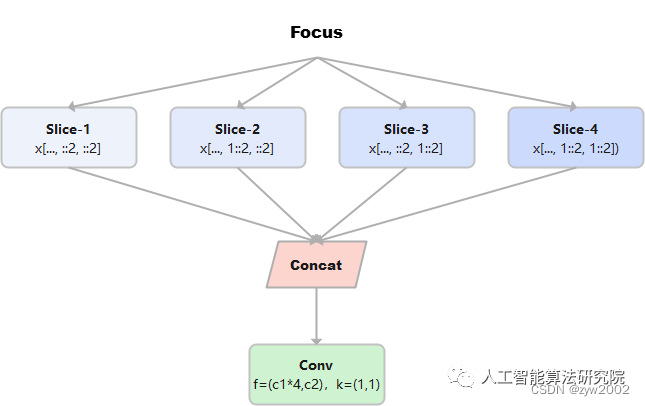
Focus
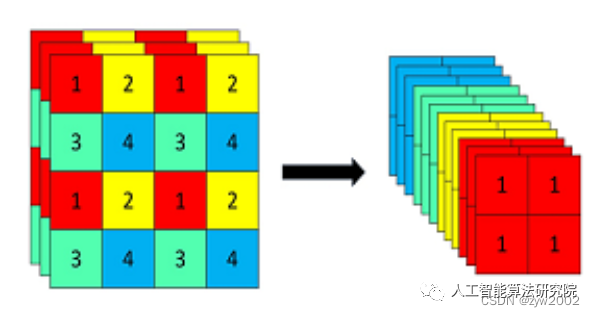
Focus模塊在v5中是圖片進入backbone前,對圖片進行切片操作,具體操作是在一張圖片中每隔一個像素拿到一個值,類似于鄰近下采樣,這樣就拿到了四張圖片,四張圖片互補,長的差不多,但是沒有信息丟失,這樣一來,將W、H信息就集中到了通道空間,輸入通道擴充了4倍,即拼接起來的圖片相對于原先的RGB三通道模式變成了12個通道,最后將得到的新圖片再經過卷積操作,最終得到了沒有信息丟失情況下的二倍下采樣特征圖。
例如:原始的640 × 640 × 3的圖像輸入Focus結構,采用切片操作,先變成320 × 320 × 12的特征圖,再經過一次卷積操作,最終變成320 × 320 × 32的特征圖。切片操作如下
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act=act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat((x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]), 1))
#returnself.conv(self.contract(x))
23
GhostConv
Ghost卷積來自華為諾亞方舟實驗室,《GhostNet: More Features from Cheap Operations》發表于2020年的CVPR上。提供了一個全新的Ghost模塊,旨在通過廉價操作生成更多的特征圖。
原理如下圖所示:
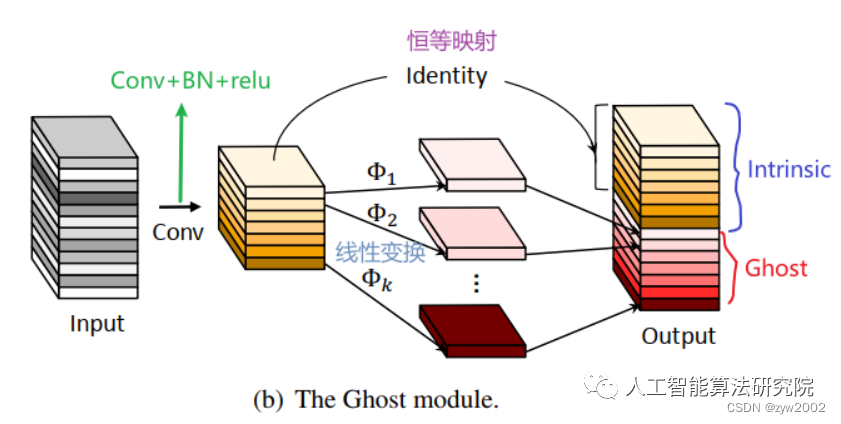
Ghost Module分為兩步操作來獲得與普通卷積一樣數量的特征圖:
Step1:少量卷積(比如正常用128個卷積核,這里就用64個,從而減少一半的計算量);
Step2:cheap operations,用圖中的Φ表示,Φ是諸如33、55的卷積,并且是逐個特征圖的進行卷積(Depth-wise convolutional,深度卷積)。
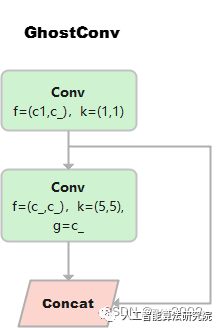
class GhostConv(nn.Module):
# Ghost Convolution https://github.com/huawei-noah/ghostnet
def __init__(self, c1, c2, k=1, s=1, g=1, act=True): # ch_in, ch_out, kernel, stride, groups
super().__init__()
c_ = c2 // 2 # hidden channels
self.cv1 = Conv(c1, c_, k, s, None, g, act=act)
self.cv2 = Conv(c_, c_, 5, 1, None, c_, act=act) # 分組數=c_=通道數,進行point-wise的深度分離卷積
def forward(self, x):
y = self.cv1(x)
returntorch.cat((y,self.cv2(y)),1)
24
GhostBottleneck
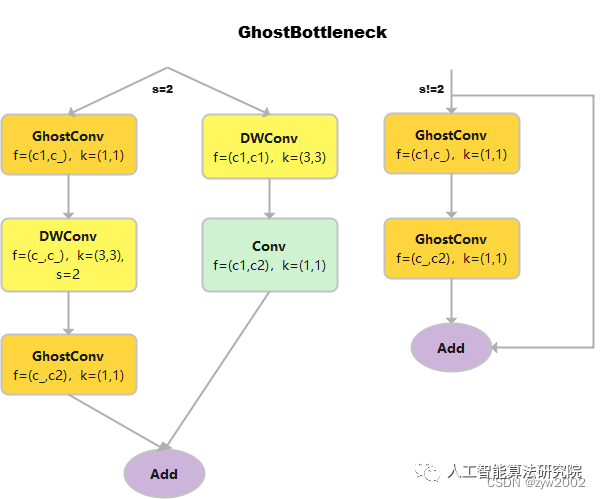
class GhostBottleneck(nn.Module):
# Ghost Bottleneck https://github.com/huawei-noah/ghostnet
def __init__(self, c1, c2, k=3, s=1): # ch_in, ch_out, kernel, stride
super().__init__()
c_ = c2 // 2
self.conv = nn.Sequential(
GhostConv(c1, c_, 1, 1), # 卷積核的大小是1*1,屬于point-wise的深度可分離卷積
DWConv(c_, c_, k, s, act=False) if s == 2 else nn.Identity(), # 輸入通道數和輸出通道數相等,屬于depth-wise的深度可分離卷積
GhostConv(c_, c2, 1, 1, act=False)) #point-wise的深度可分離卷積,且不采用偏置項。
self.shortcut = nn.Sequential(DWConv(c1, c1, k, s, act=False), Conv(c1, c2, 1, 1,
act=False)) if s == 2 else nn.Identity()
def forward(self, x):
returnself.conv(x)+self.shortcut(x)
25
C3Ghost
C3Ghost繼承自C3, Bottleneck更換為GhostBottleneck
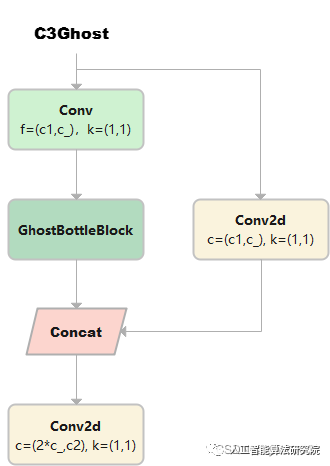
class C3Ghost(C3):
# C3 module with GhostBottleneck()
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
self.m=nn.Sequential(*(GhostBottleneck(c_,c_)for_inrange(n)))
26
Concat
當dimension=1時,將多張相同尺寸的圖像在通道維度維度上進行拼接。
class Concat(nn.Module):
# Concatenate a list of tensors along dimension
def __init__(self, dimension=1):
super().__init__()
self.d = dimension
def forward(self, x):
returntorch.cat(x,self.d)
8.Yolov8實操
Section Name
01
下載工程并安裝ultralytics
git clone https://github.com/ultralytics/ultralytics
cd ultralytics
pipinstall-e.
02
數據集準備
數據集制作參考:YOLO格式數據集制作
# 訓練/驗證/測試 數據
train: /data/zyw/project/dataset/finalTrafficLightDataset/train/images
val: /data/zyw/project/dataset/finalTrafficLightDataset/val/images
test: /data/zyw/project/dataset/finalTrafficLightDataset/WPIDataset/images
# 類別個數
nc: 12
# 類別名稱
names:["greenCircle","yellowCircle","redCircle","greenLeft","yellowLeft","redLeft","greenRight","yellowRight","redRight","greenForward","yellowForward","redForward"]
03
模型的訓練/驗證/預測/驗證
01
使用CLI
如果你想對模型進行訓練、驗證或運行推斷,并且不需要對代碼進行任何修改,那么使用YOLO命令行接口是最簡單的入門方法。
YOLO命令行界面(command line interface, CLI) 方便在各種任務和版本上訓練、驗證或推斷模型。CLI不需要定制或代碼,可以使用yolo命令從終端運行所有任務。
(1)語法
yolo task=detect mode=train model=yolov8n.yaml args...
classify predict yolov8n-cls.yaml args...
segment val yolov8n-seg.yaml args...
=onnxargs...
(2)訓練示例
yolotask=detectmode=trainmodel=yolov8n.ptdata=coco128.yamldevice=0
(3)多GPU訓練示例
yolotask=detectmode=trainmodel=yolov8n.ptdata=coco128.yamldevice='0,1,2,3'
(4)重寫默認的配置參數
# 語法
yolo task= ... mode= ... arg=val
# 例子:進行10個epoch的檢測訓練,learning_rate為0.01
=detectmode=trainepochs=10lr0=0.01
(5)重寫默認配置文件
# 可以在當前工作目錄下創建一個默認配置文件的副本
yolo task=init
# 然后可以使用cfg=name.yaml命令來傳遞新的配置文件
=default.yaml
02
使用python
允許用戶在Python項目中輕松使用YOLOv8。它提供了加載和運行模型以及處理模型輸出的函數。該界面設計易于使用,以便用戶可以在他們的項目中快速實現目標檢測。
(1)訓練
方式1:從預訓練模型開始訓練
from ultralytics import YOLO
model = YOLO("yolov8n.pt") # pass any model type
model.train(epochs=5)
方式2:從頭開始訓練
from ultralytics import YOLO
model = YOLO("yolov8n.yaml")
model.train(data="coco128.yaml",epochs=5)
(2)驗證
訓練后驗證:
from ultralytics import YOLO
model = YOLO("yolov8n.yaml")
model.train(data="coco128.yaml", epochs=5)
model.val()#It'llautomaticallyevaluatethedatayoutrained.
單獨驗證:
from ultralytics import YOLO
model = YOLO("model.pt")
# 如果不設置數據的話,就使用model.pt中的data yaml文件
model.val()
# 或者直接設置需要驗證的數據。
model.val(data="coco128.yaml")
(3)預測
從源文件預測:
from ultralytics import YOLO
model = YOLO("model.pt")
model.predict(source="0") # accepts all formats - img/folder/vid.*(mp4/format). 0 for webcam
model.predict(source="folder",show=True)#Displaypreds.Acceptsallyolopredictarguments
返回結果:
from ultralytics import YOLO
model = YOLO("model.pt")
outputs = model.predict(source="0", return_outputs=True) # treat predict as a Python generator
for output in outputs:
# each output here is a dict.
# for detection
print(output["det"]) # np.ndarray, (N, 6), xyxy, score, cls
# for segmentation
print(output["det"]) # np.ndarray, (N, 6), xyxy, score, cls
print(output["segment"]) # List[np.ndarray] * N, bounding coordinates of masks
# for classify
print(output["prob"])#np.ndarray,(num_class,),clsprob
04
數據擴充
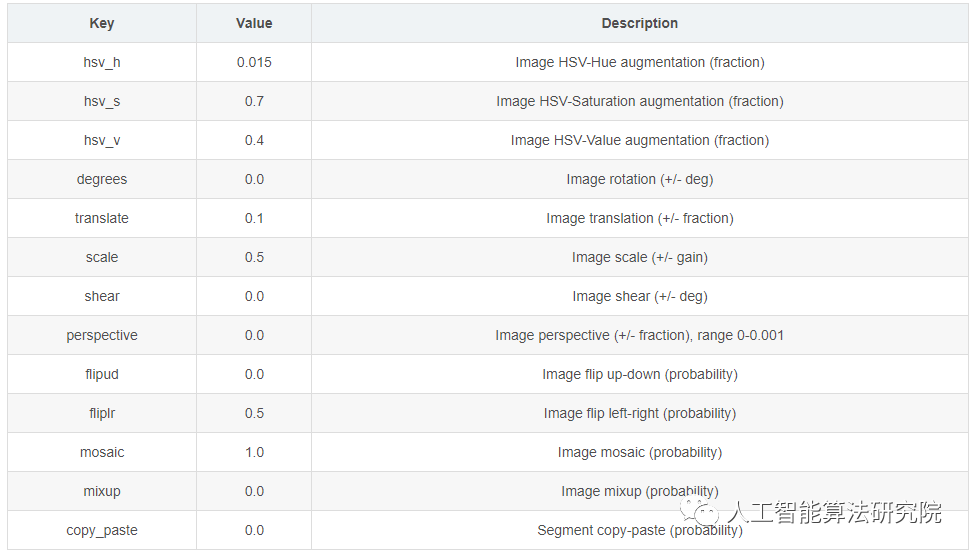
YOLO模型的增強設置是指應用于訓練數據的各種變換和修改,以增加數據集的多樣性和大小。這些設置會影響模型的性能、速度和精度。一些常見的YOLO增強設置包括應用的轉換類型和強度(例如隨機翻轉、旋轉、裁剪、顏色變化),應用每個轉換的概率,以及是否存在其他功能,如掩碼或每個框多個標簽。其他可能影響數據擴充過程的因素包括原始數據集的大小和組成,以及模型正在用于的特定任務。重要的是要仔細調整和實驗這些設置,以確保增強后的數據集具有足夠的多樣性和代表性,以訓練高性能的模型。
05
日志、檢查點、繪圖與文件管理
在訓練YOLO模型時,日志記錄、檢查點、繪圖和文件管理是重要的考慮因素。
日志記錄:在訓練期間記錄各種指標和統計數據通常有助于跟蹤模型的進展和診斷任何可能出現的問題。這可以通過使用日志庫(如TensorBoard)或將日志消息寫入文件來實現。
檢查點:在訓練期間,定期保存模型的檢查點是一個很好的做法。如果訓練過程被中斷,或者你想嘗試不同的訓練配置,這允許你從之前的點恢復訓練。繪圖:可視化模型的性能和訓練過程,有助于理解模型的行為方式和識別潛在問題。這可以使用matplotlib等繪圖庫完成,也可以使用TensorBoard等日志庫來繪圖。
文件管理:管理訓練過程中生成的各種文件,例如模型檢查點、日志文件和繪圖,可能具有挑戰性。有一個清晰和有組織的文件結構是很重要的,以便跟蹤這些文件,并使其易于根據需要訪問和分析它們。
有效的日志記錄、檢查點、繪圖和文件管理可以幫助您跟蹤模型的進度,并使其更容易調試和優化訓練過程。

-
算法
+關注
關注
23文章
4619瀏覽量
93039 -
代碼
+關注
關注
30文章
4798瀏覽量
68728 -
網絡結構
+關注
關注
0文章
48瀏覽量
11124
原文標題:一文徹底搞懂YOLOv8【網絡結構+代碼+實操】
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
TensorRT 8.6 C++開發環境配置與YOLOv8實例分割推理演示
在AI愛克斯開發板上用OpenVINO?加速YOLOv8目標檢測模型

YOLOv8版本升級支持小目標檢測與高分辨率圖像輸入
AI愛克斯開發板上使用OpenVINO加速YOLOv8目標檢測模型

教你如何用兩行代碼搞定YOLOv8各種模型推理

一文徹底搞懂YOLOv8(網絡結構+代碼+實操)

目標檢測算法再升級!YOLOv8保姆級教程一鍵體驗
解鎖YOLOv8修改+注意力模塊訓練與部署流程
如何修改YOLOv8的源碼
YOLOv8實現任意目錄下命令行訓練
基于YOLOv8的自定義醫學圖像分割

基于OpenCV DNN實現YOLOv8的模型部署與推理演示





 工商網監
工商網監
評論