") 部署CoreMark從未這么簡(jiǎn)單
部署CoreMark從未這么簡(jiǎn)單
在枯燥的MCU生態(tài)里,有沒(méi)這樣一個(gè)往群里大叫一聲“不服?跑個(gè)分看看”,然后搬個(gè)小板凳躲在角落里吃瓜的機(jī)會(huì)呢?
簡(jiǎn)單來(lái)說(shuō),Coremark是一個(gè)專門(mén)測(cè)量嵌入式MCU(或者CPU)性能的跑分軟件,用來(lái)替代已經(jīng)過(guò)時(shí)且充滿爭(zhēng)議的Dhrystone跑分。Coremark包含了一系列算法:列表操作(查找和排序)、常用的矩陣運(yùn)算、狀態(tài)機(jī)以及CRC——這樣做的目的據(jù)說(shuō)是為了克服Dhrystone過(guò)于依賴libc庫(kù)的缺點(diǎn)。
這里記住結(jié)論就行:Dhrystone低級(jí)、過(guò)時(shí)、踩一腳;Coremark高級(jí)拉一把!
【部署CoreMark從未這么簡(jiǎn)單】
雖然Coremark的源代碼在Github上可以直接下載,但拿回家后還需要針對(duì)你的目標(biāo)處理器進(jìn)行一番移植。總的來(lái)說(shuō),移植需要解決兩類問(wèn)題:
提供對(duì)printf的重映射支持
提供一個(gè)足夠精準(zhǔn)的時(shí)間測(cè)量手段
哎,巧了不是。如果你使用的是Cortex-M處理器,并且習(xí)慣了在MDK環(huán)境下耕耘,只要借助 perf_counter 的幫助,在RTE里簡(jiǎn)單的勾選幾下就可以迅速的在任意Cortex-M處理器中部署 Coremark。
首先,關(guān)于MDK下實(shí)現(xiàn)通用的printf功能
從 v2.0.0開(kāi)始perf_counter 內(nèi)置了 Coremark,并針對(duì)Cortex-M處理器完成了幾乎所有的移植工作,這意味著你只需要在RTE中勾選對(duì)應(yīng)的模塊,即可完成對(duì)Coremark的部署(如下圖所示):
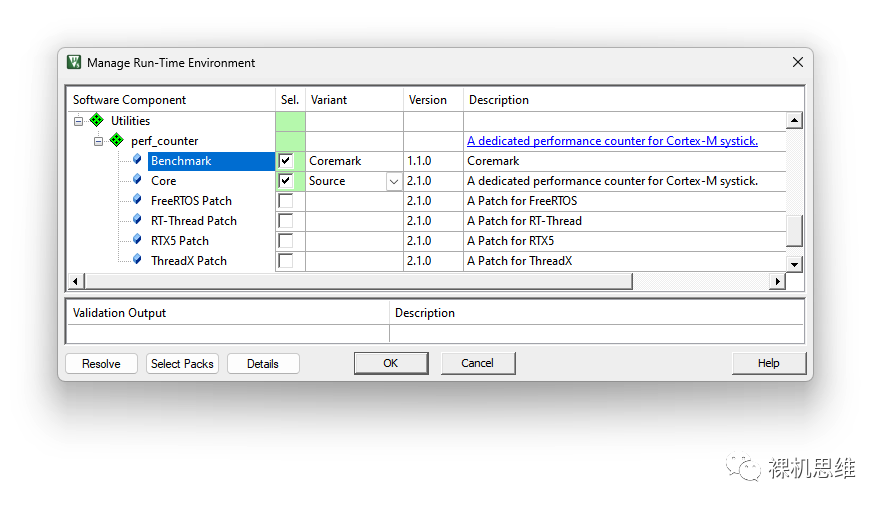
如果你已經(jīng)通過(guò)往期文章《【喂到嘴邊了的模塊】超級(jí)嵌入式系統(tǒng)“性能/時(shí)間”工具箱》熟悉過(guò)perf_counter的使用,那么接下來(lái)只要在超級(jí)循環(huán)里加入如下的代碼就大功告成了:
#include"perf_counter.h"
int main(void)
{
printf("Coremark 1.0
");
coremark_main();
while(1) {
}
}
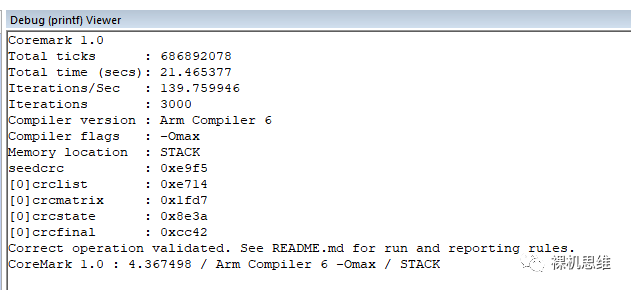
對(duì)應(yīng)的運(yùn)行效果如下(這里以Cortex-M55 r0p0為例,r0p1跑分會(huì)更高一些):
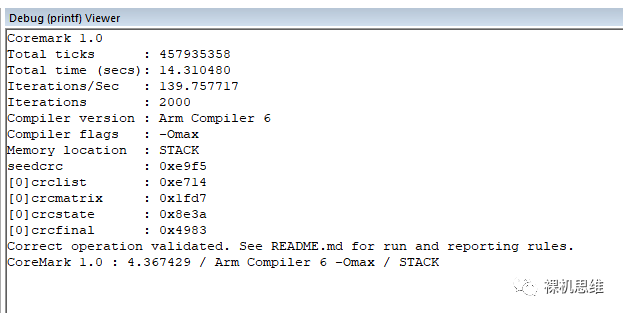
可以看到,這里的跑分結(jié)果是4.367429。
如果你之前從未用過(guò) perf_counter,則推薦通過(guò)文章《【喂到嘴邊了的模塊】超級(jí)嵌入式系統(tǒng)“性能/時(shí)間”工具箱》來(lái)了解詳細(xì)的部署和使用方式。這里就不再贅述。 值得特別強(qiáng)調(diào)的是,perf_counter 已經(jīng)加入 KEIL的官方索引列表,因此小伙伴可以直接從 Pack Installer 中找并安裝它的最新版本:
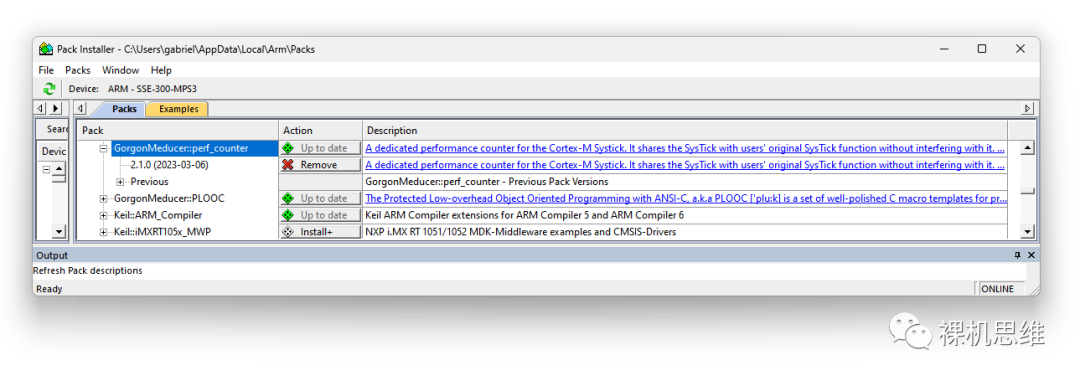
如果你的網(wǎng)絡(luò)不太好,無(wú)法通過(guò)Pack Installer直接安裝,也可以在關(guān)注公眾號(hào)【裸機(jī)思維】后向后臺(tái)發(fā)送關(guān)鍵字 perf_counter 來(lái)獲取網(wǎng)盤(pán)鏈接。 【常見(jiàn)問(wèn)題】
Coremark雖然簡(jiǎn)單直接,但在使用上仍然存在一些注意事項(xiàng):
Coremark跑分的制約因素
一般來(lái)說(shuō),Coremark的結(jié)果肯定會(huì)受到以下幾個(gè)因素的影響: 1. 優(yōu)化等級(jí)
不要奢望 -O0 能跑出多高的結(jié)果。但如果你的項(xiàng)目從來(lái)都只用 -O0 那么跑Coremark時(shí)也一定要用 -O0 ——因?yàn)檫@反應(yīng)了你使用時(shí)候的真實(shí)狀況。
很多芯片公司和Arm一樣都會(huì)用最好的編譯器在最高的速度優(yōu)化下跑Coremark,這意味著,我們通常可以在 Arm Compiler 6下使用 -Omax跑出當(dāng)前硬件平臺(tái)的最佳結(jié)果。
很多小伙伴可能不知道如何在 MDK 環(huán)境下使用 -Omax,因?yàn)?strong>Optimisation下拉列表中根本沒(méi)有 -Omax。-Omax 是一個(gè)比 -Ofast要更上一個(gè)臺(tái)階的優(yōu)化等級(jí)(用過(guò)都說(shuō)好),可以說(shuō)是MDK的一個(gè)隱藏技巧:
請(qǐng)?jiān)?Msc Controls 中直接添加 -Omax,同時(shí)
勾選 Link-Time-Optmisation
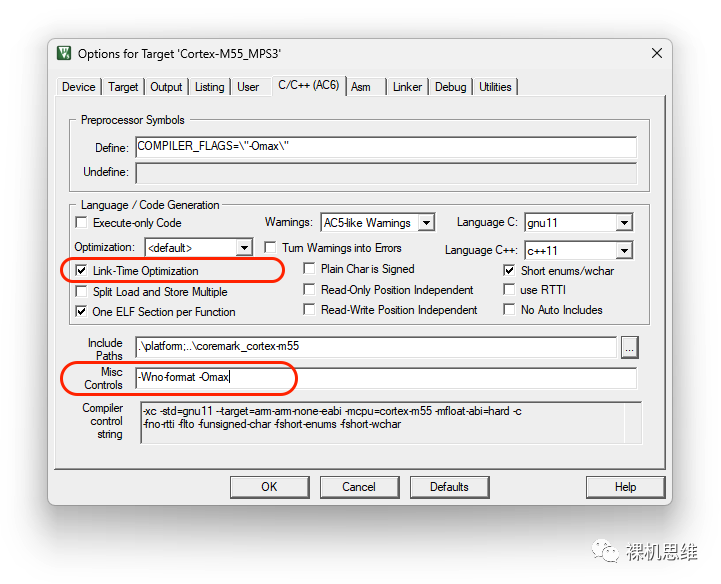
需要強(qiáng)調(diào)的是,一旦在 Misc Controls文本框中添加了 -Omax,無(wú)論你在 Optimization 下拉列表中選擇了哪個(gè)優(yōu)化等級(jí),都會(huì)被 -Omax 覆蓋掉。為了避免誤導(dǎo)后來(lái)人,推薦在這種情況下在該列表中選擇
2. 程序存儲(chǔ)器的速度以及RAM的訪問(wèn)速度
其實(shí)用腳指頭想也知道:Coremark的跑分會(huì)受到存儲(chǔ)器訪問(wèn)速度的影響。很多大公司會(huì)將程序保存在0 wait state 的 RAM中來(lái)跑 Coremark,以求獲得最佳的結(jié)果。
我猜很多小伙伴看到這里可能就炸了:我們平時(shí)都是在Flash里跑代碼,你拿RAM跑出來(lái)的數(shù)據(jù)糊弄我?這不是欺負(fù)老實(shí)人么?
實(shí)際并非如此,原因如下:
1)對(duì)很多大公司來(lái)說(shuō),他要給客戶提供理想狀況下所能達(dá)到的最高評(píng)分,方便用戶選型的時(shí)候了解芯片的能力上限(如果上限都達(dá)不到就別勉強(qiáng)了)
2)很多芯片會(huì)專門(mén)提供用于運(yùn)行代碼的 PRAM、SRAM或者 TCM(Tightly Couple Memory),因此,只要合理安排程序的存儲(chǔ)器布局,在核心應(yīng)用和算法上,的確可以跑出官方給出的最大性能
從另外一個(gè)角度來(lái)說(shuō),以Cortex-M處理器為例,通過(guò)Coremark,對(duì)比Arm提供的最高跑分,我們可以很容易的評(píng)估當(dāng)前芯片的 Flash速度是否拖累了處理器——從跑分的差異上判斷拖累的程度。比如,很多時(shí)候,使用片內(nèi)Flash跑 Coremark、XIP(QSPI)連接的片外Flash 跑Coremark 可以看出巨大的跑分差異,給了我們一個(gè)定量判斷性能損失的參考手段——注意,只是參考,不是絕對(duì)的。
此外,RAM的速度也會(huì)對(duì)Coremark產(chǎn)生很大的影響,簡(jiǎn)單來(lái)說(shuō),0 wait state的 RAM,1~2個(gè)wait state 的 RAM以及 SDRAM 跑Coremark的結(jié)果是截然不同的——這同樣給了我們一個(gè)直觀感受不同RAM性能差異的參考手段。
3. 是否存在cache
有沒(méi)有cache,有多大的cache,以及cache覆蓋ROM還是RAM對(duì)Coremark結(jié)果的影響是巨大的。比如,哪怕你用 XIP 來(lái)跑 Coremark(或者用SDRAM來(lái)存儲(chǔ)數(shù)據(jù)),只要你Cache到位,其跑分幾乎和理想狀況相差無(wú)幾。
以上內(nèi)容用腳趾都能想出來(lái)。接下來(lái)給大家說(shuō)一個(gè)由cache引起的反直覺(jué)的現(xiàn)象:
前面我們說(shuō)過(guò),如果你想跑出最佳的跑分,就應(yīng)該使用編譯器的最高性能優(yōu)化,對(duì)Cortex-M和Arm Compiler 6來(lái)說(shuō)就是 -Omax + Link Time Optimisation。
有些芯片雖然為Flash提供了一個(gè)專門(mén)的Cache,但由于其尺寸有限(通常是為了降低功耗或者芯片面積),會(huì)出現(xiàn) -Omax + Link Time Optimisation優(yōu)化下跑分反而不如 -Oz 或者 -Os 的情況。
首先這不是編譯器的BUG,也不是你忘記給電腦開(kāi)光導(dǎo)致來(lái)了臟東西。原因其實(shí)很簡(jiǎn)單:很多編譯器在面向性能優(yōu)化的時(shí)候會(huì)進(jìn)行瘋狂的循環(huán)展開(kāi),這會(huì)導(dǎo)致原本小巧的循環(huán)體突然體積暴漲——如果循環(huán)展開(kāi)后的體積超過(guò)了cache所能容忍的程度,就會(huì)在這個(gè)關(guān)鍵的循環(huán)中頻繁出現(xiàn) cache miss——相當(dāng)于處理器是直接從Flash上讀取代碼。
相反,在-Oz 和 -Os 通常不會(huì)進(jìn)行此類循環(huán)展開(kāi),因此在執(zhí)行循環(huán)熱點(diǎn)時(shí),0 wait state的cache發(fā)揮了高速緩存應(yīng)有的作用,與直接在Flash上讀取代碼相比,極大的提高了程序的運(yùn)行速度。
這里的關(guān)鍵其實(shí)是 cache 的大小以及循環(huán)展開(kāi)后的體積。一般來(lái)說(shuō),大家常用的一線廠商芯片其 Flash Cache尺寸還是很得體的,一般不會(huì)出現(xiàn)上述情況,可以放心食用。
Coremark必須跑夠10秒以上
這是Coremark為了跑出有效跑分而在算法中做出的硬性規(guī)定,如果你的芯片頻率過(guò)高,則很可能會(huì)出現(xiàn)類似如下的提示:
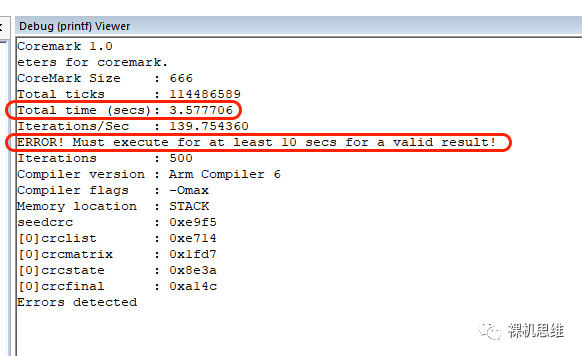
ERROR! Must execute for at least 10 secs for a valid result.
觀察Total time (secs)可以知道Coremark實(shí)際運(yùn)行了多少秒。
要解決這一問(wèn)題也很簡(jiǎn)單:直接在工程中定義宏 ITERATIONS,并給出一個(gè)較大的值即可,比如3000:
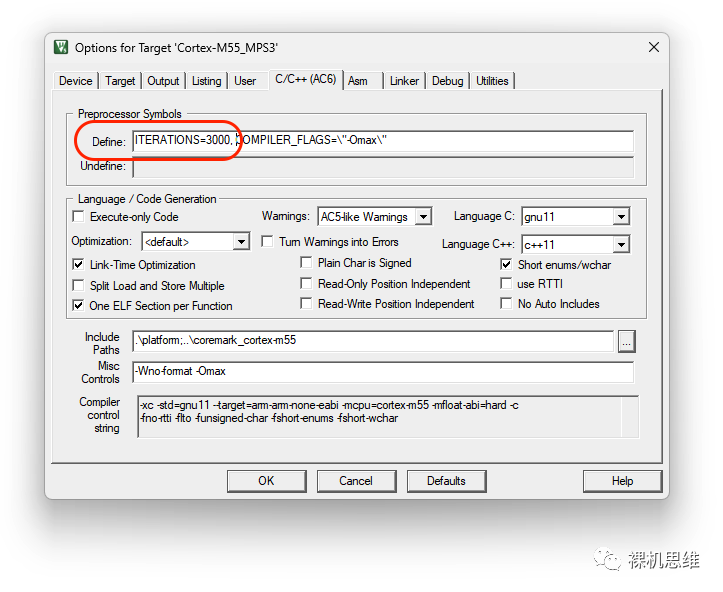
重新編譯,調(diào)試:
Coremark的結(jié)果處理
細(xì)心的小伙伴可能會(huì)發(fā)現(xiàn)一個(gè)現(xiàn)象,在很多新聞報(bào)道中,某些芯片廠商會(huì)聲稱自己的芯片Coremark跑分高達(dá)幾千分,為什么我們這里所展示的Coremark跑分只有個(gè)位數(shù)呢? 其實(shí)二者都沒(méi)錯(cuò),幾千分的那個(gè)結(jié)果是將芯片的頻率考慮在內(nèi),而這里個(gè)位數(shù)的跑分是以1MHz作為參考——也就是所謂的 “每兆赫茲Coremark”——顯然,將結(jié)果換算成 1MHz 為單位的結(jié)果更為直觀,也方便大家將不同頻率的芯片拿到一起作比較,因此 perf_counter 在移植 Coremark 時(shí)也選擇以 每MHz Coremark作為結(jié)果輸出的標(biāo)準(zhǔn)格式。
審核編輯:劉清
-
處理器
+關(guān)注
關(guān)注
68文章
19399瀏覽量
230727 -
ARM
+關(guān)注
關(guān)注
134文章
9155瀏覽量
368530 -
存儲(chǔ)器
+關(guān)注
關(guān)注
38文章
7526瀏覽量
164166 -
RAM
+關(guān)注
關(guān)注
8文章
1369瀏覽量
114875 -
Cortex-M
+關(guān)注
關(guān)注
2文章
229瀏覽量
29802
原文標(biāo)題:【嵌入式】不服?跑個(gè)分看看!——Coremark篇
文章出處:【微信號(hào):技術(shù)讓夢(mèng)想更偉大,微信公眾號(hào):技術(shù)讓夢(mèng)想更偉大】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于Cortex-M的CoreMark性能測(cè)試
程序簡(jiǎn)單,電路也簡(jiǎn)單,這么就是達(dá)不到效果
如何將CoreMark程序移植到STM32
【NUCLEO-F412ZG試用體驗(yàn)】終結(jié)之CoreMark跑分
如何將CoreMark程序移植到STM32

【先楫半導(dǎo)體HPM6750EVKMINI評(píng)估板試用體驗(yàn)】三、coremark跑分測(cè)試
【試用報(bào)告】龍芯先鋒板:CPU性能測(cè)試—CoreMark和計(jì)算質(zhì)數(shù)
大神測(cè)評(píng) | 結(jié)果出乎意料! 先楫HPM6750 CoreMark 跑分測(cè)試

RK3566的CoreMark測(cè)試






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論