 【AI簡報20230602】能聽懂語音的ChatGPT來了!***開發調查報告發布
【AI簡報20230602】能聽懂語音的ChatGPT來了!***開發調查報告發布
AI 簡報 20230602 期
1. GPT-4變笨引爆輿論!文本代碼質量都下降,OpenAI剛剛回應了降本減料質疑
原文:https://mp.weixin.qq.com/s/K8W5Wy95YsDo8gfFyIUmvA
大模型天花板GPT-4,它是不是……變笨了?
先是少數用戶提出質疑,隨后大量網友表示自己也注意到了,還貼出不少證據。
有人反饋,把GPT-4的3小時25條對話額度一口氣用完了,都沒解決自己的代碼問題。
無奈切換到GPT-3.5,反倒解決了。
總結下大家的反饋,最主要的幾種表現有:
-
以前GPT-4能寫對的代碼,現在滿是Bug
-
回答問題的深度和分析變少了
-
響應速度比以前快了
這就引起不少人懷疑,OpenAI是不是為了節省成本,開始偷工減料?
兩個月前GPT-4是世界上最偉大的寫作助手,幾周前它開始變得平庸。我懷疑他們削減了算力或者把它變得沒那么智能。
這就不免讓人想起微軟新必應“出道即巔峰”,后來慘遭“前額葉切除手術”能力變差的事情……
網友們相互交流自己的遭遇后,“幾周之前開始變差”,成了大家的共識。
一場輿論風暴同時在Hacker News、Reddit和Twitter等技術社區形成。
這下官方也坐不住了。
OpenAI開發者推廣大使Logan Kilpatrick,出面回復了一位網友的質疑:
API 不會在沒有我們通知您的情況下更改。那里的模型處于靜止狀態。
是不是真的變笨了,請大家也踴躍討論~
2. 能聽懂語音的ChatGPT來了:10小時錄音扔進去,想問什么問什么
原文:https://mp.weixin.qq.com/s/C7VzXhuG0T6Njo2pNpGRQA
類 ChatGPT 模型的輸入框里可以粘貼語音文檔了。
大型語言模型(LLM)正在改變每個行業的用戶期望。然而,建立以人類語音為中心的生成式人工智能產品仍然很困難,因為音頻文件對大型語言模型構成了挑戰。
將 LLM 應用于音頻文件的一個關鍵挑戰是,LLM 受其上下文窗口的限制。在一個音頻文件能夠被送入 LLM 之前,它需要被轉換成文本。音頻文件越長,繞過 LLM 的上下文窗口限制的工程挑戰就越大。但工作場景中,我們往往需要 LLM 幫我們處理非常長的語音文件,比如從一段幾個小時的會議錄音中抽取核心內容、從一段訪談中找到某個問題的答案……
最近,語音識別 AI 公司 AssemblyAI 推出了一個名為 LeMUR 的新模型。就像 ChatGPT 處理幾十頁的 PDF 文本一樣,LeMUR 可以將長達 10 小時的錄音進行轉錄、處理,然后幫用戶總結語音中的核心內容,并回答用戶輸入的問題。

試用地址:https://www.assemblyai.com/playground/v2/source
LeMUR 是 Leveraging Large Language Models to Understand Recognized Speech(利用大型語言模型來理解識別的語音)的縮寫,是將強大的 LLM 應用于轉錄的語音的新框架。只需一行代碼(通過 AssemblyAI 的 Python SDK),LeMUR 就能快速處理長達 10 小時的音頻內容的轉錄,有效地將其轉化為約 15 萬個 token。相比之下,現成的、普通的 LLM 只能在其上下文窗口的限制范圍內容納最多 8K 或約 45 分鐘的轉錄音頻。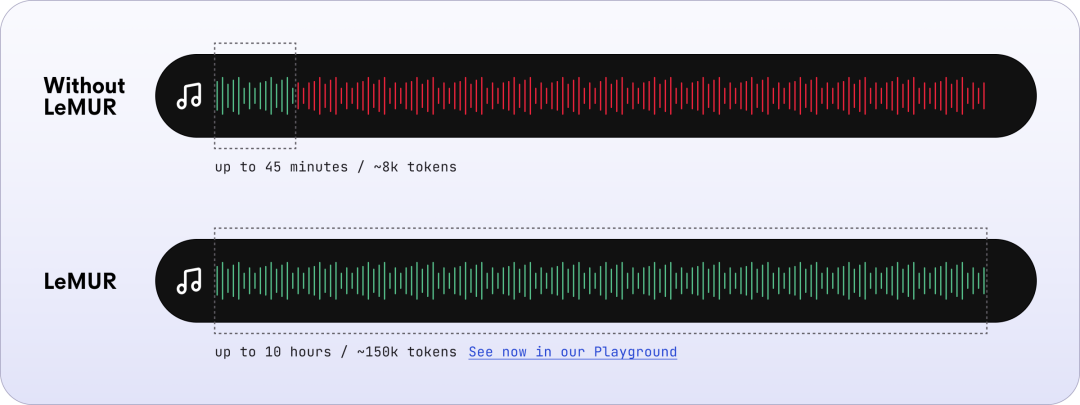
為了降低將 LLM 應用于轉錄音頻文件的復雜性,LeMUR 的 pipeline 主要包含智能分割、一個快速矢量數據庫和若干推理步驟(如思維鏈提示和自我評估),如下圖所示: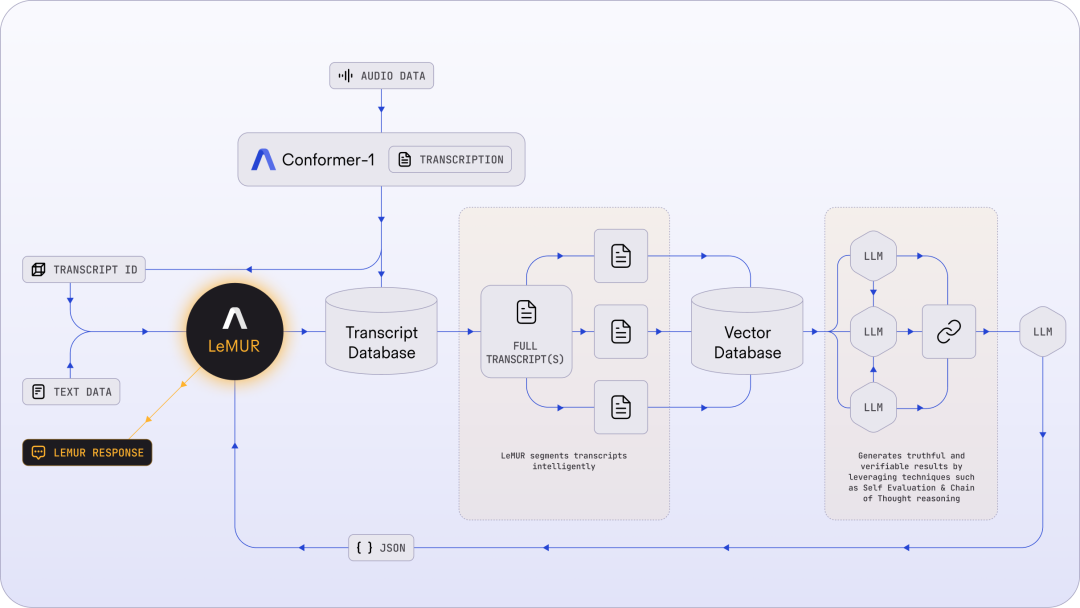
未來,LeMUR 有望在客服等領域得到廣泛應用。
LeMUR 解鎖了一些驚人的新可能性,在幾年前,我認為這些都是不可能的。它能夠毫不費力地提取有價值的見解,如確定最佳行動,辨別銷售、預約或呼叫目的等呼叫結果,感覺真的很神奇。—— 電話跟蹤和分析服務技術公司 CallRail 首席產品官 Ryan Johnson
LeMUR 解鎖了什么可能性?
將 LLM 應用于多個音頻文本
LeMUR 能夠讓用戶一次性獲得 LLM 對多個音頻文件的處理反饋,以及長達 10 小時的語音轉錄結果,轉化后的文本 token 長度可達 150K 。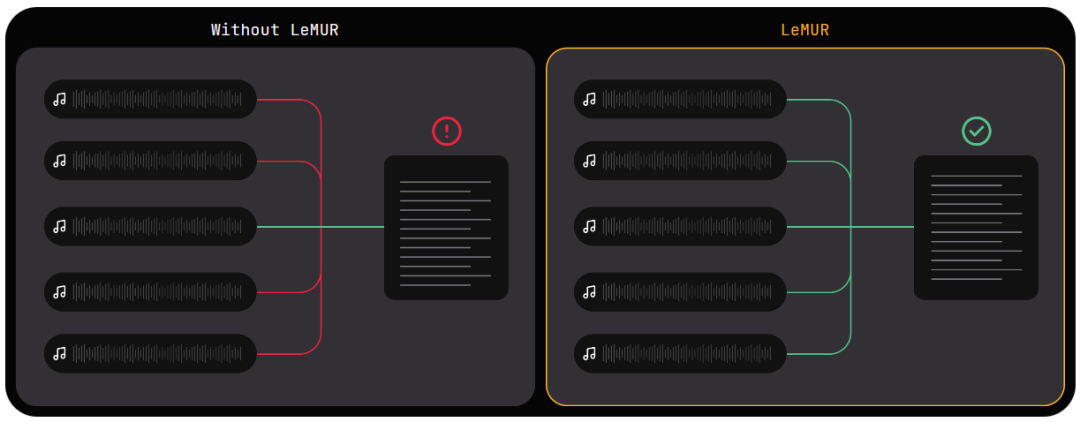
可靠、安全的輸出
由于 LeMUR 包含安全措施和內容過濾器,它將為用戶提供來自 LLM 的回應,這些回應不太可能產生有害或有偏見的語言。
可補充上下文
在推理時,它允許加入額外的上下文信息,LLM 可以利用這些額外信息在生成輸出時提供個性化和更準確的結果。
模塊化、快速集成
LeMUR 始終以可處理的 JSON 形式返回結構化數據。用戶可以進一步定制 LeMUR 的輸出格式,以確保 LLM 給出的響應是他們下一塊業務邏輯所期望的格式(例如將回答轉化為布爾值)。在這一流程中,用戶不再需要編寫特定的代碼來處理 LLM 的輸出結果。
試用結果
根據 AssemblyAI 提供的測試鏈接,機器之心對 LeMUR 進行了測試。
LeMUR 的界面支持兩種文件輸入方式:上傳音視頻文件或粘貼網頁鏈接均可。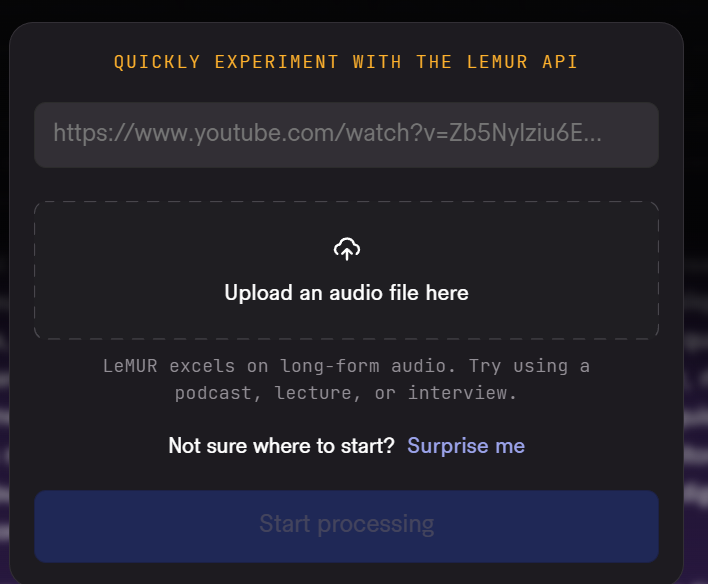
不過,LeMUR 似乎目前還不支持中文。感興趣的讀者可以去嘗試一下。
3. OpenAI要為GPT-4解決數學問題了:獎勵模型指錯,解題水平達到新高度
原文:https://mp.weixin.qq.com/s/rzm5jdwgc4mMzTZhirHOxQ
對于具有挑戰性的 step-by-step 數學推理問題,是在每一步給予獎勵還是在最后給予單個獎勵更有效呢?OpenAI 的最新研究給出了他們的答案。
現在,大語言模型迎來了「無所不能」的時代,其中在執行復雜多步推理方面的能力也有了很大提高。不過,即使是最先進的大模型也會產生邏輯錯誤,通常稱為幻覺。因此,減輕幻覺是構建對齊 AGI 的關鍵一步。
為了訓練更可靠的模型,目前可以選擇兩種不同的方法來訓練獎勵模型,一種是結果監督,另一種是過程監督。結果監督獎勵模型(ORMs)僅使用模型思維鏈的最終結果來訓練,而過程監督獎勵模型(PRMs)則接受思維鏈中每個步驟的獎勵。
考慮到訓練可靠模型的重要性以及人工反饋的高成本,仔細比較結果監督與過程監督非常重要。雖然最近的工作已經開展了這種比較,但仍然存在很多問題。
在本文中,OpenAI 進行了調研,結果發現在訓練模型解決 MATH 數據集的問題時,過程監督顯著優于結果監督。OpenAI 使用自己的 PRM 模型解決了 MATH 測試集中代表性子集的 78% 的問題。
此外為了支持相關研究,OpenAI 還開源了 PRM800K,它是一個包含 800K 個步級人類反饋標簽的完整數據集,用于訓練它們的最佳獎勵模型。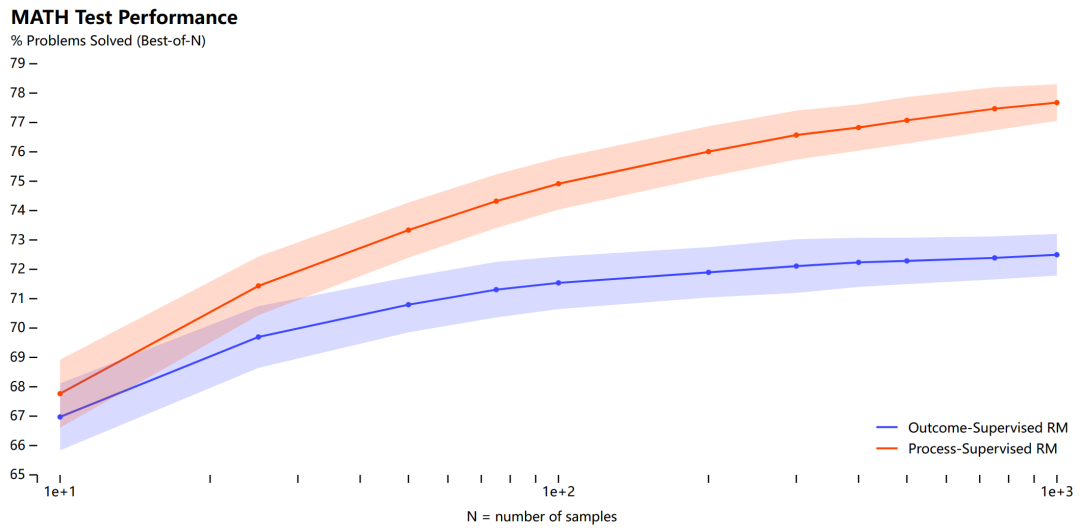
如下為一個真正(True positive)的問答示例。該問題以及 OpenAI 列舉的其他問題示例均來自 GPT-4。這個具有挑戰性的三角學問題需要并不明顯地連續應用多個恒等式。大多數解決方案嘗試都失敗了,因為很難知道哪些恒等式實際上有用。盡管 GPT-4 通常無法解決這個問題(正確率僅為 0.1% ),但本文的獎勵模型正確地識別出了這個解決方案是有效的。
再看一個假正(False positive)的問答示例。在第四步中,GPT-4 錯誤地聲稱該序列每 12 個項重復一次,而實際上是每 10 個項重復一次。這種計數錯誤偶爾會愚弄獎勵模型。
論文作者之一、OpenAI Alignment 團隊負責人 Jan Leike 表示,「使用 LLM 做數學題的真正有趣結果是:監督每一步比只檢查答案更有效。」
英偉達 AI 科學家 Jim Fan 認為,「這篇論文的觀點很簡單:對于挑戰性的逐步問題,要在每一步給予獎勵,而不要在最后給予單個獎勵。從根本上來說,密集獎勵信號>稀疏。」
我們接下來細看 OpenAI 這篇論文的方法和結果。
論文地址:https://cdn.openai.com/improving-mathematical-reasoning-with-process-supervision/Lets_Verify_Step_by_Step.pdf
數據集地址:https://github.com/openai/prm800k
方法概覽
該研究按照與 Uesato et al. (2022) 類似的方法對結果監督和過程監督進行了比較。值得注意的是這項研究無需人工即可提供結果監督,因為 MATH 數據集中的所有問題都有可自動檢查的答案。相比之下,沒有簡單的方法來自動化過程監督。該研究依靠人類數據標記者來提供過程監督,具體來說是需要人工標記模型生成的解決方案中每個步驟的正確性。該研究在大規模和小規模兩種情況下分別進行了實驗。
范圍
對于每種模型規模,該研究都使用一個固定模型來生成所有解決方案。這個模型被稱為生成器,OpenAI 表示不會通過強化學習 (RL) 來改進生成器。
基礎模型
所有大型模型均是基于 GPT-4 模型進行微調得來的。該研究還添加了一個額外的預訓練步驟 —— 在含有約 1.5B 數學相關 token 的數據集 MathMix 上微調所有模型。與 Lewkowycz et al. (2022) 類似,OpenAI 的研究團隊發現這種方法可以提高模型的數學推理能力。
生成器
為了更容易解析單個步驟,該研究訓練生成器在生成解決方案時,步驟之間用換行符分隔。具體來說,該研究對 MATH 訓練問題使用少樣本生成解決方案,過濾出得到最終正確答案的解決方案,并在該數據集上對基礎模型進行一個 epoch 的微調。
數據采集
為了收集過程監督數據,該研究向人類數據標記者展示了大規模生成器采樣的數學問題的逐步解決方案。人類數據標記者的任務是為解決方案中的每個步驟分配正面、負面或中性標簽,如下圖 1 所示。
該研究只標記大型生成器生成的解決方案,以最大限度地發揮有限的人工數據資源的價值。該研究將收集到的按步驟標記的整個數據集稱為 PRM800K。PRM800K 訓練集包含 800K 步驟標簽,涵蓋 12K 問題的 75K 解決方案。為了最大限度地減少過擬合,PRM800K 訓練集包含來自 MATH 的 4.5K 測試問題數據,并僅在剩余的 500 個 MATH 測試問題上評估模型。
結果監督獎勵模型 (ORM)
該研究按照與 Cobbe et al. (2021) 類似的方法訓練 ORM,并從生成器中為每個問題采樣固定數量的解決方案,然后訓練 ORM 來預測每個解決方案的正確與否。實踐中,自動檢查最終答案來確定正確性是一種常用的方法,但原則上由人工標記者來提供標簽。在測試時,該研究使用 ORM 在最終 token 處的預測作為每個解決方案的總分。
過程監督獎勵模型(PRM)
PRM 用來預測每個步驟(step)中最后一個 token 之后的步驟的正確性。這種預測采用單個 token 形式,并且 OpenAI 在訓練過程中最大化這些目標 token 的對數似然。因此,PRM 可以在標準的語言模型 pipeline 中進行訓練,無需任何特殊的適應措施。
圖 2 為同一個問題的 2 種解決方案,左邊的答案是正確的,右邊的答案是錯誤的。綠色背景表示 PRM 得分高,紅色背景表示 PRM 得分低。PRM 可以正確識別錯誤解決方案中的錯誤。
更多的細節請點擊原文查看。
4. 贏麻了!英偉達發布史上最強“巨型GPU”,黃仁勛:CPU擴張時代結束了
原文:https://mp.weixin.qq.com/s/N5Wd398FFplnK_uDreRlfQ
電子發燒友網報道(文/梁浩斌)今年英偉達可謂風生水起,過去五個月市值增長近三倍,自上周四公布今年一季度財報以來,截至5月30日股價也飆漲27%,市值9632億美元,有望進入萬億美元俱樂部。作為在這一輪生成式AI浪潮中的核心算力硬件供應商,已經“贏麻了”的英偉達并未有因此停下腳步,而是趁熱打鐵繼續推出驚人的算力硬件。

英偉達CEO黃仁勛在周一的臺北Computex展上帶來了2小時的激情演講,發布上推出了GH200 Grace Hopper超級芯片,以及將多達256塊GH200超級芯片整合到一起的DGX GH200“巨型GPU”,同時還展示了一系列AI相關的應用和產品。
黃仁勛表示:CPU擴張的時代已經結束了。
新計算時代:GPU買得越多,省得越多!
在這場2小時的演講開場,黃仁勛就提出了一個“暴論”,他表示“CPU擴張的時代已經結束了”。
在加速計算和AI重塑計算機行業的當下,從需要持續提升算力的數據中心可以看到,CPU的需求越來越少,而GPU的需求則不斷增長。黃仁勛認為,如今的計算機是指數據中心、是指云服務,與此同時可以為未來“計算機”編寫程序的程序員,如今將面臨行業的變革。
“我們已經到達生成式AI的爆點,從此世界的每一個角落,都會有計算需求。”在這樣的計算需求背景下,計算的性價比也非常重要。黃仁勛舉了兩個例子證明GPU比CPU在AI計算時代更有優勢:
在1000萬美元的成本下,可以用于建設一個有960顆CPU的數據中心,其中可以處理1X LLM(大語言模型)的數據量,同時需要消耗11GWh的能耗;同樣成本下,如果用于建設一個有48顆GPU的數據中心,不僅可以處理的LLM數據量是同成本CPU數據中心44倍,在功耗方面還能大幅降低至3.2GWh。
所以,黃仁勛不禁喊出了“The more you buy,The more you save”的口號,買GPU越多,你省下的錢也就越多。
強到離譜的GH200和DGX GH200
這次發布會上最重磅的產品無疑是GH200 Grace Hopper超級芯片,在發布會上,黃仁勛也公布了該款芯片的細節。GH200是基于NVIDIA NVLink-C2C互連技術,將Arm架構的NVIDIA Grace CPU和Hopper架構的 GPU實現互聯整合,最終實現高達900GB/s的總帶寬,這相比傳統的PCIe 5.0通道帶寬要高出7倍,可以滿足需求最嚴苛的AI 和HPC應用。
去年三月,英偉達在GTC大會上發布了基于Arm架構的Grace CPU,這款CPU專為計算加速平臺設計,擁有多達72個Armv9 CPU核心,緩存容量高達198MB,支持LPDDR5X ECC內存,帶寬高達1TB/s,并支持NVLink-C2C和PCIe 5.0兩種互連協議。
同樣是在去年的GTC大會上,英偉達發布了基于Hopper架構的全新H100 GPU,截至目前,H100依然是英偉達用于AI加速、HPC和數據分析等處理的最強GPU。
H100采用臺積電4nm定制工藝,擁有多達800億個晶體管,集成了18432個CUDA核心、576個Tenor核心、60MB二級緩存,并支持6144-bit位寬的HBM3/2e高帶寬內存。
而GH200 Grace Hopper,就是將72核的Grace CPU和當今世上最強的GPU H100,加上96GB的HBM3顯存、512GB的LPDDR5X內存封裝在一起,集成到一片“超級芯片”上。
黃仁勛將GH200 Grace Hopper形容為“這是一臺計算機,而不是芯片”。同時他透露,GH200 Grace Hopper目前已經全面投產。
如果GH200 Grace Hopper還不能滿足你的需求,英偉達還提供了一個由256個GH200 Grace Hopper組成的超級計算機系統——DGX GH200,而上一代的系統在不影響性能的前提下只能通過NVLink將8個GPU整合成一個系統。
那么DGX GH200是如何做到將256個GH200 Grace Hopper連接成一個系統?GH200 Grace Hopper和NVLink4.0、NVLink Switch System(交換機系統)是組建DGX GH200的重點。NVLink交換機系統形成了一個兩級、無阻塞、胖樹NVLink結構,結合新的NVLink 4.0和第三代NV SWitch,英偉達可以用一個前所未有的高帶寬水平來構建大規模NVLink交換機系統。通過計算節點外的交換機模塊,將最高256個計算節點,也就是GPU連接為一個整體。
最終這個擁有256個GH200 Grace Hopper超級芯片的DGX GH200超級計算機能夠提供高達1 Exaflop(百億億次)級別的性能、并具有144TB的共享內存,內容容量幾乎是上一代的500倍。
黃仁勛稱DGX GH200是“巨型GPU”,并預計DGX GH200將在今年年底開始供貨并投入使用,Google Cloud、Meta與微軟將會是首批能夠使用DGX GH200的公司。
除此之外,英偉達還在使用DGX GH200打造一個更大規模的超級計算機,這款被稱為NVIDIA Helios的超級計算機將配備4個DGX GH200,通過英偉達的Quantum-2 InfiniBand交換機進行互連。那么NVIDIA Helios將成為一個由1024個GH200 Grace Hopper超級芯片構成的巨型AI計算系統,這套系統也將會在今年年底啟用。
AI應用遍地開花
發布會上,黃仁勛還宣布推出一種名為Avatar Cloud Engine(ACE)的AI模型代工服務,這種模型主要應用在游戲領域,可以為游戲開發人員提供訓練模型,通過簡單的操作定制想要的游戲AI模型。
在演示中,游戲玩家可以用自己的聲音與NPC角色進行對話,由生成式AI加持的NPC,可以根據玩家的語音實時生成不同的回答,增強游戲的沉浸體驗。
在內容方面,英偉達目前正在與全球最大的廣告集團WPP合作,開發一款利用NVIDIA Omniverse和AI的內容引擎,以更高效地幫助創意團隊制作高質量商業內容,并針對客戶的品牌產出不同的針對性內容,這或許是AI顛覆廣告行業的一個嘗試。
除此之外,在工業領域,英偉達也正在用AI來幫助工業生產提高效率,比如用于模擬和測試機器人的英偉達Isaac Sim;用于自動光學檢測的英偉達Metropolis視覺AI框架;用于3D設計協作的英偉達Omniverse等。
黃仁勛表示,目前富士康工業互聯網、宜鼎國際、和碩、廣達、緯創等制造業巨頭都在使用英偉達的參考工作流程,比如構建數字孿生、模擬協作機器人、檢測自動化等。
小結
今年AIGC發展速度超出所有人想象,近期甚至有調研機構在一個半月之內將今年AI服務器出貨量增長預期從15.4%提升至38.4%。毫無疑問,黃仁勛和他的英偉達是在這新一輪AI革命中最大的贏家。
5. AI大模型落地加速還會遠嗎?首個完全量化Vision Transformer的方法FQ-ViT
原文:https://mp.weixin.qq.com/s/2LJykooI7LNSjGlFKdJCHA

模型量化顯著降低了模型推理的復雜性,并已被廣泛用于現實應用的部署。然而,大多數現有的量化方法主要是在卷積神經網絡(CNNs)上開發的,當應用于全量化的Vision Transformer時,會出現嚴重的退化。
在這項工作中證明了這些困難中的許多是由于LayerNorm輸入中的嚴重通道間變化而出現的,并且提出了Power-of-Two Factor(PTF),這是一種減少全量化Vision Transformer性能退化和推理復雜性的系統方法。此外,觀察到注意力圖中的極端非均勻分布,提出了Log Int Softmax(LIS)來維持這一點,并通過使用4位量化和BitShift算子來簡化推理。
在各種基于Transformer的架構和基準測試上進行的綜合實驗表明,全量化Vision Transformer(FQ-ViT)在注意力圖上使用更低的位寬的同時,也優于以前的工作。例如,在ImageNet上使用ViT-L達到84.89%的Top-1準確率,在COCO上使用Cascade Mask R-CNN(SwinS)達到50.8 mAP。據所知是第1個在全量化的Vision Transformer上實現無損精度下降(~1%)的算法。
Github地址:https://github.com/megvii-research/FQ-ViT
1、簡介
基于Transformer的架構在各種計算機視覺(CV)任務中取得了具有競爭力的性能,包括圖像分類、目標檢測、語義分割等。與CNN的同類架構相比,Transformer通常具有更多的參數和更高的計算成本。例如,ViT-L具有307M參數和190.7G FLOP,在經過大規模預訓練的ImageNet中達到87.76%的準確率。然而,當部署到資源受限的硬件設備時,基于Transformer的架構的大量參數和計算開銷帶來了挑戰。
為了便于部署,已經提出了幾種技術,包括架構設計的量化、剪枝、蒸餾和自適應。在本文中重點關注量化技術,并注意到剪枝、蒸餾和架構自適應與本文的工作正交,并且可以組合。
大多數現有的量化方法都是在神經網絡上設計和測試的,并且缺乏對轉化子特異性構建的適當處理。先前的工作發現,在量化Vision Transformer的LayerNorm和Softmax時,精度顯著下降。在這種情況下,模型沒有完全量化,導致需要在硬件中保留浮點單元,這將帶來巨大的消耗,并顯著降低推理速度。
因此,重新審視了Vision Transformer的這2個專屬模塊,并發現了退化的原因:
-
首先,作者發現LayerNorm輸入的通道間變化嚴重,有些通道范圍甚至超過中值的40倍。傳統方法無法處理如此大的激活波動,這將導致很大的量化誤差。
-
其次,作者發現注意力圖的值具有極端的不均勻分布,大多數值聚集在0~0.01之間,少數高注意力值接近1。
基于以上分析,作者提出了Power-of-Two Factor(PTF)來量化LayerNorm的輸入。通過這種方式,量化誤差大大降低,并且由于Bit-Shift算子,整體計算效率與分層量化的計算效率相同。
此外,還提出了Log Int Softmax(LIS),它為小值提供了更高的量化分辨率,并為Softmax提供了更有效的整數推理。結合這些方法,本文首次實現了全量化Vision Transformer的訓練后量化。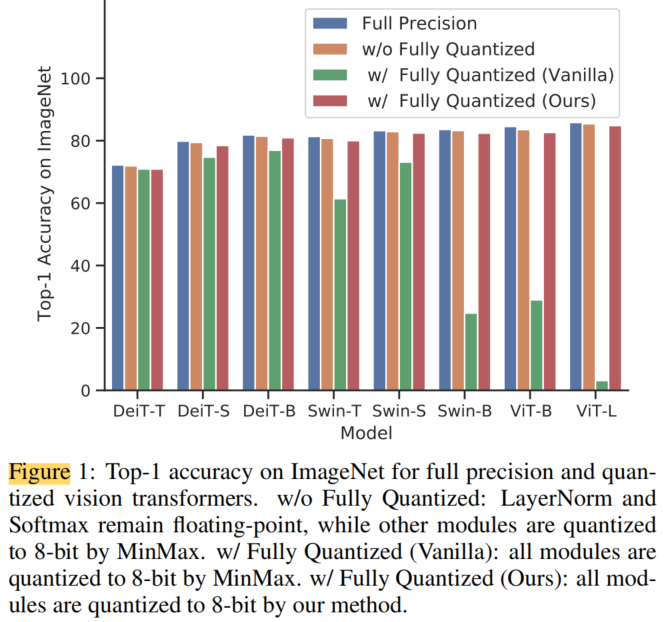
如圖1所示,本文的方法顯著提高了全量化Vision Transformer的性能,并獲得了與全精度對應算法相當的精度。
本文的貢獻有4方面:
-
重新審視了完全量化的Vision Transformer,并將精度下降歸因于LayerNorm輸入的嚴重通道間變化。同時,觀察到注意力圖的極端不均勻分布,導致量化誤差。
-
提出了Power-of-Two Factor(PTF),這是一種簡單而有效的后訓練方法,可以在只有一個分層量化尺度的情況下對LayerNorm輸入實現精確量化。
-
提出了Log Int Softmax(LIS),這是一種可以對注意力圖執行4-bit量化的新方法。使用LIS,可以將注意力映射存儲在一個激進的低位上,并用Bit-Shift運算符代替乘法。在Softmax模塊上實現了僅整數推理,顯著降低了推理消耗。
-
使用各種基于Transformer的架構對圖像分類和目標檢測進行了廣泛的實驗。結果表明,全量化Vision Transformer具有8位權重/激活和4位注意力映射,可以實現與浮點版本相當的性能。
2、相關工作
2.1、Vision Transformer
最近,基于Transformer的體系結構在CV任務中顯示出巨大的威力。基于ViT的新興工作證明了分類、檢測和分割等所有視覺任務的有效性。新提出的Swin Transformer在幾乎傳統的CV任務上甚至超過了最先進的神經網絡,呈現出強大的Transformer表達和泛化能力。
然而,這些高性能的Vision Transformer歸因于大量的參數和高計算開銷,限制了它們的采用。因此,設計更小、更快的Vision Transformer成為一種新趨勢。LeViT通過下采樣、Patch描述符和注意力MLP塊的重新設計,在更快的推理方面取得了進展。DynamicViT提出了一個動態Token稀疏化框架,以逐步動態地修剪冗余Token,實現競爭復雜性和準確性的權衡。Evo-ViT提出了一種快速更新機制,該機制可以保證信息流和空間結構,從而降低訓練和推理的復雜性。雖然上述工作側重于高效的模型設計,但本文在量化的思路上提高了壓縮和加速。
2.2、模型量化
目前的量化方法可以分為兩類:量化感知訓練(QAT)和訓練后量化(PTQ)。
QAT依賴于訓練來實現低比特(例如2比特)量化和有希望的性能,而它通常需要高水平的專家知識和巨大的GPU資源來進行訓練或微調。為了降低上述量化成本,無訓練的PTQ受到了越來越廣泛的關注,并出現了許多優秀的作品。OMSE建議通過最小化量化誤差來確定激活的值范圍。AdaRound提出了一種新的舍入機制來適應數據和任務損失。
除了上述針對神經網絡的工作外,Liu等人還提出了一種具有相似性感知和秩感知策略的Vision Transformer訓練后量化方法。然而,這項工作沒有量化Softmax和LayerNorm模塊,導致量化不完整。在本文的FQ-ViT中,目標是在PTQ范式下實現精確、完全量化的Vision Transformer。
相關更多細節,我們請點擊原文查看相關原理。
6. ***開發為什么這么難?2023 中國芯片開發者調查報告發布
https://mp.weixin.qq.com/s/WY04ogsgLngZdoZQF6YyEA
造芯難,隨著各產業的發展,研發不同場景下的芯片更難。
不久前,OPPO 芯片設計子公司哲庫關停,兩名高管在最后一次會議上幾度哽咽,宣布因為全球經濟和手機行業不樂觀,公司的營收遠遠達不到預期,芯片的巨大投資讓公司無法負擔,最終 3000 多人原地解散。這一消息迅速席卷全網,也給半導體行業帶來一抹悲涼的色彩。
事實上,近幾年來,隨著國際競爭環境的演變,以及半導體行業的長周期性,芯片行業面臨著多維度的挑戰。日前,CSDN 從開發者、工程師維度進行了深度的調研,最新發布了《2023 中國芯片開發者調查報告》,分享開發者認知中的芯片行業現狀,揭曉***研發的重點難題,希望借此能夠為半導體行業的從業者、企業、學術研究帶來一些思考。
芯片人才缺失嚴重,軟硬協調能力培養需重視
一直以來,芯片從設計到制造從未有過坦途。這背后需要大量的知識積累和開發經驗,但在國內這方面的人才儲備仍然相對較少,這使得芯片研究和開發的進程受到了限制。
數據顯示,開發者對芯片的了解程度存在較大差異。僅有 6% 的開發者能夠深入理解技術,較深入應用。多數處于了解概念階段,占比近五成。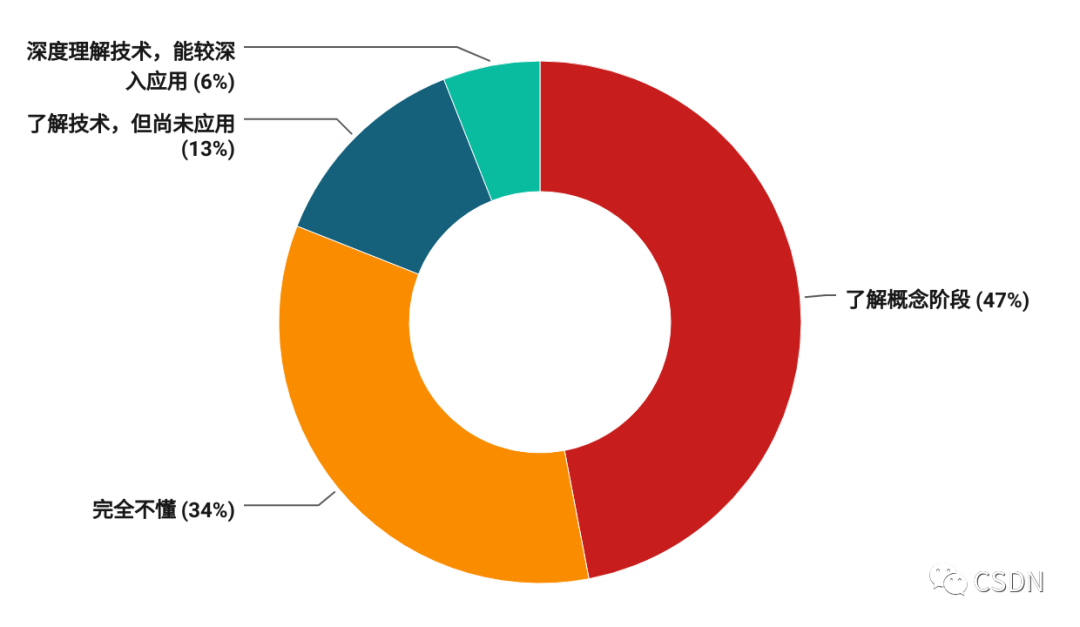
究其背后,要開發芯片,相關從業者需要掌握一系列技術,包括但不限于:
-
邏輯設計:了解數字電路設計和邏輯門電路。你需要熟悉硬件描述語言(HDL)如 Verilog、VHDL,以及邏輯設計工具 EDA(Electronic Design Automation)等。
-
物理設計:涉及芯片的物理布局和布線。
-
模擬設計:熟悉模擬電路設計和模擬集成電路(IC)設計技術。這包括了解模擬電路元件、電路模擬工具如 SPICE(Simulation Program with Integrated Circuit Emphasis),以及模擬電路布局和布線。
-
時鐘和時序設計:掌握時鐘電路設計和時序分析,以確保芯片內各個模塊的時序一致性和正確性。
-
半導體工藝技術:了解半導體制造工藝和工藝流程,包括光刻、薄膜沉積、離子注入、蝕刻等。這對于了解芯片制造過程和對芯片性能的影響非常重要。
-
芯片驗證:了解芯片驗證技術,包括功能驗證、時序驗證、功耗驗證和物理驗證。這包括使用仿真工具、驗證語言(如 SystemVerilog)和硬件驗證語言(如 UVM)。
-
芯片封裝和測試:了解芯片封裝和測試技術,包括封裝類型選擇、引腳布局、封裝材料和測試方法。
以上只是芯片開發中的一些關鍵技術,也屬于冰山一角。因此,芯片開發人員需要不斷學習來提高自身的技術水平和競爭力。數據顯示,芯片相關從業者有超過半數的人,每天至少學習 1 小時以上。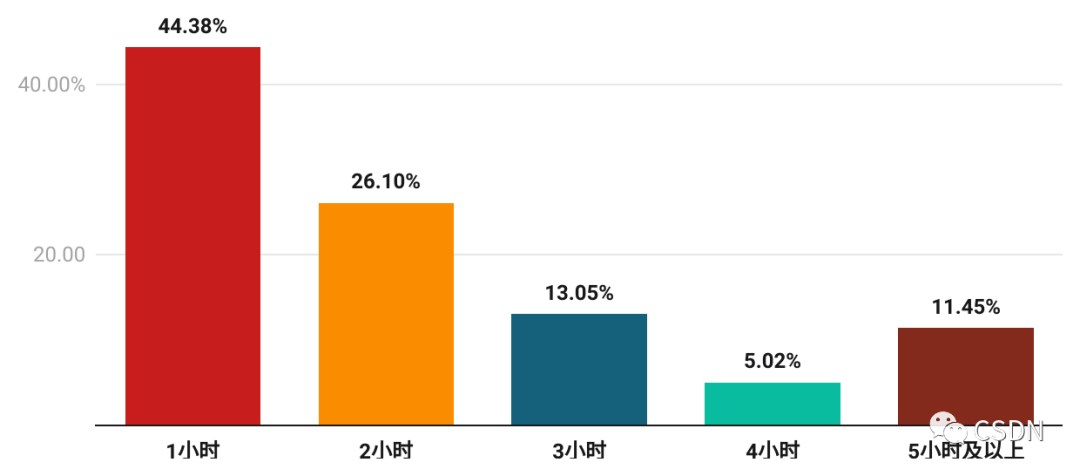
對于芯片開發這個復雜的任務,隨著物聯網、5G 網絡、人工智能等領域的快速發展,對高性能芯片的需求越來越大,而這種需求又遠遠超過了現有的芯片工程師數量。55.98% 的開發者表示,他們團隊當前最急需的是芯片架構工程師。其次是集成電路 IC 設計/應用工程師、半導體技術工程師。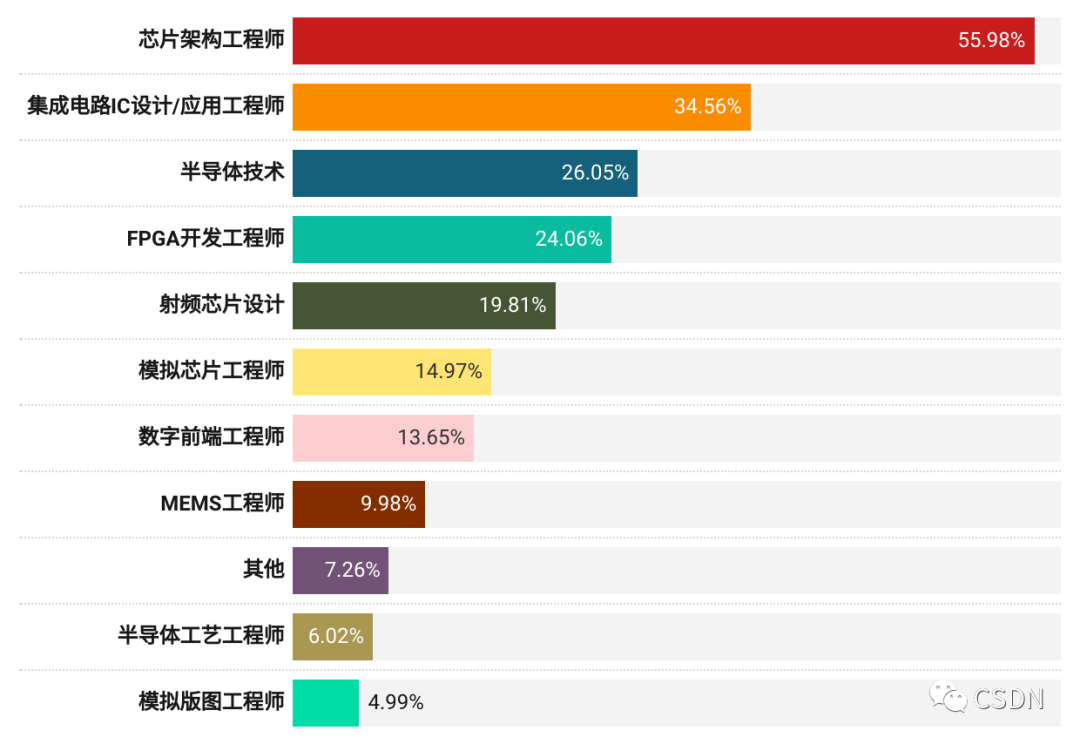
對此,中國科學院計算技術研究所副所長包云崗點評道,芯片設計人才嚴重短缺,軟硬件協同能力培養需重視。在調研的開發者中,只有 6% 的開發者能夠深入理解芯片技術,也就是芯片設計人員僅占軟件開發人員的 1/16 左右(6% vs. 94%)。用軟件行業來對比,2021 年軟件相關產品營業額約為 36000 億(軟件產品收入 26583 億元+嵌入式系統軟件收入 9376 億元),芯片設計行業產值約為軟件開發行業產值的 1/7。這些統計數據口徑并不一致,但也一定程度上能反映出芯片設計人員的嚴重短缺。
小團隊作戰,AI 成為芯片應用的重要場景之一
放眼當前國內芯片市場入局的公司規模,呈現出一定的分散趨勢。40.42% 的公司人數小于 10 人,這些公司可能是由獨立的芯片設計師或者小團隊組成,可能主要專注于某個細分領域的應用開發。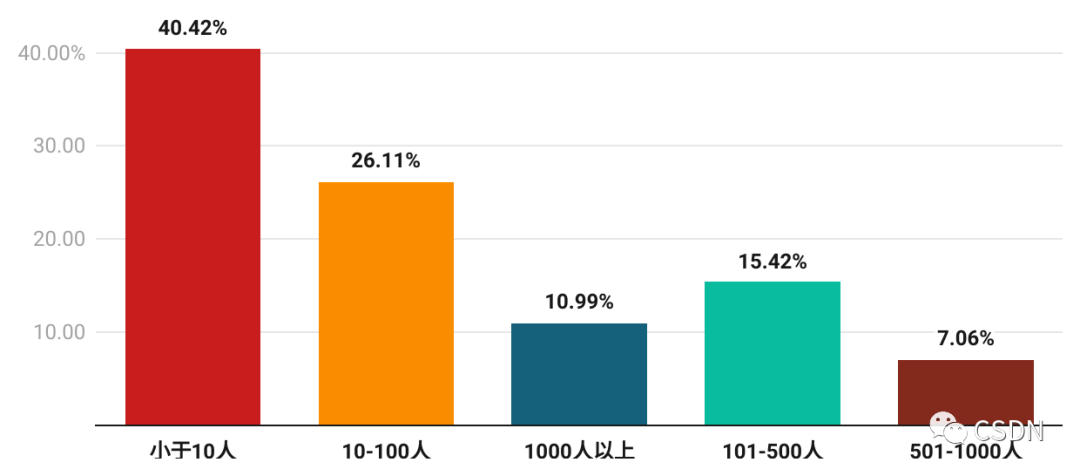
數據顯示,當前的芯片公司的芯片主要服務于物聯網以及通信系統及設備。其中,物聯網占比最大且遠高于其他產品/服務,占比 31.07%,其次為通信系統及設備,占比 20.63%。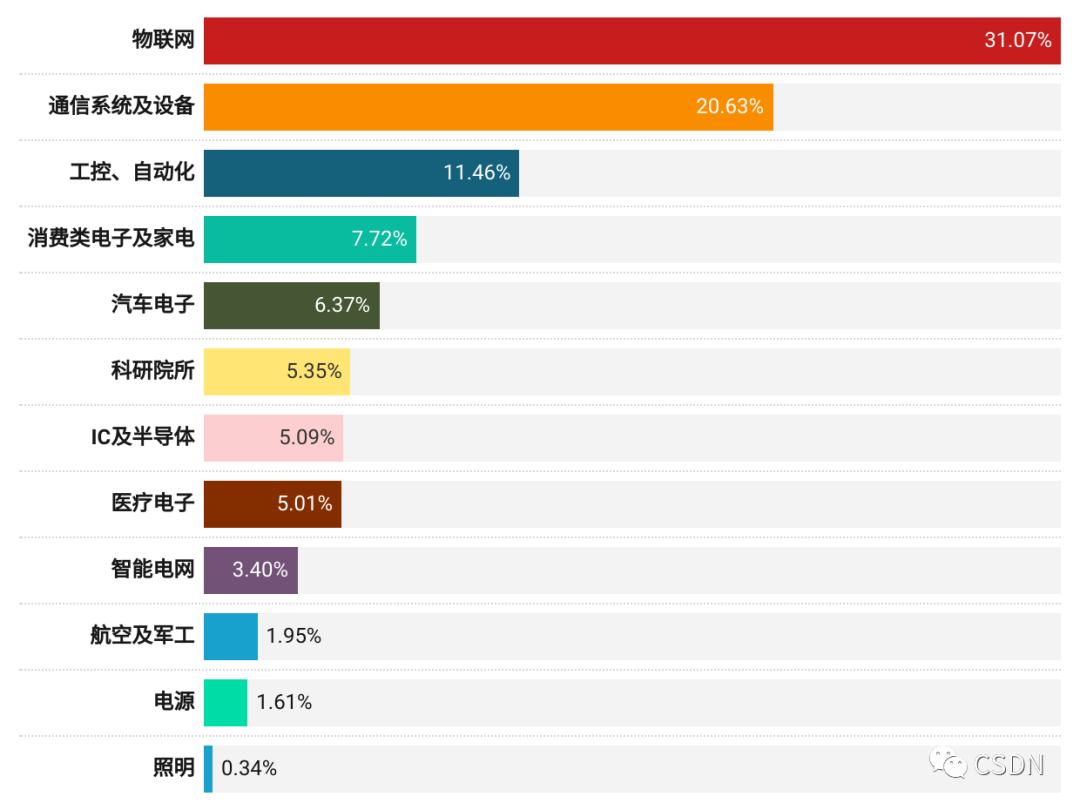
人工智能蓬勃發展,越來越多的專用芯片設計用于人工智能領域,它們的特點是針對特定的計算任務進行了高度優化。數據顯示,在國內的芯片公司中,有 38.46% 的芯片是搭載人工智能技術的,能為人工智能應用提供更加高效的計算能力。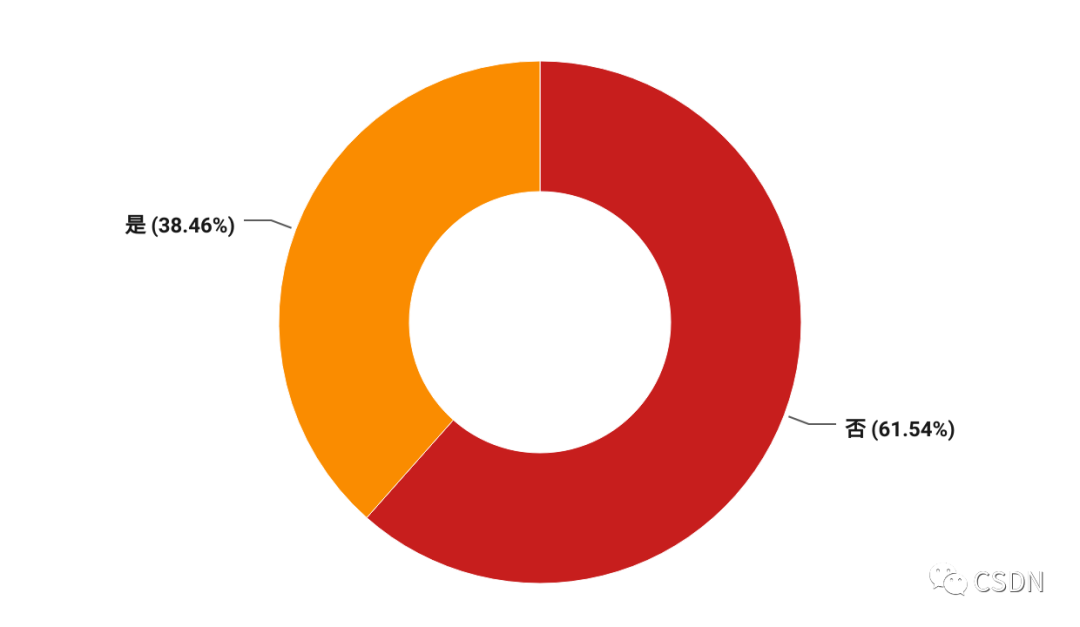
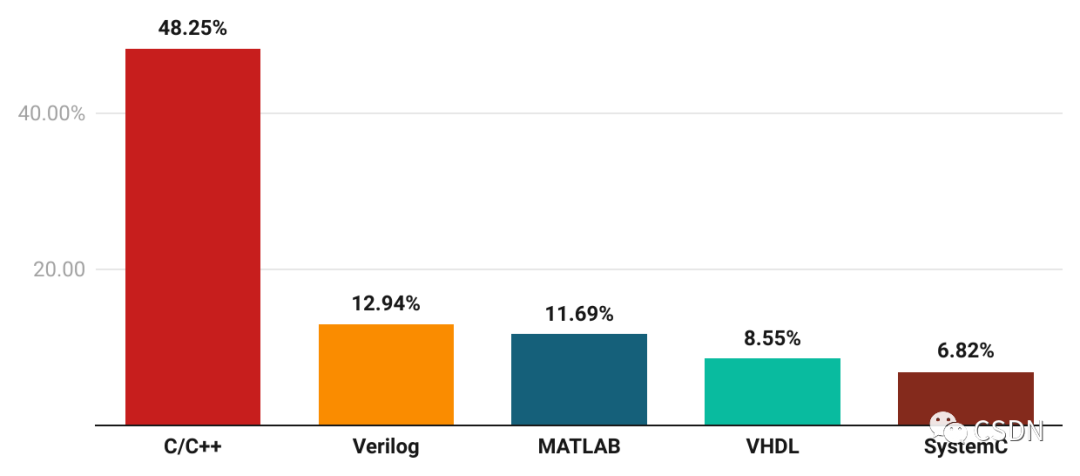
在芯片開發工具層面,芯片開發人員在開發語言的選擇上多樣性較高,其中最常用的兩種語言分別是 C/C++ 和 Verilog。C/C++ 是一種常見的通用程序設計語言,可用于高級的應用程序和底層系統編程,數據顯示,近五成的開發者在使用它們進行編寫代碼;而 Verilog 則是一種硬件描述語言,主要用于數字電路的建模和仿真,使用的開發者占比 12.94%。
芯片開發中使用的 EDA 工具多種多樣,且芯片開發人員常用的 EDA 工具呈現出多樣性和分散性。
數據顯示,使用最廣泛的工具是 Protel,占 26.11%;其次是 AlTIum Designer,占 18.10%;開發人員可以根據自己的需求、意愿和實踐經驗,選擇最適合自己的工具來進行芯片設計、仿真和測試。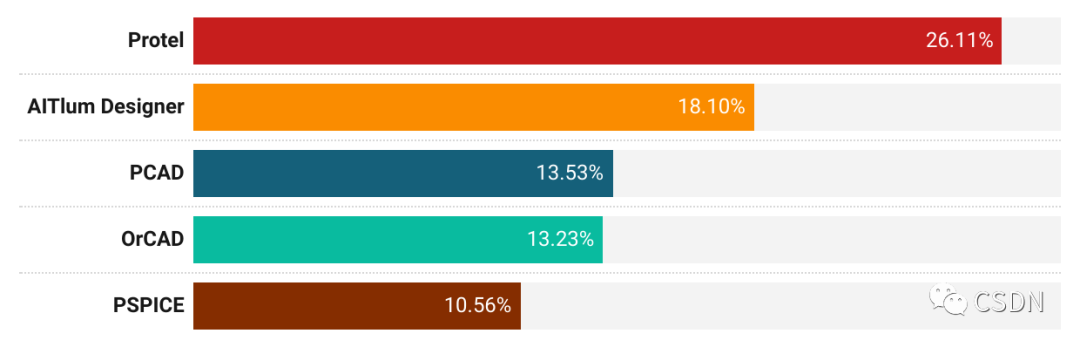
***開發的挑戰:設計、低功耗和專利
在現代技術中,芯片作為基礎設施之一,芯片參數也是開發者們最為關注的話題。首先是算力,它衡量芯片處理速度的指標,67.06% 的開發者表示他們關心芯片算力參數;其次是功耗,它也是衡量芯片的重要指標之一,42.63% 的開發者也比較關心。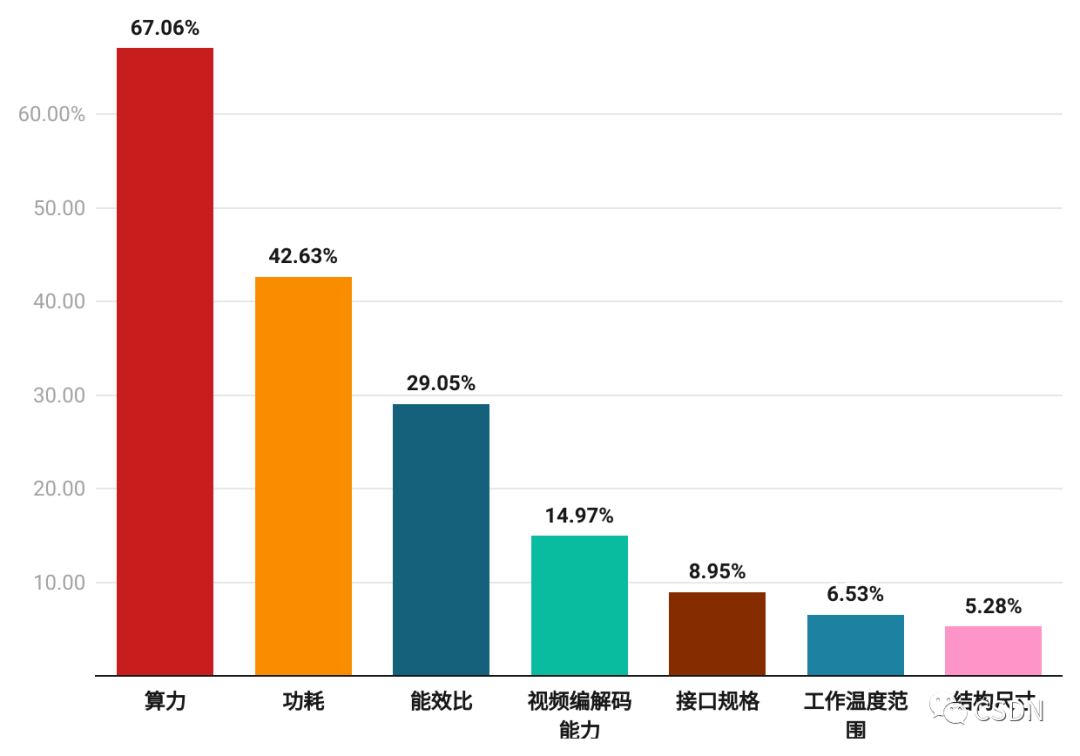
***在開發中面臨很多挑戰和難題,以下是一些主要的方面:
-
設計能力:芯片設計是復雜而艱巨的工作,需要高超的技術和精湛的設計能力。39.91% 的開發者表示,當前以國內的設計能力,很難去降低芯片設計成本。其次便是低功耗設計,35.36% 的開發者表示要實現低功耗也非常困難。
-
專利保護:芯片制造涉及到大量的專利技術,國內芯片開發中,需要進行專利規避
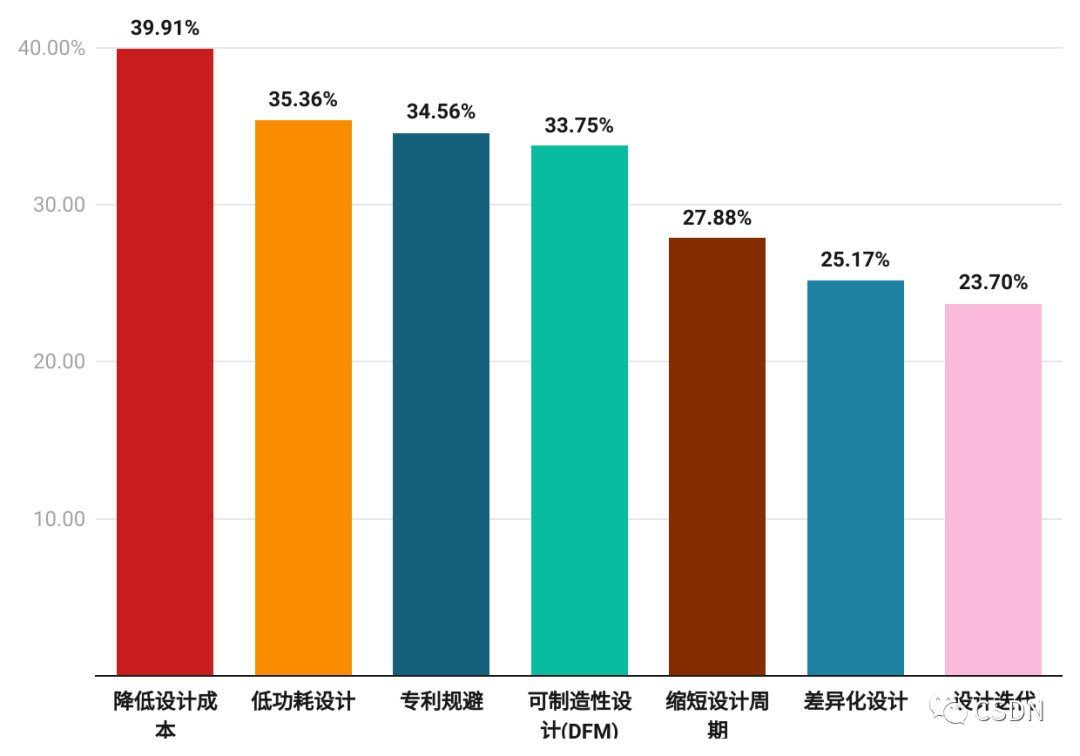
在芯片設計上,開發者最擔憂的是 EDA 設計工具,現代芯片的復雜度非常高,一個芯片可能包含數十億個晶體管和數百萬條線路,因此設計過程中需要更優秀的工具來幫助工程師處理如此巨大的設計空間。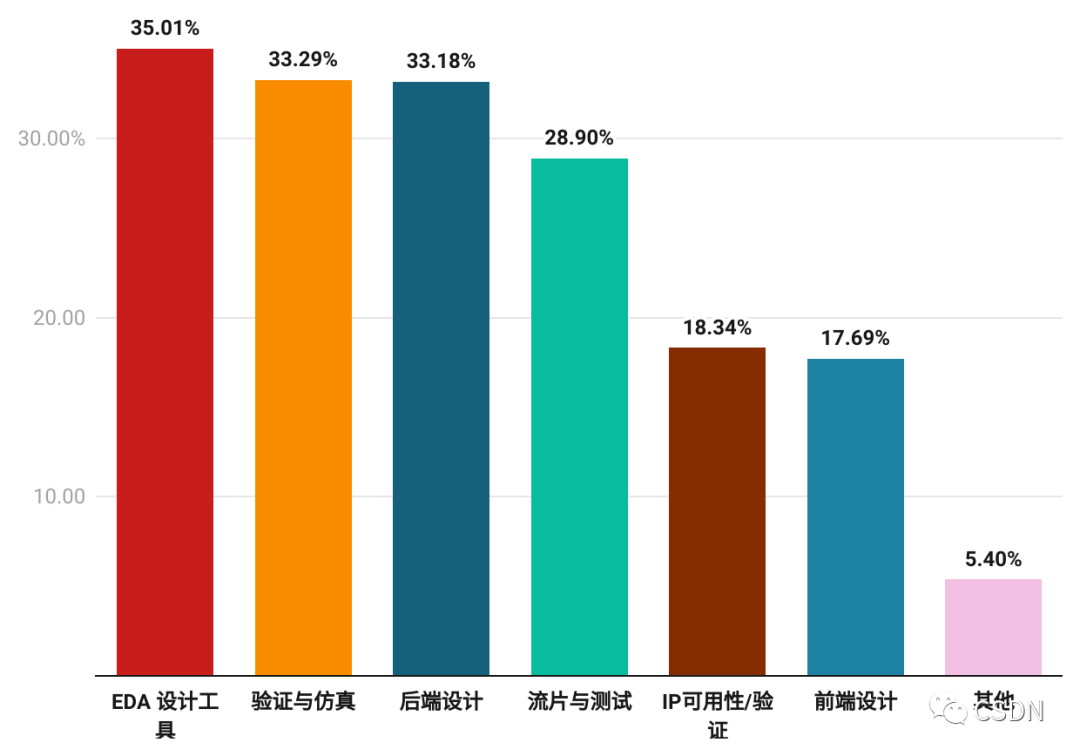
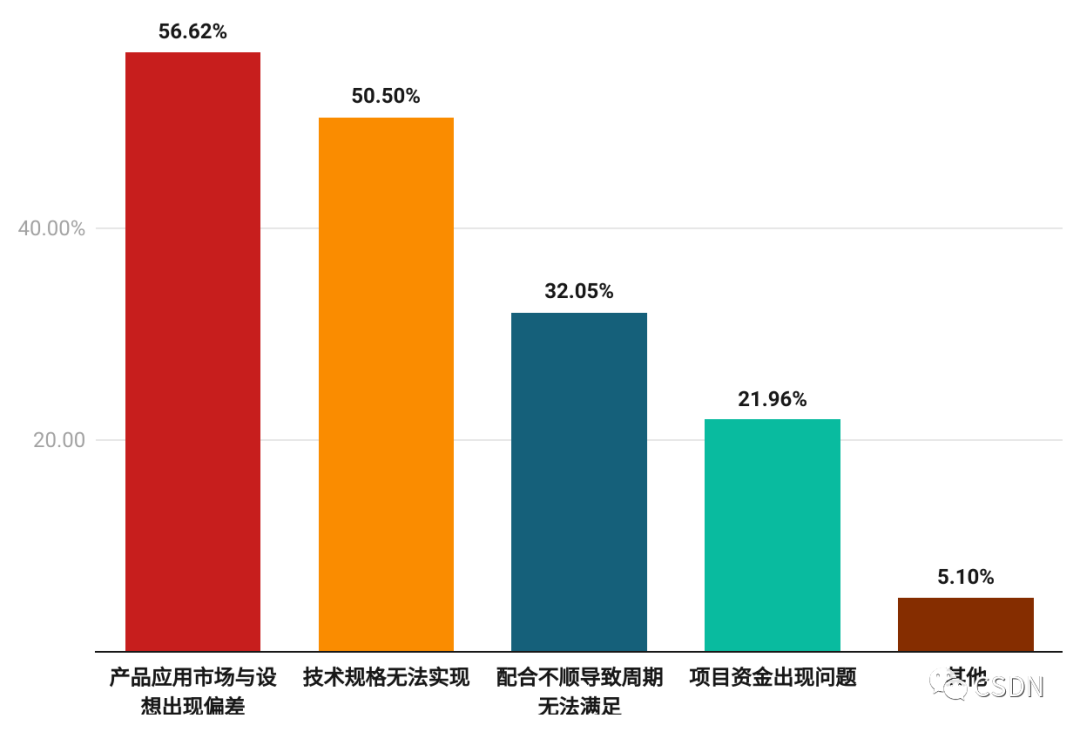
芯片制造與軟件開發流程不同,不能像軟件開發那進行小步快跑的迭代,整個制造過程的成本也比較高。
56.62% 的開發者認為在芯片制造中,容易出現產品應用市場與設想出現偏差,從而導致研發投入、生產成本等方面的浪費。其次是在芯片開發過程中,某些設計規格無法實現,半數的開發者都對此表示擔心。
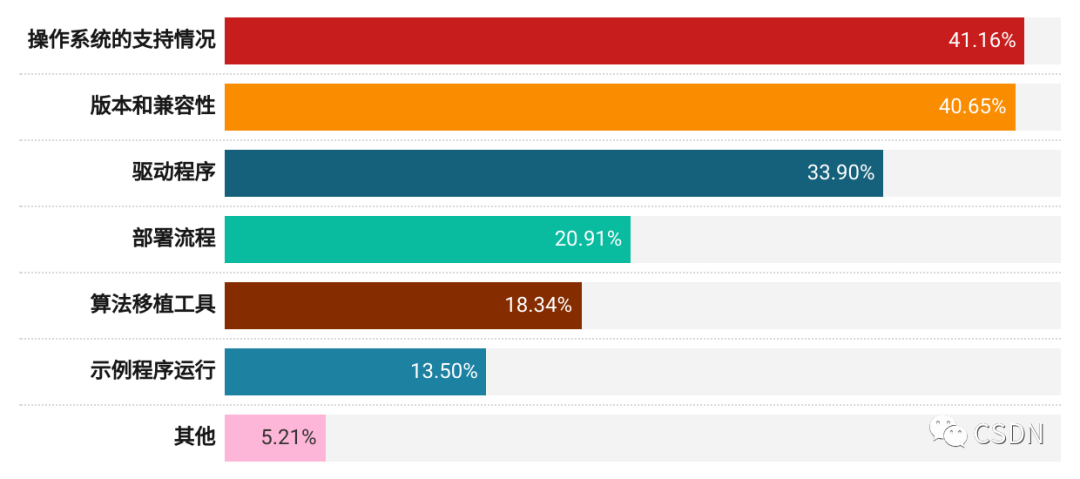 包云崗認為,超過 41% 的開發者最關心的是芯片對操作系統的支持情況。由此可見,優秀的芯片設計人才不僅僅懂芯片架構,也需要懂操作系統等軟件棧知識。然而,這類人才在國內更是稀缺,因為很多集成電路學院并不開設操作系統等軟件課程。要解決人才急缺問題,當前人才培養理念與方案需要改變,需要更重視軟硬件協同能力的培養。開源芯片的未來
隨著開源芯片技術的日益成熟,其市場份額也將逐漸增加,開源芯片平臺如 RISC-V 等已經被廣泛應用于各種應用場合。它作為一項新興技術,其未來的發展前景非常廣闊,76.77% 的開發者都看好開源芯片的發展,有望實現規模應用,將會在未來的幾年中迎來爆發式增長。
包云崗認為,超過 41% 的開發者最關心的是芯片對操作系統的支持情況。由此可見,優秀的芯片設計人才不僅僅懂芯片架構,也需要懂操作系統等軟件棧知識。然而,這類人才在國內更是稀缺,因為很多集成電路學院并不開設操作系統等軟件課程。要解決人才急缺問題,當前人才培養理念與方案需要改變,需要更重視軟硬件協同能力的培養。開源芯片的未來
隨著開源芯片技術的日益成熟,其市場份額也將逐漸增加,開源芯片平臺如 RISC-V 等已經被廣泛應用于各種應用場合。它作為一項新興技術,其未來的發展前景非常廣闊,76.77% 的開發者都看好開源芯片的發展,有望實現規模應用,將會在未來的幾年中迎來爆發式增長。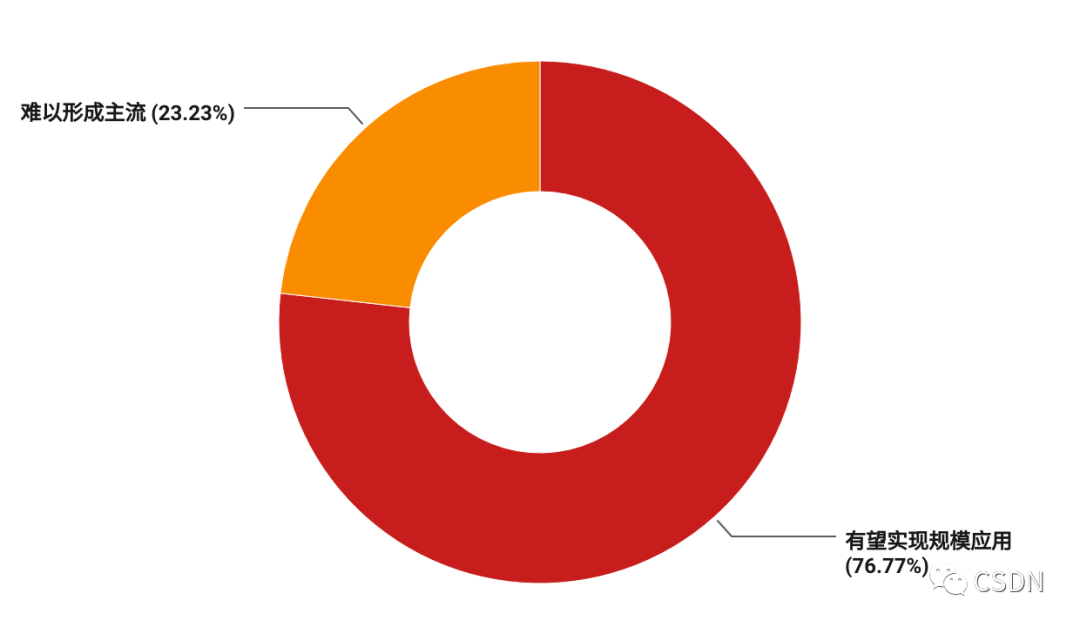 整體而言,包云崗總結道,新興領域芯片需求快速增長,開源芯片未來可期。
一方面,報告中顯示當前芯片主要服務于物聯網(31%)以及通信系統及設備(21%)。在調研的企業中,研發的芯片中有 38% 搭載人工智能技術,這也反映了當前人工智能領域的蓬勃發展。兩項數據結合,可以大致反映出很多物聯網場景也有人工智能需求。
另一方面,在被調研的芯片公司中,40% 的公司人數小于 10 人,26%的公司人數為 10-100 人。結合 2022 年 12 月魏少軍教授在 ICCAD 會上的關于中國芯片設計產業總體發展情況的報告數據顯示,全國甚至有 2700 余家(占84%)芯片設計公司人數不足 100。
總之,國內絕大多數芯片設計企業人員規模并不大,他們主要專注于某個細分領域的芯片開發。這些企業的存在是因為物聯網等新興領域帶來的芯片碎片化需求,而以 RISC-V 為代表的開源芯片允許企業更方便地定制芯片,是應對碎片化需求的有效方式,也有助于實現企業非常關心的降低芯片設計成本的需求。
?
整體而言,包云崗總結道,新興領域芯片需求快速增長,開源芯片未來可期。
一方面,報告中顯示當前芯片主要服務于物聯網(31%)以及通信系統及設備(21%)。在調研的企業中,研發的芯片中有 38% 搭載人工智能技術,這也反映了當前人工智能領域的蓬勃發展。兩項數據結合,可以大致反映出很多物聯網場景也有人工智能需求。
另一方面,在被調研的芯片公司中,40% 的公司人數小于 10 人,26%的公司人數為 10-100 人。結合 2022 年 12 月魏少軍教授在 ICCAD 會上的關于中國芯片設計產業總體發展情況的報告數據顯示,全國甚至有 2700 余家(占84%)芯片設計公司人數不足 100。
總之,國內絕大多數芯片設計企業人員規模并不大,他們主要專注于某個細分領域的芯片開發。這些企業的存在是因為物聯網等新興領域帶來的芯片碎片化需求,而以 RISC-V 為代表的開源芯片允許企業更方便地定制芯片,是應對碎片化需求的有效方式,也有助于實現企業非常關心的降低芯片設計成本的需求。
?———————End———————
RT-Thread線下入門培訓
6月 - 鄭州、杭州、深圳
1.免費2.動手實驗+理論3.主辦方免費提供開發板4.自行攜帶電腦,及插線板用于筆記本電腦充電5.參與者需要有C語言、單片機(ARM Cortex-M核)基礎,請提前安裝好RT-Thread Studio 開發環境

立即掃碼報名
報名鏈接
https://jinshuju.net/f/UYxS2k
巡回城市:青島、北京、西安、成都、武漢、鄭州、杭州、深圳、上海、南京
你可以添加微信:rtthread2020 為好友,注明:公司+姓名,拉進RT-Thread官方微信交流群!
點擊閱讀原文,進入RT-Thread 官網
原文標題:【AI簡報20230602】能聽懂語音的ChatGPT來了!***開發調查報告發布
文章出處:【微信公眾號:RTThread物聯網操作系統】歡迎添加關注!文章轉載請注明出處。
-
RT-Thread
+關注
關注
31文章
1304瀏覽量
40300
原文標題:【AI簡報20230602】能聽懂語音的ChatGPT來了!國產芯片開發調查報告發布
文章出處:【微信號:RTThread,微信公眾號:RTThread物聯網操作系統】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ChatGPT新增實時搜索與高級語音功能
大聯大推出基于MediaTek Genio 130與ChatGPT的AI語音助理方案

訊飛開放平臺攜手開發者共建繁榮生態
預計2028年京東方OLED產能將超越三星
韓企人工智能使用率僅為30.6%
OpenAI 深夜拋出王炸 “ChatGPT- 4o”, “她” 來了
蘋果首款折疊屏MacBook或提前至2026年發布

富士通發布2024 SX調查報告 揭示可持續發展的關鍵成功因素





 工商網監
工商網監
評論