") 編譯器在Cache優(yōu)化中可以做哪些工作?
編譯器在Cache優(yōu)化中可以做哪些工作?
引言
軟件開發(fā)人員往往期望計算機硬件擁有無限容量、零訪問延遲、無限帶寬以及便宜的內(nèi)存,但是現(xiàn)實卻是內(nèi)存容量越大,相應(yīng)的訪問時間越長;內(nèi)存訪問速度越快,價格也更貴;帶寬越大,價格越貴。為了解決大容量、高速度、低成本之間的矛盾,基于程序訪問的局部性原理,將更常用數(shù)據(jù)放在小容量的高速存儲器中,多種速度不同的存儲器分層級聯(lián),協(xié)調(diào)工作。
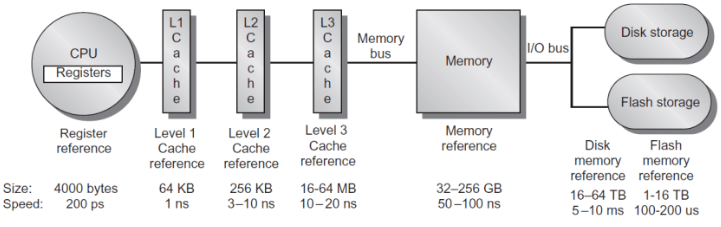
圖1 memory hierarchy for sever[1]
現(xiàn)代計算機的存儲層次可以分幾層。如圖1所示,位于處理器內(nèi)部的是寄存器;稍遠一點的是一級Cache,一級Cache一般能夠保存64k字節(jié),訪問它大約需要1ns,同時一級Cache通常劃分為指令Cache(處理器從指令Cache中取要執(zhí)行的指令)和數(shù)據(jù)Cache(處理器從數(shù)據(jù)Cache中存/取指令的操作數(shù));然后是二級Cache,通常既保存指令又保存數(shù)據(jù),容量大約256k,訪問它大約需要3-10ns;然后是三級Cache,容量大約16-64MB,訪問它大約需要10-20ns;再接著是主存、硬盤等。注意,CPU和Cache是以word傳輸?shù)模珻ache到主存以塊(一般64byte)傳輸?shù)摹?/p>
前文提到了程序的局部性原理,一般指的是時間局部性(在一定時間內(nèi),程序可能會多次訪問同一內(nèi)存空間)和空間局部性(在一定時間內(nèi),程序可能會訪問附近的內(nèi)存空間),高速緩存(Cache)的效率取決于程序的空間和時間的局部性性質(zhì)。比如一個程序重復(fù)地執(zhí)行一個循環(huán),在理想情況下,循環(huán)的第一個迭代將代碼取至高速緩存中,后續(xù)的迭代直接從高速緩存中取數(shù)據(jù),而不需要重新從主存裝載。因此,為了使程序獲得更好的性能,應(yīng)盡可能讓數(shù)據(jù)訪問發(fā)生在高速緩存中。但是如果數(shù)據(jù)訪問在高速緩存時發(fā)生了沖突,也可能會導(dǎo)致性能下降。
篇幅原因,本文重點討論編譯器在Cache優(yōu)化中可以做哪些工作,如果讀者對其他內(nèi)存層次優(yōu)化感興趣,歡迎留言。下面將介紹幾種通過優(yōu)化Cache使用提高程序性能的方法。
對齊和布局
現(xiàn)代編譯器可以通過調(diào)整代碼和數(shù)據(jù)的布局方式,提高Cache命中率,進而提升程序性能。本節(jié)主要討論數(shù)據(jù)和指令的對齊、代碼布局對程序性能的影響,大部分處理器中Cache到主存是以Cache line(一般為64Byte,也有地方稱Cache塊,本文統(tǒng)一使用Cache line)傳輸?shù)模珻PU從內(nèi)存加載數(shù)據(jù)是一次一個Cache line,CPU往內(nèi)存寫數(shù)據(jù)也是一次一個Cache line。假設(shè)處理器首次訪問數(shù)據(jù)對象A,其大小剛好為64Byte,如果數(shù)據(jù)對象A首地址并沒有進行對齊,即數(shù)據(jù)對象A占用兩個不同Cache line的一部分,此時處理器訪問該數(shù)據(jù)對象時需要兩次內(nèi)存訪問,效率低。但是如果數(shù)據(jù)對象A進行了內(nèi)存對齊,即剛好在一個Cache line中,那么處理器訪問該數(shù)據(jù)時只需要一次內(nèi)存訪問,效率會高很多。編譯器可以通過合理安排數(shù)據(jù)對象,避免不必要地將它們跨越在多個Cache line中,盡量使得同一對象集中在一個Cache中,進而有效地使用Cache來提高程序的性能。通過順序分配對象,即如果下一個對象不能放入當(dāng)前Cache line的剩余部分,則跳過這些剩余的部分,從下一個Cache line的開始處分配對象,或者將大小(size)相同的對象分配在同一個存儲區(qū),所有對象都對齊在size的倍數(shù)邊界上等方式達到上述目的。
Cache line對齊可能會導(dǎo)致存儲資源的浪費,如圖2所示,但是執(zhí)行速度可能會因此得到改善。對齊不僅僅可以作用于全局靜態(tài)數(shù)據(jù),也可以作用于堆上分配的數(shù)據(jù)。對于全局?jǐn)?shù)據(jù),編譯器可以通過匯編語言的對齊指令命令來通知鏈接器。對于堆上分配的數(shù)據(jù),將對象放置在Cache line的邊界或者最小化對象跨Cache line的次數(shù)的工作不是由編譯器來完成的,而是由runtime中的存儲分配器來完成的^[2]^。

圖2 因塊對齊可能會浪費存儲空間
前文提到了數(shù)據(jù)對象對齊,可以提高程序性能。指令Cache的對齊,也可以提高程序性能。同時,代碼布局也會影響程序的性能,將頻繁執(zhí)行的基本塊的首地址對齊在Cache line的大小倍數(shù)邊界上能增加在指令Cache中同時容納的基本塊數(shù)目,將不頻繁執(zhí)行的指令和頻繁指令的指令放到不同的Cache line中,通過優(yōu)化代碼布局來提升程序性能。
利用硬件輔助
Cache預(yù)取是將內(nèi)存中的指令和數(shù)據(jù)提前存放至Cache中,達到加快處理器執(zhí)行速度的目的。Cache預(yù)取可以通過硬件或者軟件實現(xiàn),硬件預(yù)取是通過處理器中專門的硬件單元實現(xiàn)的,該單元通過跟蹤內(nèi)存訪問指令數(shù)據(jù)地址的變化規(guī)律來預(yù)測將會被訪問到的內(nèi)存地址,并提前從主存中讀取這些數(shù)據(jù)到Cache;軟件預(yù)取是在程序中顯示地插入預(yù)取指令,以非阻塞的方式讓處理器從內(nèi)存中讀取指定地址數(shù)據(jù)至Cache。由于硬件預(yù)取器通常無法正常動態(tài)關(guān)閉,因此大部分情況下軟件預(yù)取和硬件預(yù)取是并存的,軟件預(yù)取必須盡力配合硬件預(yù)取以取得更優(yōu)的效果。本文假設(shè)硬件預(yù)取器被關(guān)閉后,討論如何利用軟件預(yù)取達到性能提升的效果。
預(yù)取指令prefech(x)只是一種提示,告知硬件開始將地址x中的數(shù)據(jù)從主存中讀取到Cache中。它并不會引起處理停頓,但若硬件發(fā)現(xiàn)會產(chǎn)生異常,則會忽略這個預(yù)取操作。如果prefech(x)成功,則意味著下一次取x將命中Cache;不成功的預(yù)取操作可能會導(dǎo)致下次讀取時發(fā)生Cache miss,但不會影響程序的正確性^[2]^。
數(shù)據(jù)預(yù)取是如何改成程序性能的呢?如下一段程序:
double a[n];
for (int i = 0; i < 100; i++)
a[i] = 0;
假設(shè)一個Cache line可以存放兩個double元素,當(dāng)?shù)谝淮卧L問a[0]時,由于a[0]不在Cache中,會發(fā)生一次Cache miss,需要從主存中將其加載至Cache中,由于一個Cache line可以存放兩個double元素,當(dāng)訪問a[1]時則不會發(fā)生Cache miss。依次類推,訪問a[2]時會發(fā)生Cache miss,訪問a[3]時不會發(fā)生Cache miss,我們很容易得到程序總共發(fā)生了50次Cache miss。
我們可以通過軟件預(yù)取等相關(guān)優(yōu)化,降低Cache miss次數(shù),提高程序性能。首先介紹一個公式^[3]^:
上述公式中L是memory latency,S是執(zhí)行一次循環(huán)迭代最短的時間。iterationAhead表示的是循環(huán)需要經(jīng)過執(zhí)行幾次迭代,預(yù)取的數(shù)據(jù)才會到達Cache。假設(shè)我們的硬件架構(gòu)計算出來的iterationAhead=6,那么原程序可以優(yōu)化成如下程序:
double a[n];
for (int i = 0; i < 12; i+=2) //prologue
prefetch(&a[i]);
for (int i = 0; i < 88; i+=2) { // steady state
prefetch(&a[i+12]);
a[i] = 0;
a[i+1] = 0;
}
for (int i = 88; i < 100; i++) //epilogue
a[i] = 0;
由于我們的硬件架構(gòu)需要循環(huán)執(zhí)行6次后,預(yù)取的數(shù)據(jù)才會到達Cache。一個Cache line可以存放兩個double元素,為了避免浪費prefetch指令,所以prologue和steady state循環(huán)都展開了,即執(zhí)行prefetch(&a[0])后會將a[0]、a[1]從主存加載至Cache中,下次執(zhí)行預(yù)取時就無需再次將a[1]從主存加載至Cache了。prologue循環(huán)先執(zhí)行數(shù)組a的前12個元素的預(yù)取指令,等到執(zhí)行steady state循環(huán)時,當(dāng)i = 0時,a[0]和a[1]已經(jīng)被加載至Cache中,就不會發(fā)生Cache miss了。依次類推,經(jīng)過上述優(yōu)化后,在不改變語義的基礎(chǔ)上,通過使用預(yù)取指令,程序的Cache miss次數(shù)從50下降至0,程序的性能將會得到很大提升。
注意,預(yù)取并不能減少從主存儲器取數(shù)據(jù)到高速緩存的延遲,只是通過預(yù)取與計算重疊而隱藏這種延遲。總之,當(dāng)處理器有預(yù)取指令或者有能夠用作預(yù)取的非阻塞的讀取指令時,對于處理器不能動態(tài)重排指令或者動態(tài)重排緩沖區(qū)小于我們希望隱藏的具體Cache延遲,并且所考慮的數(shù)據(jù)大于Cache或者是不能夠判斷數(shù)據(jù)是否已在Cache中,預(yù)取是適用的。預(yù)取也不是萬能,不當(dāng)?shù)念A(yù)取可能會導(dǎo)致高速緩存沖突,程序性能降低。我們應(yīng)該首先利用數(shù)據(jù)重用來減少延遲,然后才考慮預(yù)取。
除了軟件預(yù)取外,ARMv8還提供了Non-temporal的Load/Store指令,可以提高Cache的利用率。對于一些數(shù)據(jù),如果只是訪問一次,無需占用Cache,可以使用這個指令進行訪問,從而保護Cache中關(guān)鍵數(shù)據(jù)不被替換,比如memcpy大數(shù)據(jù)的場景下,使用該指令對于其關(guān)鍵業(yè)務(wù)而言,是有一定的收益的。
循環(huán)變換
重用Cache中的數(shù)據(jù)是最基本的高效使用Cache方法。對于多層嵌套循環(huán),可以通過交換兩個嵌套的循環(huán)(loop interchange)、逆轉(zhuǎn)循環(huán)迭代執(zhí)行的順序(loop reversal)、將兩個循環(huán)體合并成一個循環(huán)體(loop fusion)、循環(huán)拆分(loop distribution)、循環(huán)分塊(loop tiling)、loop unroll and jam等循環(huán)變換操作。選擇適當(dāng)?shù)难h(huán)變換方式,既能保持程序的語義,又能改善程序性能。我們做這些循環(huán)變換的主要目的是為了實現(xiàn)寄存器、數(shù)據(jù)高速緩存以及其他存儲層次使用方面的優(yōu)化。
篇幅受限,本節(jié)僅討論循環(huán)分塊(loop tiling)如何改善程序性能,若對loop interchange感興趣,請點擊查閱。下面這個簡單的循環(huán):
for(int i = 0; i < m; i++) {
for(int j = 0; j < n; j++) {
x = x+a[i]+c*b[j];
}
}
我們假設(shè)數(shù)組a、b都是超大數(shù)組,m、n相等且都很大,程序不會出現(xiàn)數(shù)組越界訪問情況發(fā)生。那么如果b[j]在j層循環(huán)中跨度太大時,那么被下次i層循環(huán)重用時數(shù)據(jù)已經(jīng)被清出高速緩存。即程序訪問b[n-1]時,b[0]、b[1]已經(jīng)被清出緩存,此時需要重新從主存中將數(shù)據(jù)加載至緩存中,程序性能會大幅下降。
我們?nèi)绾瓮ㄟ^降低Cache miss次數(shù)提升程序的性能呢?通過對循環(huán)做loop tiling可以符合我們的期望,即通過循環(huán)重排,使得數(shù)據(jù)分成一個一個tile,讓每一個tile的數(shù)據(jù)都可以在Cache中被hint^[4]^。從內(nèi)層循環(huán)開始tiling,假設(shè)tile的大小為t,t遠小于m、n,t的取值使得b[t-1]被訪問時b[0]依然在Cache中,將會大幅地減少Cache miss次數(shù)。假設(shè)n-1恰好被t整除,此時b數(shù)組的訪問順序如下所示:
i=1; b[0]、b[1]、b[2]...b[t-1]
i=2; b[0]、b[1]、b[2]...b[t-1]
...
i=n; b[0]、b[1]、b[2]...b[t-1]
...
...
...
i=1; b[n-t]、b[n-t-1]、b[n-t-2]...b[n-1]
i=2; b[n-t]、b[n-t-1]、b[n-t-2]...b[n-1]
...
i=n; b[n-t]、b[n-t-1]、b[n-t-2]...b[n-1]
經(jīng)過loop tiling后循環(huán)變換成:
for(int j = 0; j < n; j+=t) {
for(int i = 0; i < m; i++) {
for(int jj = j; jj < min(j+t, n); jj++) {
x = x+a[i]+c*b[jj];
}
}
}
假設(shè)每個Cache line能夠容納X個數(shù)組元素,loop tiling前a的Cache miss次數(shù)為m/X,b的Cache miss次數(shù)是m*n/X,總的Cache miss次數(shù)為m*(n+1)/x。loop tiling后a的Cache miss次數(shù)為(n/t)*(m/X),b的Cache miss次數(shù)為(t/X)*(n/t)=n/X,總的Cache miss次數(shù)為n*(m+t)/xt。此時,由于n與m相等,那么loop tiling后Cache miss大約可以降低t倍^[4]^。
前文討論了loop tiling在小用例上如何提升程序性能,總之針對不同的循環(huán)場景,選擇合適的循環(huán)交換方法,既能保證程序語義正確, 又能獲得改善程序性能的機會。
小結(jié)
汝之蜜糖,彼之砒霜。針對不同的硬件,我們需要結(jié)合具體的硬件架構(gòu),利用性能分析工具,通過分析報告和程序,從系統(tǒng)層次和算法層次思考問題,往往會有意想不到的收獲。本文簡單地介紹了內(nèi)存層次優(yōu)化相關(guān)的幾種方法,結(jié)合一些小例子深入淺出地講解了一些內(nèi)存層次優(yōu)化相關(guān)的知識。紙上得來終覺淺,絕知此事要躬行,更多性能優(yōu)化相關(guān)的知識需要我們從實踐中慢慢摸索。
-
處理器
+關(guān)注
關(guān)注
68文章
19396瀏覽量
230709 -
存儲器
+關(guān)注
關(guān)注
38文章
7525瀏覽量
164159 -
編譯器
+關(guān)注
關(guān)注
1文章
1642瀏覽量
49227 -
cache技術(shù)
+關(guān)注
關(guān)注
0文章
41瀏覽量
1075
發(fā)布評論請先 登錄
相關(guān)推薦
如何編寫有利于編譯器優(yōu)化的代碼
SIMD計算機的優(yōu)化編譯器設(shè)計
C編譯器及其優(yōu)化
編譯器是如何工作的_編譯器的工作過程詳解
編譯器優(yōu)化對函數(shù)的影響

交叉編譯器安裝教程
深度學(xué)習(xí)編譯器之Layerout Transform優(yōu)化
編譯器的優(yōu)化選項
Keil編譯器優(yōu)化方法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論