 OpenAI最新突破性進展:語言模型可以解釋語言模型中的神經元
OpenAI最新突破性進展:語言模型可以解釋語言模型中的神經元
大家好,我是zenRRan。
OpenAI在昨天發布了一篇論文:《Language models can explain neurons in language models》,可謂是深度學習可解釋性又向前邁了一大步!誰又能想到,使用GPT-4來解釋模型的可解釋性,用魔法打敗魔法,666。

大致內容
使用 GPT-4 自動編寫大型語言模型中神經元行為的解釋,并對這些解釋進行打分,并為 GPT-2 中的每個神經元發布了這些(不完美的)解釋和分數的數據集。
介紹一下
語言模型變得更強大,部署更廣泛,但我們對它們內部工作原理的理解仍然非常有限。例如,可能很難從它們的輸出中檢測到它們是使用有偏見的啟發式方法還是進行胡編亂造。可解釋性研究旨在通過查看模型內部來發現更多信息。
可解釋性研究的一種簡單方法是首先了解各個組件(神經元和注意力頭)在做什么。傳統上,這需要人類手動檢查神經元,以確定它們代表數據的哪些特征。這個過程不能很好地擴展:很難將它應用于具有數百或數千億個參數的神經網絡。OpenAI提出了一個自動化過程,該過程使用 GPT-4 來生成神經元行為的自然語言解釋并對其進行評分,并將其應用于另一種語言模型中的神經元。
這項工作是對齊研究方法的第三個支柱的一部分:希望使對齊研究工作本身自動化。這種方法的一個有前途的方面是它可以隨著人工智能發展的步伐而擴展。隨著未來的模型作為助手變得越來越智能和有用,我們會找到更好的解釋。
具體如何工作的呢
他們的方法包括在每個神經元上運行 3 個步驟。
第 1 步:使用 GPT-4 生成解釋
給定一個 GPT-2 神經元,通過向 GPT-4 顯示相關文本序列和激活來生成對其行為的解釋。
OpenAI一共舉了12個例子,這里我就隨便拿出幾個代表性的吧。

漫威漫畫的氛圍
模型生成的解釋:參考自電影、角色和娛樂。

similes,相似
模型生成的解釋:比較和類比,常用“喜歡(like)”這個詞。
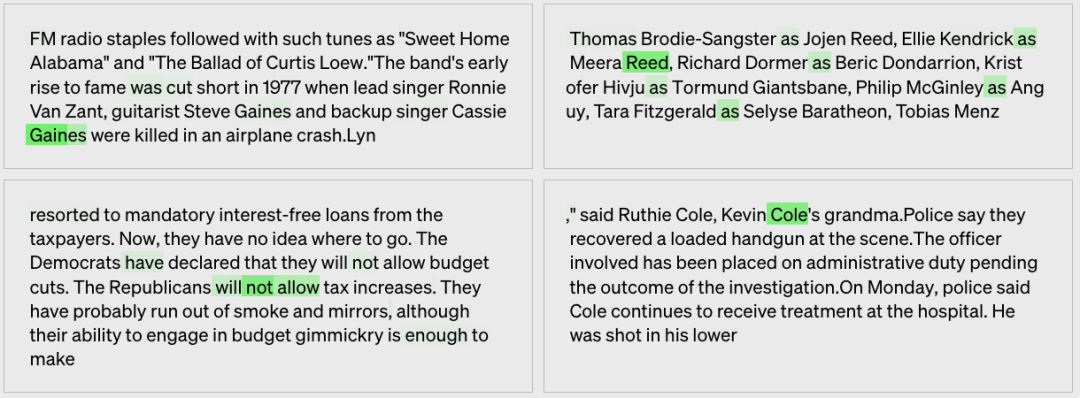
shared last names,姓氏
模型生成的解釋:姓氏,它們一般跟在名字后面。
第 2 步:使用 GPT-4 進行模擬
再次使用 GPT-4 模擬為解釋而激活的神經元會做什么。

漫威漫畫的氛圍
第 3 步:比較
根據模擬激活與真實激活的匹配程度對解釋進行評分
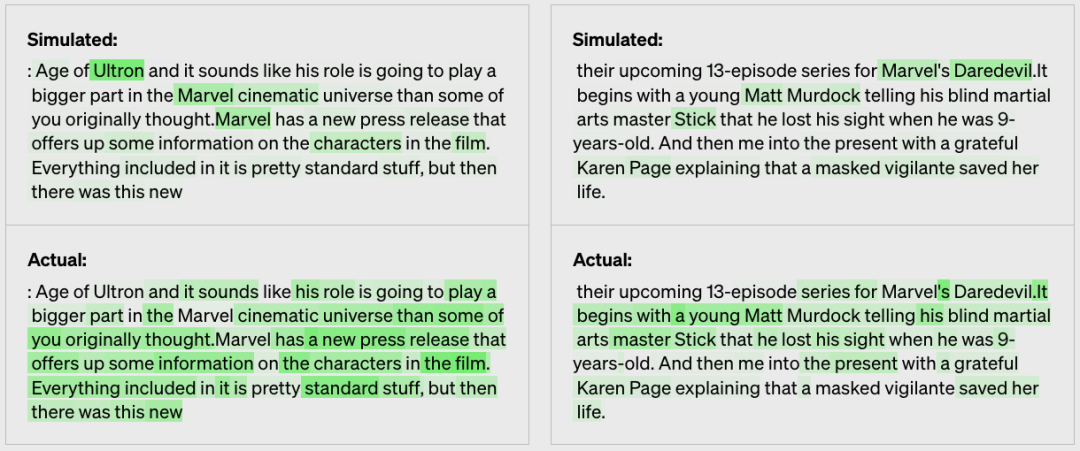
舉例:漫威漫畫的氛圍
舉例:漫威漫畫的氛圍
最終得出比較的分數為:0.34
發現了什么
使用OpenAI自己的評分方法,可以開始衡量技術對網絡不同部分的工作情況,并嘗試改進目前解釋不力的部分的技術。例如,我們的技術對于較大的模型效果不佳,可能是因為后面的層更難解釋。
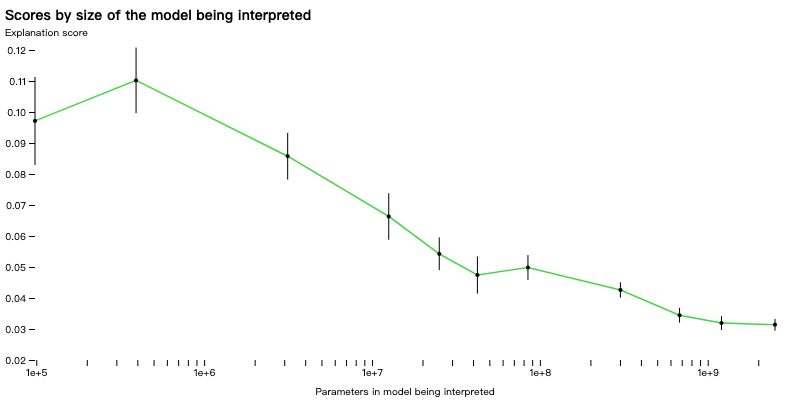
正在解釋的模型中的參數量
盡管我們的絕大多數解釋得分很低,但我們相信我們現在可以使用 ML 技術來進一步提高我們產生解釋的能力。例如,我們發現我們可以通過以下方式提高分數:
迭代解釋。我們可以通過要求 GPT-4 提出可能的反例,然后根據它們的激活修改解釋來提高分數。
使用更大的模型來給出解釋。隨著解釋器模型能力的提高,平均分數也會上升。然而,即使是 GPT-4 也給出了比人類更差的解釋,這表明還有改進的余地。
更改已解釋模型的架構。具有不同激活函數的訓練模型提高了解釋分數。
我們正在開源我們的數據集和可視化工具,用于 GPT-4 對 GPT-2 中所有 307,200 個神經元的書面解釋,以及使用 OpenAI API 上公開可用的模型[1]進行解釋和評分的代碼。我們希望研究界能夠開發新技術來生成更高分的解釋,并開發更好的工具來使用解釋來探索 GPT-2。
我們發現超過 1,000 個神經元的解釋得分至少為 0.8,這意味著根據 GPT-4,它們解釋了神經元的大部分頂級激活行為。大多數這些很好解釋的神經元都不是很有趣。然而,也發現了許多 GPT-4 不理解的有趣神經元。希望隨著解釋的改進,能夠快速發現對模型計算的有趣的定性理解。
神經元跨層激活,更高的層更抽象:

以Kat舉例
展望
我們的方法目前有很多局限性[2],我們希望在未來的工作中能夠解決這些問題。
我們專注于簡短的自然語言解釋,但神經元可能具有非常復雜的行為,無法簡潔地描述。例如,神經元可以是高度多義的(代表許多不同的概念),或者可以代表人類不理解或無法用語言表達的單一概念。
我們希望最終自動找到并解釋實現復雜行為的整個神經回路,神經元和注意力頭一起工作。我們當前的方法僅將神經元行為解釋為原始文本輸入的函數,而沒有說明其下游影響。例如,一個在句號上激活的神經元可以指示下一個單詞應該以大寫字母開頭,或者遞增一個句子計數器。
我們解釋了神經元的行為,但沒有試圖解釋產生這種行為的機制。這意味著即使是高分解釋也可能在分布外的文本上表現很差,因為它們只是描述了相關性。
我們的整個過程是計算密集型的。
我們對我們方法的擴展和推廣感到興奮。最終,我們希望使用模型來形成、測試和迭代完全通用的假設,就像可解釋性研究人員所做的那樣。
最終,OpenAI希望將最大的模型解釋為一種在部署前后檢測對齊和安全問題的方法。然而,在這些技術能夠使不誠實等行為浮出水面之前,我們還有很長的路要走。
審核編輯 :李倩
-
神經元
+關注
關注
1文章
363瀏覽量
18487 -
語言模型
+關注
關注
0文章
536瀏覽量
10311 -
OpenAI
+關注
關注
9文章
1116瀏覽量
6625
原文標題:OpenAI最新突破性進展:語言模型可以解釋語言模型中的神經元
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
【《大語言模型應用指南》閱讀體驗】+ 基礎篇
人工神經元模型的基本構成要素
人工神經元模型的基本原理是什么
人工神經元模型由哪兩部分組成
人工神經元模型的基本原理及應用
人工神經元模型的三要素是什么
基于神經網絡的語言模型有哪些
名單公布!【書籍評測活動NO.34】大語言模型應用指南:以ChatGPT為起點,從入門到精通的AI實踐教程
【大語言模型:原理與工程實踐】大語言模型的應用
【大語言模型:原理與工程實踐】核心技術綜述
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
大語言模型(LLMs)如何處理多語言輸入問題






 工商網監
工商網監
評論