 看看使用芯片驗證隨機帶來的六宗罪
看看使用芯片驗證隨機帶來的六宗罪
以前看到不少驗證技術書籍都在說驗證環境中隨機怎么怎么好,然后為了隨機,UVM,SV 提供了什么什么支持。
但是最近的一些工作小編發現在驗證中采用隨機存在很多缺點。下面小編帶大家看看使用隨機帶來的六宗罪。
第一宗罪:難以debug
出現fail的test,當debug完,對設計和驗證環境做了改動,可能無法復現fail的場景。
如何確保發現的testbench的問題,或者RTL的問題有真的修掉?一般的做法是用同樣的seed,然后跑一遍之前的fail的test。但是有很多時候,由于環境的文件,約束等改變,再用同樣的seed 跑fail 的test 和之前的行為不一致,從而錯誤的認為問題已經修掉。
第二宗罪:難以覆蓋到特定場景
有些場景通過隨機撞到的概率非常低。
如下圖所示,C=A &&B,在下圖場景中想通過 隨機到 (A==1)&&(B==1)的 場景,非常難。
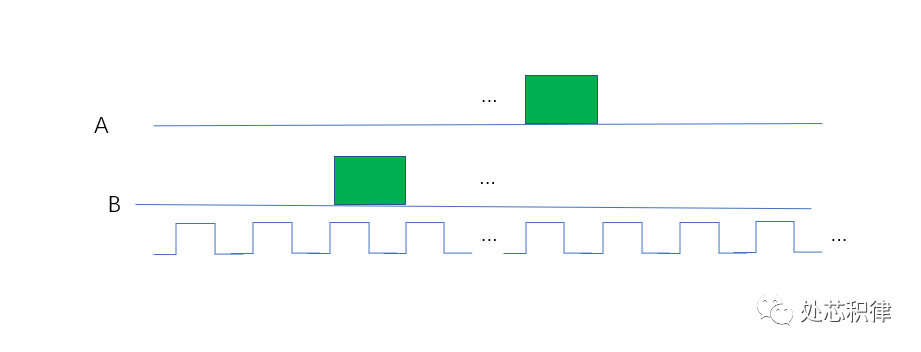
第三宗罪:驗證時間不確定
回歸結果不可靠。一次通過率100%,不代表次次回歸100%。
一次回歸可能100%,第二次回歸又變成90%。連續10次回歸100%,第十一次回歸又出現fail的test。
第四宗罪:重復測試用例很多
浪費太多license 和服務器資源。
因為單次regression不能保證沒有問題,所以要周周跑,月月跑,一直跑到tapout,這浪費了很多license和服務器資源。特別是有些test 打到的場景重復,做一些無效驗證,給公司資源造成極大浪費。
第五宗罪:覆蓋率收集耗費資源
coverage 收斂比較耗時間和資源。
由于隨機約束造成不同場景出現的概率不一樣,通過隨機測試將代碼覆蓋率和功能覆蓋率補全需要經過大量的回歸測試。coverage的收斂速度沒有直接測試來得快。
下面是一個案例,在跑完一版regression后,功能覆蓋率是80.49%。
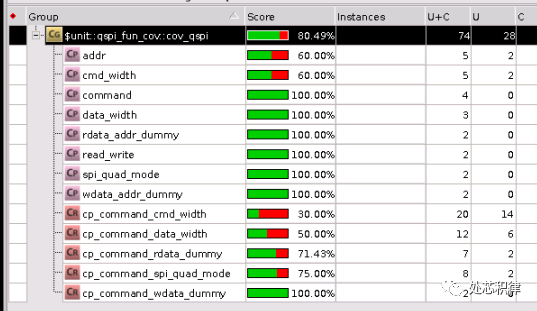
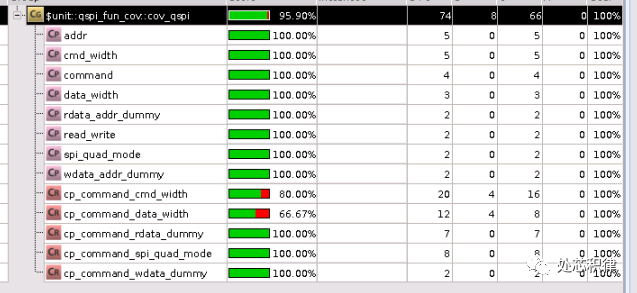
我們想將該功能覆蓋率補全,采用直接測試用例,我們調用了5次測試,可以將覆蓋率打到95.90% ,剩下的部分可以waive掉。
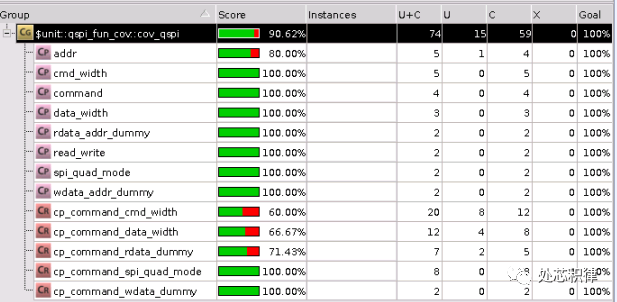
當我們采用隨機測試,調用了5次隨機測試,覆蓋率為90.62%。
當我們采用隨機測試,調用了10次隨機測試,覆蓋率為93.97%。
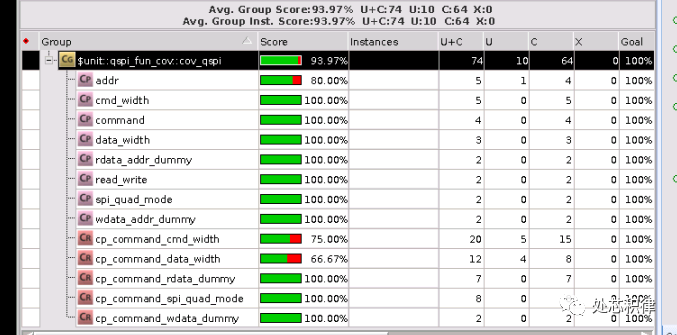
當我們采用隨機測試,調用了20次隨機測試,覆蓋率為95.90%,達到了和直接測試同樣的效果。
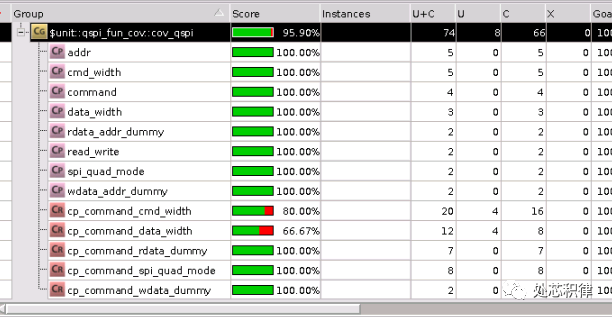
第六宗罪:場景打不全
隨機驗證打不全所有場景
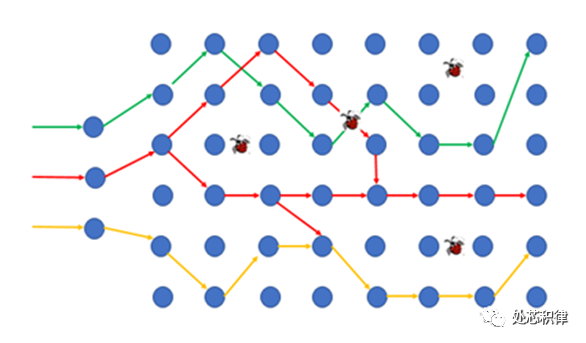
如上圖所示,隨機的行為很難將所有的測試路徑都打到。
隨機有沒有好處呢?當然有,比如
探索更多的場景:隨機驗證可以探索更多的測試場景,覆蓋更多的狀態空間。這可以幫助發現設計中的潛在問題和漏洞,從而提高驗證的質量。
發現意外錯誤:隨機測試可以揭示一些設計者未曾考慮的異常情況,以及在正常測試中可能被忽略的邊緣情況。這有助于找到并修復一些潛在的設計錯誤。
減少人為偏見:手動創建測試用例可能受到驗證工程師的認知偏見和經驗限制的影響。隨機驗證方法可以降低這種偏見對驗證結果的影響,從而提高驗證的可靠性。
減少人工編寫測試用例的時間和精力:隨機驗證方法可以自動生成大量測試用例,從而減少人工編寫測試用例的時間和精力。這有助于縮短驗證周期,提高驗證效率。
更好地應對復雜性:隨著芯片設計變得越來越復雜,人工創建足夠多的測試用例以覆蓋所有可能的場景變得越來越困難。隨機驗證方法可以在面對復雜設計時自動生成更多的測試用例,從而更好地應對這種復雜性。
雖然使用隨機驗證存在很多問題,但它在許多情況下仍然是一種非常有效的驗證方法。為了克服這些缺點,可以將隨機驗證與其他驗證方法(如指導性驗證、形式驗證等)相結合,以實現更全面、有效的芯片驗證。
審核編輯:劉清
-
RTL
+關注
關注
1文章
385瀏覽量
59897 -
UVM
+關注
關注
0文章
182瀏覽量
19205
原文標題:芯片驗證隨機(random)的六宗罪
文章出處:【微信號:處芯積律,微信公眾號:處芯積律】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
關于功能驗證、時序驗證、形式驗證、時序建模的論文
【云智易試用體驗】開箱與初評六宗罪
怎么設計基于USB和FPGA的隨機數發生器驗證平臺?
設計驗證中的隨機約束
選購低價筆記本:不得不說的五宗罪
基于OVM驗證平臺的IP芯片驗證
基于System Verilog的可重用驗證平臺設計及驗證結果分析






 工商網監
工商網監
評論