") 基于擴(kuò)散模型的視頻合成新模型,加特效杠杠的!
基于擴(kuò)散模型的視頻合成新模型,加特效杠杠的!
從文本生成圖像,再到給視頻加特效,下一個(gè) AIGC 爆發(fā)點(diǎn)要出現(xiàn)了嗎?
相信很多人已經(jīng)領(lǐng)會(huì)過生成式 AI 技術(shù)的魅力,特別是在經(jīng)歷了 2022 年的 AIGC 爆發(fā)之后。以 Stable Diffusion 為代表的文本到圖像生成技術(shù)一度風(fēng)靡全球,無數(shù)用戶涌入,借助 AI 之筆表達(dá)自己的藝術(shù)想象……
相比于圖像編輯,視頻編輯是一個(gè)更具有挑戰(zhàn)性的議題,它需要合成新的動(dòng)作,而不僅僅是修改視覺外觀,此外還需要保持時(shí)間上的一致性。
在這條賽道上探索的公司也不少。前段時(shí)間,谷歌發(fā)布的 Dreamix 以將文本條件視頻擴(kuò)散模型(video diffusion model, VDM)應(yīng)用于視頻編輯。
近日,曾參與創(chuàng)建 Stable Diffusion 的 Runway 公司推出了一個(gè)新的人工智能模型「Gen-1」,該模型通過應(yīng)用文本 prompt 或參考圖像指定的任何風(fēng)格,可將現(xiàn)有視頻轉(zhuǎn)化為新視頻。

論文鏈接:https://arxiv.org/pdf/2302.03011
項(xiàng)目主頁(yè):https://research.runwayml.com/gen1
2021 年,Runway 與慕尼黑大學(xué)的研究人員合作,建立了 Stable Diffusion 的第一個(gè)版本。隨后英國(guó)的一家初創(chuàng)公司 Stability AI 介入,資助了在更多數(shù)據(jù)上訓(xùn)練模型所需的計(jì)算費(fèi)用。2022 年,Stability AI 將 Stable Diffusion 納入主流,將其從一個(gè)研究項(xiàng)目轉(zhuǎn)變?yōu)橐粋€(gè)全球現(xiàn)象。
Runway 表示,希望 Gen-1 能像 Stable Diffusion 在圖像上所做的那樣為視頻服務(wù)。
「我們已經(jīng)看到圖像生成模型的大爆炸,」Runway 首席執(zhí)行官兼聯(lián)合創(chuàng)始人 Cristóbal Valenzuela 說。「我真的相信,2023 年將是視頻之年。」
具體來說,Gen-1 支持幾種編輯模式:
1、風(fēng)格化。將任何圖像或 prompt 的風(fēng)格轉(zhuǎn)移到視頻的每一幀。
2、故事板。將模型變成完全風(fēng)格化和動(dòng)畫的渲染。
3、遮罩。分離視頻中的主題并使用簡(jiǎn)單的文本 prompt 對(duì)其進(jìn)行修改。
4、渲染。通過應(yīng)用輸入圖像或 prompt,將無紋理渲染變成逼真的輸出。
5、定制化。通過自定義模型以獲得更高保真度的結(jié)果,釋放 Gen-1 的全部功能。
在該公司官方網(wǎng)站上發(fā)布的 demo 中,展示了 Gen-1 如何絲滑地更改視頻風(fēng)格,來看幾個(gè)示例。
比如將「街道上的人」變成「粘土木偶」,只需要一行 prompt:

或者將「堆放在桌上的書」變成「夜晚的城市景觀」:

從「雪地上的奔跑」到「月球漫步」:

年輕女孩,竟然秒變古代先哲:

論文細(xì)節(jié)
視覺特效和視頻編輯在當(dāng)代媒體領(lǐng)域無處不在。隨著以視頻為中心的平臺(tái)的普及,對(duì)更直觀、性能更強(qiáng)的視頻編輯工具的需求也在增加。然而,由于視頻數(shù)據(jù)的時(shí)間性,在這種格式下的編輯仍然是復(fù)雜和耗時(shí)的。最先進(jìn)的機(jī)器學(xué)習(xí)模型在改善編輯過程方面顯示出了巨大的前景,但很多方法不得不在時(shí)間一致性和空間細(xì)節(jié)之間取得平衡。
由于引入了在大規(guī)模數(shù)據(jù)集上訓(xùn)練的擴(kuò)散模型,用于圖像合成的生成方法最近在質(zhì)量和受歡迎程度上經(jīng)歷了一個(gè)快速增長(zhǎng)階段。一些文本條件模型,如 DALL-E 2 和 Stable Diffusion,使新手只需輸入一個(gè)文本 prompt 就能生成詳細(xì)的圖像。潛在擴(kuò)散模型提供了有效的方法,通過在感知壓縮的空間中進(jìn)行合成來生成圖像。
在本論文中,研究者提出了一個(gè)可控的結(jié)構(gòu)和內(nèi)容感知的視頻擴(kuò)散模型,該模型是在未加字幕的視頻和配對(duì)的文本 - 圖像數(shù)據(jù)的大規(guī)模數(shù)據(jù)集上訓(xùn)練的。研究者選擇用單目深度估計(jì)來表征結(jié)構(gòu),用預(yù)訓(xùn)練的神經(jīng)網(wǎng)絡(luò)預(yù)測(cè)的嵌入來表征內(nèi)容。
該方法在其生成過程中提供了幾種強(qiáng)大的控制模式:首先,與圖像合成模型類似,研究者訓(xùn)練模型使推斷出的視頻內(nèi)容,如其外觀或風(fēng)格,與用戶提供的圖像或文本 prompt 相匹配(圖 1)。其次,受擴(kuò)散過程的啟發(fā),研究者對(duì)結(jié)構(gòu)表征應(yīng)用了一個(gè)信息掩蔽過程,以便能夠選擇模型對(duì)給定結(jié)構(gòu)的支持程度。最后,研究者通過一個(gè)自定義的指導(dǎo)方法來調(diào)整推理過程,該方法受到無分類指導(dǎo)的啟發(fā),以實(shí)現(xiàn)對(duì)生成片段的時(shí)間一致性的控制。

總體來說,本研究的亮點(diǎn)如下:
通過在預(yù)訓(xùn)練圖像模型中引入時(shí)間層,并在圖像和視頻上進(jìn)行聯(lián)合訓(xùn)練,將潛在擴(kuò)散模型擴(kuò)展到了視頻生成領(lǐng)域;
提出了一個(gè)結(jié)構(gòu)和內(nèi)容感知的模型,在樣本圖像或文本的指導(dǎo)下修改視頻。編輯工作完全是在推理時(shí)間內(nèi)進(jìn)行的,不需要額外對(duì)每個(gè)視頻進(jìn)行訓(xùn)練或預(yù)處理;
展示了對(duì)時(shí)間、內(nèi)容和結(jié)構(gòu)一致性的完全控制。該研究首次表明,對(duì)圖像和視頻數(shù)據(jù)的聯(lián)合訓(xùn)練能夠讓推理時(shí)間控制時(shí)間的一致性。對(duì)于結(jié)構(gòu)的一致性,在表征中不同的細(xì)節(jié)水平上進(jìn)行訓(xùn)練,可以在推理過程中選擇所需的設(shè)置;
在一項(xiàng)用戶研究中,本文的方法比其他幾種方法更受歡迎;
通過對(duì)一小部分圖像進(jìn)行微調(diào),可以進(jìn)一步定制訓(xùn)練過的模型,以生成更準(zhǔn)確的特定主體的視頻。
方法
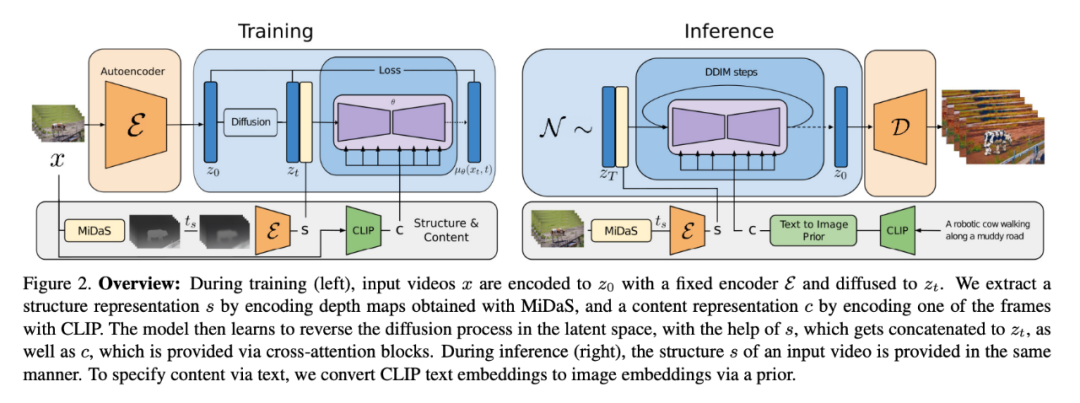
就研究目的而言,從內(nèi)容和結(jié)構(gòu)的角度來考慮一個(gè)視頻將是有幫助的。對(duì)于結(jié)構(gòu),此處指的是描述其幾何和動(dòng)態(tài)的特征,比如主體的形狀和位置,以及它們的時(shí)間變化。對(duì)于內(nèi)容,此處將其定義為描述視頻的外觀和語(yǔ)義的特征,比如物體的顏色和風(fēng)格以及場(chǎng)景的照明。Gen-1 模型的目標(biāo)是編輯視頻的內(nèi)容,同時(shí)保留其結(jié)構(gòu)。
為了實(shí)現(xiàn)這一目標(biāo),研究者學(xué)習(xí)了視頻 x 的生成模型 p (x|s, c),其條件是結(jié)構(gòu)表征(用 s 表示)和內(nèi)容表征(用 c 表示)。他們從輸入視頻推斷出形狀表征 s,并根據(jù)描述編輯的文本 prompt c 對(duì)其進(jìn)行修改。首先,描述了對(duì)生成模型的實(shí)現(xiàn),作為一個(gè)條件潛在的視頻擴(kuò)散模型,然后,描述了對(duì)形狀和內(nèi)容表征的選擇。最后,討論了模型的優(yōu)化過程。
模型結(jié)構(gòu)如圖 2 所示。
實(shí)驗(yàn)
為了評(píng)估該方法,研究者采用了 DAVIS 的視頻和各種素材。為了自動(dòng)創(chuàng)建編輯 prompt,研究者首先運(yùn)行了一個(gè)字幕模型來獲得原始視頻內(nèi)容的描述,然后使用 GPT-3 來生成編輯 prompt。
定性研究
如圖 5 所示,結(jié)果證明,本文的方法在一些不同的輸入上表現(xiàn)良好。

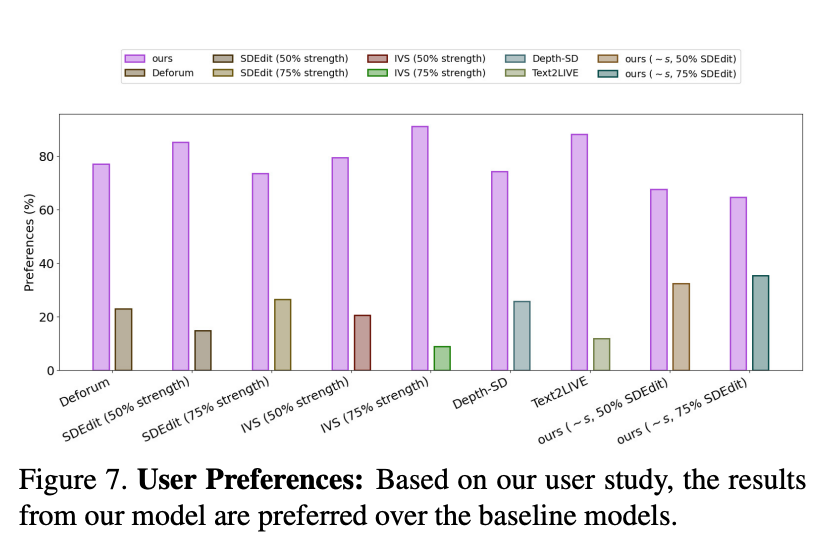
用戶研究
研究者還使用 Amazon Mechanical Turk(AMT)對(duì) 35 個(gè)有代表性的視頻編輯 prompt 的評(píng)估集進(jìn)行了用戶研究。對(duì)于每個(gè)樣本,均要求 5 個(gè)注解者在基線方法和本文方法之間對(duì)比對(duì)視頻編輯 prompt 的忠實(shí)度(「哪個(gè)視頻更好地代表了所提供的編輯過的字幕?」),然后以隨機(jī)順序呈現(xiàn),并使用多數(shù)票來決定最終結(jié)果。
結(jié)果如圖 7 所示:
定量評(píng)估
圖 6 展示了每個(gè)模型使用本文框架一致性和 prompt 一致性指標(biāo)的結(jié)果。本文模型在這兩方面的表現(xiàn)都傾向于超越基線模型(即,在圖的右上角位置較高)。研究者還注意到,在基線模型中增加強(qiáng)度參數(shù)會(huì)有輕微的 tradeoff:更大的強(qiáng)度縮放意味著更高的 prompt 一致性,代價(jià)是更低的框架一致性。同時(shí)他們還觀察到,增加結(jié)構(gòu)縮放會(huì)導(dǎo)致更高的 prompt 一致性,因?yàn)閮?nèi)容變得不再由輸入結(jié)構(gòu)決定。
定制化
圖 10 展示了一個(gè)具有不同數(shù)量的定制步驟和不同水平的結(jié)構(gòu)依附性 ts 的例子。研究者觀察到,定制化提高了對(duì)人物風(fēng)格和外觀的保真度,因此,盡管使用具有不同特征的人物的驅(qū)動(dòng)視頻,但結(jié)合較高的 ts 值,還是可以實(shí)現(xiàn)精確的動(dòng)畫效果。

審核編輯 :李倩
-
模型
+關(guān)注
關(guān)注
1文章
3298瀏覽量
49065 -
圖像生成
+關(guān)注
關(guān)注
0文章
22瀏覽量
6902
原文標(biāo)題:Stable Diffusion公司新作Gen-1:基于擴(kuò)散模型的視頻合成新模型,加特效杠杠的!
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于擴(kuò)散模型的圖像生成過程

如何在PyTorch中使用擴(kuò)散模型生成圖像

諧波加噪聲激勵(lì)模型的語(yǔ)音合成算法
擴(kuò)散模型在視頻領(lǐng)域表現(xiàn)如何?
如何改進(jìn)和加速擴(kuò)散模型采樣的方法1
如何改進(jìn)和加速擴(kuò)散模型采樣的方法2
蒸餾無分類器指導(dǎo)擴(kuò)散模型的方法
英偉達(dá)發(fā)布視頻AI大模型論文,自動(dòng)駕駛是其潛在應(yīng)用領(lǐng)域

基于文本到圖像模型的可控文本到視頻生成

基于DiAD擴(kuò)散模型的多類異常檢測(cè)工作

谷歌推出AI擴(kuò)散模型Lumiere
谷歌模型合成軟件有哪些
擴(kuò)散模型的理論基礎(chǔ)

基于移動(dòng)自回歸的時(shí)序擴(kuò)散預(yù)測(cè)模型





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論