 電子發(fā)燒友App
電子發(fā)燒友App


本文中,我們將研究擴(kuò)散模型的理論基礎(chǔ),然后演示如何在PyTorch中使用擴(kuò)散模型生成圖像。 ? 擴(kuò)散模型的迅速崛起是機(jī)器學(xué)習(xí)在過(guò)去幾年中最大的發(fā)展之一。在這篇文章中,你能了解到關(guān)于擴(kuò)散模型的一切。 ? ? ?
擴(kuò)散模型是生成模型,在過(guò)去的幾年里已經(jīng)獲得了顯著的普及。僅在21世紀(jì)20年代發(fā)表的幾篇開(kāi)創(chuàng)性論文就向世界展示了擴(kuò)散模型的能力,比如在圖像合成方面擊敗GANs。以及DALL-E 2,OpenAI的圖像生成模型的發(fā)布。 ? ?
? ? 鑒于擴(kuò)散模型最近的成功浪潮,許多機(jī)器學(xué)習(xí)從業(yè)者肯定對(duì)它們的內(nèi)部工作原理感興趣。在本文中,我們將研究擴(kuò)散模型的理論基礎(chǔ),然后演示如何在PyTorch中使用擴(kuò)散模型生成圖像。??
介紹
擴(kuò)散模型是生成模型,這意味著它們用于生成與訓(xùn)練數(shù)據(jù)相似的數(shù)據(jù)。從根本上講,擴(kuò)散模型的工作原理是通過(guò)連續(xù)添加高斯噪聲破壞訓(xùn)練數(shù)據(jù),然后通過(guò)學(xué)習(xí)反轉(zhuǎn)這個(gè)噪聲過(guò)程來(lái)恢復(fù)數(shù)據(jù)。訓(xùn)練后,我們可以使用擴(kuò)散模型通過(guò)簡(jiǎn)單地通過(guò)學(xué)習(xí)的去噪過(guò)程傳遞隨機(jī)采樣的噪聲來(lái)生成數(shù)據(jù)。
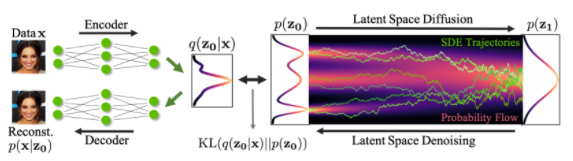
更具體地說(shuō),擴(kuò)散模型是一種潛變量模型,它使用固定的馬爾可夫鏈映射到潛在空間。該鏈逐步向數(shù)據(jù)中添加噪聲,以獲得近似后驗(yàn)值,其中為與x0具有相同維數(shù)的潛變量。在下面的圖中,我們可以看到這樣一個(gè)馬爾可夫鏈。

最后,圖像逐漸變?yōu)榧兏咚乖肼暋S?xùn)練擴(kuò)散模型的目標(biāo)是學(xué)習(xí)逆向過(guò)程,即訓(xùn)練。通過(guò)沿著這條鏈向后遍歷,我們可以生成新的數(shù)據(jù)。
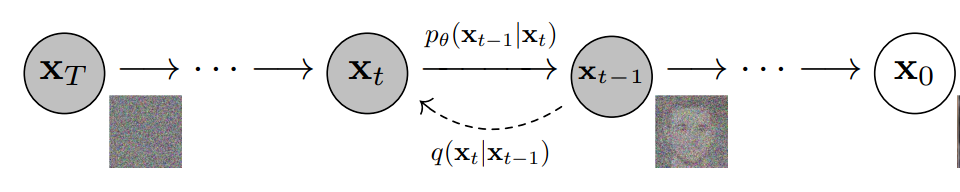
擴(kuò)散模型的優(yōu)點(diǎn)
如上所述,對(duì)擴(kuò)散模型的研究近年來(lái)呈爆炸式增長(zhǎng)。受非平衡熱力學(xué)的啟發(fā),擴(kuò)散模型目前可以生成State-of-the-Art 的圖像質(zhì)量。
除了頂尖的圖像質(zhì)量,擴(kuò)散模型還帶來(lái)了許多其他好處,包括不需要對(duì)抗性訓(xùn)練。對(duì)抗訓(xùn)練的困難是有據(jù)可查的。在訓(xùn)練效率的話題上,擴(kuò)散模型還具有可伸縮性和并行性的額外好處。
雖然擴(kuò)散模型似乎是憑空產(chǎn)生的結(jié)果,但有很多仔細(xì)和有趣的數(shù)學(xué)選擇和細(xì)節(jié)為這些結(jié)果提供了基礎(chǔ),并且最佳實(shí)踐仍在文獻(xiàn)中不斷發(fā)展。現(xiàn)在讓我們更詳細(xì)地看看支撐擴(kuò)散模型的數(shù)學(xué)理論。
擴(kuò)散模型——深入
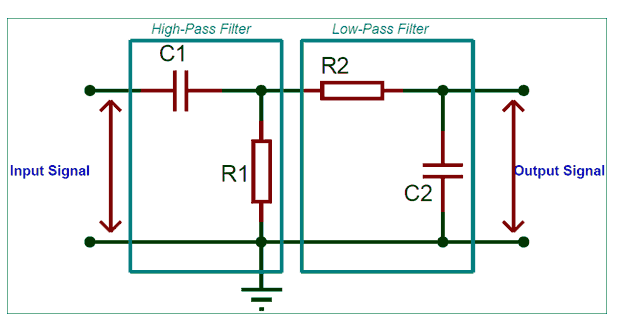
如上所述,擴(kuò)散模型由正向過(guò)程(或擴(kuò)散過(guò)程)和反向過(guò)程(或反向擴(kuò)散過(guò)程)組成,前者是對(duì)數(shù)據(jù)(通常是圖像)進(jìn)行逐步噪聲化,后者是將噪聲從目標(biāo)分布轉(zhuǎn)化回樣本。
當(dāng)噪聲水平足夠低時(shí),正向過(guò)程中的采樣鏈轉(zhuǎn)換可以設(shè)置為條件高斯。將這與馬爾可夫假設(shè)結(jié)合起來(lái),就得到了正向過(guò)程的簡(jiǎn)單參數(shù)化:
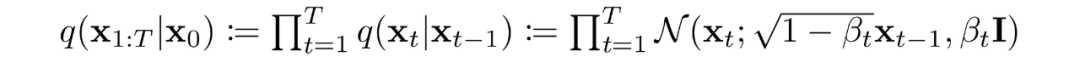
是一個(gè)方差策略(學(xué)習(xí)的或固定的),如果表現(xiàn)良好,確保對(duì)于足夠大的T,幾乎是一個(gè)各向同性的高斯噪聲。

在馬爾可夫假設(shè)下,潛變量的聯(lián)合分布是高斯條件鏈變換的乘積 ?
如前所述,擴(kuò)散模型的“魔力”來(lái)自于反向過(guò)程。在訓(xùn)練過(guò)程中,模型學(xué)習(xí)這個(gè)擴(kuò)散過(guò)程的反轉(zhuǎn),以生成新的數(shù)據(jù)。從純高斯噪聲開(kāi)始,模型學(xué)習(xí)聯(lián)合分布為:
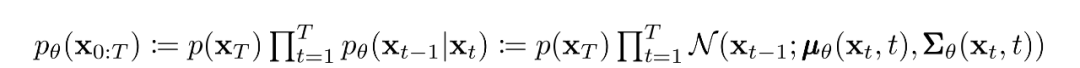
其中高斯變換的隨時(shí)間變化的參數(shù)被學(xué)習(xí)到。特別要注意的是,馬爾可夫公式斷言,給定的反向擴(kuò)散變換分布只依賴于前一個(gè)時(shí)間步(或下一個(gè)時(shí)間步,取決于你如何看待它):
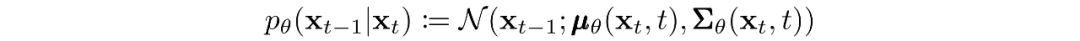
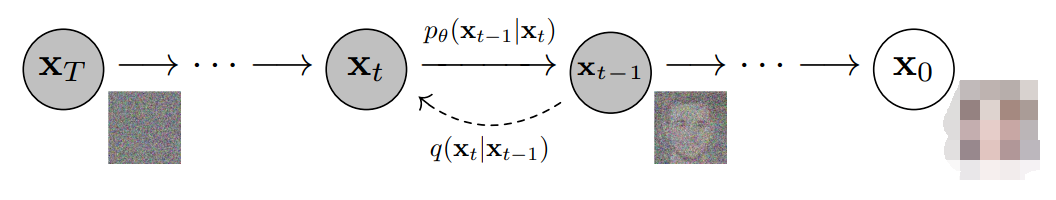
訓(xùn)練
擴(kuò)散模型通過(guò)尋找反向馬爾可夫變換來(lái)訓(xùn)練,使訓(xùn)練數(shù)據(jù)的似然性最大化。在實(shí)踐中,訓(xùn)練等價(jià)于最小化負(fù)對(duì)數(shù)似然的變分上界。
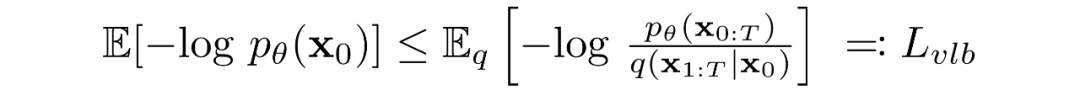
我們?cè)噲D根據(jù)?Kullback-Leibler (KL) Divergences?重寫(xiě)。KL 散度是一種不對(duì)稱統(tǒng)計(jì)距離度量,衡量一個(gè)概率分布 P 與參考分布 Q 的差異程度。我們感興趣的是根據(jù) KL 散度來(lái)重寫(xiě),因?yàn)槲覀兊鸟R爾可夫鏈中的過(guò)渡分布是高斯分布,并且高斯分布之間的 KL散度具有封閉形式。
什么是KL散度?
連續(xù)分布的KL散度的數(shù)學(xué)形式:
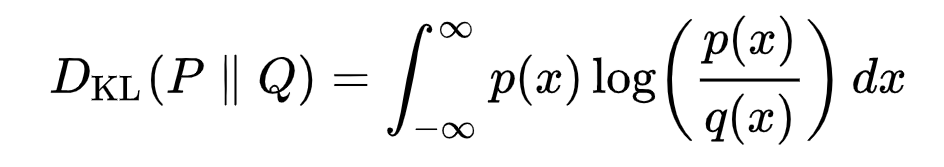
雙杠表示該函數(shù)關(guān)于其參數(shù)不對(duì)稱
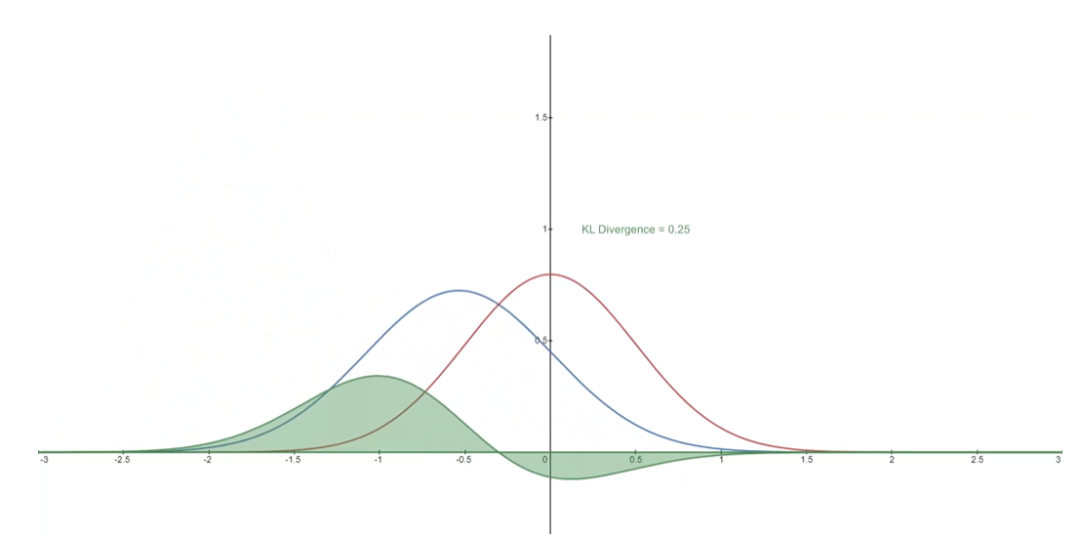
下面你可以看到分布 P(藍(lán)色)與參考分布 Q(紅色)的 KL 散度的變化。綠色曲線表示上述KL散度定義中積分內(nèi)的函數(shù),曲線下的總面積表示任意給定時(shí)刻P與Q的KL散度值。
將轉(zhuǎn)換為KL散度的形式
如上所述,可以將重寫(xiě)成KL散度的形式:
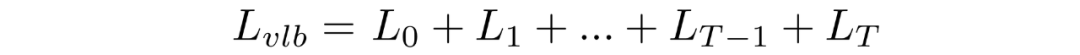
其中
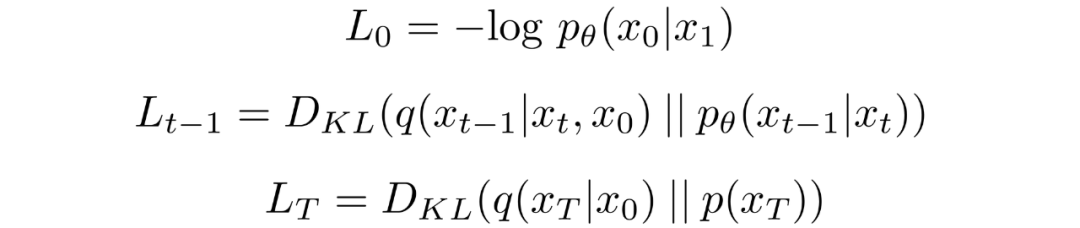
對(duì)中的后驗(yàn)的前向過(guò)程進(jìn)行條件化會(huì)導(dǎo)致易于處理的形式,從而導(dǎo)致所有 KL 散度都是高斯分布之間的比較。這意味著可以使用封閉式表達(dá)式而不是蒙特卡羅估計(jì)來(lái)精確計(jì)算。
模型選擇
建立了目標(biāo)函數(shù)的數(shù)學(xué)基礎(chǔ)后,我們現(xiàn)在需要就如何實(shí)施擴(kuò)散模型做出幾個(gè)選擇。對(duì)于前向過(guò)程,唯一需要的是定義方差策略,其值在前向過(guò)程中通常會(huì)增加。
對(duì)于逆向過(guò)程,我們多選擇高斯分布參數(shù)化/模型架構(gòu)。請(qǐng)注意擴(kuò)散模型提供的高度靈活性——我們架構(gòu)的唯一要求是其輸入和輸出具有相同的維度。
我們將在下面更詳細(xì)地探討這些選擇的細(xì)節(jié)。
前向過(guò)程和
如上所述,關(guān)于前向過(guò)程,我們必須定義方差策略。特別是,我們將它們?cè)O(shè)置為依賴時(shí)間的常數(shù),而忽略了它們可以學(xué)習(xí)的事實(shí)。例如,從到可能使用線性策略,或者可能使用幾何級(jí)數(shù)。
不管選擇的特定值如何,方差策略是固定的這一事實(shí)導(dǎo)致了相對(duì)于我們的可學(xué)習(xí)參數(shù)集成為了一個(gè)常數(shù),允許我們就訓(xùn)練而言忽略它。
反向過(guò)程和
現(xiàn)在我們討論定義反向向過(guò)程所需的東西。回想一下,我們將逆馬爾可夫轉(zhuǎn)換定義為高斯:
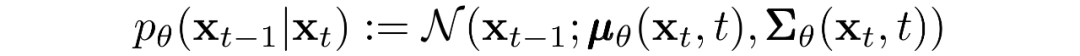
我們現(xiàn)在必須定義?或的函數(shù)形式。雖然有更復(fù)雜的方法來(lái)參數(shù)化,我們只需設(shè)置:
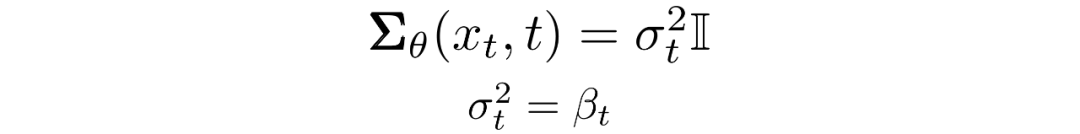
也就是說(shuō),我們假設(shè)多元高斯分布是具有相同方差的獨(dú)立高斯分布的乘積,方差值可以隨時(shí)間變化。我們將這些方差設(shè)置為我們的前向過(guò)程中的方差策略中的值。
給定了新的的形式,我們有:
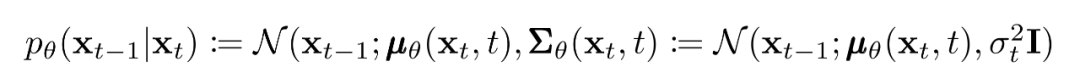
這就允許我們進(jìn)行變換,將:
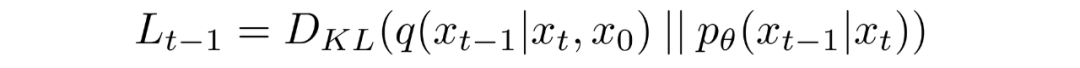
變換為:
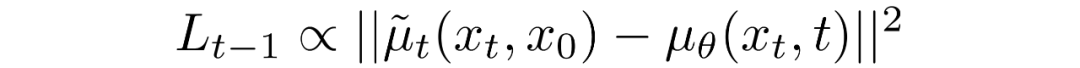
其中差分中的第一項(xiàng)是和的線性組合,它取決于方差策略。此函數(shù)的確切形式與我們的目的無(wú)關(guān)。
上述比例的意義在于最直接的對(duì)進(jìn)行參數(shù)化,直接預(yù)測(cè)擴(kuò)散的后驗(yàn)均值。重要的是,有學(xué)者發(fā)現(xiàn)訓(xùn)練來(lái)預(yù)測(cè)噪聲,在任何給定時(shí)間步長(zhǎng)的下都會(huì)產(chǎn)生更好的結(jié)果。特別地,讓
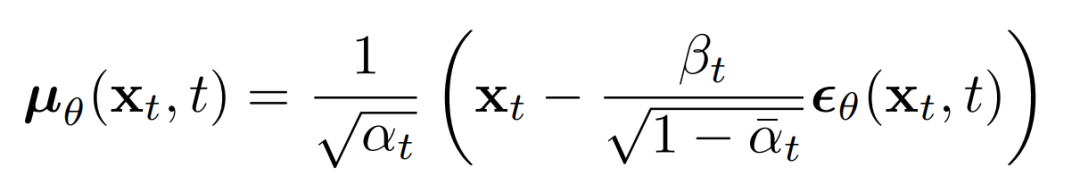
這里:
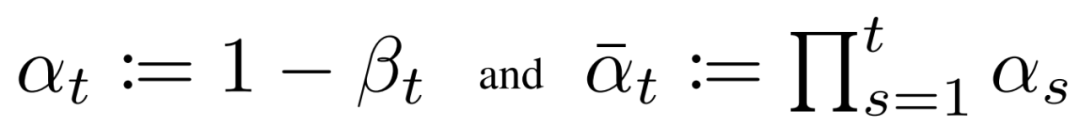
這可以導(dǎo)出下面的替代損失函數(shù),有學(xué)者發(fā)現(xiàn)可以帶來(lái)更穩(wěn)定的訓(xùn)練和更好的結(jié)果:
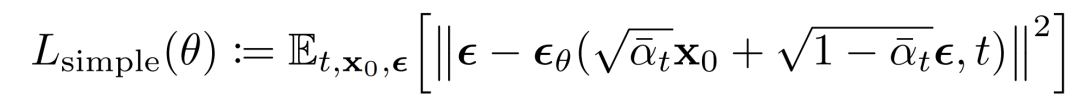
img
該學(xué)者還注意到這種擴(kuò)散模型公式與得分匹配生成模型在基于Langevin 動(dòng)力學(xué)的模型上的聯(lián)系 。事實(shí)上,擴(kuò)散模型和基于分?jǐn)?shù)的模型似乎是同一枚硬幣的兩面,類似于基于波的量子力學(xué)和基于矩陣的量子力學(xué)的獨(dú)立和同時(shí)發(fā)展,揭示了同一現(xiàn)象的兩個(gè)等價(jià)公式。
網(wǎng)絡(luò)結(jié)構(gòu)
雖然我們的簡(jiǎn)化損失函數(shù)旨在訓(xùn)練模型,但我們?nèi)晕炊x該模型的架構(gòu)。請(qǐng)注意,模型的唯一要求是其輸入和輸出維度相同。
鑒于此限制,圖像擴(kuò)散模型通常使用類似 U-Net 的架構(gòu)來(lái)實(shí)現(xiàn)。
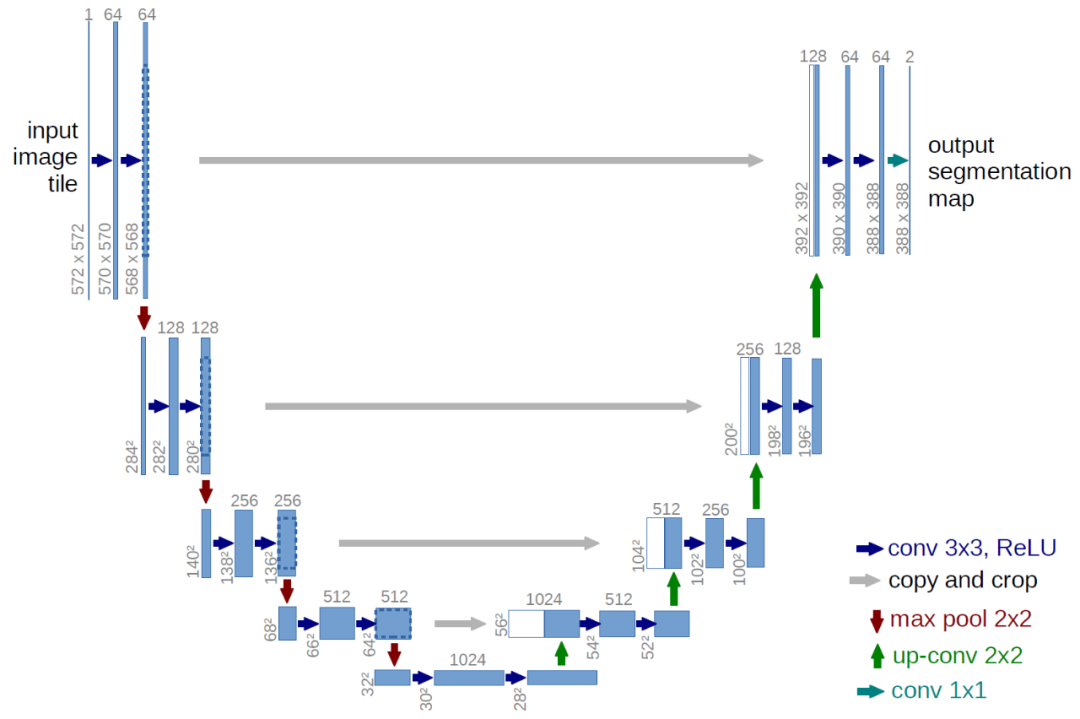
反向過(guò)程解碼和
反向過(guò)程的路徑由連續(xù)條件高斯分布下的許多變換組成。在反向過(guò)程結(jié)束時(shí),回想一下我們正在嘗試生成一個(gè)圖像,它由整數(shù)像素值組成。因此,我們必須設(shè)計(jì)一種方法來(lái)獲得所有像素中每個(gè)可能像素值的離散(對(duì)數(shù))似然。
這樣做的方法是將反向擴(kuò)散鏈中的最后一個(gè)轉(zhuǎn)換設(shè)置為獨(dú)立的離散解碼器。為了確定給定生成圖像的可能性,我們首先在數(shù)據(jù)維度之間施加獨(dú)立性:

其中D為數(shù)據(jù)的維數(shù),上標(biāo)i表示取一個(gè)坐標(biāo)。現(xiàn)在的目標(biāo)是在時(shí)刻t=1時(shí),一個(gè)給定的像素的概率分布和輕微噪聲圖中的對(duì)應(yīng)像素的相似程度:
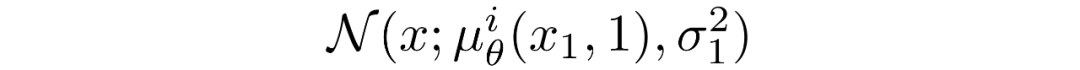
其中t=1 的像素分布源自下面的多元高斯分布,其對(duì)角協(xié)方差矩陣允許我們將分布拆分為單變量高斯分布的乘積,每個(gè)高斯分布對(duì)應(yīng)數(shù)據(jù)的每個(gè)維度:
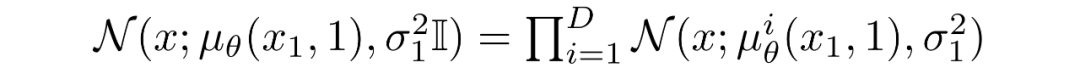
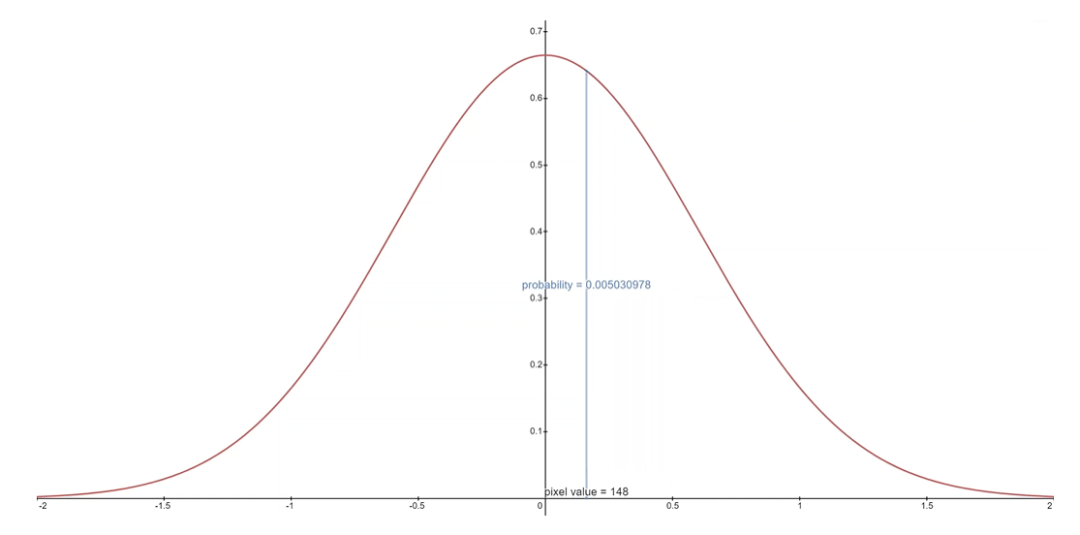
我們假設(shè)圖像由 0,1,...,255(作為標(biāo)準(zhǔn) RGB 圖像)中的整數(shù)組成,這些整數(shù)已線性縮放到 [?1,1]。其中,對(duì)于給定的像素值 x,該像素值的連續(xù)變化范圍是 [x?1/255,x+1/255]。給定中相應(yīng)像素的單變量高斯分布,像素值 x 的概率是以 x為中心的 [x?1/255,x+1/255]范圍內(nèi)的單變量高斯分布下的面積區(qū)域。
下面你可以看到每個(gè)范圍中的面積及其均值為 0 高斯的概率,在這種情況下,對(duì)應(yīng)于平均像素值為 255/2(半亮度)的分布。
對(duì)于每個(gè)像素,給定t=0時(shí)刻的像素值,就是簡(jiǎn)單的相乘就可以,這個(gè)過(guò)程可以用下面的式子表示:
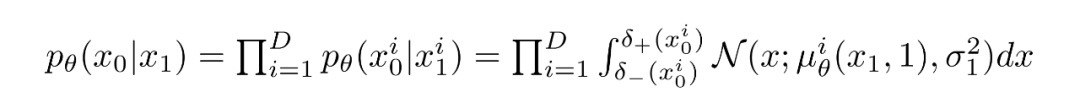
其中
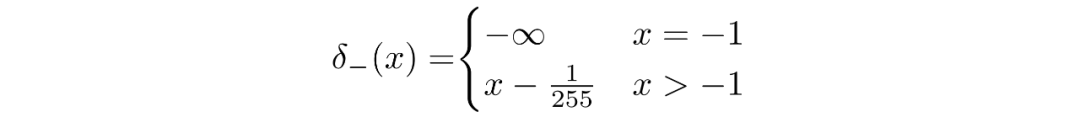
并且
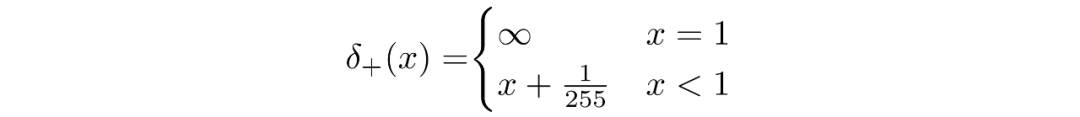
給定了的等式,我們可以計(jì)算出最終的的形式,并不是和KL散度一樣的形式:
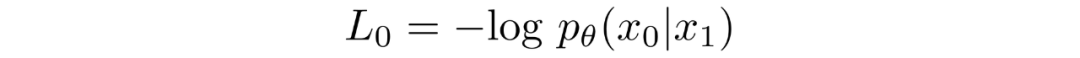
最終目標(biāo)
如上一節(jié)所述,作者發(fā)現(xiàn)預(yù)測(cè)給定時(shí)間步長(zhǎng)的圖像產(chǎn)生了最好的結(jié)果。最終,他們使用以下目標(biāo):
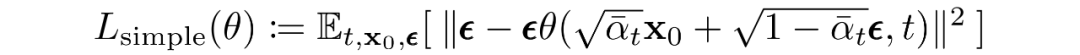
我們的擴(kuò)散模型的訓(xùn)練和采樣算法可見(jiàn)下圖:

擴(kuò)散模型總結(jié)
在本節(jié)中,我們?cè)敿?xì)探討了擴(kuò)散模型的理論。人們很容易陷入數(shù)學(xué)細(xì)節(jié),因此我們?cè)谙旅嬗涗浟俗钪匾囊c(diǎn),以便讓我們從總體的角度來(lái)定位:
我們的擴(kuò)散模型被參數(shù)化為馬爾可夫鏈,這意味著我們的潛變量?jī)H取決于之前(或之后)的時(shí)間步長(zhǎng)。
馬爾可夫鏈中的變換分布是高斯的,正向過(guò)程需要方差策略,逆向過(guò)程的參數(shù)是學(xué)習(xí)的。
擴(kuò)散過(guò)程確保對(duì)于足夠大的 T,漸近分布為各向同性高斯分布。
在我們的案例中,方差策略是固定的,但它也可以學(xué)習(xí)。對(duì)于固定策略,遵循幾何級(jí)數(shù)可能比線性級(jí)數(shù)提供更好的結(jié)果。在任一情況下,序列中的方差通常隨時(shí)間增加。
擴(kuò)散模型高度靈活,允許使用輸入和輸出維度相同的任何架構(gòu)。許多實(shí)現(xiàn)使用 U-Net-like架構(gòu)。
訓(xùn)練目標(biāo)是最大化訓(xùn)練數(shù)據(jù)的似然。這表現(xiàn)為調(diào)整模型參數(shù)以最小化數(shù)據(jù)負(fù)對(duì)數(shù)似然的變分上限。
由于我們的馬爾可夫假設(shè),目標(biāo)函數(shù)中的幾乎所有項(xiàng)都可以轉(zhuǎn)換為 KL 散度。鑒于我們使用的是高斯分布,這些值變得可以計(jì)算,因此無(wú)需執(zhí)行蒙特卡羅近似。
最終,使用簡(jiǎn)化的訓(xùn)練目標(biāo)來(lái)訓(xùn)練預(yù)測(cè)給定潛變量的噪聲分量的函數(shù)會(huì)產(chǎn)生最佳和最穩(wěn)定的結(jié)果。
作為反向擴(kuò)散過(guò)程的最后一步,離散解碼器用于獲取像素值的對(duì)數(shù)似然。
有了這個(gè)擴(kuò)散模型的高級(jí)概述,讓我們繼續(xù)看看如何在 PyTorch 中使用擴(kuò)散模型。
PyTorch中的擴(kuò)散模型
雖然擴(kuò)散模型還沒(méi)有像機(jī)器學(xué)習(xí)中其他結(jié)構(gòu)/方法那樣有很多人的實(shí)現(xiàn),但仍有可用的實(shí)現(xiàn)。在 PyTorch 中使用擴(kuò)散模型的最簡(jiǎn)單方法是使用denoising-diffusion-pytorch包,它實(shí)現(xiàn)了本文中討論的圖像擴(kuò)散模型。要安裝軟件包,只需在終端中鍵入以下命令:
pip?install?denoising_diffusion_pytorch
Minimal Example
為了訓(xùn)練模型生成圖像,我們首先導(dǎo)入必要的包:
import?torch from?denoising_diffusion_pytorch?import?Unet,?GaussianDiffusion
然后,我們定義網(wǎng)絡(luò)結(jié)構(gòu),這里用U-Net,參數(shù)中的dim表示第一次下采樣之前的特征圖的數(shù)量,dim_mults參數(shù)提了每次下采樣時(shí),通道數(shù)的乘數(shù)。
model?=?Unet( ????dim?=?64, ????dim_mults?=?(1,?2,?4,?8) )? 現(xiàn)在,網(wǎng)絡(luò)結(jié)構(gòu)定義好了,我們需要定義擴(kuò)散模型本身,我們將U-Net模型作為參數(shù)輸入到擴(kuò)散模型中,還有其他幾個(gè)參數(shù),生成的圖像的尺寸,擴(kuò)散過(guò)程的步數(shù),選擇L1還是L2歸一化。 ?
diffusion?=?GaussianDiffusion( ????model, ????image_size?=?128, ????timesteps?=?1000,???#?number?of?steps ????loss_type?=?'l1'????#?L1?or?L2 )
現(xiàn)在,擴(kuò)散模型定義好了,我們通過(guò)生成隨機(jī)數(shù)據(jù)來(lái)訓(xùn)練,然后使用常用的流程來(lái)訓(xùn)練:
training_images?=?torch.randn(8,?3,?128,?128) loss?=?diffusion(training_images) loss.backward()
模型訓(xùn)練完成后,我們最終可以使用 diffusion 對(duì)象的 sample() 方法生成圖像。這里我們生成 4 張圖像,由于我們的訓(xùn)練數(shù)據(jù)是隨機(jī)的,我們也只能得到噪聲:
sampled_images?=?diffusion.sample(batch_size?=?4)
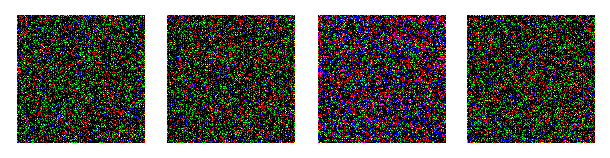
在自定義數(shù)據(jù)集上訓(xùn)練
denoising-diffusion-pytorch 包還允許你在特定數(shù)據(jù)集上訓(xùn)練擴(kuò)散模型。只需將下面的 Trainer() 對(duì)象中的 path/to/your/images 字符串替換為數(shù)據(jù)集目錄路徑,并將 image_size更改為適當(dāng)?shù)闹怠V螅恍柽\(yùn)行代碼來(lái)訓(xùn)練模型,然后像以前一樣進(jìn)行采樣。請(qǐng)注意,PyTorch 必須在啟用 CUDA 的情況下編譯才能使用 Trainer 類:
from?denoising_diffusion_pytorch?import?Unet,?GaussianDiffusion,?Trainer model?=?Unet( ????dim?=?64, ????dim_mults?=?(1,?2,?4,?8) ).cuda() diffusion?=?GaussianDiffusion( ????model, ????image_size?=?128, ????timesteps?=?1000,???#?number?of?steps ????loss_type?=?'l1'????#?L1?or?L2 ).cuda() trainer?=?Trainer( ????diffusion, ????'path/to/your/images', ????train_batch_size?=?32, ????train_lr?=?2e-5, ????train_num_steps?=?700000,?????????#?total?training?steps ????gradient_accumulate_every?=?2,????#?gradient?accumulation?steps ????ema_decay?=?0.995,????????????????#?exponential?moving?average?decay ????amp?=?True????????????????????????#?turn?on?mixed?precision ) trainer.train()
下面你可以看到從多元高斯噪聲到MNIST數(shù)字的漸進(jìn)去噪,類似于反向擴(kuò)散:

審核編輯:黃飛





















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論