 分布式文件系統的設計框架
分布式文件系統的設計框架
一、硬件故障檢測
因為HDFS系統(分布式文件系統)可由數百或數千個存儲文件數據片段的服務器組成,即HDFS系統包含較多的硬件設備,所以HDFS系統的硬件故障是常態,而非異常態。因此,HDFS系統的設計框架需包含故障檢測和數據自動快速恢復。
HDFS系統故障檢測和數據自動快速恢復功能具體過程如下:HDFS系統將數據分塊,即數據塊的形式存儲于不同硬件設備中。通常,每個數據塊在HDFS系統被存放于三個硬件設備中,即每個數據塊的份數是三份。當某一硬件設備出現故障時,HDFS系統在檢測到該設備故障后,可根據其他硬件設備的備份,將該硬件設備的數據再復制一遍,使HDFS系統中每個數據塊的份數保持在三份。
二、數據訪問
HDFS系統被設計為適合批量處理數據,具有較大的數據吞吐量。HDFS系統不適合交互式訪問。交互式訪問是指用戶在客戶端輸入命令,系統可立即對用戶命令做出反應。交互式訪問需要系統具有較快速的反應時間,而HDFS系統處理數據的速度可能是幾個小時或幾天,因此,HDFS系統的速度不足以支持交互式訪問。
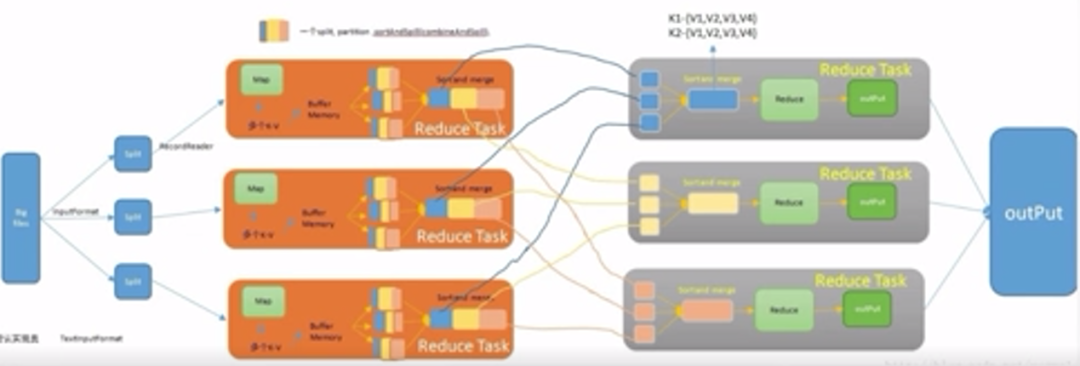
圖片來源:學堂在線《大數據導論》
三、大數據集
HDFS系統(分布式文件系統)的數據集群被設計為可包含數百個節點(個人理解:計算機或服務器均可作為HDFS系統的節點),百度最大的HDFS系統數據集群可能包含4000個節點。
HDFS系統的數據存儲量可達至100TB的數量級,一些HDFS系統的數據存儲量可超過該數量級。
HDFS系統被設計為可支持大文件存儲。數據量越大,HDFS系統的支持量越好。相對于大文件存儲,HDFS系統比較不適合存儲零散的小文件,這是因為所存儲的文件越小,主節點記錄文件存儲節點的日志文件(個人理解:存儲節點的日志文件包含數據的存儲位置等信息)越大,主節點的壓力越大。
四、簡單一致性模型
HDFS系統被設計為簡單一致性模型。簡單一致性模型是指多數HDFS系統的文件操作模式是一次寫入多次讀取,即文件一旦被創建、寫入、關閉后,就不再需要修改。HDFS系統不適合對文件進行頻繁的修改和刪除。
五、將計算移動至數據
數據計算的最理想狀態是在靠近數據的存儲位置計算,如果不能實現數據計算的最理想狀態,則需要通過將數據移動至計算或將計算移動至數據后再進行數據計算。
HDFS系統的數據計算方式是通過將計算移動至數據后再進行數據計算。將HDFS系統的數據存儲于多個數據節點,在計算過程中,可根據數據節點所存儲的數據進行相應計算,各數據節點計算結束后,再將各數據節點計算結果匯總。
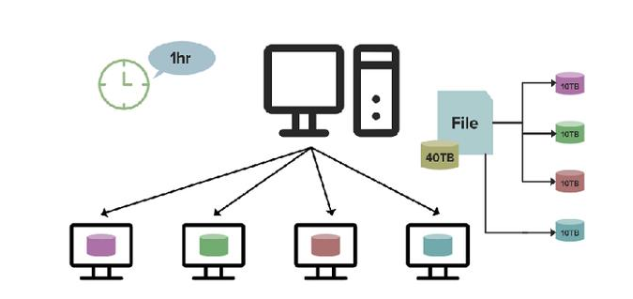
HDFS系統的數據計算方式適合大數據的計算,并且可以消除網絡擁堵,提高系統整體的吞吐量,數據計算的成本更低。如果將超過100TB的數據移動至計算中心,數據計算的速度將低于HDFS系統的數據計算方式,而且由于數據量大,網絡需要承受較大的壓力,容易造成擁堵,數據計算的成本更高。
六、異構軟硬件平臺間的可移植性
HDFS系統被設計為可簡便地實現平臺間的遷移,即不同的操作系統均可使用HDFS系統。該特點可推動大數據集應用更多采用HDFS系統。
審核編輯:劉清
-
服務器
+關注
關注
12文章
9285瀏覽量
85844 -
存儲數據
+關注
關注
0文章
89瀏覽量
14140 -
HDFS
+關注
關注
1文章
30瀏覽量
9623
原文標題:大數據相關介紹(20)——分布式文件系統的設計框架
文章出處:【微信號:行業學習與研究,微信公眾號:行業學習與研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一文解讀在RTThread平臺上使用DFS分布式文件系統
HarmonyOS分布式文件系統開發指導
采用信任管理的分布式文件系統TrustFs
海量郵件分布式文件系統的設計與實現
基于分布式文件系統元數據操作優化
盤點一下這些常見的分布式文件系統
AFS,GFS ,QKFile主流分布式存儲文件系統
解析夸克分布式文件系統如何實現資源共享
分布式文件存儲系統GFS的基礎知識
分布式文件系統主從式的伸縮性架構設計
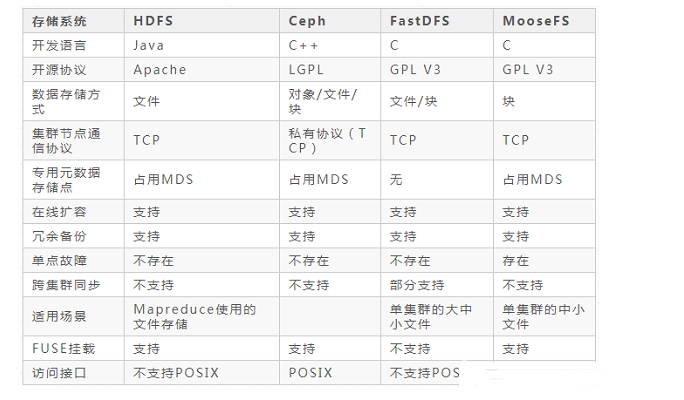
常見的分布式文件存儲系統的優缺點





 工商網監
工商網監
評論