") 基于Transformer架構(gòu)的InstructGPT介紹
基于Transformer架構(gòu)的InstructGPT介紹
1. 論文信息
1.1 prompt learning
Prompt Learning是自然語言處理中的一種技術(shù),它通過設(shè)計一些提示語(prompt)來指導(dǎo)模型在執(zhí)行任務(wù)時進行學(xué)習(xí)和推理。Prompt Learning技術(shù)的核心思想是,在模型的輸入中加入一些人工設(shè)計的提示語,這些提示語能夠幫助模型更好地理解輸入數(shù)據(jù)的含義和任務(wù)要求,從而提高模型在特定任務(wù)上的性能。通常情況下,提示語可以是一個問題、一段描述或者一個特定的標記序列。
1.2 GPT的介紹
GPT(Generative Pre-trained Transformer)的目標是訓(xùn)練出一種能夠生成自然語言文本的模型。它使用了大規(guī)模的預(yù)訓(xùn)練數(shù)據(jù)和神經(jīng)網(wǎng)絡(luò)技術(shù)來自動學(xué)習(xí)文本數(shù)據(jù)的語言規(guī)律,進而能夠生成自然流暢的文本。GPT是一種基于Transformer架構(gòu)的深度學(xué)習(xí)模型,可以用于自然語言生成、文本分類、語言理解等多種任務(wù)。
GPT的目標是通過無監(jiān)督學(xué)習(xí)的方式,將海量的自然語言文本轉(zhuǎn)化為一種通用的語言表示形式,從而使得模型能夠在不同的任務(wù)中進行遷移學(xué)習(xí),提高模型的泛化能力。為了達到這個目標,GPT使用了預(yù)訓(xùn)練和微調(diào)兩個階段。在預(yù)訓(xùn)練階段,GPT使用大量的無標簽數(shù)據(jù)對模型進行訓(xùn)練,從而學(xué)習(xí)文本的語言規(guī)律;在微調(diào)階段,GPT使用有標簽數(shù)據(jù)對模型進行微調(diào),以適應(yīng)特定的任務(wù)。
GPT是“Generative Pre-trained Transformer”的縮寫,是由OpenAI推出的自然語言處理模型。目前已經(jīng)發(fā)布了三代版本,每一代都有其獨特的特點和應(yīng)用。
以下是GPT一、二、三代的對比:
GPT-1
發(fā)布于2018年,包含1.17億個參數(shù)。
使用了12層transformer結(jié)構(gòu),可以預(yù)測下一個詞。
在通用自然語言處理任務(wù)上表現(xiàn)出色,包括文本分類、情感分析、摘要生成等。
缺點是對于長文本生成不如人意,容易出現(xiàn)重復(fù)和無意義的內(nèi)容。
GPT-2
發(fā)布于2019年,參數(shù)量是GPT-1的10倍,達到了1.5億個。
使用了24層transformer結(jié)構(gòu),可以生成更長、更復(fù)雜的文本。
在多項自然語言處理任務(wù)上表現(xiàn)出色,并且可以生成高質(zhì)量的文章、對話等。
由于生成的文本過于真實,存在濫用的風險,OpenAI沒有將模型公開發(fā)布。
GPT-3
發(fā)布于2020年,參數(shù)量是GPT-2的13倍,達到了1.75萬億個。
使用了1750億個語言模型參數(shù),可以生成更加自然、流暢、有邏輯的文本。
在多項自然語言處理任務(wù)上表現(xiàn)出色,甚至可以完成類似編程的任務(wù),例如編寫簡單的代碼。
GPT-3也被用于自然語言生成、對話系統(tǒng)、問答系統(tǒng)等應(yīng)用,具有廣泛的應(yīng)用前景。
總體來說,隨著模型的迭代和參數(shù)量的增加,GPT的性能逐漸提高,同時也具有更廣泛的應(yīng)用前景。
1.3 InstructGPT
InstructGPT是一種基于GPT-3的自然語言處理模型,它是由AI2(Allen Institute for Artificial Intelligence)開發(fā)的。與GPT-3不同的是,InstructGPT專注于解決指導(dǎo)型對話(instructional dialogue)的任務(wù)。指導(dǎo)型對話是指一種對話形式,其中一個人(通常是教師或者專家)向另一個人(通常是學(xué)生或者用戶)提供指導(dǎo)、解釋和建議。在這種對話中,用戶通常會提出一系列問題,而指導(dǎo)者則會針對這些問題提供詳細的答案和指導(dǎo)。
InstructGPT使用了GPT-3的架構(gòu)和預(yù)訓(xùn)練技術(shù),但是對其進行了針對性的微調(diào),使其能夠更好地應(yīng)對指導(dǎo)型對話任務(wù)。具體而言,InstructGPT通過對大量的指導(dǎo)型對話數(shù)據(jù)進行微調(diào),使得模型能夠更加準確地理解用戶的問題,并且能夠生成更加準確、詳細的答案和指導(dǎo)。此外,InstructGPT還支持多輪對話,可以對用戶的多個問題進行連續(xù)的回答和指導(dǎo)。
InstructGPT的應(yīng)用場景包括在線教育、智能客服等領(lǐng)域,可以幫助用戶更快地獲取所需的知識和指導(dǎo),并且能夠提高教育和客服的效率。
2. 方法框架
InstructGPT是一種基于語言模型的自然語言處理技術(shù),旨在解決指令性任務(wù)(instructional tasks),例如問答、推薦、提示、教育等領(lǐng)域。其技術(shù)路線主要包括以下幾個步驟:
數(shù)據(jù)收集:收集大規(guī)模的指令性文本數(shù)據(jù),包括問答、教育、用戶指南等。
數(shù)據(jù)預(yù)處理:對收集的數(shù)據(jù)進行預(yù)處理,包括分詞、標記化、詞干提取、停用詞過濾、詞向量化等。
模型訓(xùn)練:使用預(yù)處理后的數(shù)據(jù)訓(xùn)練深度學(xué)習(xí)模型,通常采用基于Transformer的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),例如GPT(Generative Pre-trained Transformer)。
模型微調(diào):針對具體的指令性任務(wù),對預(yù)訓(xùn)練模型進行微調(diào),例如通過遷移學(xué)習(xí)或fine-tuning的方法,使得模型能夠更好地適應(yīng)特定的任務(wù)和領(lǐng)域。
模型優(yōu)化:對微調(diào)后的模型進行進一步優(yōu)化,包括模型壓縮、量化、剪枝等技術(shù),以提高模型的速度和效率。
應(yīng)用部署:將優(yōu)化后的模型部署到具體的應(yīng)用場景中,例如問答系統(tǒng)、推薦系統(tǒng)、教育平臺等,提供高效、準確的指令性服務(wù)。
3. InstructGPT的訓(xùn)練模式
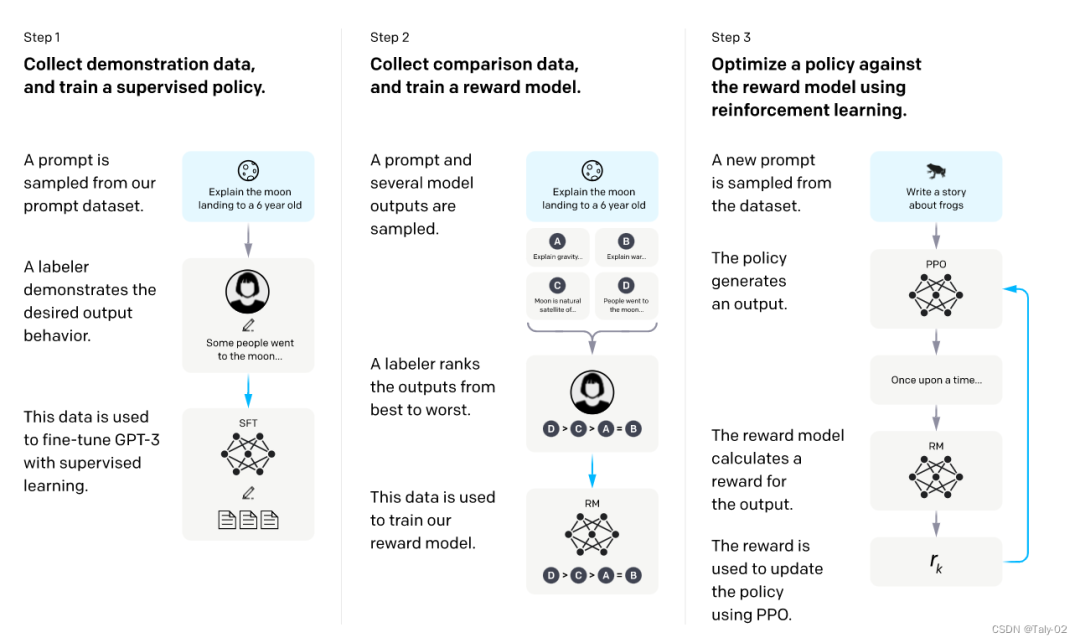
我們得想辦法怎么讓這個過程變得更輕松一點:
首先利用GPT-3進行初始化,希望對這個比較強大的模型先進行一些prompt learning來進行fine-tuning。先人工構(gòu)造一批數(shù)據(jù),讓模型學(xué)一學(xué),獲得一個模型。
然后,我們讓模型根據(jù)一系列提示輸出來評估其效果。我們讓模型針對每個提示生成多個輸出,隨后讓人員對這些輸出進行打分排序。雖然排序過程也需要人工干預(yù),但相較于直接讓人員編寫訓(xùn)練數(shù)據(jù),這種方法更為便捷。因此,這一過程能夠更輕松地標注更多數(shù)據(jù)。然而,這些標注數(shù)據(jù)不能直接用于訓(xùn)練模型,因為它們代表了一種排序結(jié)果。但我們可以訓(xùn)練一個打分模型,稱為“reward model”。該模型的作用在于對于每一個
接下來,我們繼續(xù)訓(xùn)練模型,給定一些prompt,得到輸出之后,把prompt和output輸入給RM,得到打分,然后借助強化學(xué)習(xí)的方法,來訓(xùn)練該模型,如此反復(fù)迭代,最終修煉得到最終的模型,也就是最終的InstructGPT。
可以看出InstructGPT的訓(xùn)練模式就是先靠人類手工設(shè)計一些精華信息,然后利用模型來嘗試模仿這些信息。之后根據(jù)模仿程度進行比對和打分,根據(jù)打分進行調(diào)整。最后打分機器就可以和模型配合,自動化地進行模型的迭代。這種迭代過程就是RLHF。
InstructGPT論文中,給出了上述三個步驟,涉及的訓(xùn)練樣本也是非常多的:
SFT數(shù)據(jù)集:人類預(yù)設(shè)的13k的prompts;
RM數(shù)據(jù)集:用來訓(xùn)練打分模型的數(shù)據(jù),包含33K的prompts;
PRO數(shù)據(jù)集:31K最后的數(shù)據(jù)。
前兩步的prompts,來自于OpenAI的在線API上的用戶使用數(shù)據(jù),以及雇傭的標注者手寫的。最后一步則全都是從API數(shù)據(jù)中采樣的,下表的具體數(shù)據(jù):
4. 對InstructGPT的展望
作為一個基于自然語言處理技術(shù)的AI語言模型,InstructGPT可以為用戶提供基本的對話和回答問題的服務(wù),但它仍存在以下不足:
缺乏真實人類的情感和情緒表達能力,無法在情感和社交領(lǐng)域提供有意義的支持。
缺乏真實世界知識和實際經(jīng)驗,對于需要領(lǐng)域?qū)I(yè)知識的問題回答可能不夠準確。
可能存在一些潛在的偏見和錯誤,這取決于模型的訓(xùn)練數(shù)據(jù)和算法。
隨著對話時間的增加,InstructGPT的回答可能變得越來越冗長或者不夠精確。
語言模型的工作基于已有的數(shù)據(jù)集,如果沒有合適的數(shù)據(jù)集或者缺少某些領(lǐng)域的數(shù)據(jù),模型的表現(xiàn)就會受到限制。
總之,InstructGPT目前還存在一些限制,盡管我們已經(jīng)取得了很大進展,但仍需要進一步的研究和發(fā)展,以實現(xiàn)更加高效和智能的AI對話系統(tǒng)。
審核編輯:劉清
-
Pro
+關(guān)注
關(guān)注
0文章
95瀏覽量
39501 -
GPT
+關(guān)注
關(guān)注
0文章
365瀏覽量
15647 -
自然語言處理
+關(guān)注
關(guān)注
1文章
624瀏覽量
13736 -
OpenAI
+關(guān)注
關(guān)注
9文章
1184瀏覽量
6930
原文標題:InstructGPT介紹
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
基于DINO知識蒸餾架構(gòu)的分層級聯(lián)Transformer網(wǎng)絡(luò)
關(guān)于深度學(xué)習(xí)模型Transformer模型的具體實現(xiàn)方案
如何更改ABBYY PDF Transformer+界面語言
谷歌將AutoML應(yīng)用于Transformer架構(gòu),翻譯結(jié)果飆升!
解析Transformer中的位置編碼 -- ICLR 2021

如何使用Transformer來做物體檢測?
Transformer深度學(xué)習(xí)架構(gòu)的應(yīng)用指南介紹
使用跨界模型Transformer來做物體檢測!

InstructGPT與ChatGPT的學(xué)習(xí)與解讀

ChatGPT/GPT的原理 ChatGPT的技術(shù)架構(gòu)
GPT/GPT-2/GPT-3/InstructGPT進化之路
Transformer結(jié)構(gòu)及其應(yīng)用詳解
RetNet架構(gòu)和Transformer架構(gòu)對比分析
基于Transformer模型的壓縮方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論