") 一文帶你了解基于視覺的機(jī)器人抓取自學(xué)習(xí)
一文帶你了解基于視覺的機(jī)器人抓取自學(xué)習(xí)
“一眼就能學(xué)會(huì)動(dòng)作”,或許對(duì)人而言,這樣的要求有點(diǎn)過高,然而,在機(jī)器人的身上,這個(gè)想法正在逐步實(shí)現(xiàn)中。馬斯克(Elon Musk)創(chuàng)立的人工智能公司Open AI研究通過One-Shot Imitation Learning算法(一眼模仿學(xué)習(xí)),讓機(jī)器人能夠復(fù)制人類行為。現(xiàn)階段理想化的目標(biāo)是人類教機(jī)器人一個(gè)任務(wù),經(jīng)過人類演示一次后,機(jī)器人可以自學(xué)完成指定任務(wù)。機(jī)器人學(xué)習(xí)的過程,與人類的學(xué)習(xí)具有相通之處,但是需要機(jī)器人能夠理解任務(wù)的動(dòng)作方式和動(dòng)作意圖,并且將其轉(zhuǎn)化為機(jī)器人自身的控制運(yùn)動(dòng)上。
“機(jī)器人學(xué)習(xí)”是機(jī)器人研究的重要方向,其中包含了計(jì)算機(jī)視覺,自然語言處理,機(jī)器人控制等眾多技術(shù)。機(jī)器人抓取(Robotic manipulation/grasping)是機(jī)器人智能化發(fā)展道路上亟待解決的問題之一。相較于傳統(tǒng)的開環(huán)控制系統(tǒng),本文將從基于視覺,基于視覺和語音,基于視覺和觸覺三個(gè)方向出發(fā),介紹機(jī)器人抓取的相關(guān)研究進(jìn)展,并羅列相關(guān)的文章供大家查找閱讀。
1、基于視覺信息的機(jī)器人抓取學(xué)習(xí)
結(jié)構(gòu)良好的視覺表示可以使機(jī)器人學(xué)習(xí)更快,并且可以提高通用性。在本文中,研究人員研究了在沒有人工標(biāo)記的情況下,如何通過使用自主的機(jī)器人與環(huán)境的交互獲得有效的以物體為中心的表示方法,即可完成機(jī)器人操作任務(wù)。這種機(jī)器人學(xué)習(xí)的方法可以讓機(jī)器人收集獲取更多的經(jīng)驗(yàn),不斷完善機(jī)器人的認(rèn)知,從而無需人工干預(yù)即可有效地進(jìn)行縮放。本文中的學(xué)習(xí)方法是基于對(duì)象的永久性:當(dāng)機(jī)器人從場(chǎng)景中刪除對(duì)象時(shí),該場(chǎng)景的表示會(huì)根據(jù)被刪除對(duì)象的特征而隨之變化。研究人員根據(jù)觀察結(jié)果會(huì)在特征向量之間建立關(guān)系,并使用它來學(xué)習(xí)場(chǎng)景和物體的表示。這些場(chǎng)景和物體可用于識(shí)別對(duì)象實(shí)例,將它們?cè)趫?chǎng)景中進(jìn)行定位,并在機(jī)器人從目標(biāo)箱中檢索命令對(duì)象時(shí),執(zhí)行以目標(biāo)為導(dǎo)向的任務(wù)。整體的抓取過程是通過記錄場(chǎng)景圖像,抓取和移除物體以及記錄結(jié)果,該抓取過程也可以用于為文中的方法自動(dòng)收集訓(xùn)練數(shù)據(jù)。文中實(shí)驗(yàn)表明,這種用于任務(wù)抓取的自我監(jiān)督方法明顯優(yōu)于直接增強(qiáng)圖像學(xué)習(xí)方法和先前的表征學(xué)習(xí)方法。
從小時(shí)候開始,即使從未有人明確地教過如何做,人們依舊能夠識(shí)別并收拾取自己喜歡的物品。根據(jù)認(rèn)知發(fā)展研究,這種與世界中的物體相互交互的能力,在人類感知和操縱物體的能力形成的過程中起著重要的作用。通過與周圍世界的互動(dòng),人們可以通過自我監(jiān)督來學(xué)習(xí):知道自己采取了什么行動(dòng),并且從結(jié)果中學(xué)到了什么知識(shí)。在機(jī)器人技術(shù)中,人們積極研究了這種自我監(jiān)督型學(xué)習(xí),因?yàn)樗箼C(jī)器人系統(tǒng)無需大量的訓(xùn)練數(shù)據(jù)或人工監(jiān)督即可進(jìn)行學(xué)習(xí)。
受對(duì)象永久性概念的啟發(fā),研究人員提出了Grasp2Vec,一種用于獲取物體表示的簡(jiǎn)單而高效的算法。Grasp2Vec算法中嘗試抓取任何東西都會(huì)獲取以下幾條信息——如果機(jī)器人抓住一個(gè)物體并將其抬起,則物體必須在抓取前進(jìn)入場(chǎng)景。此外,若機(jī)器人知道它抓住的物體當(dāng)前處于夾爪中,就會(huì)將其從場(chǎng)景中移除。通過使用這種形式的自監(jiān)督,機(jī)器人可以利用抓取前后的場(chǎng)景視覺變化來學(xué)習(xí)識(shí)別物體。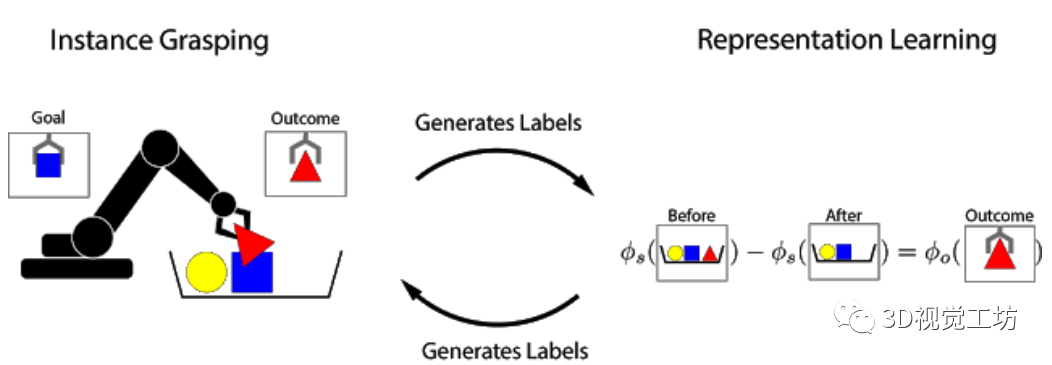
基于前與X Robotics合作的基礎(chǔ)上(該項(xiàng)目的任務(wù)是讓一系列機(jī)器人同時(shí)學(xué)習(xí)使用單目相機(jī)輸入來抓取家用物品),研究人員使用機(jī)械臂“無意間”抓取物體,這種經(jīng)驗(yàn)使機(jī)器人能夠?qū)W習(xí)豐富的圖像對(duì)象。這些表示可用于獲取“有意抓握”的能力,并且機(jī)械臂可以拾取用戶指定的對(duì)象。
在強(qiáng)化學(xué)習(xí)的框架中,通過“獎(jiǎng)勵(lì)函數(shù)”可以衡量任務(wù)的成功與否。通過最大化獎(jiǎng)勵(lì)函數(shù),機(jī)器人可以從頭開始自學(xué)各種抓握的技能。如果任務(wù)的成功與否可以通過簡(jiǎn)單的方法來衡量,設(shè)計(jì)獎(jiǎng)勵(lì)函數(shù)就很容易。一個(gè)簡(jiǎn)單的例子是當(dāng)一個(gè)按鈕被按下時(shí),該按鈕直接向機(jī)器人提供獎(jiǎng)勵(lì)。
然而,當(dāng)成功標(biāo)準(zhǔn)取決于對(duì)當(dāng)前任務(wù)的“感性理解”時(shí),設(shè)計(jì)獎(jiǎng)勵(lì)函數(shù)的難度就會(huì)加大。考慮實(shí)例抓取的任務(wù),其中機(jī)器人看到的是期望的物體圖片。當(dāng)機(jī)器人試圖抓住該物體后,將會(huì)檢查抓取的對(duì)象。此任務(wù)的獎(jiǎng)勵(lì)函數(shù)可以看作物體識(shí)別問題:抓住的物體是否與期望相匹配?
為了解決這種識(shí)別問題,需要一種感知系統(tǒng):該系統(tǒng)能從非結(jié)構(gòu)化圖像數(shù)據(jù)中提取有意義的物體概念,并能以無監(jiān)督的方式學(xué)習(xí)物體的視覺感知。該研究在數(shù)據(jù)收集的過程中,利用機(jī)器人可以操縱物體移動(dòng)的優(yōu)勢(shì),提供數(shù)據(jù)所需的變化因素。通過對(duì)物體進(jìn)行抓取,可以獲得1)抓取前的場(chǎng)景圖像;2)抓取后的場(chǎng)景圖像;3)抓握物體本身的孤立視圖。 研究人員提出了一個(gè)從圖像中提取“物體集合”的嵌入函數(shù),該函數(shù)滿足以下減法關(guān)系:
文中使用了全卷積架構(gòu)和簡(jiǎn)單的度量學(xué)習(xí)算法來實(shí)現(xiàn)這種等式關(guān)系,特征圖中嵌入抓取前的場(chǎng)景圖像和抓取后的場(chǎng)景圖像,并將其平均池化后保存到向量中,而“抓取前”和“抓取后”向量的差表示一組物體。該向量和對(duì)應(yīng)的被抓取物體的向量表示之間的等價(jià)約束是通過N-Pairs目標(biāo)函數(shù)實(shí)現(xiàn)的。通過N-Pairs目標(biāo)函數(shù)實(shí)現(xiàn)該向量和對(duì)應(yīng)的被抓取物體的向量之間的等價(jià)約束關(guān)系。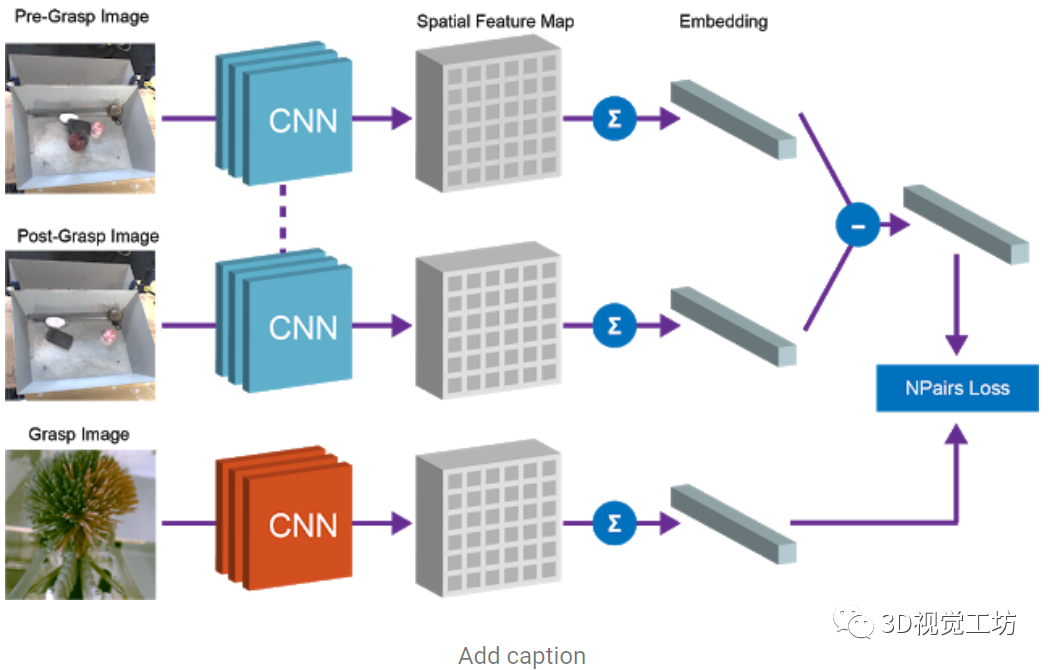
訓(xùn)練過后,模型中會(huì)出現(xiàn)兩個(gè)有用的屬性。
1)物體相似度
第一個(gè)屬性是余弦距離,利用向量間的余弦距離對(duì)物體進(jìn)行比較,并確定是否相同。這個(gè)屬性可以用于實(shí)現(xiàn)強(qiáng)化學(xué)習(xí)的獎(jiǎng)勵(lì)函數(shù),并允許機(jī)器人在沒有人工提供的標(biāo)簽的情況下學(xué)習(xí)實(shí)例抓取。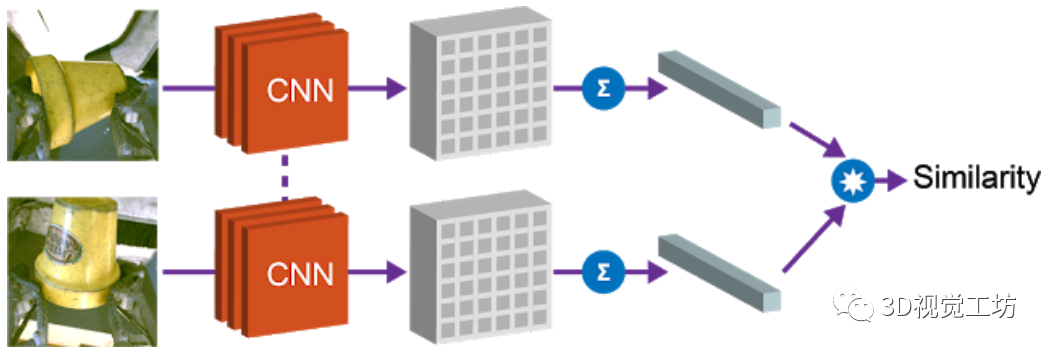
2)目標(biāo)物體本地化
第二個(gè)屬性是,可以組合場(chǎng)景空間映射和物體嵌入來本地化圖像空間中的“查詢對(duì)象”。將空間場(chǎng)景的特征圖和查詢對(duì)象的向量相乘,以找到兩者之間“匹配”的所有像素。例如下圖中的場(chǎng)景,模型可以檢測(cè)出場(chǎng)景中的多個(gè)相應(yīng)的色塊,通過點(diǎn)乘得到的“熱圖”,可用于規(guī)劃?rùn)C(jī)器人接近目標(biāo)物體的方法。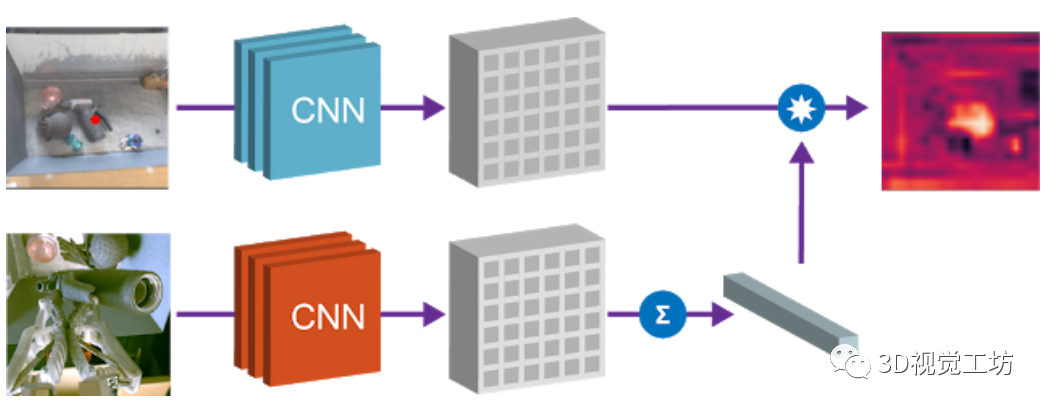
該項(xiàng)目展示了機(jī)器人抓取技能如何生成用于學(xué)習(xí)以物體為中心的表示的數(shù)據(jù),并使用表示學(xué)習(xí)來實(shí)現(xiàn)更復(fù)雜的技能,例如實(shí)例抓取,與此同時(shí)保留自主抓取系統(tǒng)中的自監(jiān)督學(xué)習(xí)屬性。
2、基于視覺和語音信息的機(jī)器人抓取
機(jī)器人自然語言理解會(huì)需要大量特定性領(lǐng)域和平臺(tái)的工程量。例如,移動(dòng)機(jī)器人在特定環(huán)境中接收操縱者的命令拾取放置物品,人類可以指定語言為某類命令,并將概念詞與物體對(duì)象的屬性進(jìn)行關(guān)聯(lián),例如紅色這樣的概念詞。減輕類似工作量的方法是使環(huán)境中的機(jī)器人能夠動(dòng)態(tài)適應(yīng),不斷學(xué)習(xí)新的語言構(gòu)造和感知概念等。在這項(xiàng)工作中,研究人員提出了一種端到端的方法,用于將自然語言命令翻譯為離散的機(jī)器人動(dòng)作,并使用對(duì)話框共同明確和改善語義和基礎(chǔ)概念。研究在Amazon Mechanical Turk的虛擬設(shè)置上對(duì)該目標(biāo)對(duì)象進(jìn)行訓(xùn)練和評(píng)估,并將該智能體轉(zhuǎn)移到現(xiàn)實(shí)世界中的物理機(jī)器人平臺(tái)上,進(jìn)行展示。
隨著機(jī)器人在家庭、工廠和醫(yī)院等環(huán)境中變得無處不在,人類對(duì)有效的人機(jī)交互的需求也在不斷增長(zhǎng)。上述各類場(chǎng)景中會(huì)包含特定的詞匯和行為啟示,例如,打開廚房的燈;把托盤往北移6英尺;如果病人的情況有變化,就通知我。因此,預(yù)編程機(jī)器人的語言理解會(huì)需要昂貴的特定性領(lǐng)域和平臺(tái)的工程。在本文中,研究人員提出并評(píng)估了一種機(jī)器人智能體,它可以通過與人類對(duì)話的方式擴(kuò)展一個(gè)初始狀態(tài)下資源較少、依靠手工編程的語言理解管道,從而與人類伙伴更好地達(dá)成共識(shí)。
研究人員結(jié)合了通過對(duì)話的信號(hào)進(jìn)行更好的語義解析(以前不使用物體的感官表征)和主動(dòng)學(xué)習(xí)方法來獲取這些概念(以前僅限于對(duì)象識(shí)別任務(wù))。因此,文中的系統(tǒng)能夠執(zhí)行自然語言命令,例如將一個(gè)能發(fā)出叮叮當(dāng)當(dāng)響聲的容器從會(huì)議室的休息室移到Bob的辦公室,其中包含組成語言(例如,語義分析器理解的會(huì)議室休息室以及將由其識(shí)別的對(duì)象的物理性質(zhì),如能發(fā)出叮叮當(dāng)當(dāng)響聲的容器)。系統(tǒng)僅用少量的用于語義解析的自然語言數(shù)據(jù)進(jìn)行初始化,沒有將概念詞與物理對(duì)象綁定的初始標(biāo)簽,而是需要通過人機(jī)對(duì)話學(xué)習(xí)解析和接地。
本文的貢獻(xiàn)主要是:1)提出了一種對(duì)話策略,僅利用少量初始領(lǐng)域內(nèi)的訓(xùn)練數(shù)據(jù)來提高語言理解;2)利用對(duì)話問題在現(xiàn)場(chǎng)實(shí)時(shí)獲取感知認(rèn)識(shí),而不是僅從預(yù)先標(biāo)記的數(shù)據(jù)或過去的交互過程中獲取;3)在一個(gè)完整的物理機(jī)器人平臺(tái)上部署對(duì)話智能體。
研究人員在Mechanical Turk上評(píng)估智能體的學(xué)習(xí)能力和可用性,要求用戶通過對(duì)話指揮智能體去完成三個(gè)任務(wù):導(dǎo)航(由廚房去休息室),傳遞(將紅色的罐子拿給Bob),和搬運(yùn)(將一個(gè)空瓶子從廚房休息室轉(zhuǎn)移到愛麗絲的辦公室)。研究發(fā)現(xiàn),根據(jù)之前對(duì)話中提取的信息對(duì)智能體進(jìn)行訓(xùn)練后,它的評(píng)價(jià)指標(biāo)會(huì)更好。然后,研究人員將經(jīng)過訓(xùn)練的智能體轉(zhuǎn)移到物理機(jī)器人上,并在人機(jī)對(duì)話中演示它的持續(xù)學(xué)習(xí)過程。
該會(huì)話智能體主要通過視覺信息和自然語言結(jié)合完成請(qǐng)求。整體主要包括以下幾個(gè)部分。
1)語義解析器:智能體通過獲取的單詞序列推斷任務(wù)的語義表示,使用組合類別語法(CCG)形式來進(jìn)行解析。
2)語言接地,根據(jù)不同的外部環(huán)境,相同的語義也可能會(huì)以不同的方式接地。例如,廚房旁邊的辦公室指的是一個(gè)物理位置,但這個(gè)位置取決于建筑。
3)對(duì)話框,人機(jī)之間的對(duì)話常常從人類用戶開始,指示智能體完成某項(xiàng)任務(wù),智能體會(huì)對(duì)未觀察到的真實(shí)任務(wù)進(jìn)行建模,并使用來自用戶的語言信號(hào)推斷該任務(wù)。該命令由語義解析和基礎(chǔ)組件處理,以獲得成對(duì)的符號(hào)和置信狀態(tài)值。置信狀態(tài)值通過語義解析(例如,“在北邊的辦公室的豆莢”中的介詞歧義;豆莢還是辦公室向北)和語言理解(例如,嘈雜的概念模型)步驟對(duì)不確定性進(jìn)行建模。
4)從對(duì)話中學(xué)習(xí):該智能體通過在完成的對(duì)話中引入訓(xùn)練數(shù)據(jù)來改進(jìn)其語義解析器,智能體能夠?qū)⒂脩舻某跏济钆c確認(rèn)的動(dòng)作進(jìn)行匹配,從會(huì)話中學(xué)習(xí)語義。同時(shí),采用主動(dòng)學(xué)習(xí)的方式,從向用戶提出的問題中快速擴(kuò)展感知概念模型,然后在各個(gè)用戶之間匯總擴(kuò)展,并且可以將學(xué)習(xí)到的概念應(yīng)用于遠(yuǎn)程測(cè)試對(duì)象,有助于獲取新概念。
會(huì)話智能體的組成如下圖所示,左側(cè)是將用戶的命令進(jìn)行語義解析,中間為利用已有的地圖和概念模型等信息對(duì)指令進(jìn)行接地,右側(cè)是利用對(duì)話改進(jìn)完善智能體的認(rèn)知模型。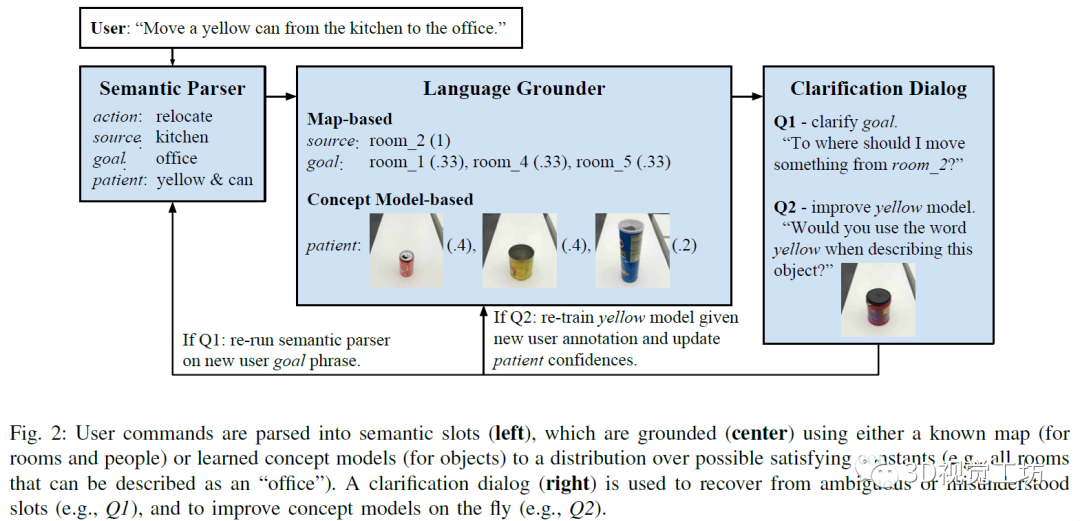
實(shí)驗(yàn)中指定的任務(wù)包含:根據(jù)用戶指示完成到達(dá)指定地點(diǎn),將物品遞送給某人,將物品從指定地點(diǎn)移動(dòng)到目的地。下圖為受過訓(xùn)練的智能體采用動(dòng)態(tài)學(xué)習(xí)的方式實(shí)現(xiàn)指定的目標(biāo)。

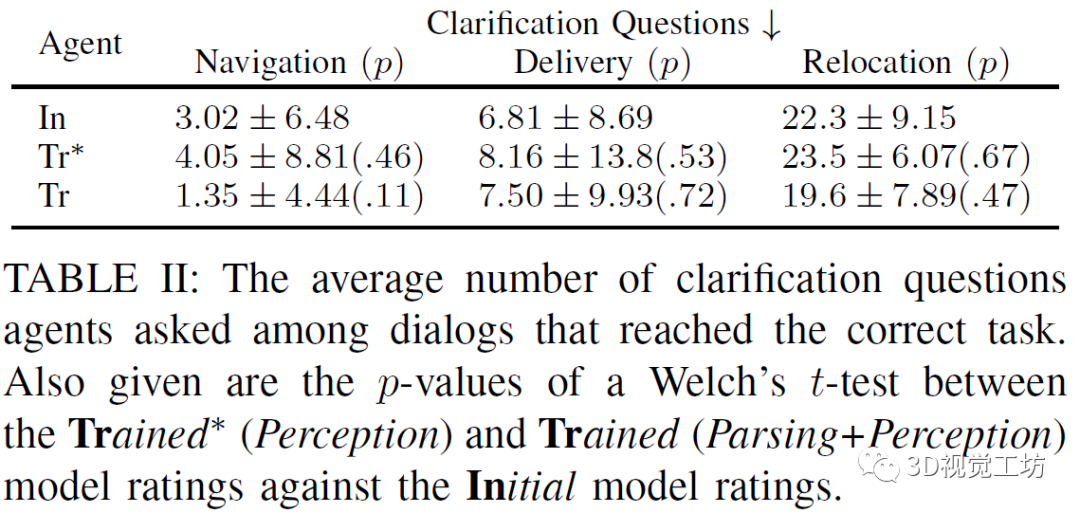
上表比較初始智能體,受過訓(xùn)練(僅感知訓(xùn)練)智能體,受過訓(xùn)練(解析訓(xùn)練和感知訓(xùn)練)的智能體三者的實(shí)驗(yàn)情況,衡量的標(biāo)準(zhǔn)是在滿足正確的任務(wù)規(guī)范之前,需要進(jìn)行的詢問的問題的個(gè)數(shù),實(shí)驗(yàn)顯示受過訓(xùn)練(僅感知訓(xùn)練)智能體表現(xiàn)較差,可能是由于對(duì)話中的許多形容詞和名詞的屬性沒有及時(shí)更新。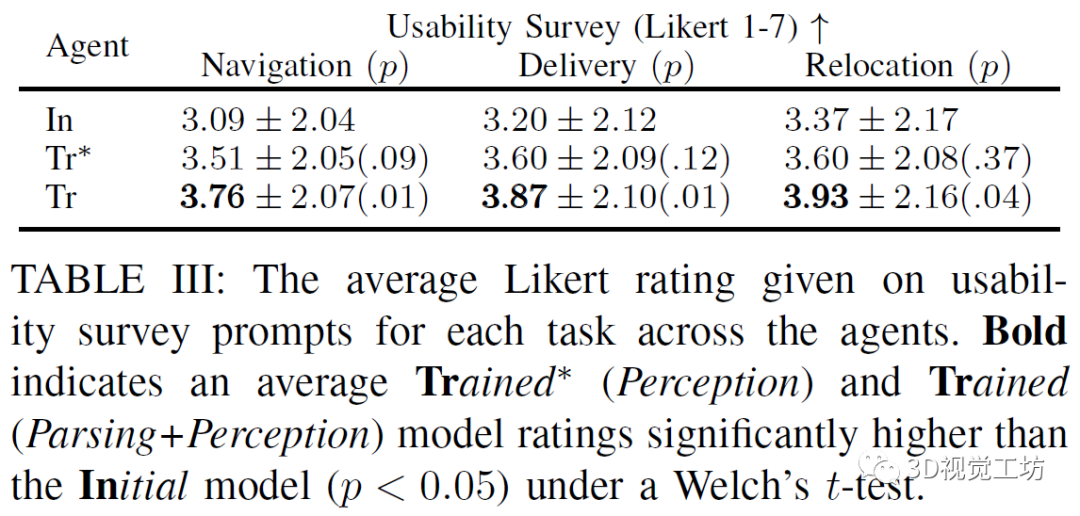
上表比較初始智能體,受過訓(xùn)練(僅感知訓(xùn)練)智能體,受過訓(xùn)練(解析訓(xùn)練和感知訓(xùn)練)的智能體三者的實(shí)驗(yàn)情況,衡量的標(biāo)準(zhǔn)是用戶對(duì)智能體表現(xiàn)的定性的評(píng)價(jià),主要包括:我將使用這樣的機(jī)器人來幫助導(dǎo)航到一棟新樓;我將會(huì)用這樣的機(jī)器人為自己或其他人拿取東西;我將會(huì)用這樣的機(jī)器人來將物品從一個(gè)地方移到另一個(gè)地方。實(shí)驗(yàn)顯示受過訓(xùn)練(解析和感知)的智能體的表現(xiàn)最好。
該研究提出了一種機(jī)器人智能體,其可以利用與人類的對(duì)話來擴(kuò)展自定義的小型化的語言理解資源,利用這些資源既可以將自然語言命令翻譯為抽象的語義形式,又可以將物理對(duì)象的抽象屬性接地。在這項(xiàng)工作中,機(jī)器人可以執(zhí)行的動(dòng)作可以分解為離散語義角色的元組,但是通常,他們需要推理更多的連續(xù)動(dòng)作空間,并獲取新的、與人類對(duì)話中看不見的行為和知識(shí)。該研究中的智能體可以從人機(jī)對(duì)話中學(xué)習(xí)知識(shí),甚至可以處理復(fù)雜的形容詞和名詞之間的依賴和上下文關(guān)系。
3、基于視覺和觸覺信息的機(jī)器人抓取
人類使用視覺、聽覺和觸覺等多種模式的感覺輸入來感知世界。在這項(xiàng)工作中研究了視覺和觸覺之間的交叉模式連接。跨模態(tài)建模任務(wù)的主要挑戰(zhàn)在于兩者之間在比例上存在顯著差異:雖然我們的眼睛一次性就可以感知到整個(gè)視覺場(chǎng)景,但人類在任何給定時(shí)刻只能觸碰感覺到物體的一個(gè)小部分。為了連接視覺和觸覺,文中合成來自視覺輸入的合理的觸覺信號(hào),以及想象我們?nèi)绾闻c以觸覺數(shù)據(jù)作為輸入的對(duì)象進(jìn)行交互。為了實(shí)現(xiàn)該目標(biāo),研究人員首先為機(jī)器人配備了視覺和觸覺傳感器,并收集了相應(yīng)視覺和觸覺圖像序列的大規(guī)模數(shù)據(jù)集。為了縮小規(guī)模差距,研究中提出了一個(gè)新的條件對(duì)抗模型,該模型結(jié)合了觸摸的規(guī)模和位置信息。人類的感知研究表明,本文中的模型可以從觸覺數(shù)據(jù)中產(chǎn)生逼真的視覺圖像,反之亦然。最后,展示了有關(guān)不同系統(tǒng)設(shè)計(jì)的定性和定量實(shí)驗(yàn)結(jié)果,以及可視化了模型的學(xué)習(xí)表示。
文中提出了一種跨模態(tài)預(yù)測(cè)方法,用于從觸摸預(yù)測(cè)視覺,反之亦可。研究人員首先將觸覺中的程度、規(guī)模、范圍和位置信息結(jié)合在模型中。然后,使用數(shù)據(jù)平衡的方法多樣化其結(jié)果。最后,通過考慮時(shí)間信息的方法進(jìn)一步提高準(zhǔn)確性。
研究中的模型基于pix2pix方法,是一個(gè)用于圖像到圖像任務(wù)的條件GAN框架。在任務(wù)中,生成器接受視覺圖像或觸覺圖像作為輸入,并生成一個(gè)對(duì)應(yīng)的觸覺或視覺圖像。而判別器觀察輸入的圖像和輸出的圖像。在訓(xùn)練中,對(duì)判別器進(jìn)行訓(xùn)練,以分辨合成圖片和真實(shí)圖片之間的差異,而生成器則是用于產(chǎn)生可以欺騙判別器的圖片。在實(shí)驗(yàn)中,研究人員使用視覺-觸覺圖像對(duì)訓(xùn)練模型。在從觸覺還原視覺的任務(wù)中,輸入觸覺圖像,而輸出是對(duì)應(yīng)的視覺圖像。而在視覺預(yù)測(cè)觸覺的任務(wù)中,則輸入和輸出對(duì)調(diào)。
模型使用編碼器-解碼器架構(gòu)用于生成任務(wù)。在編碼器上分別使用兩個(gè)ResNet-18模型用于輸入圖像(視覺或觸覺圖像)和參考的視覺-觸覺圖像,將兩個(gè)編碼器的向量合并為一個(gè)1024維向量,將其輸入解碼器。解碼器包括五層標(biāo)準(zhǔn)的卷積神經(jīng)網(wǎng)絡(luò),并在編碼器和解碼器間加入了跨層連接,研究中使用的判別器為ConvNets。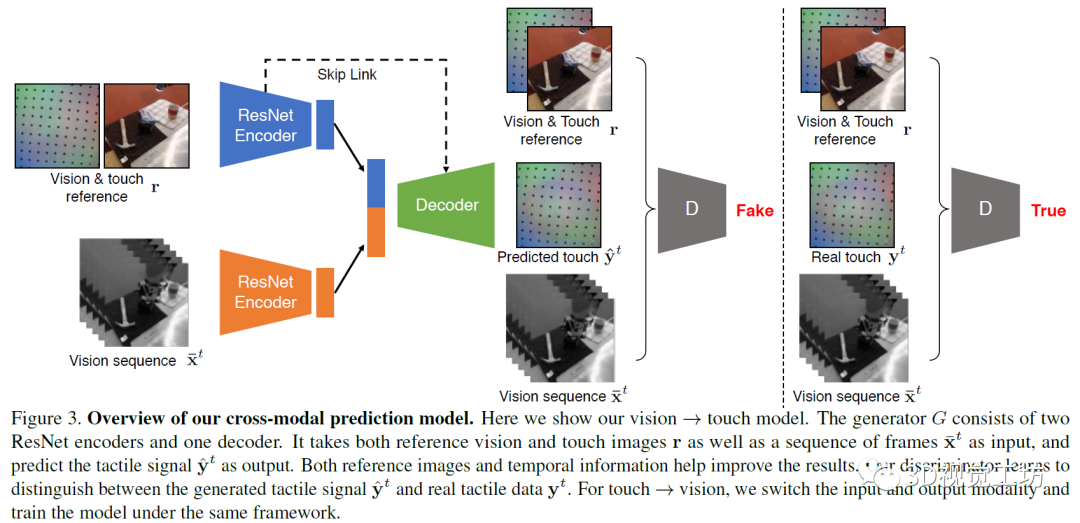
研究發(fā)現(xiàn),實(shí)驗(yàn)結(jié)果不是很好,圖片中有嚴(yán)重的視覺偽影,并且生成的結(jié)果與輸入信號(hào)不一致。為解決上述問題,研究人員對(duì)基本算法進(jìn)行修改和完善。首先將觸覺和視覺參考圖像提供給生成器和判別器,以便該模型只需要學(xué)習(xí)為交叉模式變化建模,而不是整個(gè)信號(hào)。其次,為防止模式崩塌,研究人員采取數(shù)據(jù)重均衡策略幫助生成器生成不同的模式,性能更加健壯。最后,從輸入視頻的多個(gè)相鄰幀而不是僅從當(dāng)前幀中提取信息,從而產(chǎn)生時(shí)間相干的輸出。
研究人員在一個(gè)KUKA機(jī)械手臂上放置GelSight傳感器,機(jī)械臂背面的三腳架上安裝了一個(gè)網(wǎng)絡(luò)攝像頭,以捕捉機(jī)械臂觸摸物體的場(chǎng)景視頻,實(shí)驗(yàn)中讓機(jī)械臂去戳弄不同的物體。GelSight表面有一層薄膜,在接觸物體的過程中會(huì)發(fā)生形變,進(jìn)而采集到高質(zhì)量的觸覺數(shù)據(jù)。研究團(tuán)隊(duì)總共記錄了195件物品的12000次觸碰,這些物品屬于不同類別。每個(gè)觸摸動(dòng)作包含一個(gè)250幀的視頻序列,產(chǎn)生了300萬視覺和觸覺成對(duì)的圖像的數(shù)據(jù)集—VisGel。根據(jù)此數(shù)據(jù)集,當(dāng)模型辨認(rèn)到接觸位置的形狀和材料,與參考圖像進(jìn)行比較,以識(shí)別觸摸的位置和范圍。
上圖是本文模型和其他基線模型實(shí)驗(yàn)結(jié)果的可視化對(duì)比,該模型可以更好地根據(jù)視覺信息預(yù)測(cè)物體表面的觸覺信息,也能夠更好地根據(jù)觸覺信息還原圖像表面。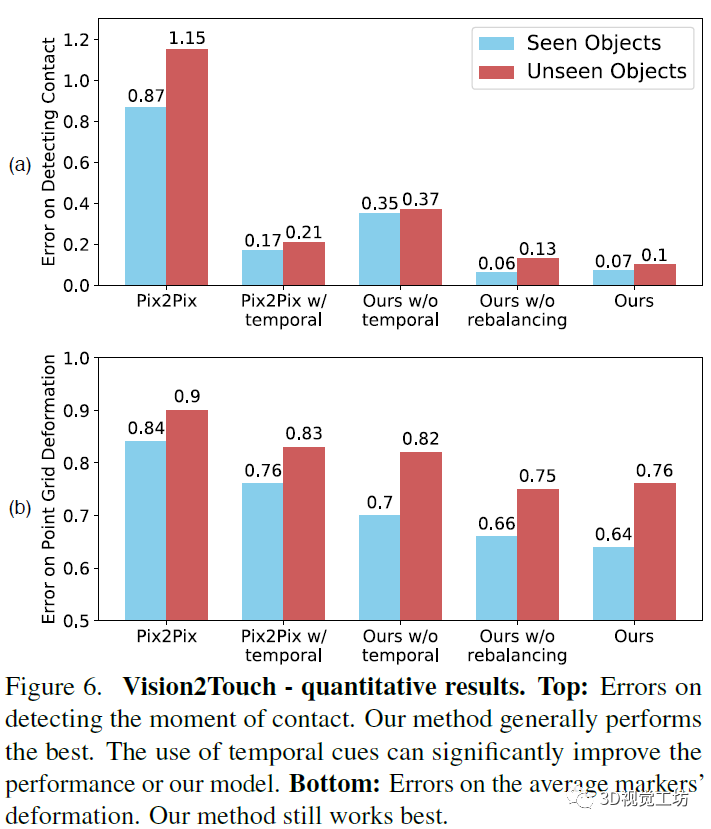
上圖是從視覺到觸覺的量化評(píng)測(cè)結(jié)果。a圖的評(píng)價(jià)指標(biāo)是測(cè)試機(jī)器人是否已經(jīng)認(rèn)知到觸摸了物體表面的錯(cuò)誤數(shù)。b圖的評(píng)價(jià)指標(biāo)是根據(jù)圖像還原觸覺點(diǎn)位置的失真錯(cuò)誤情況。本文中的模型表現(xiàn)優(yōu)于其它模型。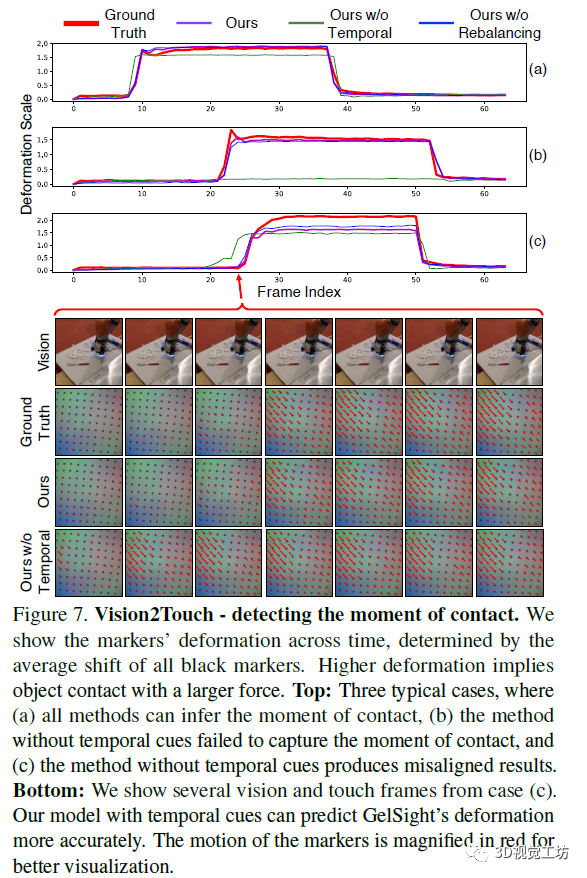
上圖是從視覺還原觸覺的情況,其中顯示了標(biāo)記隨時(shí)間的變形,該變形由所有黑色標(biāo)記的平均位移確定,較高的變形意味著物體以較大的力接觸。下圖是根據(jù)圖像還原的觸覺點(diǎn)陣信息,為便于增強(qiáng)可視化的效果,圖片中的標(biāo)記的運(yùn)動(dòng)以紅色放大。
該項(xiàng)工作提出了在視覺和觸覺與條件對(duì)抗網(wǎng)絡(luò)之間建立聯(lián)系。當(dāng)與外界互動(dòng)時(shí),人類非常依賴視覺和觸覺的感官方式。該模型可以為已知物體和未知物體進(jìn)行跨模態(tài)的預(yù)測(cè)。研究人員認(rèn)為在將來,視觸交叉的模式可以幫助視覺和機(jī)器人技術(shù)應(yīng)用,例如在弱光環(huán)境下的物體識(shí)別和抓取以及物理場(chǎng)景理解。
審核編輯:劉清
-
機(jī)器人
+關(guān)注
關(guān)注
211文章
28490瀏覽量
207448 -
計(jì)算機(jī)視覺
+關(guān)注
關(guān)注
8文章
1698瀏覽量
46030 -
機(jī)器人控制
+關(guān)注
關(guān)注
0文章
14瀏覽量
6745
原文標(biāo)題:一文帶你了解基于視覺的機(jī)器人抓取自學(xué)習(xí)(Robot Learning)
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
機(jī)器人視覺——機(jī)器人的“眼睛”
【mBot申請(qǐng)】視覺機(jī)器人
基于深度學(xué)習(xí)技術(shù)的智能機(jī)器人
【MYD-CZU3EG開發(fā)板試用申請(qǐng)】基于機(jī)器視覺的工業(yè)機(jī)器人抓取工作站
【瑞芯微RK1808計(jì)算棒試用申請(qǐng)】基于機(jī)器視覺的工業(yè)機(jī)器人抓取工作站
工業(yè)機(jī)器人與視覺實(shí)訓(xùn)平臺(tái)介紹
工業(yè)機(jī)器人視覺裝配實(shí)訓(xùn)平臺(tái)實(shí)驗(yàn)
如何讓電機(jī)自學(xué)習(xí)?
如何設(shè)計(jì)具有自學(xué)習(xí)循路功能的輪式移動(dòng)機(jī)器人模型的方法資料說明
一文解析工業(yè)機(jī)器人視覺檢測(cè)系統(tǒng)
淺談機(jī)器人視覺抓取的目的
基于視覺的機(jī)器人抓取系統(tǒng)設(shè)計(jì)
基于視覺的自主導(dǎo)航移動(dòng)抓取機(jī)器人搭建方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論