 Python-多線程、多進程、協程
Python-多線程、多進程、協程
基本使用
**基本概念
**
- 進程
- 幾乎所有的操作系統都支持同時運行多個任務,一個任務通常就是一個程序,每個運行中的程序就是一個進程
- 進程是處于運行過程中的程序,并且具有一定的獨立功能
- 進程是系統進行資源分配調度的一個獨立單位
- 線程
- 線程(Thread)也叫 輕量級進程 ,是操作系統能夠進行運算調度的最小單位
- 它被包涵在進程之中,是進程中的實際運作單位,線程自己不擁有系統資源,只擁有一點兒在運行中必不可少的資源,但它可與同屬一個進程的其它線程共享進程所擁有的全部資源
- 進程中的多個線程之間可以并發執行
一個進程可以擁有多個線程,一個線程必須有一個父進程。線程可以擁有自己的堆棧、自己的程序計數器和自己的局部變量,但不擁有系統資源,它與父進程的其他線程共享該進程所擁有的全部資源。
多線程的優點
- 進程之間不能共享內存,但線程之間共享內存非常容易
- 操作系統在創建進程時,需要為該進程重新分配系統資源,但創建線程的代價則小得多。因此,使用多線程來實現多任務并發執行比使用多進程的效率高
- Python 語言內置了多線程功能支持,而不是單純地作為底層操作系統的調度方式,從而簡化了 Python 的多線程編程
示例
**方式一: **使用 threading.Thread(target=方法名) 的方式實現多線程
參數說明:threading.Thread(參數說明)
- target: 指定該線程要調度的目標方法。只傳函數名,不傳函數,即不加()
- args: 指定一個元組,以位置參數的形式為target指定的函數傳入參數。元組的第一個參數傳給target的第一個,以此類推
- kwargs: 指定一個字典,以關鍵字參數的形式為target指定的函數傳入參數
- daemon:指定所構建的線程是否為后臺線程
import time
import threading
def eat(num):
for i in range(num):
print("我正在吃飯......")
time.sleep(1)
def drunk(num=10):
for i in range(num):
print("我正在喝水......")
time.sleep(1)
if __name__ == '__main__':
# 創建兩個線程
t1 = threading.Thread(target=eat, args=(10,))
t2 = threading.Thread(target=drunk)
# 啟動兩個線程
t1.start()
t2.start()
while True:
threadList = threading.enumerate()
print("正在運行的線程是:", threadList)
print("正在運行的線程數量是:", len(threadList))
time.sleep(2)
方式二: 繼承threading.Thread
import time
import threading
class MyThread(threading.Thread):
def run(self):
for i in range(10):
print("線程啟動了,我的名字叫:", self.name)
time.sleep(1)
if __name__ == '__main__':
# 創建兩個線程
t1 = MyThread()
t2 = MyThread()
# 啟動兩個線程, start() 方法內部會自動去調用 run方法,所以此處寫 start() 就可以了
t1.start()
t2.start()
while True:
threadList = threading.enumerate()
print("正在運行的線程是:", threadList)
print("正在運行的線程數量是:", len(threadList))
time.sleep(2)
全局變量、互斥鎖、死鎖
共享全局變量示例
import threading
g_num = 0
def fun_1(num):
global g_num
for i in range(num):
g_num += 1
print("------fun_1的g_num值:%d" % g_num)
def fun_2(num):
global g_num
for i in range(num):
g_num += 1
print("------fun_2的g_num值:%d" % g_num)
if __name__ == '__main__':
t1 = threading.Thread(target=fun_1, args=(1000000,))
t2 = threading.Thread(target=fun_2, args=(1000000,))
t1.start()
t2.start()
輸出結果 :

從以上結果可以看出,直接使用全局變量是有問題的,按理說,預期結果應該是2000000,實際結果相關很大,且每次執行結果都不一樣
原因
- 在g_num=0 時,t1取得g_num=0,此時系統把t1調度為 "sleeping" 狀態,把t2轉換為 "running" 狀態,t2 這時也獲得了 g_num=0
- 然后 t2對得到的值進行加1,并賦給g_num,使得g_num=1
- 然后系統又把 t2調度為"sleeing",把t1轉為"running",線程t1又把它之前得到的0 加1后賦值給 g_num。
- 這樣就導致了 t1和t2都對 g_num加1,但結果仍然是 g_num=1
解決方案:互斥鎖
- 當多個線程幾乎同時修改某個共享數據的時候,需要進行同步控制
- 某個線程要更改共享數據時,先將其鎖定,此時資源狀態為**” 鎖定 “ ,其他線程不能更改;直到該線程釋放資源,將資源的狀態改為 ”**非鎖定 “, 其他的線程才能再次鎖定該資源。互拆鎖保證了 每次只有一個線程進行寫入操作 ,從而保證了多線程數據的正確性
import threading
g_num = 0
def fun_1(num):
global g_num
for i in range(num):
# 上鎖,如果之前沒上鎖,此時調用就會上鎖;如果之前上鎖了,此時調用就會阻塞,直接鎖被別人釋放
lock.acquire()
g_num += 1
# 釋放鎖
lock.release()
print("------fun_1的g_num值:%d" % g_num)
def fun_2(num):
global g_num
for i in range(num):
# 上鎖,如果之前沒上鎖,此時調用就會上鎖;如果之前上鎖了,此時調用就會阻塞,直接鎖被別人釋放
lock.acquire()
g_num += 1
# 釋放鎖
lock.release()
print("------fun_2的g_num值:%d" % g_num)
if __name__ == '__main__':
# 創建一個互斥鎖,默認是沒上鎖的
lock=threading.Lock()
t1 = threading.Thread(target=fun_1, args=(1000000,))
t2 = threading.Thread(target=fun_2, args=(1000000,))
t1.start()
t2.start()
死鎖
- 在線程共享多個資源的時候,如果兩個線程分別占有一部分資源并且同時等待對方的資源,就會造成死鎖
- 盡管死鎖很少發生,但一旦發生就會造成程序停止響應
import threading
import time
def fun_1():
# 1號鎖,上鎖
lock1.acquire()
print("fun_1..do some thing.........1")
time.sleep(1)
# 2號鎖,上鎖,如果被別人占用了,則會阻塞
lock2.acquire()
print("fun_1..do some thing..........2")
# 釋放2號鎖
lock2.release()
# 釋放1號鎖
lock1.release()
def fun_2():
# 2號鎖,上鎖
lock2.acquire()
print("fun_2..do some thing.........2")
time.sleep(1)
# 1號鎖,上鎖,如果被別人占用了,則會阻塞
lock1.acquire()
print("fun_2..do some thing..........1")
# 釋放1號鎖
lock1.release()
# 釋放2號鎖
lock2.release()
if __name__ == '__main__':
# 創建兩個互斥鎖
lock1=threading.Lock()
lock2=threading.Lock()
t1 = threading.Thread(target=fun_1)
t2 = threading.Thread(target=fun_2)
t1.start()
t2.start()
輸出結果:會一直停止阻塞

死鎖解決方案
-
程序設計時避免
-
**添加超時等待
**
進程
進程的狀態
- 新建:操作系統調度啟動一個新進程
- 就緒態:運行的條件都已經滿足,等待cpu執行
- 執行態:cpu 正在執行
- 等待態:等待某些條件滿足,例如一個程序sleep了,此時就處于等待態

進程的創建
- 在python中,提供了 multiprocessing 模塊,就是跨平臺的多進程模塊,模塊提供了 Process類來代表一人進程對象,這個對象可以理解為一個獨立的進程
- Process 參數說明
- target:傳遞函數的引用,子進程將執行這個函數
- args:給target指定的函數,傳遞參數,以元組的方式傳遞,非必填
- kwargs:給target指定的函數傳遞命名參數,非必填
- name:給進程設定一個名稱,非必填
- group:指定進程組,非必填
- Process 對象的常用方法
- start():啟動子進程
- is_alive():判斷子進程是否還活著
- join(timeout):是否等待子進程執行結束,或等待多少秒
- terminate():不管任務是否完成,立即終止子進程
- Process 對象的常用屬性
- name:當前進程的別名,默認為Process-x, x為從1開始遞增的整數
- pid:當前進程的pid (進程號)
示例
import time
import os
import multiprocessing
def eat(num):
for i in range(num):
print("我正在吃飯......,我的進程號是:%d,父進程的進程號是:%d" % (os.getpid(),os.getppid()))
time.sleep(1)
def drunk(num):
for i in range(num):
print("我正在喝水......我的進程號是:%d,父進程的進程號是:%d" % (os.getpid(),os.getppid()))
time.sleep(1)
if __name__ == '__main__':
# 創建兩個進程
p1 = multiprocessing.Process(target=eat, args=(10,))
p2 = multiprocessing.Process(target=drunk, args=(10,))
# 啟動兩個進程
p1.start()
p2.start()
print("主進程的進程號是:%d" %os.getpid())
輸出結果

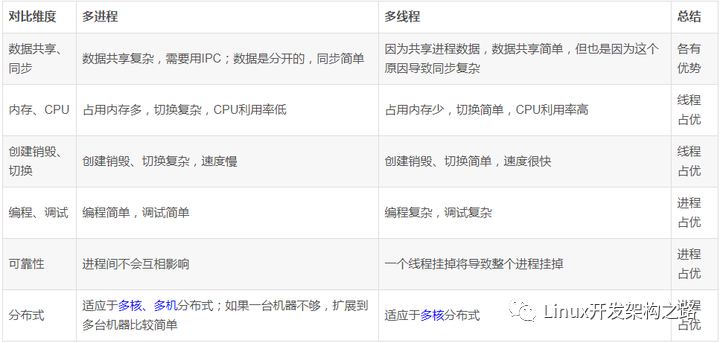
進程線程區別
- 功能區別
- 進程:能夠完成多任務,比如,在一臺電腦上運行多個qq
- 線程:能夠完成多任務,比如,在一個qq中開多個聊天窗口
- 調度
- 進程是資源分配的基本單位
- 線程是cpu調度和執行的最小單位
- 擁有資源
- 進程擁有資源的一個獨立單位
- 線程不擁有系統資源,但可以訪問隸屬于進程的資源
- 穩定性
進程有獨立的地址空間,多進程較穩定,因為其中一個出現狀況不影 響另外一個
同一個進程的多個線程,共用地址空間,多線程相比于多進程,穩定性要差,因為一個線程出現問題會嚴重影響其他線程
- 依賴關系
- 一個線程只能屬性一個進程
- 一個進程至少有一個線程
- 針對全局變量的共享
- 多進程間不共享全局變量(進程間都是獨立的)
- 多線程間共享全局變量
進程間的通信
- 不同的進程間有時也需要進行數據傳遞,在Python中,可以使用 muitiprocessiong模塊的 Queue ,來實現進程間的數據傳遞
- Queue 是一個消息隊列,數據是先進先出的原則
示例
import time
import multiprocessing
def set_data(queue):
numList=[1,2,3,4]
for i in numList:
# 給隊列中放數據,如果隊列已經滿了,則會阻塞,直到能放數據為止
queue.put(i)
time.sleep(1)
def get_data(queue):
while True:
# 判斷隊列中如果沒有數據了,則退出循環
if queue.empty():
break
# 從隊列中取數據
data=queue.get()
print("從隊列中取出的數據是:",data)
if __name__ == '__main__':
# 創建一個消息列表,容量是3(表示只能裝3個數據)
queue=multiprocessing.Queue(3)
# 創建兩個進程
p1 = multiprocessing.Process(target=set_data, args=(queue,))
p2 = multiprocessing.Process(target=get_data, args=(queue,))
# 啟動兩個進程
p1.start()
p2.start()
**輸出結果 **

進程池
- 需要創建成百上千個進程時,可以使用 muitiprocessing模塊提供的 Pool 方法
- 初始化Pool時 ,可以指定一個最大進程數,當有新的請求提交到Pool中時,如果池里面沒有滿,就會創建一個新的進程來執行該請求,如果已經滿了,那么就會等待,直到池中有空閑進程,會調用空閑進程來執行新任務
示例
import time
import os
import multiprocessing
def work(msg):
print("開始執行工作,當前進程是:",os.getpid())
time.sleep(2)
print("接收到的消息數據是:%s"%msg)
if __name__ == '__main__':
# 創建進程池,容量為3
pool=multiprocessing.Pool(3)
for i in range(10):
# pool.apply_async(要調用的目標,(傳遞給目標的參數元組,))
# 每次循環將會用空閑的子進程去執行任務
pool.apply_async(work,("傳遞參數:%d"%i,))
# 關閉進程池,關閉后進程池不再接收新請求
pool.close()
# 等待進程池中所有的子進程執行完成 ,必須放在close 語句之后
pool.join()
輸出結果

協程
迭代器
- 迭代是訪問集合元素的一種方式
- 迭代器是一個可以記住遍歷位置的對象。
- 迭代器對象從集合的第一個元素開始訪問,直到所有的元素都訪問完成
- 迭代器只會前進,不會后退
- 我們把對 list、set、str、tuple 等類型的數據使用 for...in ... 的方式從中獲取數據,這樣的過程稱為 遍歷(循環) ,也叫迭代
判斷一個數據類型是否可迭代,使用 isinstance(xxx,Iterable)
from collections.abc import Iterable
list1=[1,2]
str1="123"
tuple1=(1,2)
dict1={1:"a",2:"b"}
num=122
print(isinstance(list1,Iterable))
print(isinstance(str1,Iterable))
print(isinstance(tuple1,Iterable))
print(isinstance(dict1,Iterable))
print(isinstance(num,Iterable))
輸出結果

自已實現迭代器示例
class MyIterator:
"""自己實現一個迭代器"""
def __init__(self):
self.name = list()
self.currentIndex = 0
def add(self, arg):
self.name.append(arg)
def __iter__(self):
# 如果想要一個對象成為可以被迭代的對象,即可以使用 for ... in ... ,那么必須實現 __iter__ 方法
return self
def __len__(self):
return len(self.name)
def __next__(self):
# 當使用for...in... 迭代時,會先調用 __iter__ 方法,然后調用其返回對象中的 __next__ 方法(即本方法)
if self.currentIndex < len(self.name):
result = self.name[self.currentIndex]
self.currentIndex += 1
return result
else:
# 拋出一個 停止迭代的異常
raise StopIteration
myIter = MyIterator()
myIter.add("張三")
myIter.add("李四")
myIter.add("王五")
for i in myIter:
print(i)
# 獲取集合長度
print(len(myIter))
**生成器
**
- 生成器是一種特殊的迭代器
- 創建生成器有兩種方式
- 方式一:把一個列表生成式的[] 改成 ()
-
# 原始列表 l=[x*2 for x in range(10)] # 構建生成器 g=(x*2 for x in range(10)) # 迭代創建的生成器 for i in g: print(i)
- 方式二:使用 yield 關鍵字
-
def create_age(num): currentAge=0 while currentAge
協程
- 實現方式一:采用yield 實現
import time
def eat():
while True:
print("我在吃飯.....")
time.sleep(1)
yield
def drunk():
while True:
print("我在喝水.....")
time.sleep(1)
yield
if __name__ == '__main__':
# 創建兩個生成器
eat=eat()
drunk=drunk()
while True:
next(eat)
next(drunk)
- 實現方式二:采用 greenlet 實現
- 先安裝 greenlet 模塊:pip install greenlet
import time
from greenlet import greenlet
def eat():
while True:
print("我在吃飯.....")
# 切換到g2中運行
g2.switch()
time.sleep(1)
def drunk():
while True:
print("我在喝水.....")
# 切換到g1中運行
g1.switch()
time.sleep(1)
if __name__ == '__main__':
# 創建兩個生成器
g1 = greenlet(eat)
g2 = greenlet(drunk)
# 切換到g1中運行
g1.switch()
- 實現方式三:采用 gevent實現 ( 推薦使用 )
- 由于 greenlet 需要人手動切換,比較占用IO資源,并且會出現,一旦中間某個程序處于線程等待的話,會一直等待很長時間的問題。所以gevent就應運而生,gevent 遇到延時阻塞會自動切換
- 先安裝 gevent模塊:pip install gevent
import time
import gevent
from gevent import monkey
# 有耗時操作時需要, 將程序中用到的耗時操作的代碼,換為gevent中自己實現的模塊
monkey.patch_all()
def work(num):
for i in range(num):
print(gevent.getcurrent(), i)
# 使用 mokey.patch_all() 之后,程序會自動替換成 gevent里面的 gevent.sleep() 方法
time.sleep(1)
if __name__ == '__main__':
# 創建并啟動協程
gevent.joinall({
gevent.spawn(work, 10),
gevent.spawn(work, 10)
})
圖片下載器實現
import gevent
from gevent import monkey
from urllib import request
# 有耗時操作時需要, 將程序中用到的耗時操作的代碼,換為gevent中自己實現的模塊
monkey.patch_all()
def down_pic(filename,url):
resp=request.urlopen(url)
data=resp.read()
# 寫入文件
with open(filename,"wb") as f:
f.write(data)
if __name__ == '__main__':
# 創建并啟動協程
gevent.joinall({
gevent.spawn(down_pic, "1.jpg","https://himg3.qunarzz.com/imgs/201812/14/C._M0DCiiigrWCy4LQi1024.jpg"),
gevent.spawn(down_pic, "2.jpg","https://source.qunarzz.com/site/images/zhuanti/huodong/shangwu.jpg")
})
總結
- 進程是資源分配的單位
- 線程是操作系統調度的單位
- 進程切換需要的資源最大,效率很低
- 線程切換需要的資源一般,效率一般(不考慮GIL的情況下)
- 協程切換任務資源很小,效率高
- 多進程、多線程根據cpu核數不一樣可能是并行的,但是協程是在一個線程中,所以是并發
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
操作系統
+關注
關注
37文章
6889瀏覽量
123602 -
程序
+關注
關注
117文章
3795瀏覽量
81300 -
任務
+關注
關注
1文章
20瀏覽量
8554 -
進程
+關注
關注
0文章
204瀏覽量
13974
發布評論請先 登錄
相關推薦
多線程和多進程的區別
6.你的數據庫一會又500個連接數,一會有10個,你分析一下情況7.udp和tcp的區別8.多線程和多進程的區別9.有一臺web服務器,你選擇用多線程還是多進程,...
發表于 07-19 07:21
python多線程和多進程對比
段可以干多件事,譬如可以邊吃飯邊看電視;在Python中,多線程 和 協程 雖然是嚴格上來說是串行,但卻比一般的串行程序執行效率高得很。 一般的串行程序,在程序阻塞的時候,只能干等著,
發表于 03-15 16:42
LINUX系統下多線程與多進程性能分析
采用多進程處理多個任務,會占用很多系統資源(主要是CPU 和內存的使用)。在LINUX 中,則對這種弊端進行了改進,在用戶態實現了多線程處理多任務。本文系統論述了多線程間
發表于 08-13 08:31
?20次下載
如何選好多線程和多進程
關于多進程和多線程,教科書上最經典的一句話是“進程是資源分配的最小單位,線程是CPU調度的最小單位”,這句話應付考試基本上夠了,但如果在工作中遇到類似的選擇問題,那就沒有這么簡單了,選

多進程與多線程的深度比較
嵌入式Linux中文站,關于多進程和多線程,教科書上最經典的一句話是“進程是資源分配的最小單位,線程是CPU調度的最小單位”。這句話應付考試基本上夠了,但如果在工作中遇
發表于 04-02 14:42
?490次閱讀
Python后端項目的協程是什么
最近公司 Python 后端項目進行重構,整個后端邏輯基本都變更為采用“異步”協程的方式實現。看著滿屏幕經過 async await(協程在
python多線程和多進程的對比
在同一時間段可以干多件事,譬如可以邊吃飯邊看電視; 在Python中, 多線程 和 協程 雖然是嚴格上來說是串行,但卻比一般的串行程序執行效率高得很。 一般的串行程序,在程序阻塞的時候
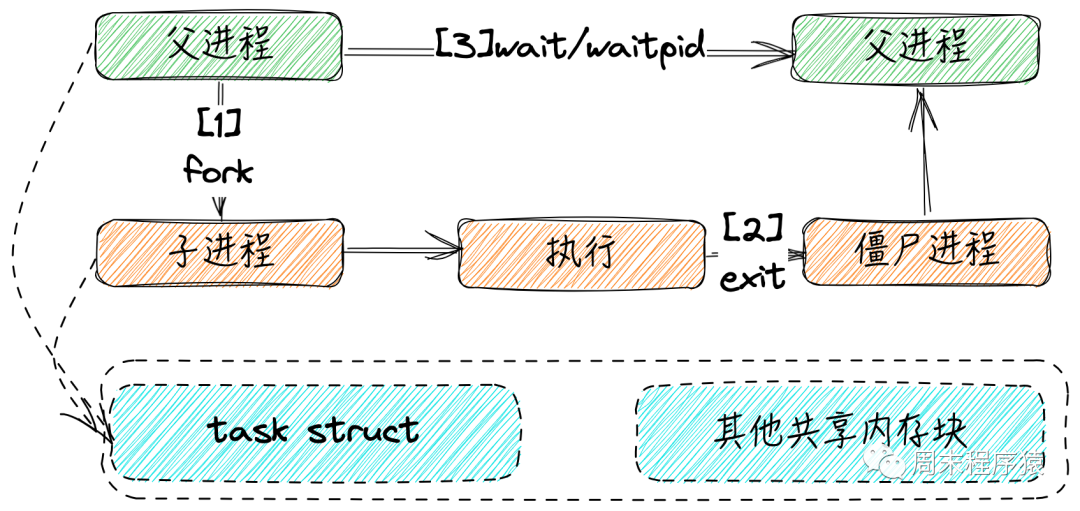
Python多進程學習
Python 多進程 (Multiprocessing) 是一種同時利用計算機多個處理器核心 (CPU cores) 進行并行處理的技術,它與 Python 的多線程 (Multith
淺談Linux網絡編程中的多進程和多線程
在Linux網絡編程中,我們應該見過很多網絡框架或者server,有多進程的處理方式,也有多線程處理方式,孰好孰壞并沒有可比性,首先選擇多進程還是多線程我們需要考慮業務場景,其次結合當
發表于 08-08 16:56
?845次閱讀
關于Python多進程和多線程詳解
進程(process)和線程(thread)是操作系統的基本概念,但是它們比較抽象,不容易掌握。關于多進程和多線程,教科書上最經典的一句話是“進程
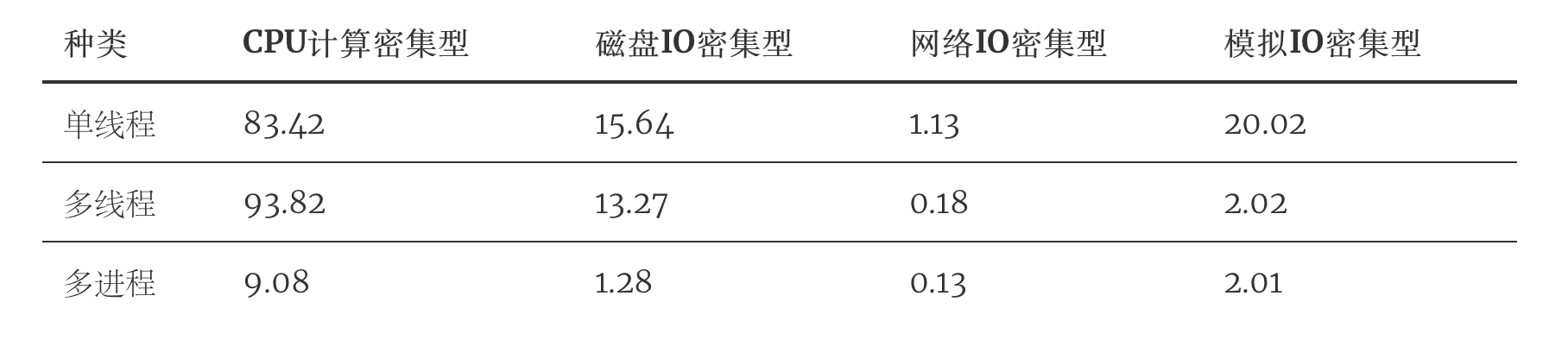
Linux系統上多線程和多進程的運行效率
關于多進程和多線程,教科書上最經典的一句話是“進程是資源分配的最小單位,線程是CPU調度的最小單位”,這句話應付考試基本上夠了,但如果在工作中遇到類似的選擇問題,那就沒有這么簡單了,選
你還是分不清多進程和多線程嗎?一文搞懂!
你還是分不清多進程和多線程嗎?一文搞懂! 多進程和多線程是并發編程中常見的兩個概念,它們都可以用于提高程序的性能和效率。但是它們的實現方式和使用場景略有不同。 1.
Python中多線程和多進程的區別
Python作為一種高級編程語言,提供了多種并發編程的方式,其中多線程與多進程是最常見的兩種方式之一。在本文中,我們將探討Python中多線程





 工商網監
工商網監
評論