 主流分布式存儲技術對比分析
主流分布式存儲技術對比分析
【導讀】 如今分布式存儲產品眾多令人眼花繚亂,如何選型?要根據其背后的核心架構來分析它本來的原貌,然后才能決定其是否適合我們的具體場景。
【作者】 趙海
1 引言
目前市面上各個廠家的分布式存儲產品五花八門,但是如果透過產品本身的包裝看到其背后的核心技術體系,基本上會分為兩種架構,一種是有中心架構的分布式文件系統架構,以GFS、HDFS為代表;另外一種是完全無中心的分布式存儲架構,以Ceph、Swift、GlusterFS為代表。對具體分布式存儲產品選型的時候,要根據其背后的核心架構來分析它本來的原貌,然后才能決定其是否適合我們的具體場景。
2 主流分布式存儲技術對比分析
2.1 GFS & HDFS
GFS和HDFS都是基于文件系統實現的分布式存儲系統;都是有中心的分布式架構 (圖2.1) ;通過對中心節點元數據的索引查詢得到數據地址空間,然后再去數據節點上查詢數據本身的機制來完成數據的讀寫;都是基于文件數據存儲場景設計的架構 ;都是適合順序寫入順序讀取,對隨機讀寫不友好。
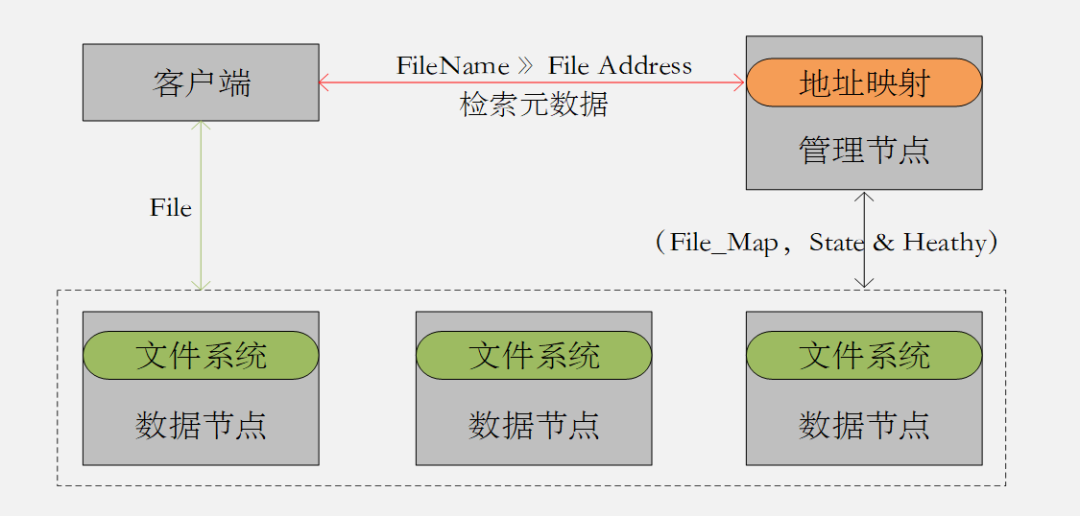
圖2.1 中心化的分布式存儲架構
接下來,我們來看GFS和HDFS都有哪些具體特性,我們應該如何應用?
- GFS是一種適合大文件,尤其是GB級別的大文件存儲場景的分布式存儲系統。
- GFS非常適合對數據訪問延遲不敏感的搜索引擎服務。
- GFS是一種有中心節點的分布式架構,Master節點是單一的集中管理節點,既是高可用的瓶頸,也是可能出現性能問題的瓶頸。
- GFS可以通過緩存一部分Metadata到Client節點,減少Client與Master的交互。
- GFS的Master節點上的Operation log和Checkpoint文件需要通過復制方式保留多個副本,來保障元數據以及中心管理功能的高可用性。
相對于GFS來說,我們來看HDFS做了哪些區別?
- HDFS的默認最小存儲單元為128M,比GFS的64M更大。
- HDFS不支持文件并發寫,對于單個文件它僅允許有一個寫或者追加請求。
- HDFS從2.0版本之后支持兩個管理節點(NameNode),主備切換可以做到分鐘級別。
- HDFS 更適合單次寫多次讀的大文件流式讀取的場景。
- HDFS不支持對已寫文件的更新操作,僅支持對它的追加操作。
2.2 GlusterFS
GlusterFS雖然是基于文件系統的分布式存儲技術,但是它與GFS/HDFS有本質的區別,它是去中心化的無中心分布式架構(圖2.2);它是通過對文件全目錄的DHT算法計算得到相應的Brike地址,從而實現對數據的讀寫;它與Ceph/Swift的架構區別在于它沒有集中收集保存集群拓撲結構信息的存儲區,因此在做計算的時候,需要遍歷整個卷的Brike信息。

圖2.2 Gluster FS
接下來,我們來看GlusterFS都有哪些具體特性,我們應該如何應用?
- GlusterFS是采用無中心對稱式架構,沒有專用的元數據服務器,也就不存在元數據服務器瓶頸。元數據存在于文件的屬性和擴展屬性中 。
- GlusterFS可以提供Raid0、Raid1、Raid1+0等多種類型存儲卷類型。
- GlusterFS采用數據最終一致性算法,只要有一個副本寫完就可以Commit。
- GlusterFS默認會將文件切分為128KB的切片,然后分布于卷對應的所有Brike當中。所以從其設計初衷來看,更適合大文件并發的場景。
- GlusterFS 采用的DHT算法不具備良好的穩定性,一旦存儲節點發生增減變化,勢必影響卷下面所有Brike的數據進行再平衡操作,開銷比較大。
- Gluster FS文件 目錄利用擴展屬性記錄子卷的中brick的hash分布范圍,每個brick的范圍均不重疊。遍歷目錄時,需要獲取每個文件的屬性和擴展屬性進行聚合,當目錄文件 較多 時,遍歷 效率很差 。
2.3 Ceph & Swift
我們知道, 相對于文件系統的中心架構分布式存儲技術,Ceph&Swift都是去中心化的無中心分布式架構(圖2.3);他們底層都是對象存儲技術;他們都是通過對對象的哈希算法得到相應的Bucket&Node地址,從而實現對數據的讀寫 。
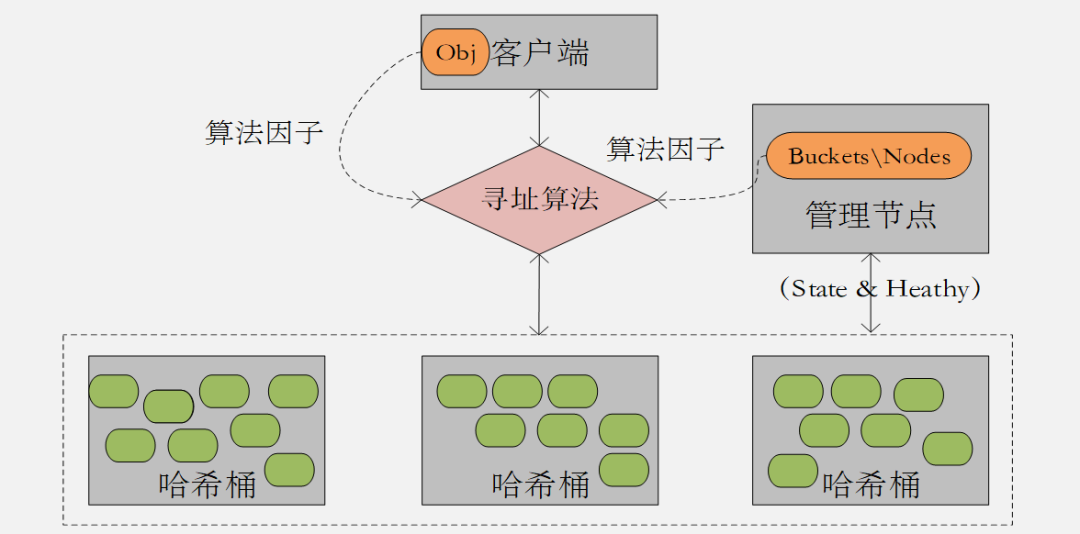
圖2.3 去中心化的分布式存儲架構
接下來,我們來看Ceph和Swift都有哪些具體特性,我們應該如何應用?
- Ceph是一種統一了三種接口的統一存儲平臺,上層應用支持Object、Block、File 。
- Ceph采用Crush算法完成數據分布計算,通過Tree的邏輯對象數據結構自然實現故障隔離副本位置計算,通過將Bucket內節點的組織結構,集群結構變化導致的數據遷移量最小。
- Ceph保持數據強一致性算法,數據的所有副本都寫入并返回才算寫事務的完成,寫的效率會差一些,所以更適合寫少讀多的場景。
- 對象保存的最小單元為4M,相比GFS&HDFS而言,適合一些小的非結構化數據存儲。
雖然底層都是對象存儲,相對于Ceph來說,Swift又有哪些獨特的特性呢?
- Swift只保障數據的最終一致性,寫完2個副本后即可Commit,這就導致讀操作需要進行副本的對比校驗,讀的效率相對較低。
- Swift采用一致性哈希算法完成數據分布計算,通過首次計算對象針對邏輯對象(Zone)的映射實現數據副本的故障隔離分布,然后通過哈希一致性算法完成對象在Bucket當中的分布計算,采用Ring環結構組織Bucket節點組織,數據分布不如Ceph均勻。
- Swift 需要借助Proxy節點完成對數據的訪問,不同于通過客戶端直接訪問數據節點,相對數據的訪問效率來講,比Ceph要差一些。
總結來看,由于Swift需要通過Proxy節點完成與數據節點的交互,雖然Proxy節點可以負載均衡,但是畢竟經歷了中間層,在并發量較大而且小文件操作量比較的場景下,Ceph的性能表現會優秀一些。 為了說明我們從原理層面的判斷,接下來借助ICCLAB&SPLAB的性能測試結果來說明。
表1 Ceph集群配置
| [Node1 - MON] | [Node2 - OSD] | [Node2 - OSD] |
|---|---|---|
| [HDD1: OS] | [HDD1: OS] | [HDD1: OS] |
| [HDD2: not used] | [HDD2: osd.0 - xfs] | [HDD2: osd.2 - xfs] |
| [HDD3: not used] | [HDD3: osd.1 - xfs] | [HDD3: osd.3 - xfs] |
| [HDD4: not used] | [HDD4: journal] | [HDD4: journal] |
表2 Swift集群配置
| [Node1 - Proxy] | [Node2 - Storage] | [Node2 - Storage] |
|---|---|---|
| [HDD1: OS] | [HDD1: OS] | [HDD1: OS] |
| [HDD2: not used] | [HDD2: dev1 - xfs] | [HDD2: dev3 - xfs] |
| [HDD3: not used] | [HDD3: dev2 - xfs] | [HDD3: dev4 - xfs] |
| [HDD4: not used] | [HDD4: not used] | [HDD4: not used] |
以上是測試本身對于Ceph和Swift的節點及物理對象配置信息,從表的對比,基本可以看出物理硬件配置都是相同的,只不過在Swift的配置當中還需要配置Container相關邏輯對象。

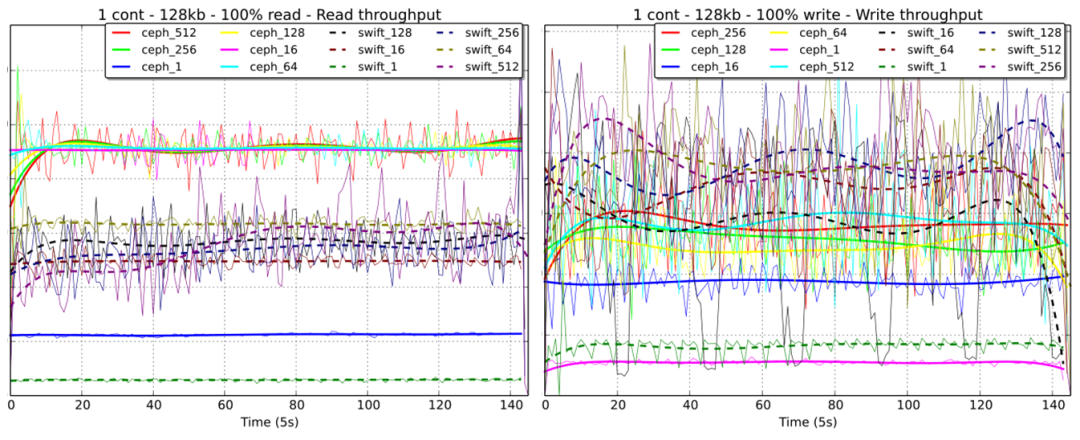
{x}count{y}kb,x表示Swift集群當中設置的Container數量,y表示進行壓力測試所用的數據大小。從圖中表現出來的性能趨勢分析:
- Container的數量越多,Swift的讀寫性能會相對差一些;
- 在4K-128K數據大小的范圍內,Ceph和Swift的讀性能表現都是最佳的;
- 在4K-64K數據大小范圍內,Ceph的讀性能幾乎是Swift的2-3倍,但是寫的性能相差不是非常大。
Ceph_{x}Swift{x},x表示并發數量。從圖中表現出來的性能趨勢分析:
- 對于并發讀操作,Ceph的表現上明顯優于Swift,無論是穩定性還是IOPS指標;
- 對于并發寫操作,Ceph的并發量越高其性能表現越接近Swift,并發量越少其性能表現會明顯遜色于Swift。
- 對于并發讀寫操作的性能穩定性上,Ceph遠勝于Swift。
3 結語
通過對主流分布式存儲技術的各項特性分析梳理之后,我們基本上可以得出以下若干結論:
- GFS/HDFS還是適合特定大文件應用的分布式文件存儲系統(搜索、大數據...);
- GlusterFS是可以代替NAS的通用分布式文件系統存儲技術,可配置性較強;
- Ceph是平衡各個維度之后相對比較寬容的統一分布式存儲技術;
- 分布式存儲技術終究不適合應用到熱點比較集中的關系型數據庫的存儲卷場景上。
-
分布式存儲
+關注
關注
4文章
172瀏覽量
19551 -
HDFS
+關注
關注
1文章
30瀏覽量
9623 -
GFS
+關注
關注
0文章
5瀏覽量
2160
發布評論請先 登錄
相關推薦
常見的分布式供電技術有哪些?
實例分析分布式數據存儲協議對比
深度解讀分布式存儲技術之分布式剪枝系統
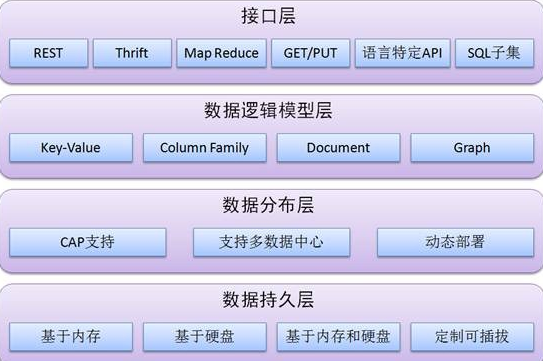
主流分布式存儲技術的對比分析與應用





 工商網監
工商網監
評論