") ChatGPT背后的核心技術(shù)報(bào)告
ChatGPT背后的核心技術(shù)報(bào)告
輸入幾個(gè)簡(jiǎn)單的關(guān)鍵詞,AI能幫你生成一篇短篇小說(shuō)甚至是專(zhuān)業(yè)論文。最近大火的ChatGPT在郵件撰寫(xiě)、文本翻譯、代碼編寫(xiě)等任務(wù)上強(qiáng)大表現(xiàn),讓埃隆·馬斯克都聲稱(chēng)感受到了AI的“危險(xiǎn)”。ChatGPT的計(jì)算邏輯來(lái)自于一個(gè)名為transformer的算法,它來(lái)源于2017年的一篇科研論文《Attention is all your need》。原本這篇論文是聚焦在自然語(yǔ)言處理領(lǐng)域,但由于其出色的解釋性和計(jì)算性能開(kāi)始廣泛地使用在AI各個(gè)領(lǐng)域,成為最近幾年最流行的AI算法模型,無(wú)論是這篇論文還是transformer模型,都是當(dāng)今AI科技發(fā)展的一個(gè)縮影。以此為前提,本文分析了這篇論文的核心要點(diǎn)和主要?jiǎng)?chuàng)新初衷。
01緣起
從Transformer提出到“大規(guī)模與訓(xùn)練模型” GPT(Generative Pre-Training)的誕生,再到GPT2的迭代標(biāo)志Open AI成為營(yíng)利性公司,以及GPT3和ChatGPT的“出圈”;再看產(chǎn)業(yè)界,多個(gè)重要領(lǐng)域比如生物醫(yī)療,智能制造紛紛有以transformer落地的技術(shù)產(chǎn)生。在這個(gè)浪潮下,我的思考是:
一是,未來(lái)很長(zhǎng)一段時(shí)間在智能化領(lǐng)域,我們都將經(jīng)歷“科研、算力、基礎(chǔ)架構(gòu)、工程、數(shù)據(jù)、解決方案”這個(gè)循環(huán)的快速迭代;流動(dòng)性、創(chuàng)新性短期不會(huì)穩(wěn)定下來(lái),而是會(huì)越來(lái)越強(qiáng)。我們很難等到科技封裝好,把這些知識(shí)全部屏蔽掉,再去打磨產(chǎn)品。未來(lái)在競(jìng)爭(zhēng)中獲勝的,將是很好地“解決了產(chǎn)品化和科研及工程創(chuàng)新之間平衡”的團(tuán)隊(duì)。我們一般理解的研發(fā)實(shí)際上是工程,但AI的實(shí)踐科學(xué)屬性需要團(tuán)隊(duì)更好的接納這種“流動(dòng)性”。因此對(duì)所有從業(yè)者或者感興趣智能化的小伙伴了解全棧知識(shí)成了一個(gè)剛需。
二是,通過(guò)對(duì)這篇論文的探討,可以更直觀(guān)地理解:在科研端發(fā)生了什么,以什么樣的速度和節(jié)奏發(fā)生;哪些是里程碑?是科學(xué)界的梅西橫空出世,帶我們發(fā)現(xiàn)真理;哪些是微創(chuàng)新?可能方向明確了,但還有很多空間可以拓展;哪些更像煉金術(shù)?仍然在摸索,尚需要很長(zhǎng)一段時(shí)間,或者一直會(huì)保持這個(gè)狀態(tài)。
三是,在AI領(lǐng)域,由于技術(shù)原因,更多的論文是開(kāi)源代碼的,一方面,促進(jìn)了更多人參與進(jìn)來(lái)改進(jìn)迭代;另一方面,科研跟工程實(shí)現(xiàn)無(wú)縫連接,一篇論文可以拉動(dòng)從核心代碼到平臺(tái),到具體應(yīng)用很大范圍的價(jià)值擴(kuò)散。一篇論文很可能就是一個(gè)領(lǐng)域,一條賽道,甚至直接驅(qū)動(dòng)業(yè)務(wù)價(jià)值和客戶(hù)價(jià)值的大幅提升。
四是, AI技術(shù)發(fā)展有很多領(lǐng)域(感知,認(rèn)知,感知又分圖像、語(yǔ)音、文字等,認(rèn)知也可以分出很多層次)之前這些領(lǐng)域的算法邏輯存在很大差別,transformer的出現(xiàn)有一定程度上推動(dòng)各個(gè)領(lǐng)域匯聚的跡象,介紹清楚這篇論文,對(duì)把握整體可能有些作用。另外ChatGPT屬于現(xiàn)象級(jí)應(yīng)用,大家更有直觀(guān)感受,未來(lái)這類(lèi)應(yīng)用的體驗(yàn)提升和更新速度只會(huì)更快,理解了其背后的邏輯,更有助于我們把握這個(gè)趨勢(shì)。
02 論文介紹
下面步入正題,開(kāi)始介紹這篇論文,會(huì)涉及一些技術(shù)細(xì)節(jié)及公式,可能還需要仔細(xì)看一下(先收藏,留出15-20分鐘比較好),相信一旦看進(jìn)去,你會(huì)對(duì)AI的理解加深很多。
總體把握
這篇論文的結(jié)構(gòu)非常精煉,提出問(wèn)題,分析問(wèn)題,解決問(wèn)題,給出測(cè)試數(shù)據(jù)。頂刊文章講究言簡(jiǎn)意賅,有描述,有代碼,有結(jié)果;其中最核心的是以下這張圖,作者團(tuán)隊(duì)提出transformer的核心算法結(jié)構(gòu):
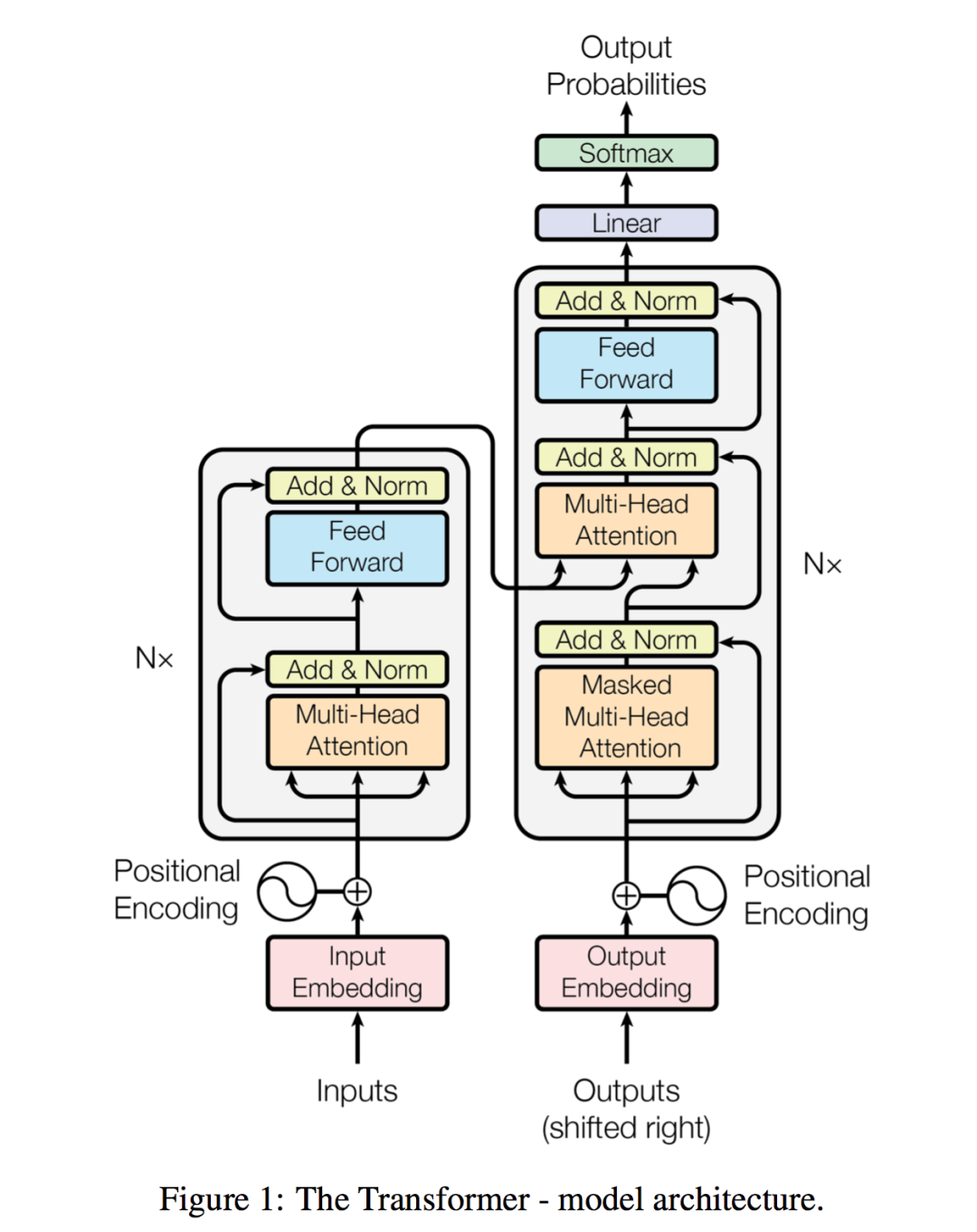
整篇文章就是圍繞這張圖來(lái)進(jìn)行解釋的,由于篇幅所限,我們聚焦在一條主線(xiàn)上:1.文章想解決主要問(wèn)題是什么 2.如何解決的 3.從文章提出的解決方案作為一個(gè)案例來(lái)引發(fā)整體思考,因此我們將內(nèi)容簡(jiǎn)化,主要關(guān)注核心部分。
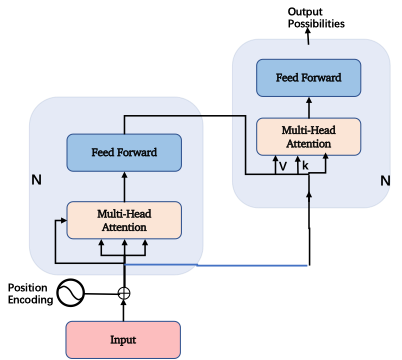
這張圖表達(dá)的內(nèi)容如果理解了,那基本上你掌握了這篇論文85%的內(nèi)容,也是最關(guān)鍵的部分。
《Attention is all your need》在編寫(xiě)時(shí)主要是為了考慮NLP任務(wù),是由幾個(gè)Google的科研人員一起完成的,其中一個(gè)背景是Google也在推廣自己的并行計(jì)算芯片以及AI TensorFlow開(kāi)發(fā)平臺(tái)。平臺(tái)主要功能特點(diǎn)是并行計(jì)算,這篇文章的算法也是在最大限度的實(shí)現(xiàn)并行計(jì)算。我們就以一個(gè)簡(jiǎn)單的例子來(lái)把這個(gè)算法串一遍。
核心內(nèi)容
需求是我們需要訓(xùn)練一個(gè)模型,進(jìn)行中文到英文翻譯。
背景知識(shí):這個(gè)需求要把“翻譯:我愛(ài)你 to I love you”轉(zhuǎn)置成一個(gè)y=f(x)問(wèn)題,x代表中文,y是英文,我們要通過(guò)訓(xùn)練得到f(),一旦訓(xùn)練成功f(),就可以實(shí)現(xiàn)翻譯。大家拼的就是誰(shuí)的訓(xùn)練方法更準(zhǔn)確,更高效,誰(shuí)的f()更好用。
之前自然語(yǔ)言處理主要的算法叫RNN(循環(huán)神經(jīng)網(wǎng)絡(luò)),它主要的實(shí)現(xiàn)邏輯是每個(gè)“字”計(jì)算之后將結(jié)果繼承給第二個(gè)字。算法的弊病是需要大量的串行計(jì)算,效率低。而且當(dāng)遇到比較長(zhǎng)的句子時(shí),前面信息很有可能會(huì)被稀釋掉,造成模型不準(zhǔn)確,也就是對(duì)于長(zhǎng)句子效果會(huì)衰減。這是這篇文章致力于要解決的問(wèn)題,也就是說(shuō)這篇文章有訓(xùn)練處更好的f()的方法。聯(lián)想一下ChatGPT可以做論文,感受一下。
在Transformer里,作者提出了將每個(gè)字與句子中所有單詞進(jìn)行計(jì)算,算出這個(gè)詞與每個(gè)單詞的相關(guān)度,從而確定這個(gè)詞在這個(gè)句子里的更準(zhǔn)確意義。
在此處,要開(kāi)始進(jìn)入一些技術(shù)細(xì)節(jié),在開(kāi)始之前,我們有必要再熟悉一下機(jī)器學(xué)習(xí)領(lǐng)域最核心的一個(gè)概念——“向量”。在數(shù)字化時(shí)代,數(shù)學(xué)運(yùn)算最小單位往往是自然數(shù)字。但在AI時(shí)代,這個(gè)最小單元變成了向量。這是數(shù)字化時(shí)代計(jì)算和智能化時(shí)代最重要的差別之一。
舉個(gè)例子,比如,在銀行,判斷一個(gè)人的信用額度,我們用一個(gè)向量來(lái)表示
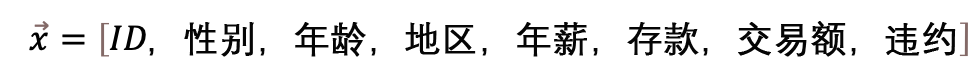
向量是一組數(shù)據(jù)的集合,也可以想象成在一個(gè)超高維度空間里的一個(gè)點(diǎn)。一個(gè)具體的信用額度向量,就是在8個(gè)特征組成的高維空間的一個(gè)點(diǎn)。數(shù)據(jù)在高維空間將展現(xiàn)更多的數(shù)學(xué)性質(zhì)比如線(xiàn)性可分,容易讓我們抓住更多隱藏的規(guī)律。
向量的加減乘除是計(jì)算機(jī)在進(jìn)行樣本訓(xùn)練是最主要的計(jì)算邏輯。
Transformer模型的主要意義就是找到了一個(gè)算法,分成三步把一個(gè)詞逐步定位到了一個(gè)高維空間,在這個(gè)過(guò)程中賦予這個(gè)單詞比其它算法更優(yōu)的信息。很多情況下這個(gè)高維空間有著不同的意義,一旦這個(gè)向量賦予的信息更準(zhǔn)確更接近真實(shí)情況,后面的機(jī)器學(xué)習(xí)工作就很容易展開(kāi)。還拿剛才信用額度向量舉例子

這兩個(gè)向量存在于兩個(gè)不同的向量空間,主要的區(qū)別就是前者多了一個(gè)向量特征:“年薪”。可以思考一下如果判斷一個(gè)人的信用額度,“年薪”是不是一個(gè)很重要的影響因子?
以上例子還是很簡(jiǎn)單的,只是增加了一個(gè)特征值,在transformer里就復(fù)雜很多,它是要把多個(gè)向量信息通過(guò)矩陣加減乘除綜合計(jì)算,從而賦予一個(gè)向量新的含義。
好,理解了向量的重要性,我們看回transformer的三步走,這三步走分別是:1.編碼(Embedding)2. 定位(Positional encoding)3. 自注意力機(jī)制(Self-Attention)。
舉個(gè)例子,比如,翻譯句子Smart John is singing到中文。
首先,要對(duì)句子每個(gè)詞進(jìn)行向量化。
我們先看“John”這個(gè)詞,需要先把“John”這個(gè)字母排列的表達(dá)轉(zhuǎn)換成一個(gè)512維度的向量John,這樣計(jì)算機(jī)可以開(kāi)始認(rèn)識(shí)它。說(shuō)明John是在這個(gè)512維空間的一個(gè)點(diǎn),這是第一步:編碼(Embedding)。
再次,第二步:定位(Positional encoding),利用以下公式(這是這篇論文的創(chuàng)新)
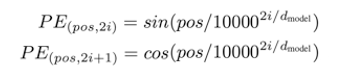
微調(diào)一個(gè)新的高維空間,生成一個(gè)新的向量。

我們不用太擔(dān)心這個(gè)公式,它核心意義是:1.在這個(gè)新的向量里面每一位由原來(lái)的0和1表示,分別取代成由sin和cos表示,這個(gè)目的是可以通過(guò)sin和cos的定律,讓這個(gè)新向量不僅表示John這個(gè)單詞的意義,還可以表示John在Smart John is singing這個(gè)句子的位置信息。如果不理解,可以直接忽略,只要記住第二步是用來(lái)在“表達(dá)John這個(gè)詞的向量”中,加入了John在句子中的位置信息。John已經(jīng)不是一個(gè)孤立的詞,而是一個(gè)具體句子中的一個(gè)詞,雖然還不知道句子中其他詞是什么含義。
如果第一步計(jì)算機(jī)理解了什么是John,第二步計(jì)算機(jī)理解了“* John**”。
最后,第三步:自注意力機(jī)制(Self-Attention),通過(guò)一個(gè)Attention(Q,K,V)算法,再次把John放到一個(gè)新的空間信息里,我們?cè)O(shè)為

在這個(gè)新向量里,不僅包含了John的含義,John在句子中位置信息,更包含了John和句子中每個(gè)單子含義之間的關(guān)系和價(jià)值信息。我們可以理解,John作為一個(gè)詞是一個(gè)泛指,但Smart John就具體了很多,singing的Smart John就又近了一步。而且Attention (Q,K,V)算法,不是對(duì)一個(gè)單詞周?chē)鲇?jì)算,是讓這個(gè)單詞跟句子里所有單詞做計(jì)算。通過(guò)計(jì)算調(diào)整這個(gè)單詞在空間里的位置。
這種方法,可以在一個(gè)超長(zhǎng)句子中發(fā)揮優(yōu)勢(shì),而且最關(guān)鍵的是一舉突破了時(shí)序序列的屏障,以前對(duì)于圖像和NLP算法的劃分,很大程度上是由于NLP有很明顯的時(shí)序特征,即每個(gè)單詞和下一個(gè)以及在下一個(gè)有比較明顯的時(shí)序關(guān)系。但Transformer這種算法打破了這種束縛,它更在意一個(gè)單詞跟句子中每個(gè)單詞的價(jià)值權(quán)重。這是Transformer可以用到everywhere的主要原因。
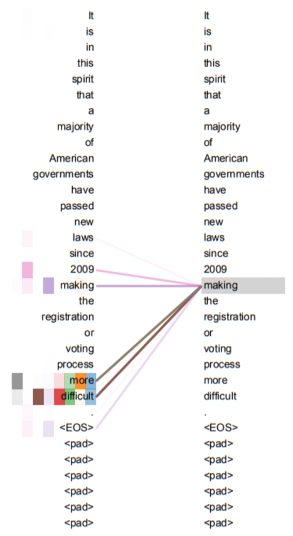
計(jì)算過(guò)程
具體的計(jì)算過(guò)程,用翻譯句子“我愛(ài)你”到“I love you”舉例(這句更簡(jiǎn)單一些)。首先進(jìn)行向量化并吸收句子位置信息,得到一個(gè)句子的初始向量組。
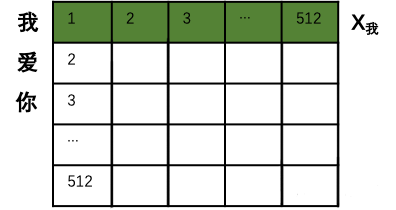
(由于樣本每個(gè)句子長(zhǎng)短不同,所以每個(gè)句子都會(huì)是一個(gè)512*512的矩陣,如果長(zhǎng)度不夠就用0來(lái)代替。這樣在訓(xùn)練時(shí),無(wú)論多長(zhǎng)的句子,都可以用一個(gè)同樣規(guī)模的矩陣來(lái)表示。當(dāng)然512是超參,可以在訓(xùn)練前調(diào)整大小。)
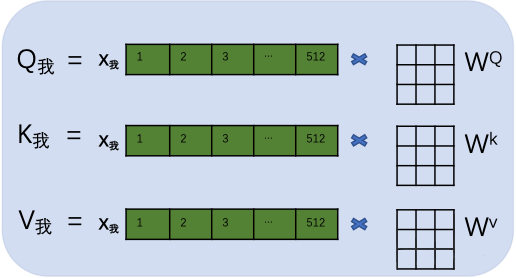
接著,用每個(gè)字的初始向量分別乘以三個(gè)隨機(jī)初始的矩陣WQ,Wk,Wv分別得到三個(gè)量Qx,Kx,Vx。下圖以“我”舉例。
然后,計(jì)算每個(gè)單詞的attention數(shù)值,比如“我”字的attention值就是用“我”字的Q我分別乘以句子中其他單詞的K值,兩個(gè)矩陣相乘的數(shù)學(xué)含義就是衡量?jī)蓚€(gè)矩陣的相似度。然后通過(guò)一個(gè)SoftMax轉(zhuǎn)換(大家不用擔(dān)心如何計(jì)算),計(jì)算出它跟每個(gè)單詞的權(quán)重,這個(gè)權(quán)重比例所有加在一起要等于1。再用每個(gè)權(quán)重乘以相對(duì)應(yīng)的V值。所有乘積相加得到這個(gè)Attention值。
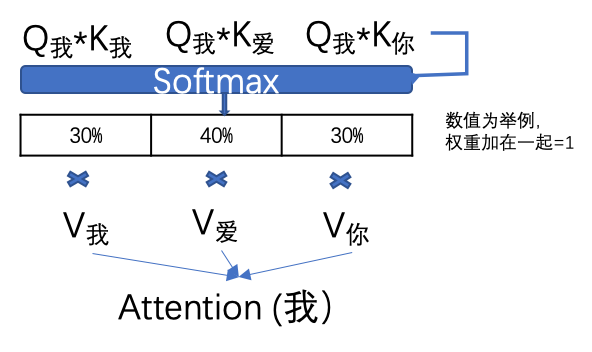
這個(gè)attention數(shù)值就是除了“我”字自有信息和位置信息以外,成功的得到了這個(gè)句子中每個(gè)單詞的相關(guān)度信息。
大家可以發(fā)現(xiàn),在所有注意力系數(shù)的計(jì)算邏輯中其實(shí)只有每個(gè)字的初始矩陣WQ,Wk,Wv是未知數(shù)(這三個(gè)矩陣是所有文字共享的)。那么我們可以把這個(gè)transformer簡(jiǎn)化成一個(gè)關(guān)于輸入,輸出和這個(gè)W矩陣的方程:其中X是輸入文字信息,Y是翻譯信息。

這里有必要再介紹一下機(jī)器學(xué)習(xí)的基礎(chǔ)知識(shí):Transformer算法本質(zhì)上是一個(gè)前饋神經(jīng)網(wǎng)絡(luò)模型,它的計(jì)算基礎(chǔ)邏輯,不去管復(fù)雜的隱藏層,就是假設(shè)Y=f(x)=wx,(目標(biāo)還是要算出一個(gè)f())然后隨機(jī)設(shè)置一個(gè)w0,開(kāi)始計(jì)算這個(gè)y=w0x的成本函數(shù),然后再把w0變成w1,計(jì)算y=w1x的成本函數(shù),以此類(lèi)推計(jì)算出無(wú)數(shù)w(不是無(wú)數(shù),也會(huì)收斂),然后比較哪個(gè)w的成本函數(shù)最小,就是我們訓(xùn)練出來(lái)的f()。那么在transformer里,這三個(gè)初始矩陣就是那個(gè)w0。
再回到transformer,在計(jì)算Attention之后,每個(gè)單詞根據(jù)語(yǔ)義關(guān)系被打入了新的高維空間這就是Self-attention(自注意力機(jī)制)。
但在transformer里,并不是代入了一個(gè)空間,而是代入了多個(gè)高維空間,叫做多頭注意力機(jī)制,(文章中沒(méi)有給出更清晰的理論支持,為什么是多頭)。
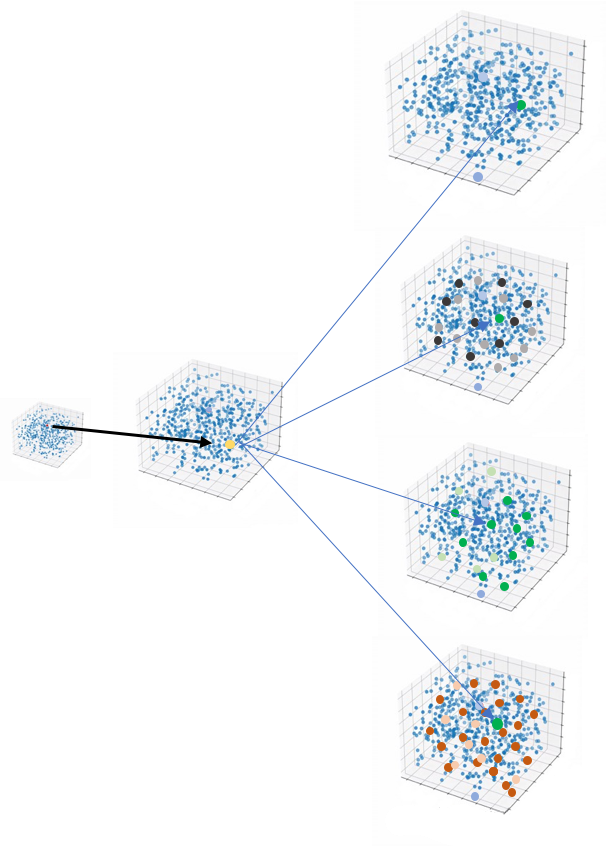
主要原因是在訓(xùn)練時(shí)效果很好。這也是AI科研論文的一個(gè)特點(diǎn),常常憑借非常高的科研素養(yǎng)和敏感性,發(fā)現(xiàn)一些方向,并且通過(guò)測(cè)試確實(shí)有效,但不一定可以給出很完美的理論支撐。這往往也給后續(xù)研究者一些可以進(jìn)一步完善的空間。
事實(shí)證明,如何提升Attention(Q,K,V)效率是transformer領(lǐng)域迭代最快的部分。之后的Bert算法提出預(yù)訓(xùn)練機(jī)制成為了主流,后面會(huì)做進(jìn)一步介紹。
當(dāng)然,事后我們可以理解是把這個(gè)句子中的邏輯關(guān)系放到不同的高維空間去訓(xùn)練,目的就是希望抓取更多的信息,這一部分可以更加深刻理解科研人員對(duì)空間的應(yīng)用。
除了以上內(nèi)容,還有一些技術(shù)點(diǎn)比如Mask機(jī)制、layer norm、神經(jīng)網(wǎng)絡(luò)激函數(shù)飽和區(qū)控制等,由于篇幅關(guān)系以及屬于技術(shù)細(xì)節(jié)就不一一介紹了。
如果大家理解了多頭自注意力機(jī)制,基本已經(jīng)85%掌握了這篇論文的重要內(nèi)容,也對(duì)還在快速擴(kuò)展影響力的transformer模型有了一個(gè)比較直觀(guān)的認(rèn)識(shí)。
03啟發(fā)收獲
從理論科研進(jìn)步的角度看
一、Transformer打破了時(shí)序計(jì)算的邏輯,開(kāi)始快速出圈,多個(gè)AI原本比較獨(dú)立的領(lǐng)域開(kāi)始在技術(shù)上融合。再往里看,Transformer能打破時(shí)序很重要一點(diǎn)是并行計(jì)算的算力模式給更復(fù)雜的計(jì)算帶來(lái)了性?xún)r(jià)比上的可能性。算力的進(jìn)一步提高,必將在AI各細(xì)分領(lǐng)域帶來(lái)融合,更基礎(chǔ)設(shè)施級(jí)別的模型,算法仍將不斷推出。AI領(lǐng)域在圖像,NLP;感知認(rèn)知領(lǐng)域的專(zhuān)業(yè)分工也會(huì)慢慢變模糊。
二、AI科研確實(shí)具有一些實(shí)驗(yàn)性質(zhì)。除了核心思想,確實(shí)還有很多技術(shù)點(diǎn)的解決方向已經(jīng)明確,但還有很大的提升空間,可以預(yù)見(jiàn)圍繞transformer周邊的微創(chuàng)新會(huì)持續(xù)加速繁榮。
三、《Attention is all your need》在業(yè)內(nèi)大名鼎鼎,但你要是細(xì)看,會(huì)發(fā)現(xiàn)很多內(nèi)容也是拿來(lái)主義,比如最重要的Attention(Q,K,V)中Query,Key,Value是互聯(lián)網(wǎng)推薦系統(tǒng)的標(biāo)配方法論;整個(gè)Transformer算法也是一個(gè)大的神經(jīng)網(wǎng)絡(luò),算法是在前人基礎(chǔ)上一步一步迭代發(fā)展,只是這個(gè)迭代速度明顯在加快。
從理論、算法、架構(gòu)、工程的角度看
四、AI算法科研領(lǐng)域正經(jīng)歷算法、開(kāi)源代碼、工程、算力的增長(zhǎng)飛輪。
下圖是頂級(jí)刊物上的學(xué)術(shù)論文中,開(kāi)放源代碼的論文比例,這個(gè)數(shù)據(jù)在這幾年以更快的速度在增長(zhǎng)。科研過(guò)程與工程過(guò)程產(chǎn)生越來(lái)越大的交集。開(kāi)源社區(qū)和開(kāi)源文化本身也在推動(dòng)算法和工程的快速發(fā)展。
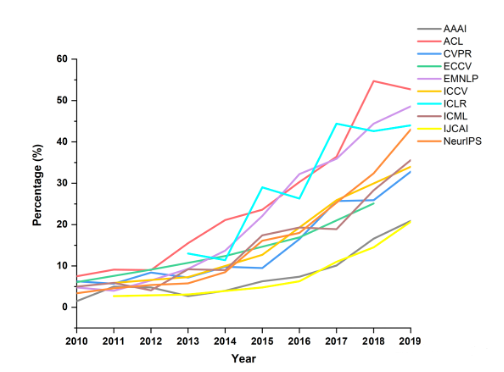
更多人參與,更多領(lǐng)域的人參與進(jìn)來(lái),進(jìn)入門(mén)檻隨著算力成本、AI基礎(chǔ)架構(gòu)和代碼、知識(shí)分享的開(kāi)源逐漸降低,科研與工程的邊界也變得模糊,這個(gè)就像足球運(yùn)動(dòng)的規(guī)律,除了足球人口增多,天才球員梅西出現(xiàn)的概率也會(huì)增大。
從數(shù)據(jù)和后續(xù)發(fā)展的角度看
五、ChatGPT的成功同大量的數(shù)據(jù)訓(xùn)練功不可沒(méi),但除了簡(jiǎn)單對(duì)話(huà)互動(dòng)或者翻譯,大篇幅回答甚至論文級(jí)別的答案還是極其缺乏樣本數(shù)據(jù)(算法訓(xùn)練需要的樣本數(shù)據(jù)需要清晰度X和Y)。而且Transformer的算法相比其他算法需要更大的數(shù)據(jù)量,原因在于它需要起始階段隨機(jī)產(chǎn)生三個(gè)矩陣,一步一步進(jìn)行優(yōu)化。除了Transformer以外,另一個(gè)技術(shù)Bert也是技術(shù)發(fā)展非常重要的現(xiàn)象級(jí)算法。其核心是一個(gè)簡(jiǎn)化的Transformer,Bert不去做從A翻譯到B,它隨機(jī)遮住X里面的一些單詞或句子讓算法優(yōu)化對(duì)遮住部分的預(yù)測(cè)。這種思路使得Bert成為了Transformer預(yù)訓(xùn)練最好的搭檔。
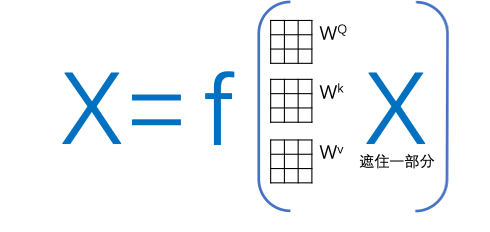
如果通過(guò)Bert進(jìn)行預(yù)訓(xùn)練,相當(dāng)于給矩陣加入了先驗(yàn)知識(shí)(之前訓(xùn)練邏輯沒(méi)有給機(jī)器任何提示,規(guī)則后者基礎(chǔ)知識(shí)),提高了正式訓(xùn)練時(shí)初始矩陣的準(zhǔn)確度,極大地提升了之后transformer的計(jì)算效率和對(duì)數(shù)據(jù)量的要求。在現(xiàn)實(shí)中,舉例來(lái)說(shuō),如果我想訓(xùn)練國(guó)家圖書(shū)館圖書(shū),之前需要每本書(shū)的信息和對(duì)這本書(shū)的解釋?zhuān)蛘咧形臅?shū)對(duì)應(yīng)的英文書(shū)。但現(xiàn)在我們可以大量只是訓(xùn)練內(nèi)容,不需要打標(biāo)簽,之后只需要通過(guò)transformer對(duì)樣本數(shù)據(jù)進(jìn)行微調(diào)。這就給ChatGPT很大的進(jìn)步空間,而且可以預(yù)見(jiàn),更多這類(lèi)大模型會(huì)雨后春筍一般快速出現(xiàn)。
六、由于transformer是更高級(jí)的神經(jīng)網(wǎng)絡(luò)深度學(xué)習(xí)算法,對(duì)數(shù)據(jù)量有很高要求,這也催生了從小數(shù)據(jù)如何快速產(chǎn)生大數(shù)據(jù)的算法,比如GAN對(duì)抗網(wǎng)絡(luò)等。這是AIGC領(lǐng)域的核心技術(shù)。解決數(shù)據(jù)量不足問(wèn)題,除了更高效率抽象小數(shù)據(jù)的信息,也多了把小數(shù)據(jù)補(bǔ)足成大數(shù)據(jù)的方法,而且這些方法在快速成熟。
七、我們發(fā)現(xiàn)在機(jī)器學(xué)習(xí)算法中有大量的超級(jí)參數(shù),比如在transformer里多頭機(jī)制需要幾頭N,文字變成向量是512還是更多,學(xué)習(xí)速率等都需要在訓(xùn)練之前提前設(shè)置。由于訓(xùn)練時(shí)間長(zhǎng),參數(shù)復(fù)雜,要想遍歷更優(yōu)秀的計(jì)算效果需要非常長(zhǎng)的摸索時(shí)間。這就催生出AutoML,拿Transformer舉例,就要很多個(gè)路線(xiàn)進(jìn)行自動(dòng)化機(jī)器學(xué)習(xí);比如貝葉斯計(jì)算(找到更優(yōu)參數(shù)配置概率);強(qiáng)化學(xué)習(xí)思路(貪婪算法在環(huán)境不明朗情況下迅速逼近最優(yōu));另外還有尋求全新訓(xùn)練網(wǎng)絡(luò)的方法(transformer,RNN,MLP等聯(lián)合使用排列組合)等。
科研發(fā)展強(qiáng)調(diào)參數(shù)化,工業(yè)發(fā)展強(qiáng)調(diào)自動(dòng)化,這兩者看似統(tǒng)一,但在現(xiàn)實(shí)實(shí)操過(guò)程中往往是相當(dāng)痛苦矛盾的。這也是開(kāi)篇說(shuō)的產(chǎn)品化和科研流動(dòng)性相平衡的一個(gè)重要領(lǐng)域。
審核編輯 :李倩
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8438瀏覽量
132900 -
ai技術(shù)
+關(guān)注
關(guān)注
1文章
1289瀏覽量
24394 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1566瀏覽量
7925
原文標(biāo)題:ChatGPT背后的核心技術(shù)報(bào)告(附下載)
文章出處:【微信號(hào):WUKOOAI,微信公眾號(hào):悟空智能科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
從MCU到SoC:汽車(chē)芯片核心技術(shù)的深度剖析

晶沛自主研發(fā)氣液集成滑環(huán)關(guān)鍵核心技術(shù)分析

ChatGPT背后的AI背景、技術(shù)門(mén)道和商業(yè)應(yīng)用

新能源汽車(chē)小三電的核心技術(shù)
精準(zhǔn)定位,深度清潔:揭秘工廠(chǎng)清潔機(jī)器人的核心技術(shù)
AI網(wǎng)絡(luò)發(fā)展的四大核心技術(shù)支柱
圖像識(shí)別算法的核心技術(shù)是什么
OpenAI 深夜拋出王炸 “ChatGPT- 4o”, “她” 來(lái)了
【大語(yǔ)言模型:原理與工程實(shí)踐】核心技術(shù)綜述

在FPGA設(shè)計(jì)中是否可以應(yīng)用ChatGPT生成想要的程序呢
學(xué)習(xí)鴻蒙背后的價(jià)值?星河版開(kāi)放如何學(xué)習(xí)?
安達(dá)發(fā)|APS生產(chǎn)排程軟件6大核心技術(shù)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論