 模擬技術學習
模擬技術學習
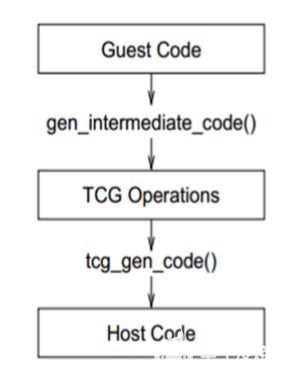
QEMU架構和內部
快速模擬(QEMU)
機器模擬器+虛擬器
模式:
用戶模式模擬:允許為一個CPU構建的進程被另一個CPU執行
QEMU作為進程模擬器
系統模式模擬:允許模擬一個完整的系統,包括處理器和各種外圍設備
QEMU作為系統模擬器
常用:
用于交叉編譯開發環境
虛擬化,特別是設備模擬,象xen和kvm
安卓模擬器(SDK的一部分)
動態二進制翻譯
動態翻譯
第一種解釋
以副產品的形式執行代碼發現
翻譯代碼
象它被發現的那樣遞增的
將翻譯后的塊放入代碼緩存中
把源到目標主機的映射保存到地址查詢表中
模擬過程
運行完已經翻譯的塊
在表里尋找下一個資源主機
如果已經翻譯了,跳轉到目標主機
沒有就直接翻譯
象JIT編譯器一樣工作,但是不包括解釋器
所有的客戶代碼都要經過二進制翻譯
客戶代碼被劃分成翻譯塊
一個翻譯塊和基本塊相似,因為都是作為一個整體執行(整個塊中沒有跳轉)
翻譯塊被翻譯成一個單獨的主機指令序列,被緩存到翻譯緩存中。
緩存塊使用客戶虛擬地址(PC計數),所以他們能很容易的被發現
翻譯塊的緩存大小能夠改變(通常是32M)
一旦緩存用完,整個緩存區清零

先將源指令流(二進制)轉換成更短小且更加簡易的操作,即微指令(C語言),被GCC編譯成對象文件(二進制),最后QEMU將對象文件鏈接成目標的指令流(二進制)。
功能模擬
模擬處理器做的工作,而不是處理器怎么做
動態二進制翻譯
解釋器一次執行一條指令
固定的開銷顯著降低
反而,QEMU根據需要轉換代碼
翻譯基本塊 產生本地主機代碼‘
把翻譯塊存儲到翻譯緩存中
微小代碼發生器(TCG)
微操作(微指令)
固定的寄存器映射能夠降低負載和存儲字符串
翻譯塊
一個TCG基本塊對應著一個被分支指令終止的指令列表
塊鏈接


cpu_exec() 在主函數的每一步都被調用
項目會一直執行除非遇到一個未連接的塊
通過 結尾返回cpu_exec()
塊鏈接
通常來說,每一個翻譯塊的執行都伴隨這很多特殊代碼塊的執行
開始時初始化處理器來執行產生的主機代碼,并跳轉到代碼塊
結束時恢復正常狀態并返回到主循環
返回主循環后,每一個塊顯著的增加了開銷,增長的還很快
當一個塊返回主循環,下一個塊已經知道并且已經被翻譯,QEMU能夠修改源代碼來直接跳轉到下一個塊,而不是跳轉到結尾
直接在基本塊之間跳轉
為跳轉準備空間,然后回到結尾
每一次一個塊返回,都要嘗試鏈接它
當是發生在幾個連續的塊上時,這些塊會形成鏈接和循環
這允許QEMU模擬緊密的循環,而不需要運行額外的代碼
在循環的條件下,這也意味除非執行到一個沒有翻譯或者沒有鏈接的塊,這個控件不會返回到QEMU
異步中斷
如果一個硬件中斷被掛起,QEMU不會檢查每一個基本塊。反而,用戶必須要調用一個特殊的功能來告訴說有個中斷被掛起
這個功能重置了當前執行的塊的鏈接,返回到控制CPU模擬的主循環
寄存器映射
如果目標寄存器的數目大于源寄存器的數目(例如:翻譯x86的二進制到RISC)(RISC精簡指令集)
當目標寄存器的數量不夠時,可能會基于每一個塊,或者每一個追蹤,或者每一個循環
不常用的寄存器(源)可能沒有映射
如何處理項目計數器
目標主機不同于源主機
對于間接的分支,寄存器持有源主機 一定會提供一種將源主機映射到目標主機的方法
翻譯系統需要時刻追蹤源主機
其它主要組件
內存地址轉換
由軟件控制的MMU(模型)將目標虛擬地址翻譯成主機虛擬地址
兩級客戶物理頁描述符表
客戶虛擬地址和主機虛擬地址之間的映射
地址轉換緩存(tlb_table)直接將目標虛擬地址翻譯成主機虛擬地址
客戶虛擬地址和該設備注冊的I/O功能之間的映射
用于內存I/O映射的緩存(iotlb)
設備模擬
i440FX主機PCI網橋,Cirrus CLGD 5446 PCI VGA卡,PS/2鼠標和鍵盤,PCI IDE接口(HDD, CDROM), PCI和ISA網絡適配器,串口,PCI UHCI USB控制器和虛擬USB hub,…
軟件地址轉換
虛擬到物理地址的轉換時在每一次內存訪問時完成的
地址轉換緩存加速了轉換
為了避免每次MMU映射改變時刷新已經翻譯代碼的緩存,QEMU使用的是物理索引的翻譯緩存
每一個基礎塊都使用他的物理地址索引
當MMU映射改變時,只有基礎塊的鏈接被重置,(例如一個基礎塊不能直接跳轉到另一個)

QEMU存儲堆棧

應用和客戶內核的工作類似于裸金屬
客戶通過仿真硬件與QEMU對話
QEMU代表客戶對一個鏡像文件執行I/O
主機內核對待客戶I/O就像任何用戶應用程序一樣

來源:csdn,qq_40316844
審核編輯 :李倩
-
二進制
+關注
關注
2文章
795瀏覽量
41719 -
C語言
+關注
關注
180文章
7614瀏覽量
137386 -
模擬器
+關注
關注
2文章
881瀏覽量
43333
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論