 【AI簡報第20230210期】 ChatGPT爆火背后、為AIoT和邊緣側AI喂算力的RISC-V
【AI簡報第20230210期】 ChatGPT爆火背后、為AIoT和邊緣側AI喂算力的RISC-V
1. ChatGPT爆火背后:AI芯片迎接算力新挑戰
原文:
https://www.163.com/dy/article/HT7BHN3C05199NPP.html
ChatGPT的出圈走紅為AIGC打開全新市場增量,催生了更高的算力需求。
作為人工智能三大核心要素之一,算力也被譽為人工智能“發動機”。華泰證券研報顯示,根據OpenAI測算,自2012年以來,全球頭部AI模型訓練算力需求3-4個月翻一番,每年頭部訓練模型所需算力增長幅度高達10倍。AI深度學習正在逼近現有芯片的算力極限,也對芯片設計廠商提出了更高要求。
由此可見,AIGC未來進一步的應用和普及離不開算力的強勁支撐。受下游算力需求高漲消息影響,2月9日,半導體及元件板塊再度轉頭向上,整體上漲4.58%。截至當日收盤,半導體及元件板塊近一周漲幅2.53%。
板塊走勢的分化也體現出市場對AI芯片的態度。近日,在接受21世紀經濟報道記者采訪時,多家AI芯片廠商表示,AIGC等相關業務需要結合下游最終端應用的實際情況考慮。
“大模型動輒千萬美元起步的基礎設施建設投入和海量的訓練數據需求,也注定了它極高的研發門檻。”百度昆侖芯方面向21世紀經濟報道記者指出,“(大模型)對計算的要求主要體現在三個方面,一是算力,二是互聯,三是通用性,對于昆侖芯來說,場景需求一直是架構研發、產品迭代的最重要的‘指南針’。”
科技新賽道
AIGC(Artificial Intelligence Generated Content)指的是人工智能系統生成的內容,是繼 UGC、PGC 之后的新型內容創作方式,包括文字、圖像、音頻或視頻等。AIGC可以通過自然語言處理、機器學習和計算機視覺等技術幫助AI系統識別理解輸入內容,并生成“創作”全新的內容。
目前,AIGC已在多應用領域實現落地,2022年更是被AI業內人士稱作AIGC“元年”。2022年8月,文本生成圖像模型Stable Diffusion火爆出圈,催生了AI作畫的熱潮;12月,OpenAI推出的人工智能聊天機器人模型 ChatGPT ,可以使用大量訓練數據模擬人類語言行為,通過語義分析生成文本從而與用戶進行自然交互,在全球范圍內掀起AIGC的熱潮。
隨著人工智能應用向縱深發展,對AI模型訓練所需要的算力支持提出了更高要求。
作為算力的硬件基石,AI芯片是針對人工智能算法做了特殊加速設計的芯片。信達證券發布研究報告稱,在技術架構層面,AI芯片可以分為 GPU(圖形處理器)、FPGA(現場可編程門陣列)、ASIC(專用集成電路)和類腦芯片,同時CPU也可用以執行通用AI計算。
在應用層面,AI芯片又可以劃分為云端、邊緣端和終端三個類型,不同場景對芯片的算力和功耗的要求不同,單一芯片難以滿足實際應用的需求。
在云端層面,由于大多數AI訓練和推理工作負載都在此進行,需要運算巨量、復雜的數據信息,因此對于 AI 芯片的性能和算力要求最高;邊緣端是指處理云端和終端之間的傳輸網絡,承擔著匯集、分析處理和通信傳輸數據的功能,一定程度上分擔云端的壓力,降低成本、提升效率。
終端AI芯片由于直面下游產品,大多以實際需求為導向,主要應用于消費電子、智能駕駛、智能家居和智慧安防等領域,終端產品類型和出貨量的增加,也相應刺激了對芯片的需求。
信達證券研究團隊總結稱,AIGC 推動 AI 產業化由軟件向硬件切換,半導體+AI 生態逐漸清晰,AI芯片產品將實現大規模落地。據前瞻產業研究院的數據,我國人工智能芯片的市場規模增速驚人,到2024 年,將達到785 億元。
2. 不出所料,自動駕駛向ChatGPT下手了!
原文:
https://mp.weixin.qq.com/s/a5A2mfG8WQElIuo5vT2s7w
ChatGPT 的技術思路與自動駕駛能碰撞出什么樣的火花呢?
去年底,ChatGPT 橫空出世。真實自然的人機對話、比擬專家的回答以及一本正經的胡說八道,使它迅速走紅,風靡全世界。
不像之前那些換臉、捏臉、詩歌繪畫生成等紅極一時又很快熱度退散的 AIGC 應用,ChatGPT 不僅保持了熱度,而且還有全面爆發的趨勢。現如今,谷歌、百度的 AI 聊天機器人已經在路上。

比爾蓋茨如此盛贊:「ChatGPT 的意義不亞于 PC 和互聯網誕生。
為什么呢?
首先,人機對話實在是剛需。人工智能技術鼻祖的圖靈所設計的「圖靈測試」,就是試圖通過人機對話的方式來檢驗人工智能是否已經騙過人類。能從人機問題中就能獲得準確答案,這可比搜索引擎給到一大堆推薦網頁和答案更貼心了。要知道懶惰乃人類進步的原動力。
其次,ChatGPT 實在是太能打了。不僅在日常語言當中,ChatGPT 能夠像人類一樣進行聊天對話,還能生成各種新聞、郵件、論文,甚至進行計算和編寫代碼,這簡直就像小朋友抓到一只「哆啦 A 夢」—— 有求必應了。
除了看看熱鬧,我們也可以弱弱地問一句:ChatGPT 為啥這么能打呢?希望大家可以在原文中找到答案。
3. 為AIoT和邊緣側AI喂算力的RISC-V
原文:
https://mp.weixin.qq.com/s/qQWahKqVkkS7bToN7-eHQQ
在去年底由晶心科技舉辦的RISC-V CON上,英特爾RISC-V投資部門的總經理Vijay Krishnan闡述了自己的Pathfinder for RISC-V計劃。通過搭建這個平臺,英特爾將助力解決RISC-V軟件開發生態上的挑戰,并表示首先側重于AIoT和邊緣端市場。
但我們也都知道這一計劃持續不到半年就被砍了,可即便如此,RISC-V在AIoT領域的探索也早早就已經處于進行時了。針對AIoT和邊緣側AI開發的RISC-V芯片、開發板也都紛紛上市,為RISC-V搶占這一市場的份額添磚加瓦。
GreenWave-GAP9
法國公司GreenWave作為一家面向電池供電IoT設備市場的廠商,主要產品就是超低功耗的RISC-V應用處理器,GAP系列。他們率先推出的GAP8就是一個用于大規模智能邊緣設備部署的IoT應用處理器,但由于算力并不高,所以只能負責一些占用管理、人臉識別、關鍵詞識別之類的簡單任務。
而他們的第二代產品GAP9則是一款為TWS降噪耳機設計的RISC-V芯片,做到超低延遲的同時,使用神經網絡來完成聲學場景檢測、降噪、3D環繞和ASRC等功能。其實用于高端TWS耳機主動降噪的低延遲RISC-V早已面世并大規模出貨了,即中科藍訊的藍訊迅龍系列。而GreenWave的GAP9為了進一步增加算力,則在其架構中塞入了1個RISC-V控制器核心,9個RISC-V計算核心和AI加速器。

嘉楠-勘智K510
嘉楠的勘智K210作為2019年發布的一款RISC-V芯片,采用了雙核64位CPU的算力,在300mW的功耗下即實現了1TOPS的算力。而且在神經網絡加速器KPU的助力下,該芯片可以直接在本地處理人臉識別、圖像識別等機器視覺任務,可廣泛應用于門禁、智能水電表等應用中,陸吾智能甚至將其用于XGOmini這樣的四足機器狗中。
而嘉楠科技于2021年發布的勘智K510,則是一款定位中高端邊緣AI推理的芯片,將其神經網絡加速器KPU升級到了2.0版本,不僅降低了芯片功耗,還將算力提升了3倍,單芯片算力高達2.5TFLOPS,支持INT8和BF16兩種精度,也支持TensorFlow、PyTorch等主流框架。

可以說,K510的出現,進一步增加了在AIoT和邊緣側AI上的算力和精度。而且由于K510還搭載了3D ISP,可以進行圖像降噪、畸變矯正等處理任務,對于AIoT和邊緣側AI常見的低照度環境和廣角鏡頭來說起到了決定性的作用。像上面提到的機器狗應用,也可以因為這龐大的算力來完成更復雜的手勢識別、人體姿態識別等工作。
小結
從RISC-V在AIoT目前的布局情況來看,產品主要面向TWS、音頻/圖像檢測與識別、智能抄表和智能家居等對AI算量不高的應用,但它們仍在繼續推進更高的算力和更多的深度學習框架支持。相信在優秀RISC-V IP核、低功耗、可編程和向量擴展等優勢的吸引下,未來我們能在該領域看到更多的RISC-V產品。
固然RISC-V在AIoT這個市場已經取得了不小的進展,也有了與主流的Arm生態一戰之力,但后者的智能生態依然是全方位的。在超低功耗的IoT設備和傳感器應用上,RISC-V至少在性能上已經不輸于人了。但到了智能設備、智能網關、本地服務器乃至云端,需要的AI算力是成倍提升的,雖然不少RISC-V IP廠商都已經開始主推AI核心了,但我們仍然需要更多落地的RISC-V AI處理器。
4. 強化學習中的Transformer發展到哪一步了?清華、北大等聯合發布TransformRL綜述
原文:
https://mp.weixin.qq.com/s/v7QJIAy7xctByJZ9lz9viQ
論文地址:
https://arxiv.org/pdf/2301.03044.pdf
強化學習(RL)為順序決策提供了一種數學形式,深度強化學習(DRL)近年來也取得巨大進展。然而,樣本效率問題阻礙了在現實世界中廣泛應用深度強化學習方法。為了解決這個問題,一種有效的機制是在 DRL 框架中引入歸納偏置。
在深度強化學習中,函數逼近器是非常重要的。然而,與監督學習(SL)中的架構設計相比,DRL 中的架構設計問題仍然很少被研究。大多數關于 RL 架構的現有工作都是由監督學習 / 半監督學習社區推動的。例如,在 DRL 中處理基于高維圖像的輸入,常見的做法是引入卷積神經網絡(CNN)[LeCun et al., 1998; Mnih et al., 2015];處理部分可觀測性(partial observability)圖像的常見做法則是引入遞歸神經網絡(RNN) [Hochreiter and Schmidhuber, 1997; Hausknecht and Stone, 2015]。
近年來,Transformer 架構 [Vaswani et al., 2017] 展現出優于 CNN 和 RNN 的性能,成為越來越多 SL 任務中的學習范式 [Devlin et al., 2018; Dosovitskiy et al., 2020; Dong et al., 2018]。Transformer 架構支持對長程(long-range)依賴關系進行建模,并具有優異的可擴展性 [Khan et al., 2022]。受 SL 成功的啟發,人們對將 Transformer 應用于強化學習產生了濃厚的興趣,希望將 Transformer 的優勢應用于 RL 領域。
Transformer 在 RL 中的使用可以追溯到 Zambaldi 等人 2018 年的一項研究,其中自注意力(self-attention)機制被用于結構化狀態表征的關系推理。隨后,許多研究人員尋求將自注意力應用于表征學習,以提取實體之間的關系,從而更好地進行策略學習 [Vinyals et al., 2019; Baker et al., 2019]。
除了利用 Transformer 進行表征學習,之前的工作還使用 Transformer 捕獲多時序依賴,以處理部分可觀測性問題 [Parisotto et al., 2020; Parisotto and Salakhutdinov, 2021]。離線 RL [Levine et al., 2020] 因其使用離線大規模數據集的能力而受到關注。受離線 RL 的啟發,最近的研究表明,Transformer 結構可以直接作為順序決策的模型 [Chen et al., 2021; Janner et al., 2021] ,并推廣到多個任務和領域 [Lee et al., 2022; Carroll et al., 2022]。
實際上,在強化學習中使用 Transformer 做函數逼近器面臨一些特殊的挑戰,包括:
強化學習智能體(agent)的訓練數據通常是當前策略的函數,這在學習 Transformer 的時候會導致不平穩性(non-stationarity);
現有的 RL 算法通常對訓練過程中的設計選擇高度敏感,包括模型架構和模型容量 [Henderson et al., 2018];
基于 Transformer 的架構經常受制于高性能計算和內存成本,這使得 RL 學習過程中的訓練和推理都很昂貴。
例如,在用于視頻游戲的 AI 中,樣本生成的效率(在很大程度上影響訓練性能)取決于 RL 策略網絡和估值網絡(value network)的計算成本 [Ye et al., 2020a; Berner et al., 2019]。
為了更好地推動強化學習領域發展,來自清華大學、北京大學、智源人工智能研究院和騰訊公司的研究者聯合發表了一篇關于強化學習中 Transformer(即 TransformRL)的綜述論文,歸納總結了當前的已有方法和面臨的挑戰,并討論了未來的發展方向,作者認為 TransformRL 將在激發強化學習潛力方面發揮重要作用。

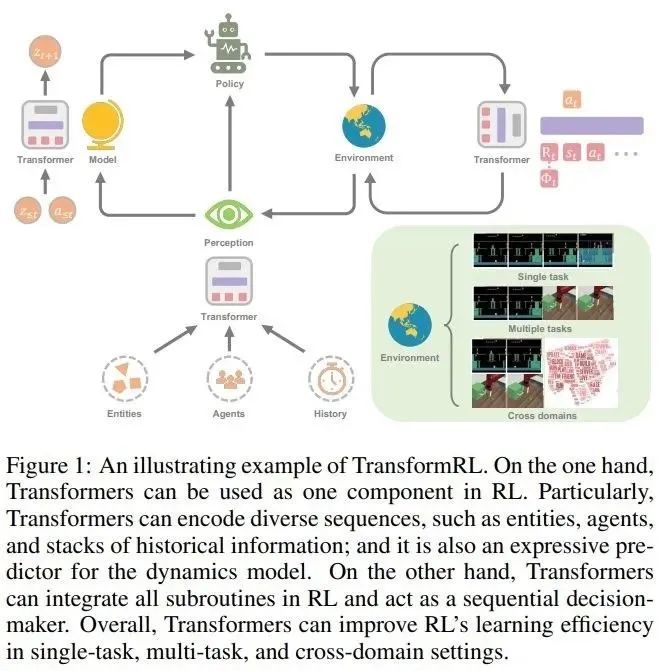
論文的總體結構如下:
第 2 章介紹了 RL 和 Transformer 的背景知識,然后簡要介紹了這兩者是如何結合在一起的;
第 3 章描述了 RL 中網絡架構的演變,以及長期以來 RL 中阻礙廣泛探索 Transformer 架構的挑戰;
第 4 章論文作者對 RL 中的 Transformer 進行了分類,并討論了目前具有代表性的方法;
第 5 章總結并指出了未來潛在的研究方向。
5. 首個快速知識蒸餾的視覺框架:ResNet50 80.1%精度,訓練加速30%
原文:
https://mp.weixin.qq.com/s/HWVpVOsYTOH98aU0tC_LzA
論文和項目網址:
http://zhiqiangshen.com/projects/FKD/index.html
代碼:
https://github.com/szq0214/FKD

知識蒸餾(KD)自從 2015 年由 Geoffrey Hinton 等人提出之后,在模型壓縮,視覺分類檢測等領域產生了巨大影響,后續產生了無數相關變種和擴展版本,但是大體上可以分為以下幾類:vanilla KD,online KD,teacher-free KD 等。最近不少研究表明,一個最簡單、樸素的知識蒸餾策略就可以獲得巨大的性能提升,精度甚至高于很多復雜的 KD 算法。但是 vanilla KD 有一個不可避免的缺點:每次 iteration 都需要把訓練樣本輸入 teacher 前向傳播產生軟標簽 (soft label),這樣就導致很大一部分計算開銷花費在了遍歷 teacher 模型上面,然而 teacher 的規模通常會比 student 大很多,同時 teacher 的權重在訓練過程中都是固定的,這樣就導致整個知識蒸餾框架學習效率很低。
針對這個問題,本文首先分析了為何沒法直接為每張輸入圖片產生單個軟標簽向量然后在不同 iterations 訓練過程中復用這個標簽,其根本原因在于視覺領域模型訓練過程數據增強的使用,尤其是 random-resize-cropping 這個圖像增強策略,導致不同 iteration 產生的輸入樣本即使來源于同一張圖片也可能來自不同區域的采樣,導致該樣本跟單個軟標簽向量在不同 iterations 沒法很好的匹配。本文基于此,提出了一個快速知識蒸餾的設計,通過特定的編碼方式來處理需要的參數,繼而進一步存儲復用軟標簽(soft label),與此同時,使用分配區域坐標的策略來訓練目標網絡。通過這種策略,整個訓練過程可以做到顯式的 teacher-free,該方法的特點是既快(16%/30% 以上訓練加速,對于集群上數據讀取緩慢的缺點尤其友好),又好(使用 ResNet-50 在 ImageNet-1K 上不使用額外數據增強可以達到 80.1% 的精度)。
首先我們來回顧一下普通的知識蒸餾結構是如何工作的,如下圖所示:
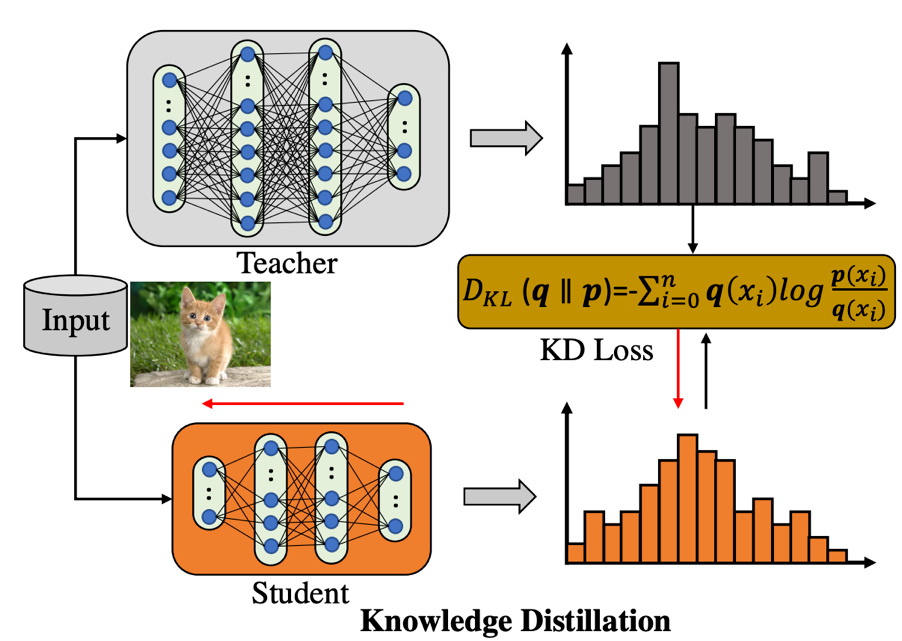
知識蒸餾框架包含了一個預訓練好的 teacher 模型(蒸餾過程權重固定),和一個待學習的 student 模型, teacher 用來產生 soft 的 label 用于監督 student 的學習。可以看到,這個框架存在一個比較明顯的缺點:當 teacher 結構大于 student 的時候,訓練圖像前饋產生的計算開銷已經超過 student,然而 teacher 權重并不是我們學習的目標,導致這種計算開銷本質上是 “無用的”。本文的動機正是在研究如何在知識蒸餾訓練過程中避免或者說重復利用這種額外的計算結果,該文章的解決策略是提前保存每張圖片不同區域的軟監督信號(regional soft label)在硬盤上,訓練 student 過程同時讀取訓練圖片和標簽文件,從而達到復用標簽的效果。所以問題就變成了:soft label 怎么來組織和存儲最為有效?請從原文中找到答案。
6. Google Brain提出基于Diffusion的新全景分割算法
原文:
https://mp.weixin.qq.com/s/CXMzZd0JP0XBJzEPhPmLvA
A Generalist Framework for Panoptic Segmentation of Images and Videos
標題:
A Generalist Framework for Panoptic Segmentation of Images and Videos
作者:
Ting Chen, Lala Li, Saurabh Saxena, Geoffrey Hinton, David J. Fleet
原文鏈接:
https://arxiv.org/pdf/2210.06366.pdf
引言
首先回顧一下全景分割的設定。全景分割(PS,Panoptic Segmentation)的task format不同于經典的語義分割,它要求每個像素點都必須被分配給一個語義標簽(stuff、things中的各個語義)和一個實例id。具有相同標簽和id的像素點屬于同一目標;對于stuff標簽,不需要實例id。與實例分割相比,目標的分割必須是非重疊的(non-overlapping),因此對那些每個目標單獨標注一個區域是不同的。雖然語義標簽的類類別是先驗固定的,但分配給圖像中對象的實例 ID 可以在不影響識別的實例的情況下進行排列。因此,經過訓練以預測實例 ID 的神經網絡應該能夠學習一對多映射,從單個圖像到多個實例 ID 分配。一對多映射的學習具有挑戰性,傳統方法通常利用涉及對象檢測、分割、合并多個預測的多個階段的管道這有效地將一對多映射轉換為基于識別匹配的一對一映射。這篇論文的作者將全景分割任務制定為條件離散數據生成問題,如下圖所示。本文是大名鼎鼎的Hinton參與的工作,非常有意思,又是基于diffusion model模式的生成模型來完成全景分割,將mask其視為一組離散標記,以輸入圖像為條件,預測得到完整的分割信息。
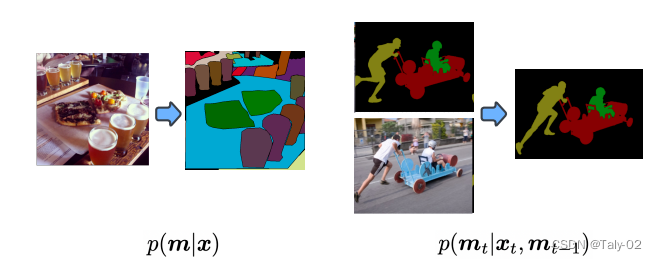
全景分割的生成式建模非常具有挑戰性,因為全景掩碼是離散的,或者說是有類別的,并且模型可能非常大。例如,要生成 512×1024 的全景掩碼,模型必須生成超過 1M 的離散標記(語義標簽和實例標簽)。這對于自回歸模型來說計算開銷是比較大的,因為 token 本質上是順序的,很難隨著輸入數據的規模變化而變化。擴散模型更擅長處理高維數據,但它們最常應用于連續域而不是離散域。通過用模擬位表示離散數據,本文作者表明可以直接在大型全景分割上完成diffusion的訓練,而不需要在latent space進行學習。這樣就使得模型 這對于自回歸模型來說是昂貴的,因為它們本質上是順序的,隨著數據輸入的大小縮放不佳。diffusion model很擅長處理高維數據,但它們最常應用于連續而非離散域。通過用模擬位表示離散數據,論文表明可以直接在大型全景掩模上訓練擴散模型,而無需學習中間潛在空間。接下來,我們來介紹本文提出的基于擴散的全景分割模型,描述其對圖像和視頻數據集的廣泛實驗。在這樣做的過程中,論文證明了所提出的方法在類似設置中與最先進的方法相比具有競爭力,證明了一種新的、通用的全景分割方法。
方法
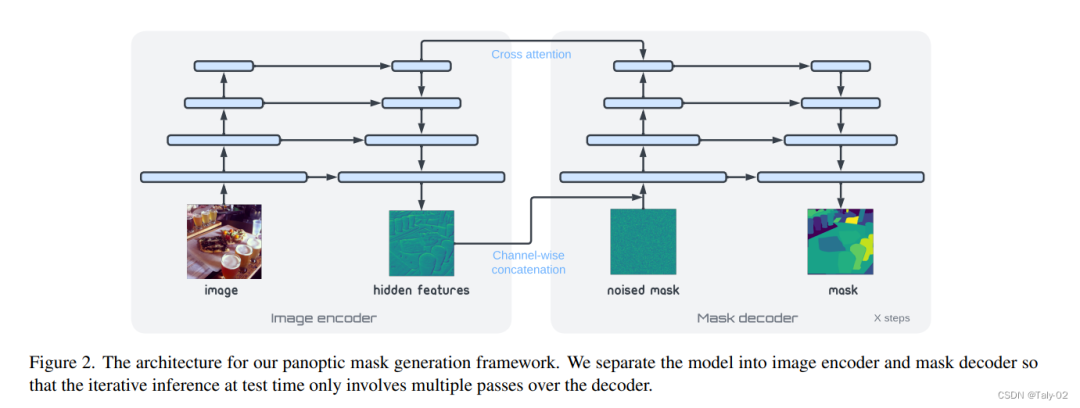
擴散模型采樣是迭代的,因此在推理過程中必須多次運行網絡的前向傳遞。因此,如上圖,論文的結構主要分為兩個部分:1)圖像編碼器;2)mask的解碼器。前者將原始像素數據映射到高級表示向量,然后掩模解碼器迭代地讀出全景掩模。
實驗
來看實驗結果:
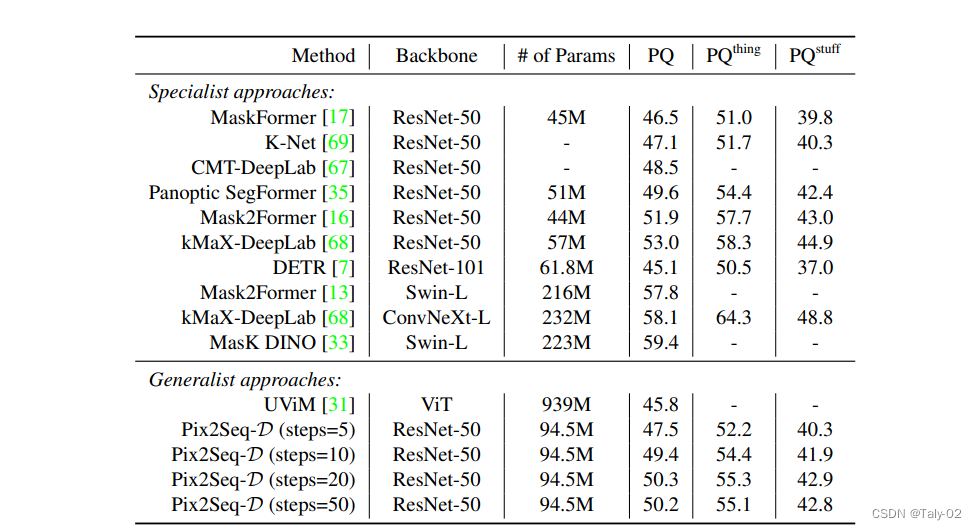
在 MS-COCO 數據集上,Pix2Seq-D 在基于 ResNet-50 的主干上的泛化質量(PQ)與最先進的方法相比有一定的競爭力。與最近的其他通用模型如 UViM 相比,本文的模型表現明顯更好,同時效率更高。
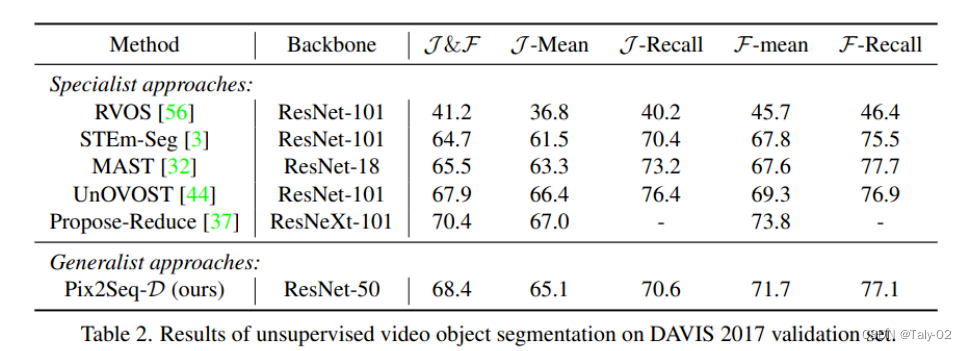
而在無監督數據集DAVIS上,也有更優的表現。
結論
本文基于離散全景蒙版的條件生成模型,提出了一種用于圖像和視頻全景分割的新型通用框架。通過利用強大的Bit Diffusion 模型,我們能夠對大量離散token建模,這對于現有的通用模型來說是困難的。
———————End———————
你可以添加微信:rtthread2020 為好友,注明:公司+姓名,拉進RT-Thread官方微信交流群!

愛我就給我點在看
點擊閱讀原文進入官網
-
RT-Thread
+關注
關注
31文章
1305瀏覽量
40302
原文標題:【AI簡報第20230210期】 ChatGPT爆火背后、為AIoT和邊緣側AI喂算力的RISC-V
文章出處:【微信號:RTThread,微信公眾號:RTThread物聯網操作系統】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
進迭時空 K1 系列 8 核 64 位 RISC - V AI CPU 芯片介紹
圣誕特輯 |開源芯片系列講座第25期:RISC-V架構在高性能領域的進展與挑戰

直播預約 |開源芯片系列講座第25期:RISC-V架構在高性能領域的進展與挑戰
RISC-V,即將進入應用的爆發期
預售啟動!昉·星光 2 AI套件正式發布,基于RISC-V構建AI算力

芯原聯合主辦RISC-V和生成式AI論壇
Banana Pi BPI-F3 進迭時空RISC-V架構下,AI融合算力及其軟件棧實踐
RISC-V最重要的方向是AI,但如何構建RISC-V+AI生態系統?
北京大學謝濤:基于RISC-V構建AI算力的優勢和兩種模式
RISC-V在中國的發展機遇有哪些場景?
科華數據攜手希姆計算,推動國產RISC-V開源AI算力快速發展

科華數據攜手希姆計算,推動國產RISC-V開源AI算力快速發展






 工商網監
工商網監
評論