") SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks 深層網(wǎng)絡(luò)連體視覺跟蹤的演變
SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks 深層網(wǎng)絡(luò)連體視覺跟蹤的演變
論文:https://arxiv.org/pdf/1812.11703.pdf
程序:https://github.com/PengBoXiangShang/SiamRPN_plus_plus_PyTorch
摘要
基于孿生網(wǎng)絡(luò)的跟蹤器將跟蹤表述為目標(biāo)模板和搜索區(qū)域之間的卷積特征互相關(guān)。然而孿生網(wǎng)絡(luò)的算法不能利用來自深層網(wǎng)絡(luò)(如 resnet-50或更深層)的特征,與先進(jìn)的算法相比仍然有差距。
在文章中我們證明了核心原因是孿生網(wǎng)絡(luò)缺乏嚴(yán)格的平移不變性。我們突破了這一限制,通過一個(gè)簡單而有效的空間感知采樣策略,成功地訓(xùn)練了一個(gè)具有顯著性能提升的基于ResNet網(wǎng)絡(luò)的孿生跟蹤器。此外,我們還提出了一種新的模型體系結(jié)構(gòu)來執(zhí)行分層和深度聚合,這不僅進(jìn)一步提高了計(jì)算的準(zhǔn)確性,而且還減小了模型的尺寸。我們?cè)谖鍌€(gè)大型跟蹤基準(zhǔn)上獲得了結(jié)果,包括OTB2015、VOT2018、UAV123、LASOT和TrackingNet。
該論文主要解決的問題是將深層基準(zhǔn)網(wǎng)絡(luò)ResNet、Inception等網(wǎng)絡(luò)應(yīng)用到基于孿生網(wǎng)絡(luò)的跟蹤網(wǎng)絡(luò)中。在SiameseFC算法之后,很多的基于孿生網(wǎng)絡(luò)的跟蹤算法都使用淺層的類AlexNet作為基準(zhǔn)特征提取器,直接使用預(yù)訓(xùn)練好的深層網(wǎng)絡(luò)反而會(huì)導(dǎo)致跟蹤算法精度的下降。
1.介紹
在平衡精度和速度方面,即使是性能好的孿生跟蹤器,如SiamRPN,在OTB2015等跟蹤基準(zhǔn)上仍與現(xiàn)有技術(shù)有顯著差距。所有這些跟蹤都在類似于AlexNet的架構(gòu)上構(gòu)建了自己的網(wǎng)絡(luò),并多次嘗試訓(xùn)練具有更復(fù)雜架構(gòu)(如ResNet)的孿生網(wǎng)絡(luò),但沒有性能提升。在這種觀察的啟發(fā)下,我們對(duì)現(xiàn)有的孿生追蹤器進(jìn)行了分析,發(fā)現(xiàn)其核心原因是絕對(duì)平移不變性(strict translation invariance)的破壞。由于目標(biāo)可能出現(xiàn)在搜索區(qū)域的任何位置,因此目標(biāo)模板的學(xué)習(xí)特征表示應(yīng)該保持空間不變性,并且我們進(jìn)一步從理論上發(fā)現(xiàn),在新的深層體系結(jié)構(gòu)中,只有AlexNet的zero-padding才能滿足這種空間不變性要求。
我們引入了一種采樣策略來打破孿生跟蹤器的空間不變性限制。我們成功地訓(xùn)練了一個(gè)基于SiamRPN的跟蹤器,使用ResNet作為主干網(wǎng)絡(luò)。利用ResNet結(jié)構(gòu),提出了一種基于層的互相關(guān)運(yùn)算特征聚合結(jié)構(gòu)(a layer-wise feature aggravation structure),該結(jié)構(gòu)有助于跟蹤器從多個(gè)層次的特征中預(yù)判出相似度圖。通過對(duì)孿生網(wǎng)絡(luò)結(jié)構(gòu)的交叉相關(guān)分析,發(fā)現(xiàn)其兩個(gè)網(wǎng)絡(luò)分支在參數(shù)個(gè)數(shù)上存在高度不平衡,因此我們進(jìn)一步提出了一種深度可分離的相關(guān)結(jié)構(gòu),它不僅大大減少了目標(biāo)模板分支中的參數(shù)個(gè)數(shù),而且使模型的訓(xùn)練過程更加穩(wěn)定。此外,還觀察到一個(gè)有趣的現(xiàn)象,即相同類別的對(duì)象在相同通道上具有較高的響應(yīng),而其余通道的響應(yīng)則被抑制。正交特性也可以提高跟蹤性能。
綜上所述,本文的主要貢獻(xiàn)如下:
1.我們對(duì)Siam進(jìn)行了深入的分析,并證明在使用深網(wǎng)絡(luò)時(shí),精度的降低是由于絕對(duì)平移不變性的破壞。
2.我們提出了一種采樣策略以打破空間不變性限制,成功訓(xùn)練了基于ResNet架構(gòu)的孿生跟蹤器。
3.提出了一種基于層次的互相關(guān)操作特征聚集結(jié)構(gòu),該結(jié)構(gòu)有助于跟蹤器根據(jù)多層次學(xué)習(xí)的特征預(yù)測(cè)相似度圖。
我們提出了一個(gè)深度可分離的相關(guān)結(jié)構(gòu)來增強(qiáng)互相關(guān),從而產(chǎn)生與不同語義相關(guān)的多重相似度圖。
在上述理論分析和技術(shù)貢獻(xiàn)的基礎(chǔ)上,我們開發(fā)了一種高效的視覺跟蹤模型,在跟蹤精度方面更為先進(jìn)。同時(shí)以35 fps的速度高效運(yùn)行。我們稱它為SiamRPN++,在五個(gè)大的跟蹤基準(zhǔn)上持續(xù)獲得跟蹤結(jié)果,包括OTB2015、VOT2018、UAV123、LASOT和TrackingNet。此外,我們還提出了一種使用MobileNet主干網(wǎng)的快速跟蹤器,該主干網(wǎng)在以70 fps的速度運(yùn)行時(shí)有良好的實(shí)時(shí)性能。
2.相關(guān)工作
RPN詳細(xì)介紹:https://mp.weixin.qq.com/s/VXgbJPVoZKjcaZjuNwgh-A
SiamFC詳細(xì)介紹:https://mp.weixin.qq.com/s/kS9osb2JBXbgb_WGU_3mcQ
SiamRPN詳細(xì)介紹:https://mp.weixin.qq.com/s/pmnip3LQtQIIm_9Po2SndA
3.深層孿生網(wǎng)絡(luò)跟蹤算法
如果使用更深層次的網(wǎng)絡(luò),基于孿生網(wǎng)絡(luò)的跟蹤算法的性能可以顯著提高。然而僅僅通過直接使用更深層的網(wǎng)絡(luò)(如ResNet)來訓(xùn)練孿生跟蹤器并不能獲得預(yù)期的性能改進(jìn)。我們發(fā)現(xiàn)其根本原因主要是由于孿生追蹤器的內(nèi)在限制。
3.1 孿生網(wǎng)絡(luò)跟蹤分析
基于孿生網(wǎng)絡(luò)的跟蹤算法將視覺跟蹤作為一個(gè)互相關(guān)問題,并從具有孿生網(wǎng)絡(luò)結(jié)構(gòu)的深層模型中學(xué)習(xí)跟蹤相似性圖,一個(gè)分支用于學(xué)習(xí)目標(biāo)的特征表示,另一個(gè)分支用于搜索區(qū)域。
目標(biāo)區(qū)域通常在序列的第一幀中給出,可以看作是一個(gè)模板z。目標(biāo)是在語義嵌入空間Φ(·)中從后續(xù)幀x中找到相似的區(qū)域(實(shí)例):
f(z,x)=\\phi(z)×\\phi(x)+b_i
其中b是偏移量。
這個(gè)簡單的匹配函數(shù)自然意味著孿生網(wǎng)絡(luò)跟蹤器有兩個(gè)內(nèi)在的限制。
1.孿生跟蹤器中使用的收縮部分和特征抽取器對(duì)絕對(duì)平移不變性有內(nèi)在的限制。
f(z,x[\\Delta\\tau_j])=f(z,x)[\\Delta\\tau_j]
確保了有效的訓(xùn)練和推理。
2.收縮部分對(duì)結(jié)構(gòu)對(duì)稱性有著內(nèi)在的限制,即:
f(z,x)=f(x,z)
適用于相似性學(xué)習(xí)。即如果將搜索區(qū)域圖像和模板區(qū)域圖像進(jìn)行互換,輸出的結(jié)果應(yīng)該保持不變。
通過詳細(xì)的分析,我們發(fā)現(xiàn)防止使用深網(wǎng)絡(luò)的孿生跟蹤器的核心原因與這兩個(gè)方面有關(guān)。具體來說,一個(gè)原因是深層網(wǎng)絡(luò)中的填充會(huì)破壞絕對(duì)平移不變性。另一個(gè)是RPN需要不對(duì)稱的特征來進(jìn)行分類和回歸。我們將引入空間感知抽樣策略來克服第一個(gè)問題,并在3.4中討論第二個(gè)問題。
絕對(duì)平移不變性只存在于no padding的網(wǎng)絡(luò)中,如修改后的AlexNet。以前基于孿生的網(wǎng)絡(luò)設(shè)計(jì)為淺層網(wǎng)絡(luò),可以滿足這一限制。然而,如果使用的網(wǎng)絡(luò)被新型網(wǎng)絡(luò)如ResNet或MobileNet所取代,padding將不可避免地使網(wǎng)絡(luò)更深入,從而破壞了絕對(duì)平移不變性限制。我們的假設(shè)是,違反這一限制將導(dǎo)致學(xué)習(xí)到空間偏移。例如SiamFC在訓(xùn)練方法時(shí)正樣本都在正中心,網(wǎng)絡(luò)逐漸會(huì)學(xué)習(xí)到樣本中正樣本分布的情況,圖像的中心會(huì)有更大的權(quán)重。
我們通過在帶有padding的網(wǎng)絡(luò)上進(jìn)行模擬實(shí)驗(yàn)來驗(yàn)證我們的假設(shè)。移位定義為數(shù)據(jù)擴(kuò)充中均勻分布產(chǎn)生的大平移范圍。我們的模擬實(shí)驗(yàn)如下。首先,在三個(gè)單獨(dú)的訓(xùn)練實(shí)驗(yàn)中,目標(biāo)被放置在具有不同shift range(0、16和32)的中心。Shift為正樣本距離中心點(diǎn)的距離。在收斂后,我們將測(cè)試數(shù)據(jù)集上生成的熱圖集合起來,然后將結(jié)果顯示在圖1中。
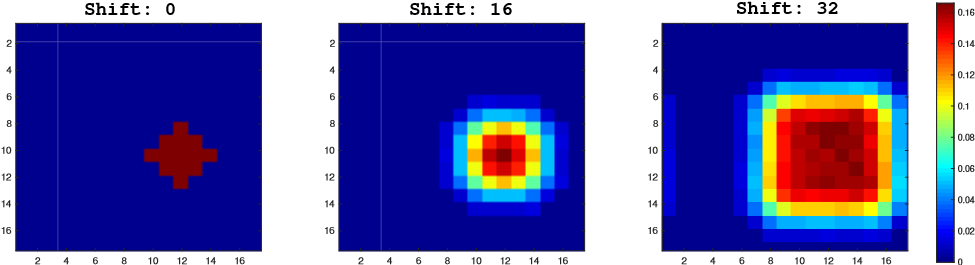
圖1. 當(dāng)使用不同的隨機(jī)翻譯時(shí),可視化正樣本的先驗(yàn)概率。在±32像素內(nèi)隨機(jī)平移后,分布變得更均勻。
在shift-0模擬中存在很強(qiáng)的中心偏移,只有中心位置具有較大的響應(yīng)值,邊界區(qū)域的概率降為零。另外兩個(gè)模擬表明,增加位移范圍(shift range)將逐漸增加圖中響應(yīng)的范圍。分析表明32-shift的總熱圖更接近于測(cè)試對(duì)象的位置分布。因此空間感知抽樣策略有效地緩解了填充網(wǎng)絡(luò)對(duì)嚴(yán)格平移不變性的破壞。
為了避免對(duì)物體產(chǎn)生中心偏差,我們采用空間感知采樣策略,在訓(xùn)練過程中,不再把正樣本塊放在圖像正中心,而是按照均勻分布的采樣方式讓目標(biāo)在中心點(diǎn)附近進(jìn)行偏移。用ResNet50主干訓(xùn)練SiamRPN。

圖2.隨機(jī)平移對(duì)VOT數(shù)據(jù)集的影響。
如圖2所示,在VOT2018上 0-shift的EAO只有0.14,適當(dāng)增加shift可以提高EAO(將算法的魯棒性和準(zhǔn)確性結(jié)合起來的一個(gè)綜合指標(biāo))。Shift=64時(shí)EAO最高。
3.2 基于ResNet的孿生網(wǎng)絡(luò)跟蹤算法
基于以上分析,我們消除了對(duì)中心位置的學(xué)習(xí)偏差,任何現(xiàn)成的網(wǎng)絡(luò)(如MobileNet,ResNet)都可以用于視覺跟蹤。此外,還可以自適應(yīng)地構(gòu)造網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu),揭示深度網(wǎng)絡(luò)的視覺跟蹤性能。
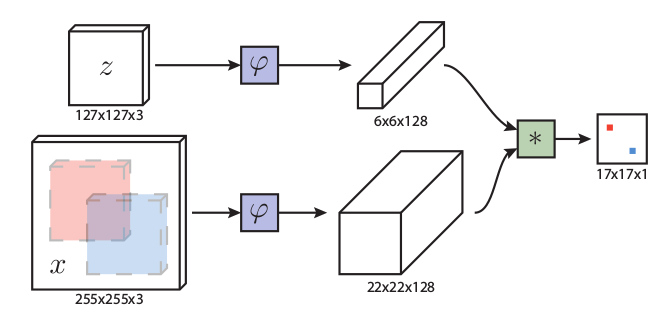
在本小節(jié)中,我們將討論如何將深度網(wǎng)絡(luò)傳輸?shù)轿覀兊母櫵惴ㄖ校瑢?shí)驗(yàn)主要集中在ResNet-50 。原來的ResNet有32 pix的大stride,不適合密集的孿生網(wǎng)絡(luò)預(yù)測(cè)。如圖3所示,我們通過修改conv4和conv5塊以獲得單位空間步幅,將后兩個(gè)塊的有效步幅從16像素和32像素減少到8像素,并通過擴(kuò)大卷積增加其感受野。在每個(gè)塊輸出端附加一個(gè)額外的1×1卷積層,將通道減少到256。

圖3.我們提出的框架的插圖。給定目標(biāo)模板和搜索區(qū)域,網(wǎng)絡(luò)通過融合多個(gè)SiamRPN塊的輸出來輸出密集預(yù)測(cè)。每個(gè)SiamRPN塊都顯示在右側(cè)。
由于所有層的填充都保持不變,模板特征的空間大小增加到15,這給相關(guān)模塊帶來了沉重的計(jì)算負(fù)擔(dān)。因此,我們裁剪中心的7×7區(qū)域作為模板特征,其中每個(gè)特征單元仍然可以捕獲整個(gè)目標(biāo)區(qū)域。
在SiamRPN的基礎(chǔ)上,我們將互相關(guān)層(cross correlation layers)和全卷積層組合成頭模塊(head module) 用于計(jì)算分類分?jǐn)?shù)(用S表示)和邊界框回歸器(用B表示)的頭模塊。SiameseRPN塊用P表示。此外可以微調(diào)ResNet將提高性能,通過將ResNet提取器的學(xué)習(xí)速率設(shè)置為比RPN小10倍可以更好的用于跟蹤任務(wù)。與傳統(tǒng)的孿生方法不同,深層網(wǎng)絡(luò)的參數(shù)以端到端的方式進(jìn)行聯(lián)合訓(xùn)練。這是第一個(gè)在深度孿生網(wǎng)絡(luò)(>20層)上實(shí)現(xiàn)端到端學(xué)習(xí)的視覺跟蹤算法。
3.3 分層聚合
利用像ResNet 50這樣的深層網(wǎng)絡(luò),可以聚合不同的深度層。直觀地說,視覺跟蹤需要豐富的表示,從低到高,從小到大,從細(xì)到粗的分辨率。即使在卷積網(wǎng)絡(luò)中有深度的特征,單獨(dú)的層是不夠的。復(fù)合和聚合這些特征可以提高識(shí)別和定位。
在以前的文獻(xiàn)中,僅使用像AlexNet這樣的淺層網(wǎng)絡(luò),多層特性不能提供多元的特征表示。然而,考慮到感受野的變化很大,ResNet中的不同層更有意義。淺層特征主要集中在顏色、形狀等低級(jí)信息上,對(duì)于定位是必不可少的,而缺乏語義信息;深層特征具有豐富的語義信息,在運(yùn)動(dòng)模糊、大變形等挑戰(zhàn)場景中有利于定位。我們假設(shè)使用這種豐富的層次信息對(duì)于跟蹤任務(wù)是有幫助的。
在我們的網(wǎng)絡(luò)中,多分支特征被提取出來共同推斷目標(biāo)定位。對(duì)于ResNet 50,我們探索從 后三個(gè)殘差模塊(residual blocks)中提取的多級(jí)特性,以進(jìn)行分層聚合。我們將這些輸出特征分別稱為F3(z)、F4(z) 和F5(z)。如圖3所示,conv3、 conv4、conv5的輸出分別輸入三個(gè)SiamRPN模塊。由于三個(gè)RPN模塊的輸出尺寸具有相同的空間分辨率,因此直接在RPN輸出上采用加權(quán)求和。加權(quán)融合層結(jié)合了所有的輸出。
S_{all}=\\sum^5_{l=3}\\alpha_i×S_l,B_{all}=\\sum^5_{l=3}\\beta×B_l
S——分類,B——回歸。

圖4 不同互相關(guān)層的圖示。(a)交叉相關(guān)(XCorr)層預(yù)測(cè)目標(biāo)模板和搜索區(qū)域之間的單通道相似度圖。(b)向上通道互相關(guān)(UP-XCorr)層通過在SiamRPN中將一個(gè)具有多個(gè)獨(dú)立XCorr層的重卷積層級(jí)聯(lián)而輸出多通道相關(guān)特征。(c)深度相關(guān)(DW-XCorr)層預(yù)測(cè)模板和搜索塊之間的多通道相關(guān)特征。
組合權(quán)重被分開用于分類和回歸,因?yàn)樗鼈兊挠蚴遣煌摹?quán)重與網(wǎng)絡(luò)一起進(jìn)行端到端優(yōu)化離線。與以前的論文相比,我們的方法沒有明確地結(jié)合卷積特征,而是分別學(xué)習(xí)分類器和回歸。請(qǐng)注意,隨著骨干網(wǎng)絡(luò)的深度顯著增加,我們可以從視覺語義層次結(jié)構(gòu)的充分多樣性中獲得實(shí)質(zhì)性效果。
3.4 深度交叉相關(guān)
互相關(guān)模塊是嵌入兩個(gè)分支信息的核心操作。SiamFC 利用交叉相關(guān)層獲得目標(biāo)定位的單通道響應(yīng)圖。在SiamRPN 中,通過添加巨大的卷積層來擴(kuò)展通道(UP-XCorr),交叉相關(guān)被擴(kuò)展為嵌入更高級(jí)別的信息,例如anchors。巨大的up-channel模塊嚴(yán)重影響參數(shù)分布的不平衡(即RPN模塊包含20M參數(shù),而特征提取器在SiamRPN中僅包含4M參數(shù)),這使得SiamRPN中的訓(xùn)練優(yōu)化變得困難。
在本小節(jié)中,我們提出了一個(gè)輕量級(jí)互相關(guān)層,名為Depth wise Cross Correlation(DW-XCorr),以實(shí)現(xiàn)有效的信息關(guān)聯(lián)。DW-XCorr層包含的參數(shù)比SiamRPN中使用的UP-XCorr少10 倍,而性能卻很高。

圖5. conv4中深度相關(guān)輸出的通道。conv4中共有256個(gè)通道,但是在跟蹤過程中只有少數(shù)通道具有高響應(yīng)。因此我們選擇第148,222,226通道作為演示,圖中為第2,第3,第4行。第一行包含來自O(shè)TB數(shù)據(jù)集的六個(gè)對(duì)應(yīng)搜索區(qū)域。不同的通道代表不同的語義,第148通道對(duì)汽車有很高的響應(yīng),而對(duì)人和人臉的反應(yīng)很低。第222和第226通道分別對(duì)人和面部有很高的反應(yīng)。
為實(shí)現(xiàn)此目的,采用conv-bn塊來調(diào)整每個(gè)殘差模塊(residual blocks)的特征以適應(yīng)跟蹤任務(wù)。至關(guān)重要的是,bb的預(yù)測(cè)和基于anchor的分類都是不對(duì)稱的,這與SiamFC不同(見第3.1節(jié))。為了對(duì)差異進(jìn)行編碼,模板分支和搜索分支傳遞兩個(gè)非共享卷積層。然后,具有相同數(shù)量的通道的兩個(gè)特征圖按通道進(jìn)行相關(guān)操作。附加另一個(gè)conv-bn-relu塊以融合不同的通道輸出。然后,附加用于分類或回歸輸出的最后一個(gè)卷積層。通過將互相關(guān)替換為深度相關(guān),我們可以大大降低計(jì)算成本和內(nèi)存使用。通過這種方式,模板和搜索分支上的參數(shù)數(shù)量得到平衡,從而使訓(xùn)練過程更加穩(wěn)定。
此外,有趣的現(xiàn)象如圖5所示。同一類別中的對(duì)象在相同的通道上具有高響應(yīng)(第148通道中的車,第222通道中的人,以及第226通道中的人),而其余通道的響應(yīng)被抑制。由于深度互相關(guān)產(chǎn)生的通道方式特征幾乎正交并且每個(gè)通道代表一些語義信息,因此可以理解該屬性。我們還使用上通道互相關(guān)分析熱圖,并且響應(yīng)圖的解釋性較差。
4.實(shí)驗(yàn)結(jié)果
4.1訓(xùn)練集及評(píng)估
訓(xùn)練
我們的架構(gòu)的骨干網(wǎng)絡(luò)在ImageNet 上進(jìn)行了預(yù)訓(xùn)練,用于圖像標(biāo)記,已經(jīng)證明這是對(duì)其他任務(wù)的非常好的初始化。我們?cè)贑OCO,ImageNet DET,ImageNet VID和YouTube-Bounding-Boxes數(shù)據(jù)集的訓(xùn)練集上訓(xùn)練網(wǎng)絡(luò),并學(xué)習(xí)如何測(cè)量視覺跟蹤的一般對(duì)象之間相似性的一般概念。在訓(xùn)練和測(cè)試中,我們使用單比例圖像,其中127個(gè)像素用于模板區(qū)域,255個(gè)像素用于搜索區(qū)域。
評(píng)估
我們專注于OTB2015 [46],VOT2018 [21]和UAV123 [31]上的短時(shí)單目標(biāo)跟蹤。我們使用VOT2018-LT [21]來評(píng)估長時(shí)跟蹤任務(wù)。在長時(shí)跟蹤中,物體可能長時(shí)間離開視野或完全遮擋,這比短期跟蹤更具挑戰(zhàn)性。我們還分析了我們的方法在LaSOT [10]和TrackingNet [30]上的實(shí)驗(yàn),這兩個(gè)是最近才出現(xiàn)的單一目標(biāo)跟蹤的benchmarks。
4.2 實(shí)施細(xì)節(jié)
網(wǎng)絡(luò)結(jié)構(gòu)
在實(shí)驗(yàn)中,我們按照DaSiamRPN進(jìn)行訓(xùn)練和設(shè)置。我們將兩個(gè)同級(jí)卷積層連接到減少步幅(stride-reduced)的ResNet-50(第3.2節(jié)),用5個(gè)anchors執(zhí)行分類和邊界框回歸。將三個(gè)隨機(jī)初始化的1×1卷積層連接到conv3,conv4,conv5,以將特征尺寸減小到256。
優(yōu)化
SiamRPN ++采用隨機(jī)梯度下降(SGD)進(jìn)行訓(xùn)練。我們使用8個(gè)GPU的同步SGD,每個(gè)小批量共128對(duì)(每個(gè)GPU 16對(duì)),需要12小時(shí)才能收斂。我們使用前5個(gè)時(shí)間段的0.001的預(yù)熱學(xué)習(xí)率來訓(xùn)練RPN分支。在過去的15個(gè)時(shí)間段中,整個(gè)網(wǎng)絡(luò)都是端到端的訓(xùn)練,學(xué)習(xí)率從0.005到0.0005呈指數(shù)衰減。使用0.0005的重量衰減和0.9的動(dòng)量。訓(xùn)練損失是分類損失和回歸的標(biāo)準(zhǔn)平滑L1損失的總和。
4.3 對(duì)比實(shí)驗(yàn)
主干架構(gòu)
特征提取器的選擇至關(guān)重要,因?yàn)閰?shù)的數(shù)量和層的類型直接影響跟蹤器的內(nèi)存消耗,速度和性能。我們比較了視覺跟蹤的不同網(wǎng)絡(luò)架構(gòu)。圖6顯示了使用AlexNet,ResNet-18,ResNet-34,ResNet-50和MobileNet-v2作為主干的性能。我們畫出了在OTB2015上成功曲線的曲線下面積(AUC)相對(duì)于ImageNet的top1精度的性能。我們觀察到我們的SiamRPN ++可以從更深入的ConvNet中受益。
逐層特征聚合
為了研究分層特征聚合的影響,首先我們?cè)赗esNet-50上訓(xùn)練三個(gè)具有單個(gè)RPN的變體。單獨(dú)使用conv4可以在EAO中獲得0.374的良好性能,而更深的層和更淺的層則會(huì)有4%的下降。通過組合兩個(gè)分支,conv4 和conv5獲得了改進(jìn),但是在其他兩個(gè)組合上沒有觀察到改善。盡管如此,魯棒性也增加了10%,這說明我們的追蹤器仍有改進(jìn)的余地。在匯總所有三個(gè)層之后,準(zhǔn)確性和穩(wěn)健性都穩(wěn)步提高,VOT和OTB的增益在3.1%和1.3%之間。總體而言,逐層特征聚合在VOT2018上產(chǎn)生0.414的 EAO分?jǐn)?shù),比單層基線高4.0%。
5.結(jié)論
在本文中,我們提出了一個(gè)統(tǒng)一的框架,稱為SiamRPN ++,用于端到端訓(xùn)練深度連體網(wǎng)絡(luò)進(jìn)行視覺跟蹤。我們展示了如何在孿生跟蹤器上訓(xùn)練深度網(wǎng)絡(luò)的理論和實(shí)證證據(jù)。我們的網(wǎng)絡(luò)由多層聚合模塊組成,該模塊組合連接層次以聚合不同級(jí)別的表示和深度相關(guān)層,這允許我們的網(wǎng)絡(luò)降低計(jì)算成本和冗余參數(shù),同時(shí)還導(dǎo)致更好的收斂。使用SiamRPN ++,我們實(shí)時(shí)獲得了VOT2018上先進(jìn)的結(jié)果,顯示了SiamRPN ++的有效性。SiamRPN ++還在La-SOT和TrackingNet等大型數(shù)據(jù)集上實(shí)現(xiàn)了先進(jìn)的結(jié)果,顯示了它的泛化性。
學(xué)習(xí)更多編程知識(shí),請(qǐng)關(guān)注我的公眾號(hào):

-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4779瀏覽量
101040 -
視覺跟蹤
+關(guān)注
關(guān)注
0文章
11瀏覽量
8831
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
雙目立體視覺原理大揭秘(二)
基于立體視覺的變形測(cè)量
雙目立體視覺的運(yùn)用
雙目立體視覺在嵌入式中有何應(yīng)用
基于預(yù)測(cè)的立體視覺_力反饋研究
自動(dòng)跟蹤對(duì)稱電源:Tracking Regulated Po
FM跟蹤發(fā)射器FM Tracking Transmitter
圖像處理基本算法-立體視覺
雙相機(jī)立體視覺和結(jié)構(gòu)光立體視覺原理及優(yōu)勢(shì)對(duì)比
基于信息熵的級(jí)聯(lián)Siamese網(wǎng)絡(luò)目標(biāo)跟蹤方法
SiamFC:用于目標(biāo)跟蹤的全卷積孿生網(wǎng)絡(luò) fully-convolutional siamese networks for object tracking
SiamRPN:High Performance Visual Tracking with Siamese Region Proposal Network 孿生網(wǎng)絡(luò)
SA-Siam:用于實(shí)時(shí)目標(biāo)跟蹤的孿生網(wǎng)絡(luò)A Twofold Siamese Network for Real-Time Object Tracking
DW-Siam:Deeper and Wider Siamese Networks for Real-Time Visual Tracking 更寬更深的孿生網(wǎng)絡(luò)
傳輸豐富的特征層次結(jié)構(gòu)以實(shí)現(xiàn)穩(wěn)健的視覺跟蹤Transferring Rich Feature Hierarchies for Robust Visual Tracking






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論