

論文地址:https://openaccess.thecvf.com/content_cvpr_2018/papers/He_A_Twofold_Siamese_CVPR_2018_paper.pdf
摘要
1.本文核心一:將圖像分類任務(wù)中的 語(yǔ)義特征 (Semantic features)與相似度匹配任務(wù)中的外觀特征(Appearance features)互補(bǔ)結(jié)合,非常適合與目標(biāo)跟蹤任務(wù),因此本文方法可以簡(jiǎn)單概括為:SA-Siam=語(yǔ)義分支+外觀分支;
2.Motivation:目標(biāo)跟蹤的特點(diǎn)是,我們想從眾多背景中區(qū)分出變化的目標(biāo)物體,其中難點(diǎn)為:背景和變化。本文的思想是用一個(gè)語(yǔ)義分支過(guò)濾掉背景,同時(shí)用一個(gè)外觀特征分支來(lái)泛化目標(biāo)的變化,如果一個(gè)物體被語(yǔ)義分支判定為不是背景,并且被外觀特征分支判斷為該物體由目標(biāo)物體變化而來(lái),那么我們認(rèn)為這個(gè)物體即需要被跟蹤的物體;
3.本文的目的是提升SiamFC在目標(biāo)跟蹤任務(wù)中的判別力。在深度CNN訓(xùn)練目標(biāo)分類的任務(wù)中,網(wǎng)絡(luò)中深層的特征具有強(qiáng)的語(yǔ)義信息并且對(duì)目標(biāo)的外觀變化擁有不變性。這些語(yǔ)義特征是可以用于互補(bǔ)SiamFC在目標(biāo)跟蹤任務(wù)中使用的外觀特征。基于此發(fā)現(xiàn),我們提出了SA-Siam,這是一個(gè)雙重孿生網(wǎng)絡(luò),由語(yǔ)義分支和外觀分支組成。每一個(gè)分支都使用孿生網(wǎng)絡(luò)結(jié)構(gòu)計(jì)算候選圖片和目標(biāo)圖片的相似度。為了保持兩個(gè)分支的獨(dú)立性,兩個(gè)孿生網(wǎng)絡(luò)在訓(xùn)練過(guò)程中沒(méi)有任何關(guān)系,僅僅在測(cè)試過(guò)程中才會(huì)結(jié)合。
4.本文核心二:對(duì)于新引入的語(yǔ)義分支,本文進(jìn)一步提出了通道注意力機(jī)制。在使用網(wǎng)絡(luò)提取目標(biāo)物體的特征時(shí),不同的目標(biāo)激活不同的特征通道,我們應(yīng)該對(duì)被激活的通道賦予高的權(quán)值,本文通過(guò)目標(biāo)物體在網(wǎng)絡(luò)特定層中的響應(yīng)計(jì)算這些不同層的權(quán)值。實(shí)驗(yàn)證實(shí),通過(guò)此方法,可以進(jìn)一步提升語(yǔ)義孿生網(wǎng)絡(luò)的判別力。
其仍然沿用SiamFC在跟蹤過(guò)程中所有幀都和第一幀對(duì)比,是該類方法的主要缺陷。
相關(guān)工作
RPN詳細(xì)介紹:https://mp.weixin.qq.com/s/VXgbJPVoZKjcaZjuNwgh-A
SiamFC詳細(xì)介紹:https://mp.weixin.qq.com/s/kS9osb2JBXbgb_WGU_3mcQ
SiamRPN詳細(xì)介紹:https://mp.weixin.qq.com/s/pmnip3LQtQIIm_9Po2SndA
1.SiamFC:對(duì)于A,B,C三個(gè)圖片,假設(shè)C圖片和A圖片是一個(gè)物體,但是外觀發(fā)生了一些變化,B和A沒(méi)有任何關(guān)系。SiamFC網(wǎng)絡(luò)輸入兩張圖片,那么經(jīng)過(guò)SiamFC后會(huì)得到A和C相似度高,A和B相似度低。通過(guò)上述SiamFC的功能,自然地其可以用于目標(biāo)跟蹤算法中。SiamFC網(wǎng)絡(luò)突出優(yōu)點(diǎn):無(wú)需在線fine-tune和end-to-end跟蹤模式,使得其可以做到保證跟蹤效果的前提下進(jìn)行實(shí)時(shí)跟蹤。
2.集成跟蹤器:大多數(shù)跟蹤是一個(gè)模型A,利用模型A對(duì)當(dāng)前數(shù)據(jù)進(jìn)行計(jì)算得到跟蹤結(jié)果,集成跟蹤器就是它有多個(gè)模型A,B,C,分別對(duì)當(dāng)前數(shù)據(jù)進(jìn)行分析,然后對(duì)結(jié)果融合得到最終的跟蹤結(jié)果。本文的語(yǔ)義特征+外觀特征正是借鑒了集成跟蹤器的思路。在集成跟蹤器,模型A,B,C相關(guān)度越低,跟蹤效果越好,這個(gè)很好理解,如果他們?nèi)浅O嚓P(guān),那么用三個(gè)和用一個(gè)沒(méi)啥區(qū)別,因?yàn)檫@個(gè)原因,本文的語(yǔ)義特征和外觀特征網(wǎng)絡(luò)在訓(xùn)練過(guò)程中是完全不相關(guān)的。
框架
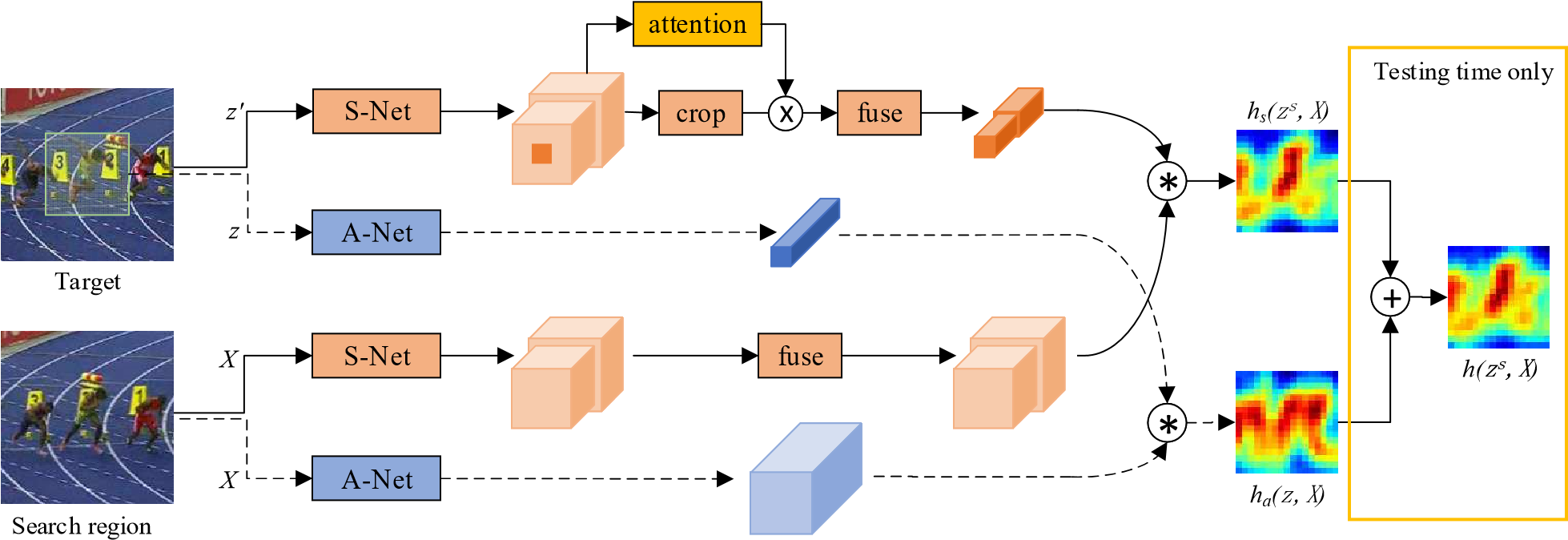
提議的雙重SA-Siam網(wǎng)絡(luò)的體系結(jié)構(gòu)。A-Net表示外觀網(wǎng)絡(luò)。用虛線連接的網(wǎng)絡(luò)和數(shù)據(jù)結(jié)構(gòu)與SiamFC完全相同。S-Net表示語(yǔ)義網(wǎng)絡(luò)。提取最后兩個(gè)卷積層的特征。信道關(guān)注模塊基于目標(biāo)和上下文信息確定每個(gè)特征信道的權(quán)重。外觀分支和語(yǔ)義分支是單獨(dú)訓(xùn)練的,直到測(cè)試時(shí)間才結(jié)合。
1.外觀分支(藍(lán)色部分)
一個(gè)目標(biāo)A送到網(wǎng)絡(luò)P里,一個(gè)比目標(biāo)大的搜索域S送到網(wǎng)絡(luò)P里,A出來(lái)的特征圖與S出來(lái)的特征圖進(jìn)行卷積操作得到相關(guān)系數(shù)圖,相關(guān)系數(shù)越大,越可能是同一個(gè)目標(biāo),網(wǎng)絡(luò)則采用和SiamFC中一樣的網(wǎng)絡(luò)。
外觀分支以(z,X)為輸入。它克隆了SiamFC網(wǎng)絡(luò)。用于提取外觀特征的卷積網(wǎng)絡(luò)稱為A-Net。來(lái)自外觀分支的響應(yīng)映射可以寫(xiě)為:
L(y,v)=\\frac{1}{D}\\sum_{u\\in D}l(y[u],v[u])
在相似性學(xué)習(xí)問(wèn)題中,A-Net中的所有參數(shù)都是從頭開(kāi)始訓(xùn)練的。
通過(guò)最小化邏輯損失函數(shù)L(·)來(lái)優(yōu)化A-Net,如下:
arg \\min_{\\theta_a}\\frac{1}{N} \\sum^N_{i=1}{(L(h_a(z_i,X_i,\\theta_a),Y_i))}
其中θa表示A-Net中的參數(shù),N是訓(xùn)練樣本的數(shù)量,Yi是ground truth的響應(yīng)。
2.語(yǔ)義分支(橙色部分)
這篇文章的重點(diǎn)便是此。橙色的表示語(yǔ)義網(wǎng)絡(luò),用的是預(yù)訓(xùn)練好的AlexNet,在訓(xùn)練和測(cè)試時(shí)固定所有參數(shù),只提取最后conv4和conv5的特征,目標(biāo)模板變?yōu)閦s,zs和X一樣大,和z有一樣的中心,但包含了上下文信息,因?yàn)橹飞霞恿送ǖ雷⒁饬δP停ㄟ^(guò)目標(biāo)和周?chē)男畔?lái)決定權(quán)重,選擇對(duì)特定跟蹤目標(biāo)影響更大的通道。另外,為了更好的進(jìn)行后續(xù)的相關(guān)操作,作者將上下兩支路加入融合模型,加入了1×1的卷積層,對(duì)提取的兩層每層進(jìn)行卷積操作,使目標(biāo)模板支路和檢測(cè)支路的特征通道相同,而且通道總數(shù)和外觀網(wǎng)絡(luò)的通道一樣。
語(yǔ)義分支網(wǎng)絡(luò)訓(xùn)練時(shí)只訓(xùn)練通道注意力模塊和融合模塊。
來(lái)自語(yǔ)義分支的響應(yīng)映射可以寫(xiě)為:
h_s(z^s,X)=corr(g(\\xi ·f_s(z)),g(f_s(X)))
ξ是通道權(quán)重,g()是對(duì)特征進(jìn)行融合,便于相關(guān)操作。
損失函數(shù)L(·)如下:
arg \\min_{\\theta_a}\\frac{1}{N} \\sum^N_{i=1}{(L(h_s(z_i^s,X_s,\\theta_a),Y_i))}
其中θs表示可訓(xùn)練參數(shù),N是訓(xùn)練樣本的數(shù)量。
3.結(jié)合
外觀網(wǎng)絡(luò)和語(yǔ)義網(wǎng)絡(luò)分開(kāi)訓(xùn)練,語(yǔ)義網(wǎng)絡(luò)只訓(xùn)練通道注意力模塊和融合模塊。在測(cè)試時(shí)間內(nèi),最終的響應(yīng)圖計(jì)算為來(lái)自兩個(gè)分支的圖的加權(quán)平均值:
h(z^s,X)=\\lambda h_a(z,X)+(1-\\lambda)h_s(z^s,X)
其中 λ 是加權(quán)參數(shù),以平衡兩個(gè)分支的重要性。在實(shí)踐中,λ可以從驗(yàn)證集估計(jì)。作者通過(guò)實(shí)驗(yàn)得出 λ=0.3 最好。
4.語(yǔ)義分支中的Channel Attention機(jī)制
為什么要這么做:高維語(yǔ)義特征對(duì)目標(biāo)的外觀(圖片的形變、旋轉(zhuǎn)等)變化是魯棒的,導(dǎo)致判別力低。為了提升語(yǔ)義分支的判別力,我們?cè)O(shè)計(jì)了一個(gè)Channel Attention模塊。直覺(jué)上,在跟蹤不同的物體時(shí),不同的通道扮演著不同的角色,某些通道對(duì)于一些物體來(lái)說(shuō)是極其重要的,但是對(duì)于其他物體而言則可以被忽略,甚至可能引入噪聲。如果我們能自適應(yīng)的調(diào)整通道的重要性,那么我們將獲得目標(biāo)跟可靠地特征表達(dá)。為了達(dá)到這個(gè)目的,不僅目標(biāo)對(duì)于我們來(lái)說(shuō)是重要的,其周?chē)欢ǚ秶鷥?nèi)的背景對(duì)于我們來(lái)說(shuō)同樣重要,因此這里輸入網(wǎng)絡(luò)的模板要比外觀分支大一圈。
下面講具體怎么實(shí)現(xiàn)這個(gè)功能的。

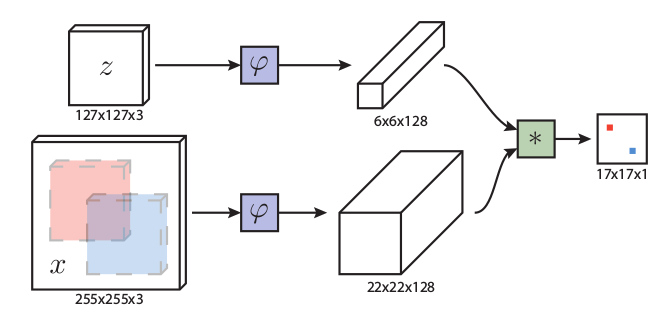
通道注意力通過(guò)最大池化層和多層感知器(MLP)生成通道i的加權(quán)系數(shù)ξi。
上述圖中,假設(shè)是conv5層的第i個(gè)通道特征圖,維度為22×22,將該圖分割成3×3份(其中中間的那份為6×6,是準(zhǔn)確的目標(biāo)),經(jīng)過(guò)max-pooling操作后變成3×3的圖,經(jīng)過(guò)一個(gè)兩層的MLP網(wǎng)絡(luò)(Multi-Layer Perceptron多層感知機(jī),含有9個(gè)神經(jīng)元和一個(gè)隱層,隱層采用ReLU函數(shù))后得到分?jǐn)?shù),在sigmoid一下(為了讓得分系數(shù)在0~1之間)得到最終的得分系數(shù)。值得注意的是:這里的得分系數(shù)計(jì)算操作僅僅在第一幀進(jìn)行計(jì)算,后續(xù)幀沿用第一幀的結(jié)果,所以其計(jì)算時(shí)間是可以忽略不計(jì)的。
實(shí)驗(yàn)
數(shù)據(jù)維度:在我們的實(shí)現(xiàn)中,目標(biāo)圖像塊z的尺寸為127×127×3,并且zs和X都具有255×255×3的尺寸。對(duì)于z和X,A-Net的輸出特征具有尺寸分別為6×6×256和22×22×256。來(lái)自S-Net的conv4和conv5功能具有尺寸為24×24×384和22×22×256通道的zs和X。這兩組功能的1×1 ConvNet每個(gè)輸出128個(gè)通道(最多可達(dá)256個(gè)通道) ),空間分辨率不變。響應(yīng)圖具有相同的17×17維度。

學(xué)習(xí)更多編程知識(shí),請(qǐng)關(guān)注我的公眾號(hào):

-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4797瀏覽量
102222 -
圖像處理
+關(guān)注
關(guān)注
27文章
1320瀏覽量
57490
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
LabVIEW 不適用于實(shí)時(shí)處理( Real-Time )的應(yīng)用?
如何獲得NI Linux Real-Time系統(tǒng)?
如何獲得NI Linux Real-Time系統(tǒng)?
FPGA and Real-time技術(shù)
Real-Time DSP Implementation f
Improved Real-Time Quantitativ
BQ32002,pdf(Real-Time Clock (R
DS1346,DS1347(compatible real-time clocks RTCs)
MathWorks推出Simulink Real-Time,提供完整、集成的實(shí)時(shí)仿真和測(cè)試
基于信息熵的級(jí)聯(lián)Siamese網(wǎng)絡(luò)目標(biāo)跟蹤方法
SiamFC:用于目標(biāo)跟蹤的全卷積孿生網(wǎng)絡(luò) fully-convolutional siamese networks for object tracking
SiamRPN:High Performance Visual Tracking with Siamese Region Proposal Network 孿生網(wǎng)絡(luò)
DW-Siam:Deeper and Wider Siamese Networks for Real-Time Visual Tracking 更寬更深的孿生網(wǎng)絡(luò)
新版本Real-time Edge正式發(fā)布啦!高效的工業(yè)邊緣實(shí)時(shí)應(yīng)用開(kāi)發(fā),就用它!
恩智浦Real-time Edge v2.7正式發(fā)布!





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論