 offset新探索:雙管齊下,加速大數據量查詢
offset新探索:雙管齊下,加速大數據量查詢
offset新探索:雙管齊下,加速大數據量查詢
眾所周知,在各類業務中時常會用到LIMIT y offset x來做跳過x條數據讀取Y條數據的操作。例如:SELECT * FROM ... LIMIT 1000 OFFSET 1000000;表示從第1000001條數據開始查,讀取1000條數據。隨著offset的增加,查詢的時長也會越來越長。當offset達到百萬級別的時候查詢時長有可能秒級,這是業務所不能容忍的。
那么如何來提升offset在大數據量查詢時的性能、縮短執行時間呢?我們的答案是:
offset Pushdown( offset下推,下文簡稱OP)
Redundant Condition Removal (冗余條件刪除,下文簡稱 RCR)
這是華為云GaussDB for MySQL推出的兩個新特性,通過OP和RCR的結合,將大數據量查詢的性能提升一到兩個數量級。下面我們分別介紹這兩個特性的基本原理、如何啟用、執行驗證、以及通過嚴密測試來驗證其帶來的性能提升。
Offset Pushdown -- OP
OP賦予MySQL存儲引擎InnoDB處理offset的能力。當OP啟用時,在SQL層評估offset是否可以下推并將下推信息傳遞給存儲引擎。SQL層不再對存儲引擎返回的行進行offset處理,取而代之的是存儲引擎層直接跳過offset范圍內的行,僅返回后續行,即查詢所需要的行。
通過啟用OP,offset范圍內的行不會再傳輸到SQL層,從而節省了存儲引擎和SQL層之間多次來回交互時間;其次,對非覆蓋索引掃描(non-covering index,即查詢訪問二級索引之后,還必須訪問基表),直接跳過offset范圍內的行可以節省對這些行回表訪問的開銷。這種對offset的提前處理可以節省數據處理時間,特別是當offset非常大時。OP的適用性取決于WHERE子句是否可以由存儲引擎整體處理。
下方圖1和2分別說明了在沒有OP和啟用OP時LIMIT offset的處理邏輯。
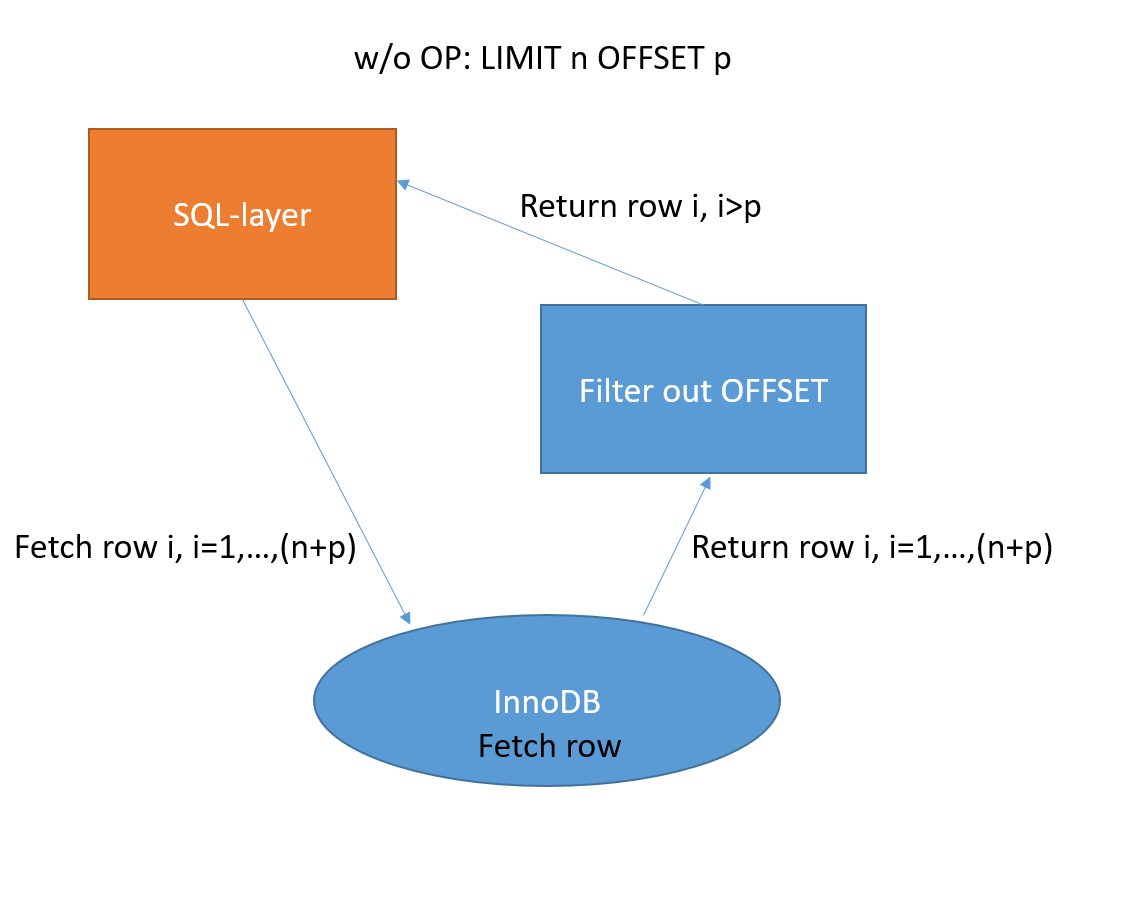
圖1無OP的極限偏移邏輯
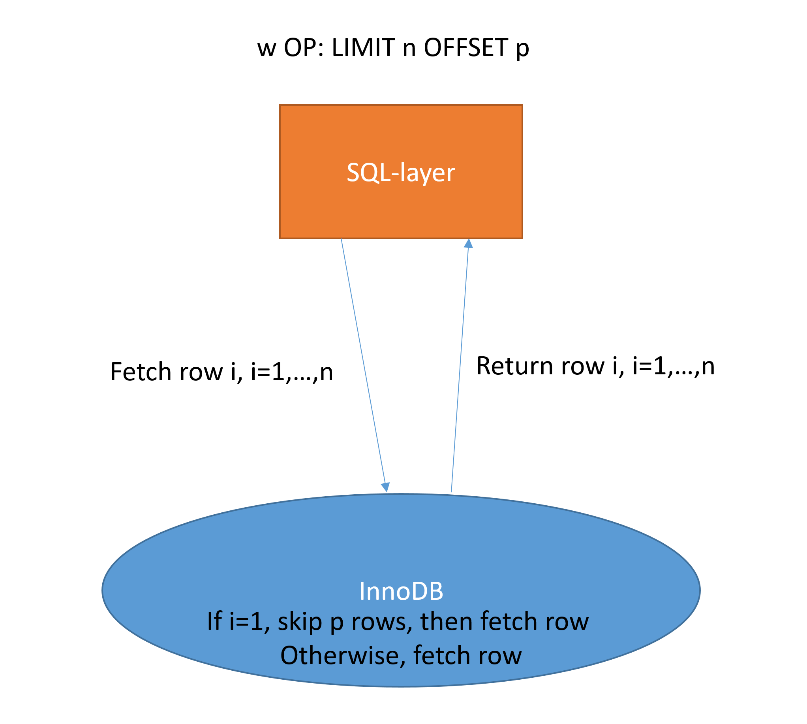
圖2啟用OP的LIMIT offset邏輯
Redundant Condition Removal – RCR
RCR的思路也比較簡單:當進行索引范圍掃描時,SQL層對存儲引擎返回的行執行冗余檢查,因為它不知道存儲引擎已經執行了這些檢查,而RCR就是讓 SQL層了解這點。為了使 OP成為可能,除了要求WHERE條件能夠被存儲引擎獨立且完整的評估,SQL層還必須了解這點從而避免冗余檢查。
OP功能的實現方式與索引條件下推 (Index Condition Pushdown,ICP) 類似。對于某些查詢,ICP通過將整個 WHERE子句下推到存儲引擎來啟用 OP。而RCR在 ICP執行之前會評估條件是否冗余,并且移除冗余條件,確保了ICP不會處理冗余的條件檢查。RCR很好地補充了OP特性的適用范圍,允許更多查詢使用 OP。
請注意:OP的啟用需要滿足三個主要條件:
SQL語句包含offset
WHERE子句完全由InnoDB處理
SQL語句只涉及一張表
另外,
查詢中使用的表必須是InnoDB表
不使用HAVING, aggregations, GROUP BY, SELECT DISTINCT, ROLLUP,Window functions以及文件排序
不支持涉及多個分區的分區表查詢,只涉及單個分區的可以
RCR適用于索引范圍掃描,如果WHERE子句中出現了一個或者多個條件,而這些條件涉及到的字段在對應使用的索引上是被連續定義的,這些條件的冗余檢查就都會被移除。
如何啟用OP?
方法一:使用特定的optimizer switch:offset _PUSHDOWN
set optimizer_switch='OFFSET_PUSHDOWN=[on]/[off]';
默認為打開。
方法二:使用特定的優化器hint:[NO]_OFFSET_PUSHDOWN()
SELECT /*+ [NO]_OFFSET_PUSHDOWN() */ FROM TABLE LIMIT n OFFSET p;
請注意,hint優先級高于optimizer switch的設置。
我們基于下方創建的t1表,來舉例說明如何使用OP:
CREATE TABLE t1 (a int, b int, INDEX (b));
示例一:表掃描
explain format=tree select * from t1 limit 100 offset 1;
+----------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+----------------------------------------------------------------------------------------------------------------------+
| -> Limit/Offset: 100/1 row(s), with offset pushdown (cost=0.65 rows=4)
-> Table scan on t1 (cost=0.65 rows=4)
|
+----------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
示例二:二級索引上的索引范圍掃描
explain format=tree select a,b from t1 where b>2 limit 100 offset 1;
+------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+------------------------------------------------------------------------------------------------------------------------------------+
| -> Limit/Offset: 100/1 row(s), with offset pushdown (cost=1.61 rows=3)
-> Index range scan on t1 using b (cost=1.61 rows=3)
|
+------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
如何啟用RCR?
通過系統變量rds_empty_redundant_check_in_range_scan設置,如下:
set rds_empty_redundant_check_in_range_scan=[true]/[false];
默認為true。
我們通過一個示例來說明:
創建t0表:
CREATE TABLE t0 (a int, b int, INDEX (a,b));
不啟用RCR:
explain format=tree select * from t0 where a<100 and a>20 LIMIT 1 OFFSET 100;
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Limit/Offset: 1/100 row(s) (cost=0.46 rows=1)
-> Filter: ((t0.a < 100) and (t0.a > 20)) (cost=0.46 rows=1)
-> Index range scan on t0 using a (cost=0.46 rows=1)
|
+---------------------------
可以看出:列a上的范圍條件會被InnoDB默認檢查,但SQL層將再次檢查InnoDB返回的行是否匹配列a的范圍條件。在這種情況下,無法使用OP,因為SQL層不知道存儲引擎實際上處理了整個WHERE子句。
啟用RCR:設定rds_empty_redundant_check_in_range_scan = true;
explain format=tree select * from t0 where a<100 and a>20 LIMIT 1 OFFSET 100;
+------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+------------------------------------------------------------------------------------------------------------------------------------+
| -> Limit/Offset: 1/100 row(s), with offset pushdown (cost=0.46 rows=1)
-> Index range scan on t0 using a (cost=0.46 rows=1)
|
+------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
可以看出:啟用RCR,刪除SQL層對列A的范圍條件的冗余檢查后,啟用OP。
簡化ICP:
創建表t1:
create table t1(a int, b int, INDEX(b));
不啟用RCR:
explain format=tree select a,b from t1 where b>2 limit 100 offset 1;
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Limit/Offset: 100/1 row(s), with offset pushdown (cost=1.61 rows=3)
-> Index range scan on t1 using b, with index condition: (t1.b > 2) (cost=1.61 rows=3)
|
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
可以看出:使用了ICP后,OP也被啟用了
啟用RCR:
explain format=tree select a,b from t1 where b>2 limit 100 offset 1;
+------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+------------------------------------------------------------------------------------------------------------------------------------+
| -> Limit/Offset: 100/1 row(s), with offset pushdown (cost=1.61 rows=3)
-> Index range scan on t1 using b (cost=1.61 rows=3)
|
+------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
以上示例說明:ICP不是必要的。通過評估是否應使用ICP之前移除冗余條件,就可以避免使用ICP。
性能驗證:
下面我們通過實際測試來驗證OP所帶來的性能提升。在測試中,我們重點關注:
覆蓋/非覆蓋索引
考慮一個非覆蓋索引,不使用OP,InnoDB必須從基表讀取行,然后才能將它們返回到SQL層。使用OP后,就可以跳過行,而不必從基表讀取。因此,OP在非覆蓋索引上可以提供更好的性能。
熱/冷緩沖池
我們希望通過熱緩沖池全面提高性能,但我們也希望OP在熱緩沖池上相對更高效,原因如下:
基于一個冷緩沖池并且查詢使用覆蓋索引掃描的場景,設定
)和使用OP的計算時間(
)的比值:
比值
預計將大于1,因為使用OP將獲得性能提升。基于一個熱緩沖池并且查詢使用覆蓋索引掃描的場景,設定
是不使用OP的計算時間(
和使用OP的計算時間(
的比值:
其中
表示從磁盤讀取索引所需的時間,可以合理地假設,在使用OP和不使用OP的情況下,
都是相同的。因為不論是否使用OP,都必須從左到右遍歷索引,無法在使用OP的情況下,利用B-tree結構索引的優勢直接跳轉到offset范圍的結束點。
那么,這兩個比值的差值可以表述為:
因此,我們預計OP在熱緩沖池將更有效。
緩沖池大小
對于覆蓋索引查詢,可以假定索引數據都在緩沖池中,因此,緩沖池的大小對性能不會產生太大影響。然而,對于非覆蓋索引的查詢,情況會大不相同。在不使用OP時,緩沖池能緩存表數據的比例確實會對查詢的性能產生有利的影響。
基于以上三個關注點以及預判,我們在一個包含200萬行數據的測試表中,分別測試覆蓋/非覆蓋索引、冷/熱緩沖池、不同緩沖池大小下條件下,通過OP帶來的性能表現。
測試語句:
覆蓋索引查詢:
CREATE TABLE data (id int, value int, INDEX (id,value));
SELECT * FROM data LIMIT 1 OFFSET p;
非覆蓋索引查詢:
CREATE TABLE data_non_covering(id INT, value INT, INDEX (value));
INSERT INTO data_non_covering SELECT * FROM data;
SELECT * FROM data_non_covering WHERE value>2 LIMIT 1 OFFSET p;
為了過濾干擾,計算時間是取9次運行結果的中位數。
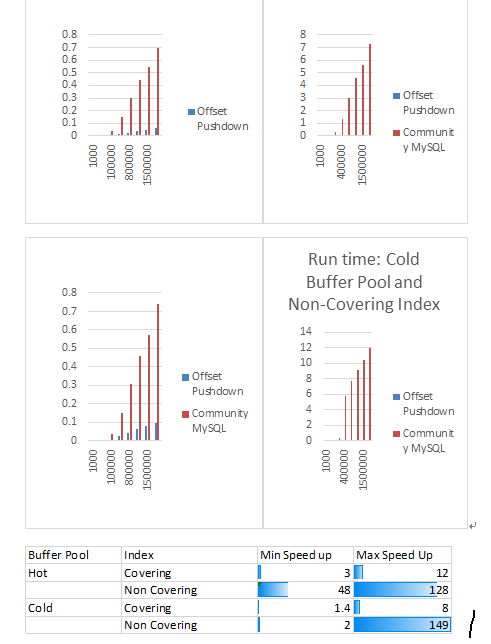
通過以上測試結果可以看出:
熱緩沖池,并將其大小設為128MB
使用覆蓋索引,OP可以將查詢性能提升3 – 12倍;
使用非覆蓋索引,OP可以將查詢性能提升 48 – 128倍
冷緩沖池,并將其大小設定為128MB:
使用覆蓋索引,OP可以將性能提升 40% - 8倍;
使用非覆蓋索引,OP可以將性能提升2 - 148倍
綜上,在所有測試中,使用OP能提升查詢性能。不論是冷緩沖池還是熱緩沖池,啟用OP后,非覆蓋索引掃描可以比覆蓋索引掃描獲得10倍以上的性能提升。此外,正如我們所預計,在熱緩沖池上啟用OP獲得了更大的性能提升。
對于大的OFFSET,使用OP可將性能提高一兩個數量級,而RCR可擴大了OP的適用范圍。正如上述測試所證明,使用OP所帶來的性能提升主要受下面兩個因素的影響:
OP可以在存儲引擎層跳過offset行,而不必將它們返回到SQL層,這將導致計算時間的顯著降低。
OP可以跳過offset行,而不必從基表讀取它們,從而獲得性能提升。
而OP和RCR的聯合使用,進一步擴大了OP的使用范圍,可以為更多的Limit/offset查詢帶來性能提升,尤其是對大的offset操作。
在后續的研究中,我們將會評估OP與NDP(Near Data Processing, 近數據處理)的兼容性以及潛在的性能改進。
本文作者
呂漫漪
現任華為瑞典研究所數據庫Lab首席科學家,云數據庫歐洲研發團隊的負責人。在數據庫領域有20多年經驗,曾經參與開發電信行業分布式高可用數據庫,在國際知名軟件公司深耕了十年MySQL技術。2020年加入華為,立志于打造世界頂端的企業級云數據庫。
Maxime Conjard
華為云數據庫工程師,就職于華為云數據庫歐洲研發團隊。Max畢業于挪威科技大學(NTNU),獲得統計學碩士和博士學位;在此之前,他在法國馬賽中央學院獲得工程碩士學位。
審核編輯:湯梓紅
-
數據庫
+關注
關注
7文章
3842瀏覽量
64579 -
大數據
+關注
關注
64文章
8904瀏覽量
137631 -
華為云
+關注
關注
3文章
2677瀏覽量
17538
發布評論請先 登錄
相關推薦
緩存對大數據處理的影響分析
合作共贏 埃克森美孚開啟液冷技術新探索
圖為大模型一體機新探索,賦能智能家居行業
雙管燈的線路怎么接線
大數據從業者必知必會的Hive SQL調優技巧
ESP8266_RTOS3.0串口0傳輸大量數據丟包的原因?
CC2640R2F BLE如何實現一次連接事件傳輸的數據量為500字節,或者更大?
藍牙Mesh模塊多跳大數據量高帶寬傳輸數據方法
STM32F302使用ADC+DMA的方案,采集大數據出錯怎么解決?
天齊鋰業一季度最高預虧43億 天齊鋰業股價跌停

分布式存儲與計算:大數據時代的解決方案
MySQL單表數據量限制:為何2000萬行成為瓶頸?

淺析大數據時代下的數據中心運維管理






 工商網監
工商網監
評論