") 一次對API響應(yīng)時間的優(yōu)化探索
一次對API響應(yīng)時間的優(yōu)化探索
一次對 API 響應(yīng)時間的優(yōu)化探索。
在這普通的一天,我們用著普通的 API,突然發(fā)現(xiàn)響應(yīng)速度過慢的警報意外亮起。
結(jié)果顯示,我們的 API 需要約 70 秒的時間才能對常規(guī)流量下的客戶端做出響應(yīng)。開什么玩笑……
從問題入手先向大家匯報一下我們的這個慢速 API 是做什么,又是怎么做的。
在這款應(yīng)用程序中,我們把書籍及其作者的目錄存儲在 MySQL 數(shù)據(jù)庫中。其中共包含約 6800 萬本書,每本書對應(yīng)一家出版社。
下面來看書籍和作者的表結(jié)構(gòu)。
CREATE TABLE `book` (
`id` int NOT NULL AUTO_INCREMENT,
`book_uuid_bin` binary(16) NOT NULL,
`publishing_house_uuid_bin` binary(16) NOT NULL,
`display_name` varchar(750) NOT NULL,
`normalized_name` varchar(750) NOT NULL,
`description` varchar(1000) DEFAULT NULL,
`level` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `unique_book_uuid_bin` (`book_uuid_bin`),
KEY `book_description_idx` (`description`(768)),
KEY `book_display_name_idx` (`display_name`),
KEY `book_normalized_name_idx` (`normalized_name`),
KEY `publishing_house_uuid_bin_idx` (`publishing_house_uuid_bin`),
KEY `book_uuid_bin_idx` (`book_uuid_bin`)
)
CREATE TABLE `publishing_house` (
`id` int NOT NULL AUTO_INCREMENT,
`publishing_house_uuid_bin` binary(16) DEFAULT NULL,
`display_name` varchar(750) NOT NULL,
`normalized_name` varchar(750) NOT NULL,
`alias_uuid_bin` binary(16) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `unique_publishing_house_uuid_bin` (`author_uuid_bin`),
KEY `publishing_house_normalized_name_idx` (`normalized_name`),
KEY `publishing_house_display_name_idx` (`display_name`)
)
再說回 API,其用例是在 UI 上提供自動補全功能,方便用戶更好地查找特定出版社出版的書籍,同時保證用戶的查詢字符串同書籍名稱或描述的前綴相匹配。
API 中使用的 MySQL 查詢?nèi)缦滤荆?/p>
select book_uuid_bin,
display_name,
normalized_name,
description,
author_uuid_bin
from book
where
((lower(display_name) like lower("%Software E%") or lower(description) like lower("%Software E%")) and publishing_house_uuid_bin = UUID_TO_BIN("d2230981-e570-5ba4-9a3a-16028c51d54f"))order by display_name asc limit 100;
即使查詢在單表上就能完成,不需要連接作者表,這條 SQL 查詢也需要 7 秒左右才能執(zhí)行完成。
我們在 where 子句所使用的列上建立了索引。但這一實現(xiàn)還是存在問題,包括:
1、display_name 和 description 等列屬于 VARCHAR 類型。
2、會在 VARCHAR 類型列上使用帶有 OR 子句的 LIKE 運算符。
3、會使用 ORDER BY。
4、 WHERE 子句中使用的所有列,都缺少復(fù)合索引。
5、表中共包含 5800 萬條記錄。
我們曾嘗試在查詢中使用的各列上創(chuàng)建一個復(fù)合索引,但最終發(fā)現(xiàn)無濟于事。因為對于 RDBMS 數(shù)據(jù)庫內(nèi)的大表來說,在 VARCHAR 列上搜索文本的效率就不可能太高。
我們知道 Elasticsearch 提供全文本搜索功能,所以想在自己的用例中試試看。我們一直在用 AWS 的云服務(wù),因此選擇了相應(yīng)的 AWS OpenSearch 服務(wù)。
Amazon OpenSearch 托管服務(wù)能幫助用戶輕松在 AWS 云中部署、操作和擴展 OpenSearch 集群。Amazon OpenSearch 是 Amazon Elasticsearch 的繼任方案。
開始行動我們通過腳本將表數(shù)據(jù)從 MySQL 加載到了 AWS OpenSearch 集群當(dāng)中。整個數(shù)據(jù)遷移過程大概用了幾個小時。
我們?yōu)樗饕A袅?5 個分片和 1 個副本因子。
我們還為用例編寫了一條等效的 OpenSearch 查詢,具體如下所示:
API — POST /books-catalog/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"publisherUuid": "1f754fc0-610c-5b29-b22b-fa8140afb7be"
}
},
{
"bool": {
"should": [
{
"match_phrase": {
"displayName": "Software E"
}
},
{
"match_phrase": {
"description": "Software E"
}
}
]
}
}
]
}
},
"size": 100,
"sort": [
{
"displayName.keyword": {
"unmapped_type": "keyword",
"order": "asc"
}
}
]
}
結(jié)果我們的 API 響應(yīng)速度直接縮短至 70 毫秒以內(nèi)。
API 響應(yīng)速度提高了 1000 倍!
關(guān)于 OpenSearch 全文搜索的一些細(xì)節(jié) :
在 ElasticSearch 中對文檔進行索引(創(chuàng)建)時,AWS OpenSearch 會對字符串類型的字段使用文本分析器。
文本分析器會將字符串字段拆分為多個 token,為各 token 構(gòu)建內(nèi)部索引,然后根據(jù)查詢中提供的 token 進行匹配。
權(quán)衡取舍為了避免重寫整個服務(wù),同時盡快在 MySQL 切換至 AWS OpenSearch 后恢復(fù)正常生產(chǎn),我們決定只在這個特定用例中使用 OpenSearch。
而且速度提升 1000 倍的代價,就是多了一套需要在 OpenSearch 當(dāng)中維護的數(shù)據(jù)副本。但由于我們的數(shù)據(jù)大多是靜態(tài)的,持續(xù)更新量非常有限,所以維護強度和成本都很低。
可以看到,選擇正確的數(shù)據(jù)庫引擎往往會給業(yè)務(wù)用例帶來翻天覆地的提升。
希望我們的經(jīng)歷能給大家?guī)硪稽c啟發(fā),祝編程愉快!
-
API
+關(guān)注
關(guān)注
2文章
1510瀏覽量
62286 -
MySQL
+關(guān)注
關(guān)注
1文章
829瀏覽量
26674 -
響應(yīng)時間
+關(guān)注
關(guān)注
0文章
11瀏覽量
6932
原文標(biāo)題:將 API 從 MySQL 遷移到 AWS OpenSearch 后,我們將響應(yīng)時間提高了 1000 倍
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
產(chǎn)品響應(yīng)時間
請問AD9144輸出響應(yīng)時間?
SAR ADC響應(yīng)時間實現(xiàn)迅速響應(yīng)、快速控制的方法
什么是響應(yīng)時間
什么是液晶電視的響應(yīng)時間
光敏電阻響應(yīng)時間研究
SAR ADC 響應(yīng)時間:迅速響應(yīng)、快速控制
什么是單片機的中斷響應(yīng)時間

面板響應(yīng)時間有什么影響
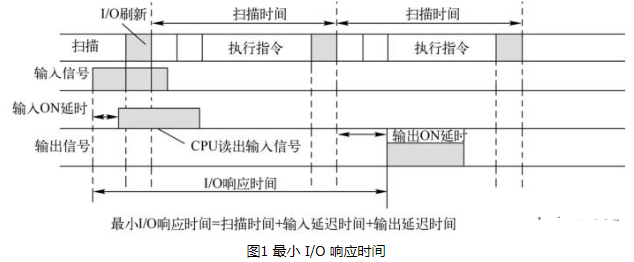
PLC的I/O響應(yīng)時間
進程響應(yīng)時間是指什么
影響VCO響應(yīng)時間的因素
驅(qū)動鈦絲(SMA)的可靠性設(shè)計(3)響應(yīng)時間的設(shè)計





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論