") 2PFLOPS,存算一體迎來新的卷王
2PFLOPS,存算一體迎來新的卷王
存算一體技術(shù)作為當下內(nèi)存廠商和不少AI芯片公司都在全力鉆研的方向,已經(jīng)有了不少成果展示,下一代智能存儲的產(chǎn)品均已呼之欲出了。但新技術(shù)的新生期就是這樣,不斷有新的初創(chuàng)企業(yè)冒頭,不斷有新的架構(gòu)和路線面世,而今年的HotChips34上,就有這么兩個存算一體技術(shù)的分享,在現(xiàn)有的存算一體生態(tài)上做出了創(chuàng)新,再度為這條賽道上的激烈競爭添油加醋。
1PB/s帶寬的千核RISC-V AI推理加速器
存算一體技術(shù)需要解決的,往往都是AI運算上的問題,比如訓練和推理等等,所以不少做存算一體公司與AI芯片公司并無二致。而AI推理的出現(xiàn)為芯片設(shè)計者提出了三大關(guān)鍵挑戰(zhàn),一是不斷提升的算力和功耗要求,不說是存算一體芯片了,GPU、FPGA、ASIC等AI加速器都在往這個方向卷;二是神經(jīng)網(wǎng)絡(luò)的格局一直在變化,現(xiàn)有的芯片可能缺乏跟上節(jié)奏的擴展性和靈活性;第三則是推理精度的缺失,在某些業(yè)務(wù)中精度的缺失可能只是意味著虧損,但在ADAS這樣的應(yīng)用中,就很有可能危及人身安全。
加拿大本土AI初創(chuàng)公司Untether AI就打算從計算的角度來解決AI推理問題,早在2020年他們就推出了runAI200這款加速器芯片,不過該芯片基于臺積電16nm工藝,集成了200MB的SRAM,算力最高也只有500 TOPS(INT8),顯然不能滿足高性能的AI推理需求,但他們的思路卻從一開始就和其他存算一體公司不同。
我們常見的存算一體技術(shù)無疑就是近存計算和存內(nèi)計算這兩種,前者基于馮諾依曼架構(gòu),主要還是完成加快數(shù)據(jù)轉(zhuǎn)移的過程,后者通過模擬技術(shù)來完成乘法累加運算,再利用數(shù)字處理器來完成其他運算。
Untether AI卻提出了存間計算(At-MemoryComputation),將雙向的計算邏輯單元放在SRAM之間。如此一來不僅能提供大規(guī)模并行卻又簡短的直接連接,也能提供獨立優(yōu)化過的內(nèi)存,提升效率和帶寬,根據(jù)Untether AI所說,存間計算恰好能夠解決AI加速的痛點。
1PB/s帶寬的千核RISC-V AI推理加速器
存算一體技術(shù)需要解決的,往往都是AI運算上的問題,比如訓練和推理等等,所以不少做存算一體公司與AI芯片公司并無二致。而AI推理的出現(xiàn)為芯片設(shè)計者提出了三大關(guān)鍵挑戰(zhàn),一是不斷提升的算力和功耗要求,不說是存算一體芯片了,GPU、FPGA、ASIC等AI加速器都在往這個方向卷;二是神經(jīng)網(wǎng)絡(luò)的格局一直在變化,現(xiàn)有的芯片可能缺乏跟上節(jié)奏的擴展性和靈活性;第三則是推理精度的缺失,在某些業(yè)務(wù)中精度的缺失可能只是意味著虧損,但在ADAS這樣的應(yīng)用中,就很有可能危及人身安全。
加拿大本土AI初創(chuàng)公司Untether AI就打算從計算的角度來解決AI推理問題,早在2020年他們就推出了runAI200這款加速器芯片,不過該芯片基于臺積電16nm工藝,集成了200MB的SRAM,算力最高也只有500 TOPS(INT8),顯然不能滿足高性能的AI推理需求,但他們的思路卻從一開始就和其他存算一體公司不同。
我們常見的存算一體技術(shù)無疑就是近存計算和存內(nèi)計算這兩種,前者基于馮諾依曼架構(gòu),主要還是完成加快數(shù)據(jù)轉(zhuǎn)移的過程,后者通過模擬技術(shù)來完成乘法累加運算,再利用數(shù)字處理器來完成其他運算。
Untether AI卻提出了存間計算(At-MemoryComputation),將雙向的計算邏輯單元放在SRAM之間。如此一來不僅能提供大規(guī)模并行卻又簡短的直接連接,也能提供獨立優(yōu)化過的內(nèi)存,提升效率和帶寬,根據(jù)Untether AI所說,存間計算恰好能夠解決AI加速的痛點。
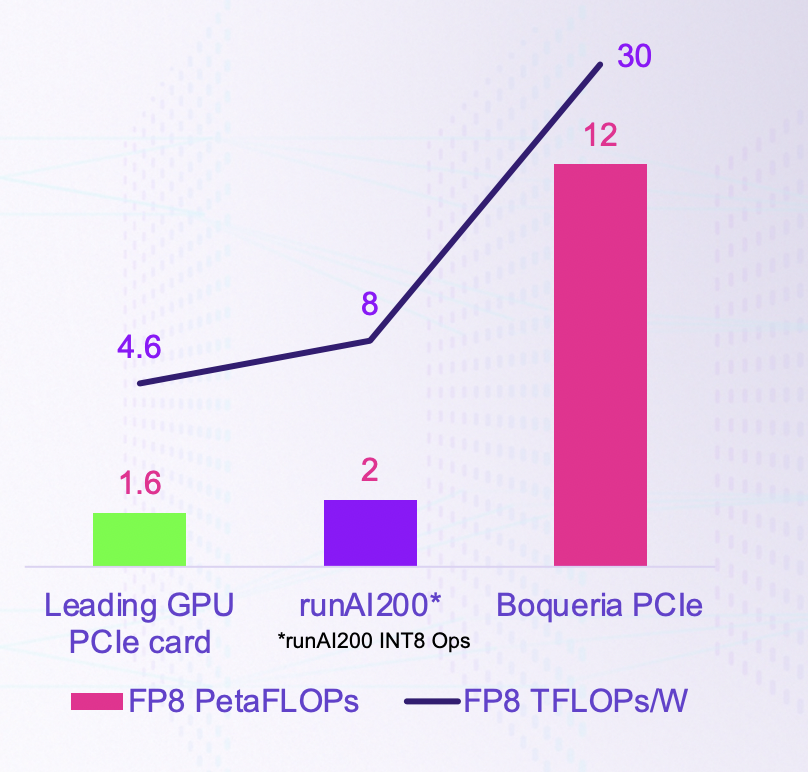
Boqueria與競品的對比/ Untether AI
為此,Untether AI推出了Boqueria,一個算力高達2PFLOPS、能效比高達30TFLOPS/W的存間計算AI推理加速器芯片。Boqueria基于臺積電7nm打造,頻率高達1.35GHz,集成了729個存儲體、238MB的片上SRAM和1458個RISC-V核心,SRAM內(nèi)存帶寬可以達到1PB/s。
每個存儲體中包含2個RISC-V核心,各管理4個行控制器。行控制器之間獨立運行,每個行控制器控制64個SIMD處理單元,用于完成矩陣向量乘法運算。這些處理單元支持INT4、INT8、FP8和BF16這四種常見數(shù)據(jù)格式,而且依Untether AI看來,F(xiàn)P8是精度、吞吐量和能效平衡上最好的一個,更不用說Untether AI在處理單元上加入了零檢測,進一步拉高了能效比。
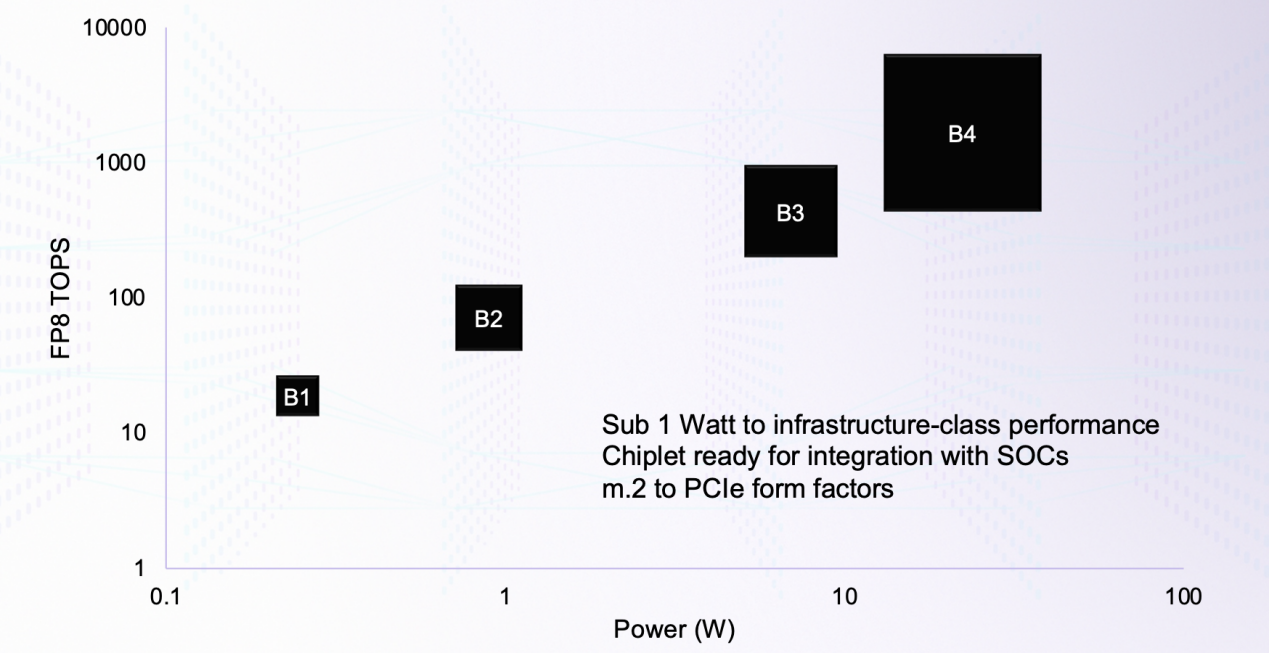
Boqueria架構(gòu)不同規(guī)模下的功耗與算力對比/ Untether AI
Boqueria上的RISC-V核心由Untether AI自己客制化的,本身基于RV32EMC指令集的同時,還加入了20多條專用于存間計算和推理加速的指令。Boqueria的另一大優(yōu)勢,就是它極具擴展性的架構(gòu)。最小的結(jié)構(gòu)可以做到1W以下,也可以將其做成Chiplet集成在其他SoC中,或者是再大一點的M.2卡、PCIe5.0卡等。要想追求最高的性能,可以做成集成6個Boqueria芯片的PCIe5.0卡,SRAM容量可達1.4GB,LPDDR5 DRAM容量可達192GB,F(xiàn)P8算力可達12PFLOPS,更不用說除了芯片到芯片之間的通信外,Boqueria也支持PCIe卡之間的通信。
神經(jīng)形態(tài)存內(nèi)計算處理器
韓國科學技術(shù)院的研究團隊在本屆HotChips上展示了一種新型的存算一體處理器,結(jié)合了時下兩大新技術(shù),神經(jīng)形態(tài)和存內(nèi)計算。傳統(tǒng)的存內(nèi)計算處理器由于在矩陣乘法上的優(yōu)勢,可以為深度學習解決最大的計算問題。可這個計算結(jié)果的準確性很大程度取決于處理器上DAC和ADC的精度。
可DAC和ADC的精度越高,模擬計算的結(jié)果也就越精確,也使得處理器的硬件開銷變高,無論是功耗還是面積都是如此,甚至有可能抵消存內(nèi)計算原本的硬件優(yōu)勢。在整個處理器的功耗中,高精度的ADC甚至可能會占據(jù)一半以上的功耗,甚至超過驅(qū)動器和控制器的總和。
不僅如此,在真實應(yīng)用中由于低稀疏度,其能效比也遠不如紙面數(shù)據(jù)那么理想,比如面對CIFAR-10或ImageNet等數(shù)據(jù)集時,其能效比甚至可能會縮水到十分之一,徹底毀掉了存內(nèi)計算處理器在算力和能耗上的雙重優(yōu)勢。
于是韓國科學技術(shù)院團隊考慮用二進制脈沖信號的事件驅(qū)動運算來生成輸入稀疏,并將卷積神經(jīng)網(wǎng)絡(luò)轉(zhuǎn)換成脈沖神經(jīng)網(wǎng)絡(luò),從而剔除ADC/DAC,并引入了四大特性。比如用最高有效位WordSkipping和早停法來減少位線活動,從而降低各種模式下的功耗,并用混合模式的神經(jīng)元放電和電壓折疊技術(shù),將該處理器的動態(tài)電壓范圍提高至3倍。

傳統(tǒng)存內(nèi)計算架構(gòu)與神經(jīng)形態(tài)存內(nèi)計算架構(gòu)對比/ 韓國科學技術(shù)院
如此一來,他們打造出了一個高能效的神經(jīng)形態(tài)存內(nèi)計算架構(gòu),存內(nèi)計算減少內(nèi)存訪問和多字線驅(qū)動的優(yōu)勢依然保留,但脈沖神經(jīng)網(wǎng)絡(luò)的加入,卻消除了高精度ADC的需求。他們根據(jù)這一架構(gòu)打造出了一個基于28nm工藝的存內(nèi)計算芯片,總存儲大小只有32KB,頻率也只有200MHz,卻可以在100到200mW的系統(tǒng)功耗下,實現(xiàn)最高310.4 TOPS/W的高能效比。考慮到這一研究本身也是由三星贊助,這一思路未來很有可能被用于三星的MRAM存內(nèi)計算芯片中去,屆時才會考慮使用更優(yōu)的工藝來實現(xiàn)更高的性能,并做到更大的容量。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學習之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
內(nèi)存
+關(guān)注
關(guān)注
8文章
3047瀏覽量
74206 -
AI
+關(guān)注
關(guān)注
87文章
31421瀏覽量
269818 -
存算一體
+關(guān)注
關(guān)注
0文章
102瀏覽量
4315
發(fā)布評論請先 登錄
相關(guān)推薦
存算于芯 · 智啟未來 — 2024蘋芯科技產(chǎn)品發(fā)布會盛大召開
8月8日,國際領(lǐng)先的存算一體芯片開拓者——蘋芯科技在北京召開“存算于芯智啟未來——2024蘋芯科技產(chǎn)品發(fā)布會”,集中推出兩款革命性產(chǎn)品:PI


瑞迅科技瑞芯微RK3588系列工控一體機,CPU強大,6TOPS算力的高性能神經(jīng)網(wǎng)絡(luò)處理器單元 #工控一體機
一體機
瑞迅科技
發(fā)布于 :2024年12月02日 17:57:34
開源芯片系列講座第24期:基于SRAM存算的高效計算架構(gòu)
鷺島論壇開源芯片系列講座第24期「基于SRAM存算的高效計算架構(gòu)」明晚(27日)20:00精彩開播期待與您云相聚,共襄學術(shù)盛宴!|直播信息報告題目基于SRAM存算的高效計算架構(gòu)報告簡介

直播預(yù)約 |開源芯片系列講座第24期:SRAM存算一體:賦能高能效RISC-V計算
鷺島論壇開源芯片系列講座第24期「SRAM存算一體:賦能高能效RISC-V計算」11月27日(周三)20:00精彩開播期待與您云相聚,共襄學術(shù)盛宴!|直播信息報告題目SRAM存
存算一體化與邊緣計算:重新定義智能計算的未來
隨著數(shù)據(jù)量爆炸式增長和智能化應(yīng)用的普及,計算與存儲的高效整合逐漸成為科技行業(yè)關(guān)注的重點。數(shù)據(jù)存儲和處理需求的快速增長推動了對計算架構(gòu)的重新設(shè)計,“存算一體化”技術(shù)應(yīng)運而生。同時,隨著物聯(lián)網(wǎng)、5G網(wǎng)絡(luò)

存算一體架構(gòu)創(chuàng)新助力國產(chǎn)大算力AI芯片騰飛
在灣芯展SEMiBAY2024《AI芯片與高性能計算(HPC)應(yīng)用論壇》上,億鑄科技高級副總裁徐芳發(fā)表了題為《存算一體架構(gòu)創(chuàng)新助力國產(chǎn)大算力AI芯片騰飛》的演講。
科技新突破:首款支持多模態(tài)存算一體AI芯片成功問世
存算一體介質(zhì),通過存儲單元和計算單元的深度融合,采用22nm成熟工藝制程,有效把控制造成本。與傳統(tǒng)架構(gòu)下的AI芯片相比,該款芯片在算力、能效比,功耗等方面都具有明顯的優(yōu)勢。芯片采用AI
發(fā)表于 09-26 13:51
?449次閱讀

后摩智能首款存算一體智駕芯片獲評突出創(chuàng)新產(chǎn)品獎
近日,2024年6月29日,由深圳市汽車電子行業(yè)協(xié)會主辦的「第十三屆國際汽車電子產(chǎn)業(yè)峰會暨2023年度汽車電子科學技術(shù)獎頒獎典禮」在深圳寶安隆重舉行。后摩智能首款存算一體智駕芯片——后摩鴻途??H30 獲評「突出創(chuàng)新產(chǎn)品獎」。
蘋芯科技引領(lǐng)存算一體技術(shù)革新 PIMCHIP系列芯片重塑AI計算新格局
智能芯片國產(chǎn)化再傳利好,8月8日,國際領(lǐng)先的存算一體芯片開拓者——蘋芯科技在北京召開 “存算于芯 智啟未來——2024 蘋芯科技產(chǎn)品發(fā)布會”
發(fā)表于 08-08 17:21
?275次閱讀

后摩智能推出邊端大模型AI芯片M30,展現(xiàn)出存算一體架構(gòu)優(yōu)勢
電子發(fā)燒友網(wǎng)報道(文/李彎彎)近日,后摩智能推出基于存算一體架構(gòu)的邊端大模型AI芯片——后摩漫界??M30,最高算力100TOPS,典型功耗12W。為了進
知存科技助力AI應(yīng)用落地:WTMDK2101-ZT1評估板實地評測與性能揭秘
突破正迎合市場需求,使存算一體技術(shù)迎來了產(chǎn)業(yè)化的拐點。新興企業(yè)在探索新技術(shù)應(yīng)用和大算力布局方面更具前瞻性。隨著技術(shù)和應(yīng)用的不斷成熟,這些企業(yè)
發(fā)表于 05-16 16:38
探索存內(nèi)計算—基于 SRAM 的存內(nèi)計算與基于 MRAM 的存算一體的探究
本文深入探討了基于SRAM和MRAM的存算一體技術(shù)在計算領(lǐng)域的應(yīng)用和發(fā)展。首先,介紹了基于SRAM的存內(nèi)邏輯計算技術(shù),包括其原理、優(yōu)勢以及在神經(jīng)網(wǎng)絡(luò)領(lǐng)域的應(yīng)用。其次,詳細討論了基于MR

知存科技攜手北大共建存算一體化技術(shù)實驗室,推動AI創(chuàng)新
揭牌儀式結(jié)束后,王紹迪在北大集成電路學院舉辦的“未名·芯”論壇上做了主題演講,分享了他對于多模態(tài)大模型時代存內(nèi)計算發(fā)展的見解。他強調(diào)了存算一體
北京大學-知存科技存算一體聯(lián)合實驗室揭牌,開啟知存科技產(chǎn)學研融合戰(zhàn)略新升級
5月5日,“北京大學-知存科技存算一體技術(shù)聯(lián)合實驗室”在北京大學微納電子大廈正式揭牌,北京大學集成電路學院院長蔡一茂、北京大學集成電路學院副

聚焦全國一體化算力體系構(gòu)建,憶聯(lián)以強大存力“引擎”釋放算力潛能
算力是數(shù)字時代的生產(chǎn)力,為數(shù)字經(jīng)濟與實體經(jīng)濟深度融合提供了強大支持。在不久前結(jié)束的全國兩會中,“全國一體化算力體系”成為新詞熱詞,會議提出“適度超前建設(shè)數(shù)字基礎(chǔ)設(shè)施,加快形成全國一體化






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論