 基于隨機分區的超快并行DBSCAN算法介紹
基于隨機分區的超快并行DBSCAN算法介紹
DBSCAN是一種基于密度的空間聚類算法。如在點p鄰域范圍內的點達到一定數量則點p稱為核心點,若點q在p的鄰域范圍內,則p直接密度可達q,且p、q屬于同一密集區域。由這種關系連接的最大數據點集形成一個簇。DBSCAN算法有檢測任意形狀的簇、不需要提前知道檢測簇的數量等優點。隨著近年來大規模并行化的熱潮,又出現了許多并行DBSCAN算法。大多數并行DBSCAN算法中,為并行地發現直接密度可達關系,相鄰的點被分配到相同的數據分區中進行并行處理,以方便計算相鄰點的密度。但是,這種數據分區方案會導致一些問題,如分割成本大、子區域重疊、數據分區之間的負載不平衡等,其中負載問題在分布不均勻的數據集中尤為體現。
為了解決這些問題,本文提出了一種新的并行DBSCAN算法,隨機分區DBSCAN,簡稱RP-DBSCAN,它使用偽隨機劃分和兩級單元格字典。偽隨機劃分是一種基于單元格的數據劃分方案,它可以隨機采樣小的單元格,而不是點本身。無論數據如何分布,它都可以實現負載平衡,同時保持DBSCAN所需的數據連續性。兩級單元格字典是整個數據集的一個高度凝煉的摘要,來表示每個隨機分區。該算法能夠實現同時找到每個數據分區的局部聚類,然后將這些局部聚類合并得到全局聚類。
一.偽隨機劃分
本文定義d維空間中的一個單元格是一個對角線長度為ε 的d維超立方體,ε 是一個表示鄰域半徑的參數。如果至少有一個數據點位于一個密集區域內,則可以保證該單元格中的所有數據點都屬于同一簇。這大大簡化了之后的聚類合并過程。在進行數據分區時,我們隨機采樣單元格,而不是采樣數據點,因此稱為偽隨機劃分。然后,將相同顏色的單元格及其內部的數據點劃分為同一個分區。由于ε 遠小于整個空間的長度,這種劃分也可以實現真正的隨機劃分的效果。圖 1 說明了偽隨機分區的思想,不同顏色代表不同分區。
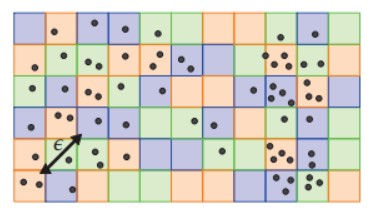
圖1 偽隨機劃分
二.兩級單元格字典
兩級單元格字典是整個數據集的一個摘要。本質上它是一個兩級的樹。第一級的節點對應單元格,第二級的節點對應子單元格,其邊長為單元格的h分之一,其中h由用戶給出以指定近似度。每個節點編碼每個(子)單元格的密度及其位置。密度是其內部的點數,而位置可以用它們所屬單元內的子單元的順序來表示,故只用d(h? 1)位。(d是維度,h是字典級數)如圖 2,h = 2,d= 2,只需兩位來表示子單元格位置(00,01,10,11)。
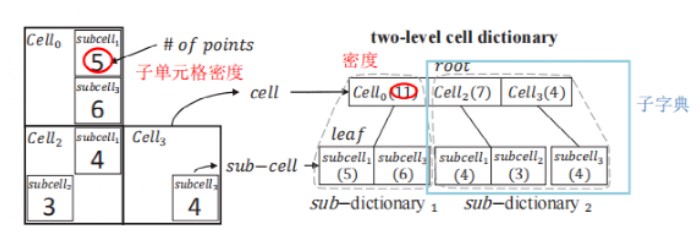
圖2 兩級單元格字典的構建
因此,可以得出兩級單元格字典總大小為
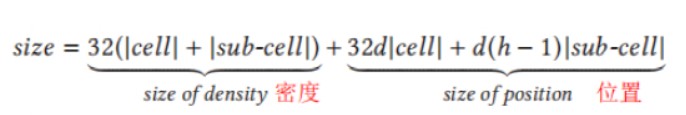
如果數據集非常大,由于內存的限制,有可能無法立即加載整個兩級單元格字典,因此把字典劃分成較小的子字典,它由根節點集合的一個子集以及與它們連接的葉節點組成。
三. 算法實現的三個階段
1. 數據分區
通過偽隨機劃分對整個數據集進行分區,并構建兩級單元格字典,為并行處理做好準備。向并行系統中的每個工作者發送一個分區和對應的兩級單元格字典。如圖3,整個空間被劃分為諸多單元格,其中沒有為空區域創建單元格。將黃色和綠色單元格劃分到兩個不同的分區P1和P2中。然后為每個分區生成一個兩級單元格字典。
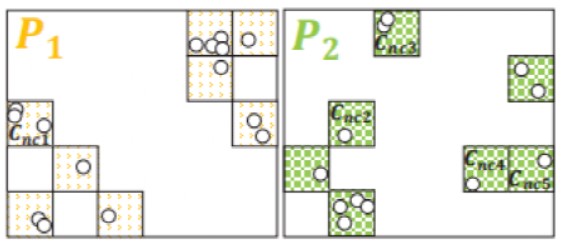
圖3 數據分區
2. 單元格圖的構造
通過(ε, ρ)區域查詢的方式區分單元格是否為核心單元格,構造單元格圖時將排除非核心單元格。如圖3中的Cnc1-Cnc5判斷為非核的,它們在圖4中將被排除。然后,從每個分區的每個核心單元搜索其所有完全或部分直接可達的單元格來構建一個單元圖。這些單獨的關系可以在單元格級別上進行聚合,從而生成一個單元格圖。單元格圖的頂點是單元格,邊是單元格之間的可達性關系。總的來說,一個單元格圖表示從一個給定的分區中獲得的局部聚類。
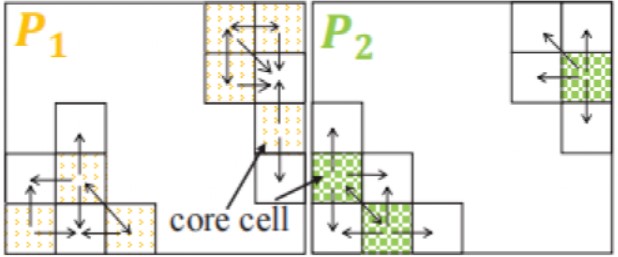
圖4 單元格圖構造
(ε, ρ)區域查詢:
如圖5所示,若點p與子單元格中心scn的距離小于ε ,那么,就將這個子單元格加入到點p的鄰居集合當中。當點p的鄰居點數大于等于設定的參數minPts,就把包含p的單元格標記為核心單元格。
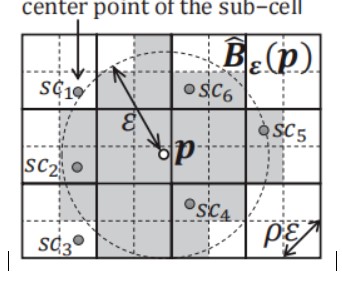
圖5 (ε,ρ)區域查詢
3. 單元格圖的合并
這一部分主要包括漸進式圖合并和點標記兩個過程。首先,結合從每個工作者返回的對應每個分區的單元格圖,確認每條邊直接可達性關系,以合并成全局單元格圖。之后,根據合并后的圖對聚類進行擴展,并根據最終的聚類結果來標記所有的點。整個過程就是由局部聚類產生全局聚類。例如在圖 6 中,單元格圖簡單合并后要進行邊類型檢測,即判斷是完全邊(深色實線),部分邊(實線箭頭)還是未知邊(虛線箭頭),還要進行減邊操作,根據樹的結構去除冗余邊,最終得到一個樹式的全局單元格圖。然后,圖 7 中進行點標記,圖4中位于P1和P2左下角的單元格在圖 7 中形成了一個C1簇,將單元格其中的點標記為同一個顏色,即為最終聚類的結果。
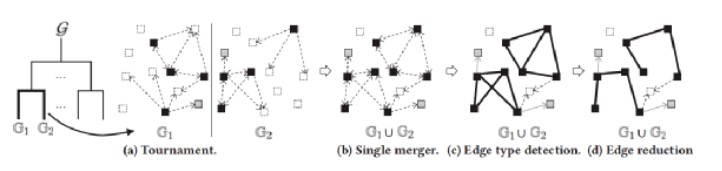
圖6 漸進式圖合并
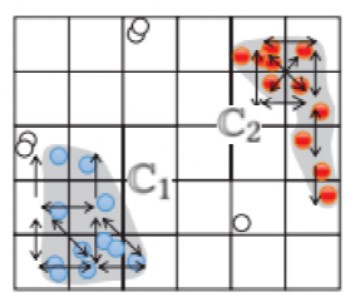
圖7 點標記
四. 總結
本文提出采用隨機劃分策略并行運行DBSCAN。為此,提出了一種基于單元格的數據分割策略,即偽隨機劃分,它具有區域劃分策略和隨機劃分策略的優點。為了能夠在隨機分割上執行區域查詢,本文設計了兩級單元格字典,它是整個數據集的一個高度凝煉的摘要。將它們放在一起,開發了一個高效的并行DBSCAN算法RP-DBSCAN。本文使用GeoLife,Cosmo50,OpenStreetMap等大規模數據集進行實驗,將RP-DBSCAN與SPARK-DBSCAN,ESP-DBSCAN等其它6種算法進行效率和精確度的對比。結果顯示,RP-DBSCAN更快,更精準,更高效且可擴展性強。RP-DBSCAN顯著地超過了最先進的并行DBSCAN算法高達180倍。此外,只有RP-DBSCAN可以處理最大的362GB數據集,而其他算法則不能,有力地驗證了其性能的優越性。本文的研究工作顯著地提高了DBSCAN算法在大數據時代的可用性。
審核編輯:劉清
-
編碼
+關注
關注
6文章
957瀏覽量
54911 -
DBSCAN
+關注
關注
0文章
7瀏覽量
10431 -
DBSCAN算法
+關注
關注
0文章
3瀏覽量
1256
發布評論請先 登錄
相關推薦
xgboost的并行計算原理
小鵬大眾將攜手合力打造中國最大的超快充網絡
迅為RK3568開發板傳統分區和定制擴展分區鏡像對比
有獎問卷:隨機抽取 30 名用戶送出快充數據線
使用FAL分區管理與easyflash變量管理

合科泰超快恢復二極管ES1JL產品介紹

剛剛,國內超快光纖激光器獲重要進展
如何采用分區架構提升車輛的簡易性
超快恢復二極管ES1GF的應用介紹
GGII:新上市快充車型超15款,中國快充版車型銷量有望超5萬輛

什么是超快激光器?

昊鉑超充站已超1200座,15分鐘快充續航450km
什么是隨機森林?隨機森林的工作原理





 工商網監
工商網監
評論