 3個DNN的項目介紹
3個DNN的項目介紹
介紹
深度神經網絡 (DNN) 是一種人工神經網絡(ANN),在輸入層和輸出層之間具有多層。有不同類型的神經網絡,但它們基本由相同的組件組成:神經元、突觸、權重、偏差和函數。這些組件的功能類似于人類大腦,可以像任何其他 ML 算法一樣進行訓練。
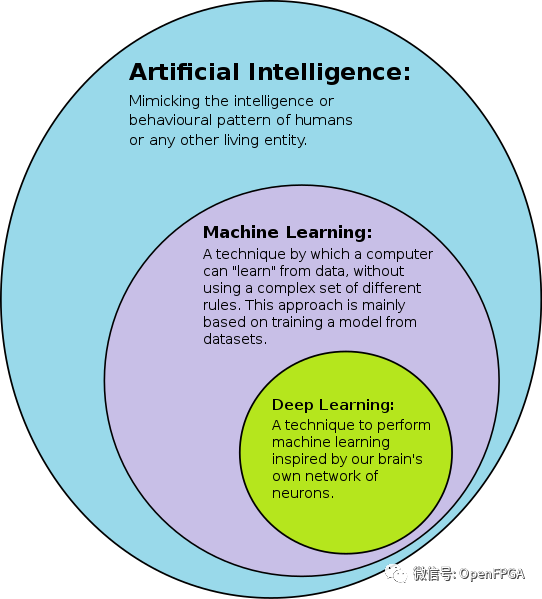
例如,經過訓練以識別狗品種的 DNN 將遍歷給定的圖像并計算圖像中的狗是某個品種的概率。用戶可以查看結果并選擇網絡應該顯示哪些概率(超過某個閾值等)并返回建議的標簽。每個數學操作都被認為是一個層,復雜的 DNN 有很多層,因此被稱為“深度”網絡。
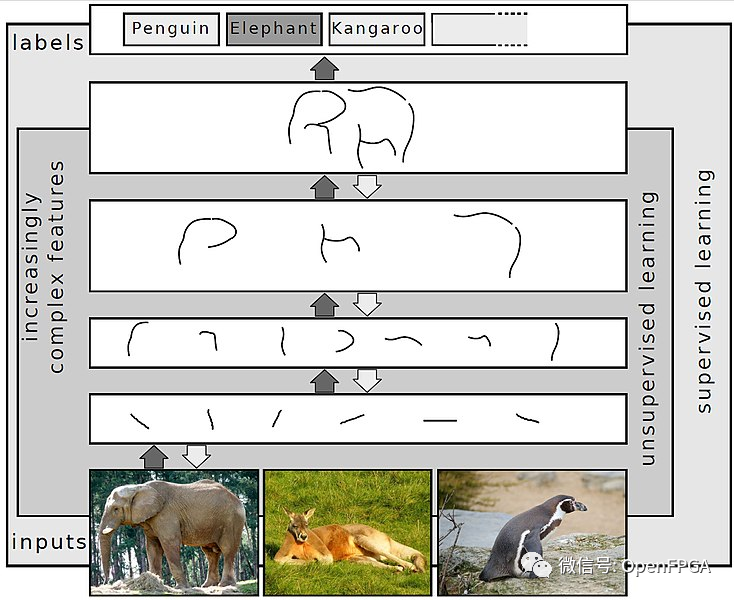
關于DNN、ANN、CNN區別,請看下圖:
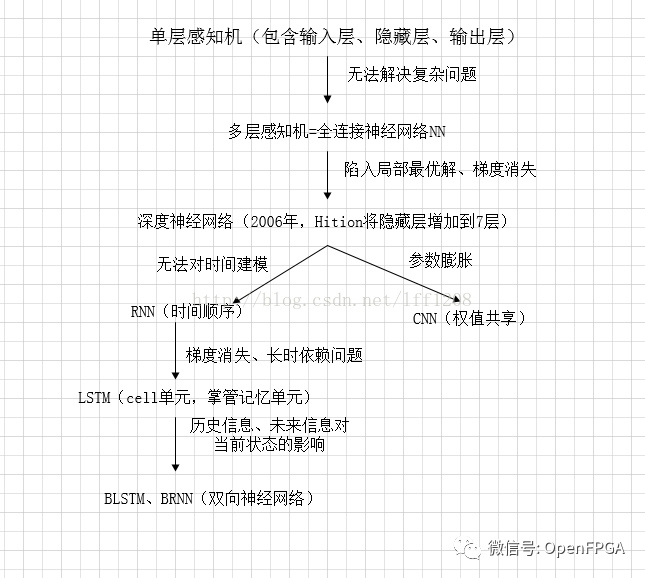
https://blog.csdn.net/lff1208/article/details/77717149
IBM_AccDNN
https://github.com/IBM/AccDNN
AccDNN(深度神經網絡加速器核心編譯器)又名;DNNBuilder
項目介紹
在這個項目中,我們提出了一種新穎的解決方案,可以自動將經過 Caffe 訓練的深度神經網絡轉換為 FPGA RTL 級別的實現,無需任何編程工作,并為用戶的識別任務提供統一的 API。
因此,沒有任何 FPGA 編程經驗的開發人員可以將他們的 FPGA 加速深度學習服務部署在數據中心或邊緣設備中,僅提供他們經過訓練的 Caffe 模型。該作品發表在 ICCAD'18 上,并獲得了前端最佳論文獎。了解更多設計細節。請參考我們的論文(https://docs.wixstatic.com/ugd/c50250_77e06b7f02b44eacb76c05e8fbe01e08.pdf)。
轉換過程
轉換包括三個階段:
首先對 Caffe 網絡文件進行解析,得到網絡結構。我們估計每一層的工作量以確定在 FPFA 資源約束下的并行度。
該網絡中定義的每一層通過在庫中實例化相應的神經層來生成一個定制的 Verilog 模塊。頂層模塊也是根據net文件中定義的層順序將這些自定義實例連接在一起生成的,并且在這個階段也生成了權重所需的片上內存。
綜合生成的源文件、布線和布局,生成可執行的 FPGA 位文件。
AccDNN 缺點
僅支持 Caffe 框架訓練的模型。
僅支持卷積層、最大池化層、全連接層和批量歸一化層。
Caffe .prototxt 中定義的網絡中卷積層和全連接層的總數應少于 15 層
DNN-Hardware-Accelerator
https://github.com/ryaanluke/DNN-Hardware-Accelerator
https://github.com/gwatcha/dnn_accelerator
介紹
在本實驗中,將以嵌入式 Nios II 系統為核心構建深度神經網絡加速器。在本項目中還將學習如何與片外 SDRAM 連接,以及如何使用 PLL 生成具有特定屬性的時鐘。
由于整個系統比我們之前構建的系統更復雜,因此在將設計的所有部分連接在一起之前,編寫大量的測試單元并仔細調試將變得尤為重要。
深度神經網絡
我們將使用一種稱為多層感知器 (MLP) 的神經網絡對 MNIST 手寫數字數據集進行分類。也就是說,我們的 MLP 將以 28×28 像素的灰度圖像作為輸入,并確定該圖像對應的數字 (0..9)。
MLP 由幾個線性層組成,它們首先將前一層的輸出乘以權重矩陣,并為每個輸出添加一個恒定的“偏差”值,然后應用非線性激活函數來獲得當前層的輸出(稱為激活)。我們的 MLP 將有一個 784 像素的輸入(28×28 像素的圖像)、兩個 1000 個神經元的隱藏層和一個 10 個神經元的輸出層;具有最高值的輸出神經元將告訴我們網絡認為它看到了哪個數字。對于激活函數,我們將使用整流線性單元 (ReLU),它將所有負數映射到 0,將所有正數映射到自身。
在推理過程中,每一層計算a' = ReLU( W · a + b ),其中W是權重矩陣,a是前一層的激活向量,b是偏置向量,a'是當前層的激活向量。
不要被神經網絡等花哨的術語嚇倒——你實際上是在構建一個加速器來進行矩陣向量乘法。這里的大部分挑戰來自與片外 SDRAM 存儲器的交互以及正確處理諸如waitrequest和readdatavalid 之類的信號。
不需要知道這些網絡是如何訓練的,因為我們已經為您訓練了網絡并預先格式化了圖像(請參閱data文件夾的內容和測試輸入列表)。但是,如果好奇,可以查看scripts/train.py我們是如何訓練 MLP 的。

關于該項目的一些補充說明請查看下面的PDF:
https://github.com/ryaanluke/DNN-Hardware-Accelerator/blob/main/Deep%20Neural%20Networks%20on%20FPGA.pdf
DNN-accelerator-on-zynq
https://github.com/joycenerd/DNN-accelerator-on-zynq
https://github.com/karanam1997/Dnnweaver-Zed-board-/tree/master/DNNWeaver_original
https://github.com/anonsum/DNNWeaver_Simulations
設計要求:

整個系統框圖如下:
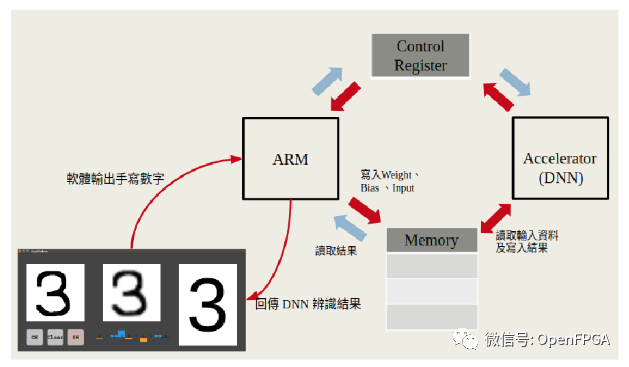
相關的設計文檔:
https://github.com/joycenerd/DNN-accelerator-on-zynq/blob/master/2019DD_lab12Finalv4.pdf
Handwritting-number-distinguishing-with-DNN-by-Nexys-4-DDR-in-Verilog-HDL
https://github.com/MaxMorning/Handwritting-number-distinguishing-with-DNN-by-Nexys-4-DDR-in-Verilog-HDL
用 Verilog HDL 實現 DNN 區分手寫數字,在Nexys 4 DDR 上運行。
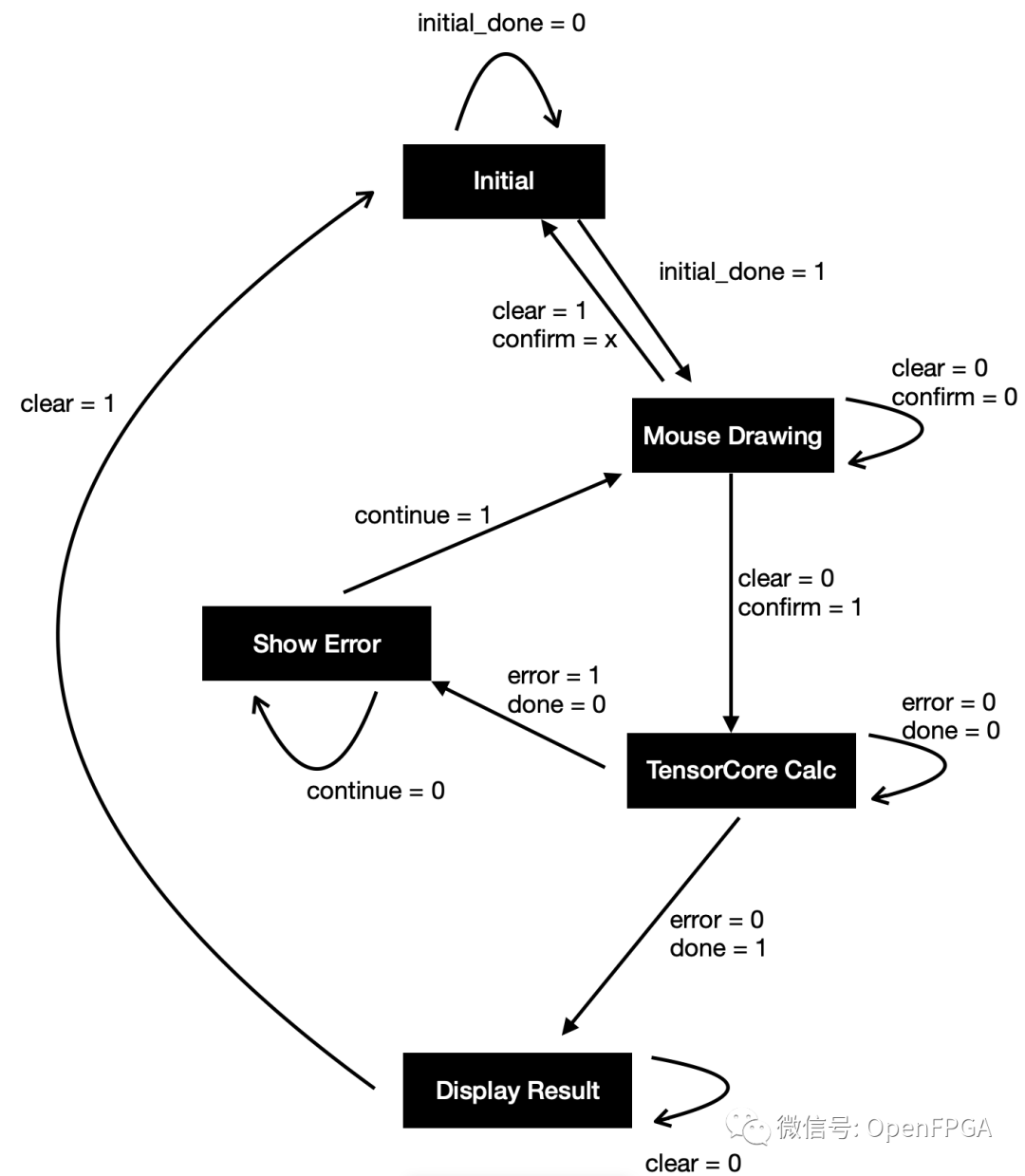
總結
今天介紹了3個DNN的項目,主要是DNN復雜度較TPU或者CNN高了幾個臺階,所以用它來直接對FPGA進行移植難度很大,還是只建議對第一個IBM項目進行研究,其他在ZYNQ上進行數字識別適合實現,其他都不怎么推薦。
關于DNN或者CNN也介紹了幾十個項目了,這些只適合學習研究,并不適合拿來商用,所以后臺噴我的小伙伴要求也不要太高,這些開源的項目能直接商用的少之又少,大部分項目只適合學習。還有一些項目是學生做的,所以你們也不必噴:說是拿一些學生做的項目能干什么,我這里只想說,這些項目至少能給您一些參考,什么事情總比從零開始好,或者讓你們了解一些同齡人在學校里在干什么,最后,這些項目您又看不上您開源幾個出來~
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4778瀏覽量
101023 -
dnn
+關注
關注
0文章
60瀏覽量
9073
原文標題:?優秀的 Verilog/FPGA開源項目- 深度神經網絡 (DNN)
文章出處:【微信號:HXSLH1010101010,微信公眾號:FPGA技術江湖】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
2025年半導體行業將啟動18個新晶圓廠項目
充電樁3C認證有哪些測試項目
9個開關電源電路設計項目
如何將布局受限的從屬entity應用到另一個項目
重裝PSoC Creator后無法打開CCG3PA項目,為什么?
深度神經網絡(DNN)架構解析與優化策略
BP神經網絡屬于DNN嗎
分享6個實用的ESP32-S3物聯網項目:從智能設備到安全創新
自制一個3D打印的移動終端——T3rminal

基于FPGA進行DNN設計的經驗總結

【Longan Pi 3H 開發板試用連載體驗】基于 Longan Pi 3H 開發板完成智能家居控制小型項目
Eclipse EZ-USB1.3.5為CX3創建一個新的配置項目時報向導無法啟動的原因?怎么解決?
基于OpenCV DNN實現YOLOv8的模型部署與推理演示
重慶公布SiC重大項目 三安2個工廠即將點亮投產






 工商網監
工商網監
評論