 TensorRT創建層時序緩存以保存層分析信息
TensorRT創建層時序緩存以保存層分析信息
6.1. The Timing Cache
為了減少構建器時間,TensorRT 創建了一個層時序緩存,以在構建器階段保存層分析信息。它包含的信息特定于目標構建器設備、CUDA 和 TensorRT 版本,以及可以更改層實現的BuilderConfig參數,例如BuilderFlag::kTF32或BuilderFlag::kREFIT。
如果有其他層具有相同的輸入/輸出張量配置和層參數,則 TensorRT 構建器會跳過分析并重用重復層的緩存結果。如果緩存中的計時查詢未命中,則構建器會對該層計時并更新緩存。
時序緩存可以被序列化和反序列化。您可以通過IBuilderConfig::createTimingCache從緩沖區加載序列化緩存:
ITimingCache* cache = config->createTimingCache(cacheFile.data(), cacheFile.size());
將緩沖區大小設置為0會創建一個新的空時序緩存。
然后,在構建之前將緩存附加到構建器配置。
config->setTimingCache(*cache, false);
在構建期間,由于緩存未命中,時序緩存可以增加更多信息。在構建之后,它可以被序列化以與另一個構建器一起使用。
IHostMemory* serializedCache = cache->serialize();
如果構建器沒有附加時間緩存,構建器會創建自己的臨時本地緩存并在完成時將其銷毀。
緩存與算法選擇不兼容(請參閱算法選擇和可重現構建部分)。可以通過設置BuilderFlag來禁用它。
6.2. Refitting An Engine
TensorRT 可以用新的權重改裝引擎而無需重建它,但是,在構建時必須指定這樣做的選項:
... config->setFlag(BuilderFlag::kREFIT) builder->buildSerializedNetwork(network, config);
稍后,您可以創建一個Refitter對象:
ICudaEngine* engine = ...; IRefitter* refitter = createInferRefitter(*engine,gLogger)
然后更新權重。例如,要更新名為“MyLayer”的卷積層的內核權重:
Weights newWeights = ...;
refitter->setWeights("MyLayer",WeightsRole::kKERNEL,
newWeights);
新的權重應該與用于構建引擎的原始權重具有相同的計數。如果出現問題,例如錯誤的層名稱或角色或權重計數發生變化,setWeights返回false。
由于引擎優化的方式,如果您更改一些權重,您可能還必須提供一些其他權重。該界面可以告訴您需要提供哪些額外的權重。
您可以使用INetworkDefinition::setWeightsName()在構建時命名權重 – ONNX 解析器使用此 API 將權重與 ONNX 模型中使用的名稱相關聯。然后,您可以使用setNamedWeights更新權重:
Weights newWeights = ...;
refitter->setNamedWeights("MyWeights", newWeights);
setNamedWeights和setWeights可以同時使用,即,您可以通過setNamedWeights更新具有名稱的權重,并通過setWeights更新那些未命名的權重。
這通常需要兩次調用IRefitter::getMissing,首先獲取必須提供的權重對象的數量,然后獲取它們的層和角色。
const int32_t n = refitter->getMissing(0, nullptr, nullptr); std::vectorlayerNames(n); std::vector weightsRoles(n); refitter->getMissing(n, layerNames.data(), weightsRoles.data());
或者,要獲取所有缺失權重的名稱,請運行:
const int32_t n = refitter->getMissingWeights(0, nullptr); std::vectorweightsNames(n); refitter->getMissingWeights(n, weightsNames.data());
您可以按任何順序提供缺失的權重:
for (int32_t i = 0; i < n; ++i)
refitter->setWeights(layerNames[i], weightsRoles[i],
Weights{...});
返回的缺失權重集是完整的,從某種意義上說,僅提供缺失的權重不會產生對任何更多權重的需求。
提供所有權重后,您可以更新引擎:
bool success = refitter->refitCudaEngine(); assert(success);
如果refit返回false,請檢查日志以獲取診斷信息,可能是關于仍然丟失的權重。 然后,您可以刪除refitter:
delete refitter;
更新后的引擎的行為就像它是從使用新權重更新的網絡構建的一樣。
要查看引擎中的所有可改裝權重,請使用refitter->getAll(...)或refitter->getAllWeights(...);類似于上面使用getMissing和getMissingWeights的方式。
6.3. Algorithm Selection and Reproducible Builds
TensorRT 優化器的默認行為是選擇全局最小化引擎執行時間的算法。它通過定時每個實現來做到這一點,有時,當實現具有相似的時間時,系統噪聲可能會決定在構建器的任何特定運行中將選擇哪個。不同的實現通常會使用不同的浮點值累加順序,兩種實現可能使用不同的算法,甚至以不同的精度運行。因此,構建器的不同調用通常不會導致引擎返回位相同的結果。
有時,確定性構建或重新創建早期構建的算法選擇很重要。通過提供IAlgorithmSelector接口的實現并使用setAlgorithmSelector將其附加到構建器配置,您可以手動指導算法選擇。
方法IAlgorithmSelector::selectAlgorithms接收一個AlgorithmContext,其中包含有關層算法要求的信息,以及一組滿足這些要求的算法選擇。它返回 TensorRT 應該為層考慮的算法集。
構建器將從這些算法中選擇一種可以最小化網絡全局運行時間的算法。如果未返回任何選項并且BuilderFlag::kREJECT_EMPTY_ALGORITHMS未設置,則 TensorRT 將其解釋為意味著任何算法都可以用于該層。要覆蓋此行為并在返回空列表時生成錯誤,請設置BuilderFlag::kREJECT_EMPTY_ALGORITHMSS標志。
在 TensorRT 完成對給定配置文件的網絡優化后,它會調用reportAlgorithms,它可用于記錄為每一層做出的最終選擇。
selectAlgorithms返回一個選項。要重播早期構建中的選擇,請使用reportAlgorithms記錄該構建中的選擇,并在selectAlgorithms中返回它們。
sampleAlgorithmSelector演示了如何使用算法選擇器在構建器中實現確定性和可重復性。
注意:
-
算法選擇中的“層”概念與
INetworkDefinition中的ILayer不同。由于融合優化,前者中的“層”可以等同于多個網絡層的集合。 -
selectAlgorithms中選擇最快的算法可能不會為整個網絡產生最佳性能,因為它可能會增加重新格式化的開銷。 -
如果 TensorRT 發現該層是空操作,則
IAlgorithm的時間在selectAlgorithms中為0 。 -
reportAlgorithms不提供提供給selectAlgorithms的IAlgorithm的時間和工作空間信息。
6.4. Creating A Network Definition From Scratch
除了使用解析器,您還可以通過網絡定義 API 將網絡直接定義到 TensorRT。此場景假設每層權重已在主機內存中準備好在網絡創建期間傳遞給 TensorRT。
以下示例創建了一個簡單的網絡,其中包含Input、Convolution、Pooling、MatrixMultiply、Shuffle、Activation和Softmax層。
6.4.1. C++
本節對應的代碼可以在sampleMNISTAPI中找到。在此示例中,權重被加載到以下代碼中使用的weightMap數據結構中。
首先創建構建器和網絡對象。請注意,在以下示例中,記錄器通過所有 C++ 示例通用的logger.cpp文件進行初始化。 C++ 示例幫助程序類和函數可以在common.h頭文件中找到。
auto builder = SampleUniquePtr(nvinfer1::createInferBuilder(sample::gLogger.getTRTLogger()));
const auto explicitBatchFlag = 1U << static_cast(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
auto network = SampleUniquePtr(builder->createNetworkV2(explicitBatchFlag));
kEXPLICIT_BATCH標志的更多信息,請參閱顯式與隱式批處理部分。
通過指定輸入張量的名稱、數據類型和完整維度,將輸入層添加到網絡。一個網絡可以有多個輸入,盡管在這個示例中只有一個:
auto data = network->addInput(INPUT_BLOB_NAME, datatype, Dims4{1, 1, INPUT_H, INPUT_W});
添加帶有隱藏層輸入節點、步幅和權重的卷積層,用于過濾器和偏差。
auto conv1 = network->addConvolution( *data->getOutput(0), 20, DimsHW{5, 5}, weightMap["conv1filter"], weightMap["conv1bias"]); conv1->setStride(DimsHW{1, 1});
注意:傳遞給 TensorRT 層的權重在主機內存中。
添加池化層;請注意,前一層的輸出作為輸入傳遞。
auto pool1 = network->addPooling(*conv1->getOutput(0), PoolingType::kMAX, DimsHW{2, 2});
pool1->setStride(DimsHW{2, 2});
添加一個 Shuffle 層來重塑輸入,為矩陣乘法做準備:
int32_t const batch = input->getDimensions().d[0];
int32_t const mmInputs = input.getDimensions().d[1] * input.getDimensions().d[2] * input.getDimensions().d[3];
auto inputReshape = network->addShuffle(*input);
inputReshape->setReshapeDimensions(Dims{2, {batch, mmInputs}});
現在,添加一個MatrixMultiply層。在這里,模型導出器提供了轉置權重,因此為這些權重指定了kTRANSPOSE選項。
IConstantLayer* filterConst = network->addConstant(Dims{2, {nbOutputs, mmInputs}}, mWeightMap["ip1filter"]);
auto mm = network->addMatrixMultiply(*inputReshape->getOutput(0), MatrixOperation::kNONE, *filterConst->getOutput(0), MatrixOperation::kTRANSPOSE);
添加偏差,它將在批次維度上廣播。
auto biasConst = network->addConstant(Dims{2, {1, nbOutputs}}, mWeightMap["ip1bias"]);
auto biasAdd = network->addElementWise(*mm->getOutput(0), *biasConst->getOutput(0), ElementWiseOperation::kSUM);
添加 ReLU 激活層:
auto relu1 = network->addActivation(*ip1->getOutput(0), ActivationType::kRELU);
添加 SoftMax 層以計算最終概率:
auto prob = network->addSoftMax(*relu1->getOutput(0));
為 SoftMax 層的輸出添加一個名稱,以便在推理時可以將張量綁定到內存緩沖區:
prob->getOutput(0)->setName(OUTPUT_BLOB_NAME);
將其標記為整個網絡的輸出:
network->markOutput(*prob->getOutput(0));
代表 MNIST 模型的網絡現已完全構建。請參閱構建引擎和反序列化文件部分,了解如何構建引擎并使用此網絡運行推理。
6.4.2. Python
此部分對應的代碼可以在network_api_pytorch_mnist中找到。
這個例子使用一個幫助類來保存一些關于模型的元數據:
class ModelData(object):
INPUT_NAME = "data"
INPUT_SHAPE = (1, 1, 28, 28)
OUTPUT_NAME = "prob"
OUTPUT_SIZE = 10
DTYPE = trt.float32
在此示例中,權重是從 Pytorch MNIST 模型導入的。
weights = mnist_model.get_weights()
創建記錄器、構建器和網絡類。
TRT_LOGGER = trt.Logger(trt.Logger.ERROR) builder = trt.Builder(TRT_LOGGER) EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH) network = builder.create_network(common.EXPLICIT_BATCH)
kEXPLICIT_BATCH標志的更多信息,請參閱顯式與隱式批處理部分。
接下來,為網絡創建輸入張量,指定張量的名稱、數據類型和形狀。
input_tensor = network.add_input(name=ModelData.INPUT_NAME, dtype=ModelData.DTYPE, shape=ModelData.INPUT_SHAPE)
添加一個卷積層,指定輸入、輸出圖的數量、內核形狀、權重、偏差和步幅:
conv1_w = weights['conv1.weight'].numpy()
conv1_b = weights['conv1.bias'].numpy()
conv1 = network.add_convolution(input=input_tensor, num_output_maps=20, kernel_shape=(5, 5), kernel=conv1_w, bias=conv1_b)
conv1.stride = (1, 1)
添加一個池化層,指定輸入(前一個卷積層的輸出)、池化類型、窗口大小和步幅:
pool1 = network.add_pooling(input=conv1.get_output(0), type=trt.PoolingType.MAX, window_size=(2, 2))
pool1.stride = (2, 2)
添加下一對卷積和池化層:
conv2_w = weights['conv2.weight'].numpy()
conv2_b = weights['conv2.bias'].numpy()
conv2 = network.add_convolution(pool1.get_output(0), 50, (5, 5), conv2_w, conv2_b)
conv2.stride = (1, 1)
pool2 = network.add_pooling(conv2.get_output(0), trt.PoolingType.MAX, (2, 2))
pool2.stride = (2, 2)
添加一個 Shuffle 層來重塑輸入,為矩陣乘法做準備:
batch = input.shape[0] mm_inputs = np.prod(input.shape[1:]) input_reshape = net.add_shuffle(input) input_reshape.reshape_dims = trt.Dims2(batch, mm_inputs)
現在,添加一個MatrixMultiply層。在這里,模型導出器提供了轉置權重,因此為這些權重指定了kTRANSPOSE選項。
filter_const = net.add_constant(trt.Dims2(nbOutputs, k), weights["fc1.weight"].numpy()) mm = net.add_matrix_multiply(input_reshape.get_output(0), trt.MatrixOperation.NONE, filter_const.get_output(0), trt.MatrixOperation.TRANSPOSE);
添加將在批次維度廣播的偏差添加:
bias_const = net.add_constant(trt.Dims2(1, nbOutputs), weights["fc1.bias"].numpy()) bias_add = net.add_elementwise(mm.get_output(0), bias_const.get_output(0), trt.ElementWiseOperation.SUM)
添加 Relu 激活層:
relu1 = network.add_activation(input=fc1.get_output(0), type=trt.ActivationType.RELU)
添加最后的全連接層,并將該層的輸出標記為整個網絡的輸出:
fc2_w = weights['fc2.weight'].numpy()
fc2_b = weights['fc2.bias'].numpy()
fc2 = network.add_fully_connected(relu1.get_output(0), ModelData.OUTPUT_SIZE, fc2_w, fc2_b)
fc2.get_output(0).name = ModelData.OUTPUT_NAME
network.mark_output(tensor=fc2.get_output(0))
代表 MNIST 模型的網絡現已完全構建。請參閱構建引擎和執行推理部分,了解如何構建引擎并使用此網絡運行推理。
6.5. Reduced Precision
6.5.1. Network-level Control of Precision
默認情況下,TensorRT 以 32 位精度工作,但也可以使用 16 位浮點和 8 位量化浮點執行操作。使用較低的精度需要更少的內存并實現更快的計算。
降低精度支持取決于您的硬件(請參閱NVIDIA TensorRT 支持矩陣中的硬件和精度部分)。您可以查詢構建器以檢查平臺上支持的精度支持:C++
if (builder->platformHasFastFp16()) { … };
Python
if builder.platform_has_fp16:
在構建器配置中設置標志會通知 TensorRT 它可能會選擇較低精度的實現:C++
config->setFlag(BuilderFlag::kFP16);
Python
config.set_flag(trt.BuilderFlag.FP16)
共有三個精度標志:FP16、INT8和TF32,它們可以獨立啟用。請注意,如果 TensorRT 導致整體運行時間較短,或者不存在低精度實現,TensorRT 仍將選擇更高精度的內核。
當 TensorRT 為層選擇精度時,它會根據需要自動轉換權重以運行層。
sampleGoogleNet和sampleMNIST提供了使用這些標志的示例。
雖然使用FP16和TF32精度相對簡單,但使用INT8時會有額外的復雜性。有關詳細信息,請參閱使用 INT8章節。
6.5.2. Layer-level Control of Precision
builder-flags提供了允許的、粗粒度的控制。然而,有時網絡的一部分需要更高的動態范圍或對數值精度敏感。您可以限制每層的輸入和輸出類型:C++
layer->setPrecision(DataType::kFP16)
Python
layer.precision = trt.fp16
這為輸入和輸出提供了首選類型(此處為DataType::kFP16)。
您可以進一步設置圖層輸出的首選類型:
C++
layer->setOutputType(out_tensor_index, DataType::kFLOAT)
Python
layer.set_output_type(out_tensor_index, trt.fp16)
計算將使用與輸入首選相同的浮點類型。大多數 TensorRT 實現具有相同的輸入和輸出浮點類型;但是,Convolution、Deconvolution和FullyConnected可以支持量化的INT8輸入和未量化的FP16或FP32輸出,因為有時需要使用來自量化輸入的更高精度輸出來保持準確性。
設置精度約束向 TensorRT 提示它應該選擇一個輸入和輸出與首選類型匹配的層實現,如果前一層的輸出和下一層的輸入與請求的類型不匹配,則插入重新格式化操作。請注意,只有通過構建器配置中的標志啟用了這些類型,TensorRT 才能選擇具有這些類型的實現。
默認情況下,TensorRT 只有在產生更高性能的網絡時才會選擇這樣的實現。如果另一個實現更快,TensorRT 會使用它并發出警告。您可以通過首選構建器配置中的類型約束來覆蓋此行為。
C++
config->setFlag(BuilderFlag::kPREFER_PRECISION_CONSTRAINTS)
Python
config.set_flag(trt.BuilderFlag.PREFER_PRECISION_CONSTRAINTS)
如果約束是首選的,TensorRT 會服從它們,除非沒有具有首選精度約束的實現,在這種情況下,它會發出警告并使用最快的可用實現。
要將警告更改為錯誤,請使用OBEY而不是PREFER:
C++
config->setFlag(BuilderFlag::kOBEY_PRECISION_CONSTRAINTS);
Python
config.set_flag(trt.BuilderFlag.OBEY_PRECISION_CONSTRAINTS);
sampleINT8API說明了使用這些 API 降低精度。
精度約束是可選的 – 您可以查詢以確定是否已使用C++ 中的layer->precisionIsSet()或 Python 中的layer.precision_is_set設置了約束。如果沒有設置精度約束,那么從 C++ 中的layer->getPrecision()返回的結果,或者在 Python 中讀取精度屬性,是沒有意義的。輸出類型約束同樣是可選的。
layer->getOutput(i)->setType()和layer->setOutputType()之間存在區別——前者是一種可選類型,它限制了 TensorRT 將為層選擇的實現。后者是強制性的(默認為 FP32)并指定網絡輸出的類型。如果它們不同,TensorRT 將插入一個強制轉換以確保兩個規范都得到尊重。因此,如果您為產生網絡輸出的層調用setOutputType(),通常還應該將相應的網絡輸出配置為具有相同的類型。
6.5.3. Enabling TF32 Inference Using C++
TensorRT 默認允許使用 TF32 Tensor Cores。在計算內積時,例如在卷積或矩陣乘法期間,TF32 執行執行以下操作:
- 將 FP32 被乘數舍入到 FP16 精度,但保持 FP32 動態范圍。
- 計算四舍五入的被乘數的精確乘積。
- 將乘積累加到 FP32 總和中。
TF32 Tensor Cores 可以使用 FP32 加速網絡,通常不會損失準確性。對于需要高動態范圍的權重或激活的模型,它比 FP16 更強大。
不能保證 TF32 Tensor Cores 會被實際使用,也沒有辦法強制實現使用它們 – TensorRT 可以隨時回退到 FP32,如果平臺不支持 TF32,則總是回退。但是,您可以通過清除 TF32 builder 標志來禁用它們。
C++
config->clearFlag(BuilderFlag::kTF32);
Python
config.clear_flag(trt.BuilderFlag.TF32)
盡管設置了BuilderFlag::kTF32,但在構建引擎時設置環境變量NVIDIA_TF32_OVERRIDE=0會禁用TF32。此環境變量在設置為0時會覆蓋 NVIDIA 庫的任何默認值或編程配置,因此它們永遠不會使用TF32 Tensor Cores加速 FP32 計算。這只是一個調試工具,NVIDIA 庫之外的任何代碼都不應更改基于此環境變量的行為。除0以外的任何其他設置都保留供將來使用。
警告:在引擎運行時將環境變量NVIDIA_TF32_OVERRIDE設置為不同的值可能會導致無法預測的精度/性能影響。引擎運轉時最好不要設置。
注意:除非您的應用程序需要 TF32 提供的更高動態范圍,否則FP16將是更好的解決方案,因為它幾乎總能產生更快的性能。
6.6. I/O Formats
TensorRT 使用許多不同的數據格式優化網絡。為了允許在 TensorRT 和客戶端應用程序之間有效傳遞數據,這些底層數據格式在網絡 I/O 邊界處公開,即用于標記為網絡輸入或輸出的張量,以及在將數據傳入和傳出插件時。對于其他張量,TensorRT 選擇導致最快整體執行的格式,并可能插入重新格式化以提高性能。
您可以通過分析可用的 I/O 格式以及對 TensorRT 之前和之后的操作最有效的格式來組裝最佳數據管道。
要指定 I/O 格式,請以位掩碼的形式指定一種或多種格式。 以下示例將輸入張量格式設置為TensorFormat::kHWC8。請注意,此格式僅適用于DataType::kHALF,因此必須相應地設置數據類型。
C++
auto formats = 1U << TensorFormat::kHWC8; network->getInput(0)->setAllowedFormats(formats); network->getInput(0)->setType(DataType::kHALF);
Python
formats = 1 << int(tensorrt.TensorFormat.HWC8) network.get_input(0).allowed_formats = formats network.get_input(0).dtype = tensorrt.DataType.HALF
通過設置構建器配置標志DIRECT_IO,可以使 TensorRT 避免在網絡邊界插入重新格式化。這個標志通常會適得其反,原因有兩個:
- 如果允許 TensorRT 插入重新格式化,則生成的引擎可能會更慢。重新格式化可能聽起來像是浪費工作,但它可以允許最有效的內核耦合。
- 如果 TensorRT 在不引入此類重新格式化的情況下無法構建引擎,則構建將失敗。故障可能僅發生在某些目標平臺上,因為這些平臺的內核支持哪些格式。
該標志的存在是為了希望完全控制重新格式化是否發生在 I/O 邊界的用戶,例如構建僅在 DLA 上運行而不回退到 GPU 進行重新格式化的引擎。
sampleIOFormats說明了如何使用 C++ 指定 IO 格式。
下表顯示了支持的格式。Table 1. Supported I/O formats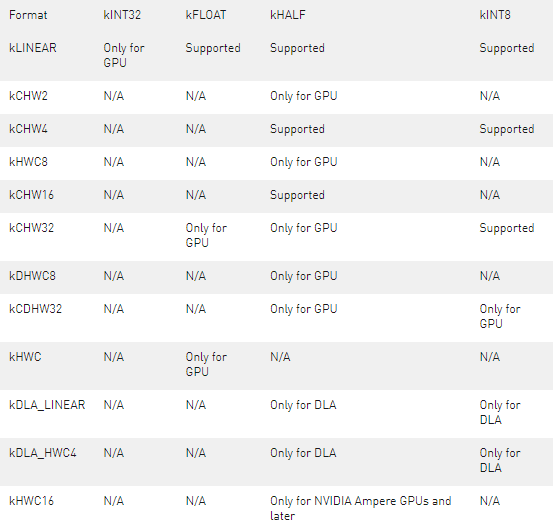
請注意,對于矢量化格式,通道維度必須補零到矢量大小的倍數。例如,如果輸入綁定的維度為[16,3,224,224] 、kHALF數據類型和kHWC8格式,則綁定緩沖區的實際所需大小將為16* 8 *224*224*sizeof(half)字節,甚至盡管engine->getBindingDimension()API 將張量維度返回為[16,3,224,224]。填充部分中的值(即本例中的C=3,4,…,7 )必須用零填充。
有關這些格式的數據在內存中的實際布局方式,請參閱數據格式說明。
6.7.Compatibility of Serialized Engines
僅當與用于序列化引擎的相同操作系統、CPU 架構、GPU 模型和 TensorRT 版本一起使用時,序列化引擎才能保證正常工作。
TensorRT 檢查引擎的以下屬性,如果它們與引擎被序列化的環境不匹配,將無法反序列化:
- TensorRT 的主要、次要、補丁和構建版本
- 計算能力(主要和次要版本)
這確保了在構建階段選擇的內核存在并且可以運行。此外,TensorRT 用于從 cuDNN 和 cuBLAS 中選擇和配置內核的 API 不支持跨設備兼容性,因此在構建器配置中禁用這些策略源的使用。 TensorRT 還會檢查以下屬性,如果它們不匹配,則會發出警告:
- 全局內存總線帶寬
- 二級緩存大小
- 每個塊和每個多處理器的最大共享內存
- 紋理對齊要求
- 多處理器數量
- GPU 設備是集成的還是分立的
如果引擎序列化和運行時系統之間的 GPU 時鐘速度不同,則從序列化系統中選擇的策略對于運行時系統可能不是最佳的,并且可能會導致一些性能下降。
如果反序列化過程中可用的設備內存小于序列化過程中的數量,反序列化可能會由于內存分配失敗而失敗。
在大型設備上構建小型模型時,TensorRT 可能會選擇效率較低但可在可用資源上更好地擴展的內核。因此,如果優化單個TensorRT 引擎以在同一架構中的多個設備上使用,最好的方法是在最小的設備上運行構建器。或者,您可以在計算資源有限的大型設備上構建引擎(請參閱限制計算資源部分)。
6.8. Explicit vs Implicit Batch
TensorRT 支持兩種指定網絡的模式:顯式批處理和隱式批處理。
在隱式批處理模式下,每個張量都有一個隱式批處理維度,所有其他維度必須具有恒定長度。此模式由 TensoRT 的早期版本使用,現在已棄用,但繼續支持以實現向后兼容性。 在顯式批處理模式下,所有維度都是顯式的并且可以是動態的,即它們的長度可以在執行時改變。許多新功能(例如動態形狀和循環)僅在此模式下可用。 ONNX 解析器也需要它。
例如,考慮一個處理 NCHW 格式的具有 3 個通道的大小為 HxW 的 N 個圖像的網絡。在運行時,輸入張量的維度為 [N,3,H,W]。這兩種模式在INetworkDefinition指定張量維度的方式上有所不同:
- 在顯式批處理模式下,網絡指定 [N,3,H,W]。
- 在隱式批處理模式下,網絡僅指定 [3,H,W]。批次維度 N 是隱式的。
“跨批次對話”的操作無法在隱式批次模式下表達,因為無法在網絡中指定批次維度。隱式批處理模式下無法表達的操作示例:
- 減少整個批次維度
- 重塑批次維度
- 用另一個維度轉置批次維度
例外是張量可以在整個批次中廣播,通過方法ITensor::setBroadcastAcrossBatch用于網絡輸入,并通過隱式廣播用于其他張量。
顯式批處理模式消除了限制 – 批處理軸是軸 0。顯式批處理的更準確術語是“batch oblivious”,因為在這種模式下,TensorRT 對引導軸沒有特殊的語義含義,除非特定操作需要. 實際上,在顯式批處理模式下,甚至可能沒有批處理維度(例如僅處理單個圖像的網絡),或者可能存在多個長度不相關的批處理維度(例如比較從兩個批處理中提取的所有可能對)。
INetworkDefinition時,必須通過標志指定顯式與隱式批處理的選擇。這是顯式批處理模式的 C++ 代碼:
IBuilder* builder = ...; INetworkDefinition* network = builder->createNetworkV2(1U << static_cast(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH)));
對于隱式批處理,使用createNetwork或將 0 傳遞給createNetworkV2。
這是顯式批處理模式的 Python 代碼:
builder = trt.Builder(...) builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
對于隱式批處理,省略參數或傳遞 0。
6.9. Sparsity
NVIDIA 安培架構 GPU 支持結構化稀疏性。為了利用該特性獲得更高的推理性能,卷積核權重和全連接權重必須滿足以下要求:
對于每個輸出通道和內核權重中的每個空間像素,每 4 個輸入通道必須至少有 2 個零。換句話說,假設內核權重的形狀為[K, C, R, S]和C % 4 == 0 ,那么要求是:
for k in K:
for r in R:
for s in S:
for c_packed in range(0, C // 4):
num_zeros(weights[k, c_packed*4:(c_packed+1)*4, r, s]) >= 2
要啟用稀疏特性,請在構建器配置中設置kSPARSE_WEIGHTS標志,并確保啟用kFP16或kINT8模式。例如
C++
config->setFlag(BuilderFlag::kSPARSE_WEIGHTS);
Python
config.set_flag(trt.BuilderFlag.SPARSE_WEIGHTS)
在構建 TensorRT 引擎時,在 TensorRT 日志的末尾,TensorRT 會報告哪些層包含滿足結構稀疏性要求的權重,以及 TensorRT 在哪些層中選擇了利用結構化稀疏性的策略。在某些情況下,具有結構化稀疏性的策略可能比正常策略慢,TensorRT 在這些情況下會選擇正常策略。以下輸出顯示了一個顯示有關稀疏性信息的 TensorRT 日志示例:
[03/23/2021-00:14:05] [I] [TRT] (Sparsity) Layers eligible for sparse math: conv1, conv2, conv3 [03/23/2021-00:14:05] [I] [TRT] (Sparsity) TRT inference plan picked sparse implementation for layers: conv2, conv3
強制內核權重具有結構化的稀疏模式可能會導致準確性損失。要通過進一步微調恢復丟失的準確性,請參閱PyTorch 中的 Automatic SParsity 工具。
要使用trtexec測量結構化稀疏性的推理性能,請參閱trtexec部分。
6.10. Empty Tensors
TensorRT 支持空張量。如果張量具有一個或多個長度為零的維度,則它是一個空張量。零長度尺寸通常不會得到特殊處理。如果一條規則適用于長度為 L 的任意正值 L 的維度,它通常也適用于 L=0。
例如,當沿最后一個軸連接兩個維度為[x,y,z]和[x,y,w]的張量時,結果的維度為[x,y,z+w],無論x,y, z,或者w為零。
隱式廣播規則保持不變,因為只有單位長度維度對廣播是特殊的。例如,給定兩個維度為[1,y,z]和[x,1,z]的張量,它們由IElementWiseLayer計算的總和具有維度[x,y,z],無論x、y 或 z是否為零.
如果一個引擎綁定是一個空的張量,它仍然需要一個非空的內存地址,并且不同的張量應該有不同的地址。這與C++中每個對象都有唯一地址的規則是一致的,例如new float[0]返回一個非空指針。如果使用可能返回零字節空指針的內存分配器,請改為請求至少一個字節。
有關空張量的任何每層特殊處理,請參閱TensorRT 層。
6.11. Reusing Input Buffers
TensorRT 還包括一個可選的 CUDA 事件作為enqueue方法的參數,一旦輸入緩沖區可以重用,就會發出信號。這允許應用程序在完成當前推理的同時立即開始重新填充輸入緩沖區以進行下一次推理。例如:
C++
context->enqueueV2(&buffers[0], stream, &inputReady);
Python
context.execute_async_v2(buffers, stream_ptr, inputReady)
6.12. Engine Inspector
TensorRT 提供IEngineInspectorAPI 來檢查 TensorRT 引擎內部的信息。從反序列化的引擎中調用createEngineInspector()創建引擎inspector,然后調用getLayerInformation()或getEngineInformation() inspectorAPI分別獲取引擎中特定層或整個引擎的信息。可以打印出給定引擎的第一層信息,以及引擎的整體信息,如下:
C++
auto inspector = std::unique_ptr(engine->createEngineInspector()); inspector->setExecutionContext(context); // OPTIONAL std::cout << inspector->getLayerInformation(0, LayerInformationFormat::kJSON); // Print the information of the first layer in the engine. std::cout << inspector->getEngineInformation(LayerInformationFormat::kJSON); // Print the information of the entire engine.
Python
inspector = engine.create_engine_inspector(); inspector.execution_context = context; # OPTIONAL print(inspector.get_layer_information(0, LayerInformationFormat.JSON); # Print the information of the first layer in the engine. print(inspector.get_engine_information(LayerInformationFormat.JSON); # Print the information of the entire engine.
請注意,引擎/層信息中的詳細程度取決于構建引擎時的ProfilingVerbosity構建器配置設置。默認情況下,ProfilingVerbosity設置為kLAYER_NAMES_ONLY,因此只會打印層名稱。如果ProfilingVerbosity設置為kNONE,則不會打印任何信息;如果設置為kDETAILED,則會打印詳細信息。
getLayerInformation()API 根據ProfilingVerbosity設置打印的層信息的一些示例:
kLAYER_NAMES_ONLY
node_of_gpu_0/res4_0_branch2a_1 + node_of_gpu_0/res4_0_branch2a_bn_1 + node_of_gpu_0/res4_0_branch2a_bn_2
kDETAILED
{
"Name": "node_of_gpu_0/res4_0_branch2a_1 + node_of_gpu_0/res4_0_branch2a_bn_1 + node_of_gpu_0/res4_0_branch2a_bn_2",
"LayerType": "CaskConvolution",
"Inputs": [
{
"Name": "gpu_0/res3_3_branch2c_bn_3",
"Dimensions": [16,512,28,28],
"Format/Datatype": "Thirty-two wide channel vectorized row major Int8 format."
}],
"Outputs": [
{
"Name": "gpu_0/res4_0_branch2a_bn_2",
"Dimensions": [16,256,28,28],
"Format/Datatype": "Thirty-two wide channel vectorized row major Int8 format."
}],
"ParameterType": "Convolution",
"Kernel": [1,1],
"PaddingMode": "kEXPLICIT_ROUND_DOWN",
"PrePadding": [0,0],
"PostPadding": [0,0],
"Stride": [1,1],
"Dilation": [1,1],
"OutMaps": 256,
"Groups": 1,
"Weights": {"Type": "Int8", "Count": 131072},
"Bias": {"Type": "Float", "Count": 256},
"AllowSparse": 0,
"Activation": "RELU",
"HasBias": 1,
"HasReLU": 1,
"TacticName": "sm80_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize256x128x64_stage4_warpsize4x2x1_g1_tensor16x8x32_simple_t1r1s1_epifadd",
"TacticValue": "0x11bde0e1d9f2f35d"
}
另外,當引擎使用動態形狀構建時,引擎信息中的動態維度將顯示為-1 ,并且不會顯示張量格式信息,因為這些字段取決于推理階段的實際形狀。要獲取特定推理形狀的引擎信息,請創建一個IExecutionContext,將所有輸入尺寸設置為所需的形狀,然后調用inspector->setExecutionContext(context)。設置上下文后,檢查器將打印上下文中設置的特定形狀的引擎信息。
trtexec工具提供了--profilingVerbosity、--dumpLayerInfo和--exportLayerInfo標志,可用于獲取給定引擎的引擎信息。有關詳細信息,請參閱trtexec部分。
目前,引擎信息中只包含綁定信息和層信息,包括中間張量的維度、精度、格式、策略指標、層類型和層參數。在未來的 TensorRT 版本中,更多信息可能會作為輸出 JSON 對象中的新鍵添加到引擎檢查器輸出中。還將提供有關檢查器輸出中的鍵和字段的更多規范。
關于作者
Ken He 是 NVIDIA 企業級開發者社區經理 & 高級講師,擁有多年的 GPU 和人工智能開發經驗。自 2017 年加入 NVIDIA 開發者社區以來,完成過上百場培訓,幫助上萬個開發者了解人工智能和 GPU 編程開發。在計算機視覺,高性能計算領域完成過多個獨立項目。并且,在機器人和無人機領域,有過豐富的研發經驗。對于圖像識別,目標的檢測與跟蹤完成過多種解決方案。曾經參與 GPU 版氣象模式GRAPES,是其主要研發者。
審核編輯:郭婷
-
C++
+關注
關注
22文章
2114瀏覽量
73801 -
CUDA
+關注
關注
0文章
121瀏覽量
13657
發布評論請先 登錄
相關推薦
什么是原子層刻蝕

帶屏蔽層的網線怎么接
MultiGABSE-AU物理層PMA子層及PMD子層的相關機制
AUTOSAR通信組件介紹 AUTOSAR通信層功能分析
OSI七層模型的每一層功能
詳解KiCad中的層

一文讓你了解PCB六層板布局
神經網絡中的卷積層、池化層與全連接層
三層神經網絡模型的基本結構是什么
反向傳播神經網絡分為多少層
PCB多層板為什么都是偶數層?奇數層不行嗎?
什么是PCB疊層?PCB疊層設計原則
雙電層電容器的工作原理 雙電層電容器的特點
華為顯示面板專利公布,聚焦介質層、平坦化層、像素界定層及電路設計





 工商網監
工商網監
評論