") 無人車業(yè)務(wù)中的視覺三維重建
無人車業(yè)務(wù)中的視覺三維重建
業(yè)務(wù)背景
高精地圖也稱為高分辨率地圖(High Definition Map, HDMap)或者高度自動駕駛地圖(Highly Automated Driving Map, HAD Map)。近些年,隨著自動駕駛技術(shù)以及業(yè)務(wù)的蓬勃發(fā)展,高精地圖成為了實現(xiàn)高等級自動駕駛必不可少的數(shù)據(jù)。
高精地圖是一類擁有精確的地理位置信息和豐富的道路元素語義信息的地圖數(shù)據(jù),能起到構(gòu)建類似于人腦對于空間的整體記憶與認(rèn)知功能,可以幫助自動駕駛車輛預(yù)知路面復(fù)雜信息,如坡度、曲率、航向等,更好的規(guī)避潛在的風(fēng)險。是實現(xiàn)自動駕駛的關(guān)鍵所在。
高精地圖以精細(xì)描述道路及其車道線、路沿、護(hù)欄、交通燈、交通標(biāo)志牌、動態(tài)信息為主要內(nèi)容,具有精度高、數(shù)據(jù)維度多、時效性高等特點(diǎn)。為自動駕駛汽車的規(guī)劃、決策、控制、定位、感知等應(yīng)用提供支撐,是自動駕駛解決方案的基礎(chǔ)及核心。
高精地圖與普通的導(dǎo)航地圖不同,主要面向自動駕駛汽車,通過車輛自身特有的定位導(dǎo)航體系,協(xié)助自動駕駛系統(tǒng)完成規(guī)劃、決策、控制等功能,以及解決自動駕駛車輛計算性能限制問題,拓展傳感器檢測范圍。
通俗來講,高精地圖是比普通導(dǎo)航地圖精度更高,數(shù)據(jù)維度更廣的地圖。其精度更高體現(xiàn)在地圖精度精確到厘米級,數(shù)據(jù)維度更廣則體現(xiàn)在地圖數(shù)據(jù)除了道路信息以外還包括與交通相關(guān)的周圍靜態(tài)、動態(tài)信息。
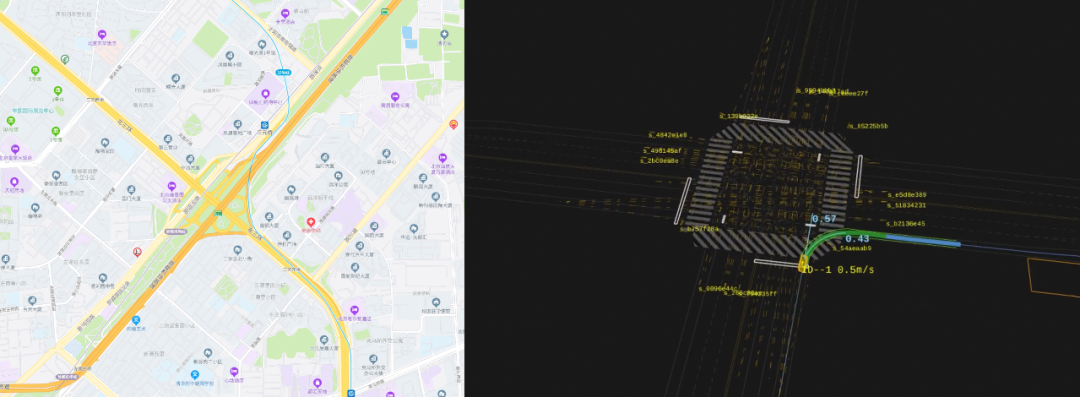
普通導(dǎo)航地圖(左)vs高精地圖(右)
1.2 高精地圖對自動駕駛的價值
高精地圖作為自動駕駛的稀缺資源和必備構(gòu)件,能夠滿足自動駕駛車輛在行駛過程中地圖精確計算匹配、實時路徑規(guī)劃導(dǎo)航、輔助環(huán)境感知、駕駛決策輔助和智能汽車控制的需要,并在每個環(huán)節(jié)都發(fā)揮著至關(guān)重要的作用。主要有以下幾個方面: 輔助環(huán)境感知 傳感器作為自動駕駛的感官,有其局限性,如易受惡劣環(huán)境影響,性能受限或者算法魯棒性不足等。高精地圖可以對傳感器無法探測或者探測精度不夠的部分進(jìn)行補(bǔ)充,實現(xiàn)實時狀況的檢測以及外部信息的反饋,進(jìn)而獲取當(dāng)前位置精準(zhǔn)的交通狀況。
通過對高精地圖的解析,可以將當(dāng)前自動駕駛車輛周邊的道路、交通設(shè)施、基礎(chǔ)設(shè)施等元素和元素質(zhì)檢的拓?fù)溥B接關(guān)系提取出來。如果自動駕駛汽車在行駛過程中檢測到高精地圖不存在的元素,則在一定程度上可將這些元素視為障礙物。通過該方式,可以幫助感知系統(tǒng)識別周圍環(huán)境,提高檢測精度和檢測速度,并節(jié)約計算資源。
輔助定位 由于定位系統(tǒng)可能因環(huán)境關(guān)系或者系統(tǒng)穩(wěn)定性問題存在定位誤差,無人駕駛車輛并不能與周圍環(huán)境始終保持正確的位置關(guān)系,在無人駕駛車輛行駛過程中,利用高精地圖元素匹配可精確定位車輛在車道上的具體位置,從而提高無人駕駛車輛的定位精度。
相比更多的依賴于GNSS(Global Navigation Satellite System,全球?qū)Ш叫l(wèi)星系統(tǒng))提供定位信息的普通導(dǎo)航地圖,高精地圖更多依靠其準(zhǔn)確且豐富的先驗信息(如車道形狀、曲率、路面導(dǎo)向箭頭、交通標(biāo)志牌等),通過結(jié)合高維度數(shù)據(jù)與高效率的匹配算法,能夠?qū)崿F(xiàn)符合自動駕駛車輛所需的高精度定位功能。
輔助路徑規(guī)劃決策 普通導(dǎo)航地圖僅能給出道路級的路徑規(guī)劃,而高精地圖的路徑規(guī)劃導(dǎo)航能力則提高到了車道級,例如高精地圖可以確定車道的中心線,可以保證無人駕駛車輛盡可能地靠近車道中心行駛。在人行橫道、低速限制或減速帶等區(qū)域,高精地圖可使無人駕駛車輛能夠提前查看并預(yù)先減速。對于汽車行駛附近的障礙物,高精地圖可以幫助自動駕駛汽車縮小路徑選擇范圍,以便選擇最佳避障方案。
輔助控制 高精地圖是對物理環(huán)境道路信息的精準(zhǔn)還原,可為無人駕駛車輛加減速、并道和轉(zhuǎn)彎等駕駛決策控制提供關(guān)鍵道路信息。而且,高精地圖能給無人駕駛車輛提供超視距的信息,并與其他傳感器形成互補(bǔ),輔助系統(tǒng)對無人駕駛車輛進(jìn)行控制。
高精地圖為無人駕駛車輛提供了精準(zhǔn)的預(yù)判信息,具有提前輔助其控制系統(tǒng)選擇合適的行駛策略功能,有利于減少車載計算平臺的壓力以及對計算性能瓶頸的突破,使控制系統(tǒng)更多關(guān)注突發(fā)狀況,為自動駕駛提供輔助控制能力。因此,高精地圖在提升汽車安全性的同時,有效降低了車載傳感器和控制系統(tǒng)的成本。
1.3 高精地圖生產(chǎn)的路線
精度與成本的平衡
與傳統(tǒng)的標(biāo)精地圖生產(chǎn)相比,衛(wèi)星影像已經(jīng)無法滿足高精地圖的精度需求,地圖制作需要在地面進(jìn)行實際道路采集。為了滿足高精地圖的精度需求,業(yè)界的各家公司分別給出了不同的數(shù)據(jù)采集方案。主要可以分為以激光雷達(dá)(LiDAR)+ 組合慣導(dǎo) + RTK的高精度自采方案,以及有RTK+視覺的眾包采集方案。
簡單的講,這兩種方案主要是在精度與成本兩個因素中進(jìn)行取舍的結(jié)果。兩者都經(jīng)歷了長期的演進(jìn),孰優(yōu)孰劣無法一概而論。或者說,方案的選擇更多的要看具體的業(yè)務(wù)需求與場景條件。接下來本文對兩種采集方案進(jìn)行簡要的介紹。
“高富帥”的高精自采方案:LiDAR+慣導(dǎo)+RTK
很多自動駕駛廠商目前上線使用的高精地圖的原始數(shù)據(jù)都采集自高規(guī)格的多傳感器(LiDAR+慣導(dǎo)+RTK)采集設(shè)備。這種數(shù)據(jù)可重建出具備厘米級精度的道路地圖,但其采用的各種“頂配傳感器”動輒幾十萬元。業(yè)界常見的裝備齊全的高精地圖采集車通常都需要幾百萬元一輛。加上其背后的巨大的數(shù)據(jù)處理及運(yùn)維成本,真可謂是“高富帥”的建圖方案。
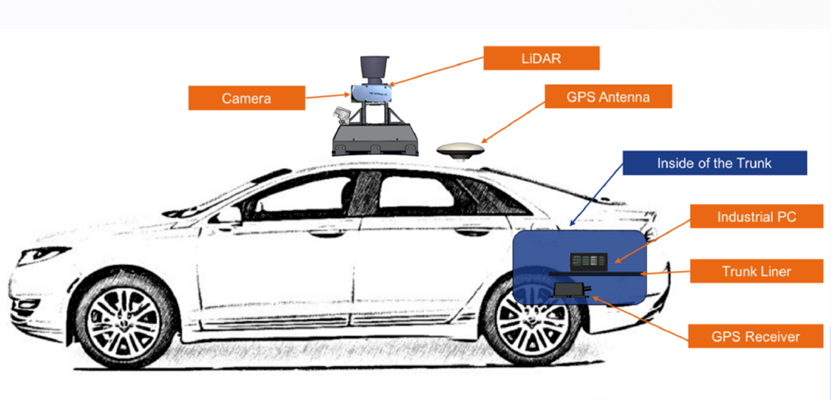
“LiDAR+慣導(dǎo)+RTK” 采集方案的采集車12
在這種方案下,建圖主要過程是以慣導(dǎo)+RTK融合的位姿作為先驗,之后基于LiDAR點(diǎn)云進(jìn)行三維場景的高精重建。得到精確的位姿和點(diǎn)云后,再通過LiDAR在地面上的反射率圖恢復(fù)出路面標(biāo)識,并進(jìn)一步進(jìn)行矢量化,最終完成高精地圖的生產(chǎn)。通常而言,這種以LiDAR+慣導(dǎo)為主的建圖方法所獲得的高精地圖可以達(dá)到厘米級別的地圖精度,以滿足自動駕駛中實時精準(zhǔn)定位的需求。
經(jīng)濟(jì)實惠的視覺眾包方案:GNSS+視覺
對于高精地圖生產(chǎn)而言,最大的成本不在于完成一次全路網(wǎng)的地圖構(gòu)建,而在于如何解決高精地圖的隨時更新。如何用較低的成本維持一個城市級別乃至國家級別路網(wǎng)的鮮度,才是各大地圖廠商面臨的最大挑戰(zhàn)。
隨著傳感器芯片的不斷發(fā)展,集成了GNSS、IMU(Inertial measurementunit,慣性測量單元)模塊與攝像頭的模塊的一體式設(shè)備成本已經(jīng)到達(dá)百元級別。事實上,這一傳感器組合采集的數(shù)據(jù)在很多路況下已經(jīng)可以勝任高精地圖重建任務(wù)。目前道路上有大量乘用車已經(jīng)安裝了帶有GNSS功能的行車記錄儀。一方面,行車記錄儀可以保證日常的行車安全需要。另一方面,記錄儀采集的原始數(shù)據(jù)可以通過網(wǎng)絡(luò)回傳到服務(wù)器,經(jīng)過數(shù)據(jù)清洗工作后形成建圖數(shù)據(jù)集,并進(jìn)一步通過地圖重建算法形成高精地圖。
由于傳感器成本較低,這樣的采集數(shù)據(jù)較之上文的“高富帥”方案精度較低,同時受路況和天氣的影響較大。因此在這種方案下,需要有很好的算法能力以及數(shù)據(jù)清洗能力,才能完成相應(yīng)的高精地圖生產(chǎn)與更新。
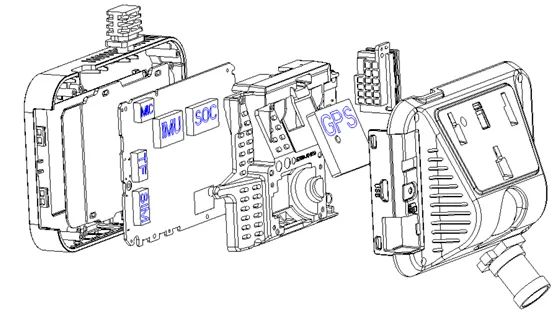
GNSS+視覺解決方案13 對于這種性價比極高的眾包方案,技術(shù)上有很多難關(guān)要攻克。例如如何高效合理的對原始采集數(shù)據(jù)進(jìn)行回傳與篩選,如何指定特定的區(qū)域進(jìn)行更新,如何克服低價傳感器帶來的各種誤差,如何解決設(shè)備多樣性帶來的誤差等等。同時,如果真的將這種方式投入到規(guī)模化的高精地圖生產(chǎn),還需要解決好法律上的測繪合規(guī)的問題。 本文要介紹的視覺重建算法,正是這種高性價比重建方案中的核心技術(shù)。接下來,將基于這種GNSS+視覺的采集方式,介紹一下幾類可行的視覺重建系統(tǒng)設(shè)計方案。
視覺重建的系統(tǒng)設(shè)計
基于不同業(yè)務(wù)場景,數(shù)據(jù)特點(diǎn),研發(fā)人員可以為視覺重建設(shè)計不同的算法流程。這里簡單介紹三類:基于Structure-from-Motion的重建、基于深度網(wǎng)絡(luò)的視覺重建、基于語義的矢量化視覺重建。下面將一一進(jìn)行介紹。 2.1 基于Structure-from-Motion的重建 在視覺高精地圖重建方面,Structure-form-Motion (SfM) 方案是非常常見的選擇。從業(yè)務(wù)需求上講,建圖大多無實時性要求,而對精度的要求較為嚴(yán)格。相比之下,各種VO或SLAM方案要追求實時性,同時其最終的目的更傾向于定位,而非建圖。SfM方案更強(qiáng)調(diào)建圖的精度,方案中并無時序性要求。這為地圖的長期維護(hù)提供了便利。典型的SfM重建流程大致可以分為特征提取、稀疏重建,稠密重建三個步驟。

Colmap中的SfM重建流程1? 特征與匹配 在SfM中,首先要進(jìn)行的就是特征點(diǎn)的提取與匹配工作。這一部分中,最經(jīng)典的莫過于SIFT特征子1。如果不限制具體的應(yīng)用場景(室內(nèi) vs. 室外,自然景觀 vs. 人造物體等等),那么SIFT特征子可以在各類場景中均有比較穩(wěn)定的特征提取與匹配結(jié)果。 隨著近些年深度學(xué)習(xí)網(wǎng)絡(luò)的發(fā)展,很多研究者提出了基于深度學(xué)習(xí)的特征提取與匹配方案。其中最著名的當(dāng)屬M(fèi)agicLeap團(tuán)隊提出的SuperPoint(CVPR2018)2+ SuperGlue(CVPR2020)3方案。 SuperPoint作為一種特征點(diǎn)提取算法,采用了自監(jiān)督的方式進(jìn)行訓(xùn)練,并采用了Homographic Adaptation技術(shù)大大加強(qiáng)了提取特征點(diǎn)的場景適應(yīng)性。相比于傳統(tǒng)的SIFT,提取的特征點(diǎn)可信度更強(qiáng)。 SuperGlue作為一種特征匹配算法,引入了注意力機(jī)制來強(qiáng)化網(wǎng)絡(luò)對特征的表達(dá)能力,從而使得在視差較大的兩幅圖像之間仍然可以很好的找到特征點(diǎn)間的匹配關(guān)系。在CVPR2020/ECCV2020的indoor/outdoor localization challenges中,使用了SuperPoint以及SuperGlue的方案名列前茅,充分展現(xiàn)了這兩種方法在特征提取與匹配方面的優(yōu)勢。

基于SuperPoint+SuperGlue的特征提取與匹配效果1? 在今年的CVPR2021上,商湯團(tuán)隊發(fā)表了LofTR?。該工作基于Transformer構(gòu)建了一個端到端的特征匹配模型,對于弱紋理區(qū)域可以給出較為準(zhǔn)確的匹配結(jié)果。由于Transformer提供了較大的感受野,使之可以更好的利用全局信息去對局部特征進(jìn)行描述。相較SuperPoint+SuperGlue,該方法在室內(nèi)的弱紋理場景有著更為穩(wěn)定可信的匹配結(jié)果。

LofTR的特征匹配結(jié)果1?稀疏重建 完成了特征點(diǎn)的提取與匹配后,便可以開始增量式的稀疏重建。算法會基于一定的篩選條件,選擇兩幀作為初始幀,利用雙視幾何(two-view-geometry)的方法計算兩幀的相對位姿,并基于其中的一幀構(gòu)建本次重建的坐標(biāo)系。當(dāng)位姿確認(rèn)后,就可以基于特征點(diǎn)的匹配關(guān)系,三角化出空間中的3D地圖點(diǎn)。初始化完成后,便可以繼續(xù)選擇尚未注冊的新圖像注冊到模型中。注冊時可以用雙視幾何計算其與已有幀的相對位姿,也可以用3D-2D的方法(例如PnP, pespective-n-point)計算位姿,甚至可以使用精度較高的先驗位姿直接注冊。注冊后要再次進(jìn)行三角化,計算出更多的3D地圖點(diǎn)。同時,在注冊一定數(shù)量的新幀后,需要進(jìn)行BA(bundle adjustment)優(yōu)化,進(jìn)一步優(yōu)化位姿與地圖點(diǎn)的精度。上述注冊新幀,三角化,BA優(yōu)化的過程將循環(huán)進(jìn)行,直到完成所有圖像的重建。最終,就獲得了所有圖像的位姿以及一個由稀疏地圖點(diǎn)構(gòu)成的稀疏重建結(jié)果。

長距離稀疏重建結(jié)果
稠密重建
完成稀疏重建后,需要進(jìn)行稠密化建圖。這個過程中,首先要解決深度估計問題。得到了深度圖之后,結(jié)合深度圖與相機(jī)位姿,就可以進(jìn)行物體表面紋理的稠密重建。
以Colmap?中的稠密重建過程為例。首先要進(jìn)行深度估計。這個模塊大致可分為匹配代價構(gòu)造,代價累積,深度估計,深度圖優(yōu)化這四個部分。Colmap中使用了NCC來構(gòu)造匹配代價,之后使用Patch Match作為信息傳遞的策略。通過這個過程,深度估計問題轉(zhuǎn)化為針對每個特征,尋找其最優(yōu)的深度和法向量。整個過程利用GEM算法進(jìn)行優(yōu)化。Colmap中的方案對于弱紋理的區(qū)域無法很好的給出較好的深度估計。
在得到深度估計結(jié)果(深度圖)后,各幀的深度圖會進(jìn)行融合。在融合后RGB圖像上的像素就可以投影到三維空間中,得到稠密點(diǎn)云,完成最終的稠密重建。
對于道路場景而言,由于路面的特征點(diǎn)非常稀少(典型的弱紋理),所以使用經(jīng)典的算法恢復(fù)路面紋理具有較大的挑戰(zhàn)。于是,很多研究者開始嘗試?yán)蒙疃?a href="http://m.1cnz.cn/tags/神經(jīng)網(wǎng)絡(luò)/" target="_blank">神經(jīng)網(wǎng)絡(luò)去解決這一難題。
2.2 基于深度網(wǎng)絡(luò)的視覺重建 在SfM中,當(dāng)在稀疏重建中獲得了相機(jī)的位姿之后,還需要稠密的深度圖來準(zhǔn)確的恢復(fù)出路面的DOM(Digital Orthophoto Map,數(shù)字正射影像圖)以及各種交通標(biāo)識。而基于特征點(diǎn)的SfM僅能提供一些稀疏的路面點(diǎn),這對于恢復(fù)路面平面是遠(yuǎn)遠(yuǎn)不夠的。因此需要借助其他方法來進(jìn)行稠密的深度恢復(fù)。 近些年,隨著深度學(xué)習(xí)的迅猛發(fā)展,越來越多的工作實現(xiàn)了基于RGB圖像的深度預(yù)測。按照工作發(fā)表的前后順序,大致可以將這一研究方向分為四類,分別是:基于單幀圖像的深度估計,基于多幀圖像的深度估計,同時估計相機(jī)運(yùn)動與深度,基于自監(jiān)督訓(xùn)練的運(yùn)動與深度估計。 基于單幀的深度估計 對于神經(jīng)網(wǎng)絡(luò)深度估計,最簡單的方式要算基于單幀的深度估計。這一領(lǐng)域比較經(jīng)典的工作有MonoDepth?及MonoDepth2?這兩個工作基于雙目的約束進(jìn)行無監(jiān)督訓(xùn)練,獲得的模型可以基于單幀RGB圖像輸出深度圖。 此種方法雖然可以很好的預(yù)測出稠密的深度圖,但由于在預(yù)測過程中缺乏幾何約束,因此模型存在泛化性的問題。一旦相機(jī)參數(shù)或者場景類型發(fā)生了變化,模型很難保證可以給出正確的深度預(yù)測。同時,幀間的深度連續(xù)性也是這種方法難以解決的問題。因此,單幀的深度預(yù)測很難應(yīng)用到高精地圖的重建過程中。

單目深度預(yù)測:MonoDepth21?
基于多幀圖像的深度估計
考慮到實際場景中我們的輸入是一個圖像序列,因此利用多視幾何(Multiview Video Stereo, MVS)進(jìn)行多幀的深度估計可以很好的解決單幀深度估計中多幀之間的深度連續(xù)性問題,同時由于可以利用幀間的幾何約束,模型能預(yù)測更準(zhǔn)確的深度值。
近些年很多工作圍繞這個問題展開。一個比較經(jīng)典的工作是MVSNet?,作者利用多幀構(gòu)建cost volume,對深度進(jìn)行估計。獲得初步的深度估計結(jié)果后,再通過一個優(yōu)化網(wǎng)絡(luò),對深度圖做進(jìn)一步的優(yōu)化,最終可以得到比較理想的深度信息。對于視覺高精重建任務(wù)而言,由于位姿存在著一定的誤差。因此一旦某一幀的位姿計算錯誤,將會直接影響相鄰幀的深度預(yù)測。因此這種方案在道路重建任務(wù)中存在著一定的局限性。
同時估計相機(jī)運(yùn)動與深度
解決多幀圖像深度估計問題時,可以借鑒經(jīng)典SfM算法中“預(yù)測新幀的位姿-三角化獲得地圖點(diǎn)”這樣迭代的思路,讓網(wǎng)絡(luò)交替預(yù)測位姿與深度,并進(jìn)行多輪迭代。這樣能保證深度與位姿之間可以有很好的幾何匹配,同時也可以獲得較高的預(yù)測精度。
在這一方面,DeepV2D?是一個比較有代表性的工作。DeepV2D中引入了深度估計和運(yùn)動估計兩個子網(wǎng)絡(luò)。網(wǎng)絡(luò)會選取一個長度為5-8幀的滑窗,滑窗內(nèi)的圖像會輸入到兩個子網(wǎng)絡(luò)中,推理得到的深度和位姿會相互更新。經(jīng)過幾輪更新之后,最終就可以得到連續(xù)性好,精度高的深度預(yù)測結(jié)果。這種網(wǎng)絡(luò)設(shè)計充分的利用了圖像的運(yùn)動特性與幾何約束,可以很好的利用相鄰的多幀信息的對深度進(jìn)行預(yù)測。在兩個子網(wǎng)迭代結(jié)果的過程中,預(yù)測精度會逐漸收斂,得到的深度也會有比較好的連續(xù)性。
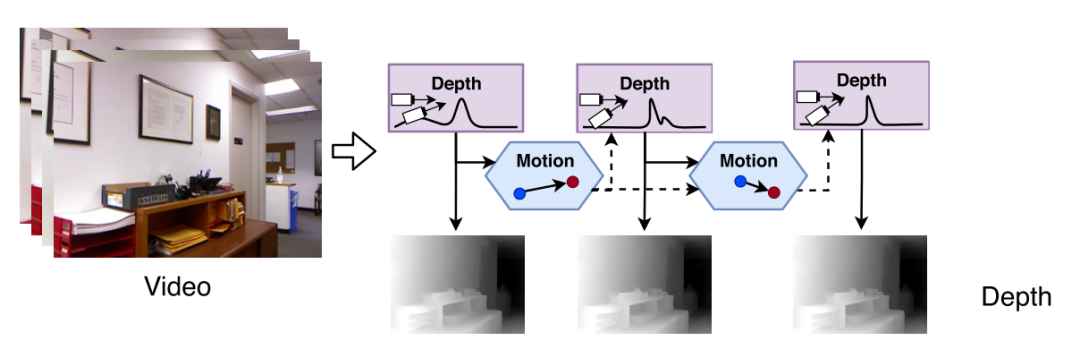
同時預(yù)測深度與相機(jī)運(yùn)動的網(wǎng)絡(luò):DeepV2D1?
下圖展示了使用LiDAR數(shù)據(jù)訓(xùn)練而得的深度估計網(wǎng)絡(luò)模型,在實際道路上預(yù)測深度的結(jié)果。可見在這種典型的弱紋理場景下,網(wǎng)絡(luò)一方面可以較好的預(yù)測出平整的路面,同時也可以對物體邊緣(路沿,樹木)有較好的描述。

輸入RGB圖像(上)深度預(yù)測結(jié)果(下)
基于自監(jiān)督訓(xùn)練的運(yùn)動與深度估計
在上一類工作中,為了訓(xùn)練運(yùn)動估計網(wǎng)絡(luò)與深度估計網(wǎng)絡(luò),需要大量高精度的深度圖作為訓(xùn)練數(shù)據(jù)。為了解決一些業(yè)務(wù)上缺乏訓(xùn)練數(shù)據(jù)的問題,有一些研究者提出了無監(jiān)督的訓(xùn)練方法去進(jìn)行單目深度估計訓(xùn)練。例如最近在CVPR2021上發(fā)表的ManyDepth1?。類似于Monodepth,此方法利用了cost volume進(jìn)行深度估計。對于相鄰幀,其預(yù)測了幀間的相對位置,以便于多幀之前構(gòu)建cost volume。同時也使用提取局部特征的方法,將特征圖輸入到最終的深度預(yù)測中,提高深度預(yù)測的穩(wěn)定性。對于道路場景深度預(yù)測中最難解決的動態(tài)物體問題,該工作也給出了基于置信度預(yù)測的解決方案。
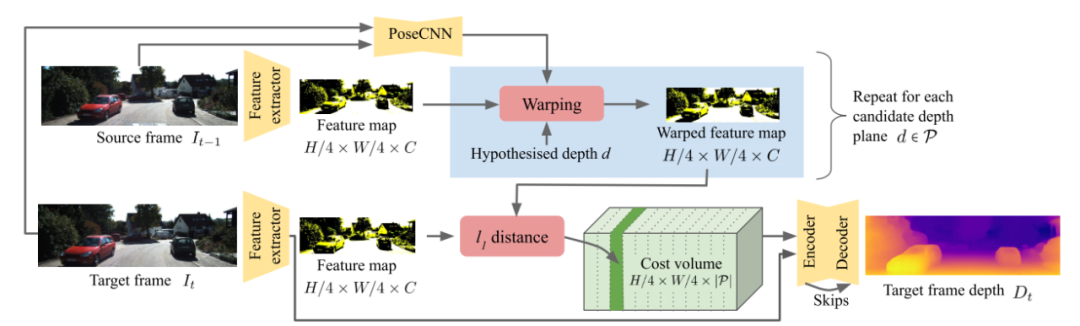
自監(jiān)督的單目深度估計網(wǎng)絡(luò):ManyDepth1?
2.3 基于語義的矢量化視覺重建
端側(cè)實時重建
在業(yè)界一些廠商的實踐中,有些公司提出了“通過語義分割檢測+語義重建來創(chuàng)建矢量地圖”(地平線NavNet方案11)。該方案僅需一顆前視攝像頭,運(yùn)用深度學(xué)習(xí)和SLAM技術(shù)實現(xiàn)了道路場景的語義三維重建,將建圖與定位的過程全部在車端實時進(jìn)行。車輛通過前視攝像頭捕捉即時交通信息,然后抽象出道路場景的特征(即實現(xiàn)場景語義三維重建),并直接在車端完成地圖“繪制”與定位。 在數(shù)據(jù)采集過程中,路況信息的采集通過幾項相關(guān)的傳感器來實現(xiàn)——攝像頭,GNSS和IMU。在這之后,輸入的圖像數(shù)據(jù)會進(jìn)行基于神經(jīng)網(wǎng)絡(luò)的語義分析,以獲得主要的道路要素信息。 在建圖過程中,方案通過語義SLAM的方式來實現(xiàn)高精度地圖的創(chuàng)建。具體來說,方案使用語義分割檢測+語義重建來創(chuàng)建矢量地圖,將后端優(yōu)化、語義識別和參數(shù)化等方面和鏈路,融合成為一條優(yōu)化模塊——聯(lián)合優(yōu)化模塊,既簡化了工作的流程,節(jié)約時間和運(yùn)算能耗,又可以實現(xiàn)同樣的功能。 如果在同一路段有多次采集的數(shù)據(jù),在云端可以將大量車輛采集的地圖片段數(shù)據(jù)進(jìn)行關(guān)聯(lián)匹配,以矢量地圖要素的屬性參數(shù)為變量,根據(jù)屬性的相似度約束建立統(tǒng)一的目標(biāo)函數(shù),優(yōu)化求解以獲得融合地圖結(jié)果。這一融合優(yōu)化過程既可以定時全量執(zhí)行,也可以根據(jù)地圖更新的結(jié)論,經(jīng)過事件觸發(fā)進(jìn)行高效融合之后,提供更新、更精準(zhǔn)的地圖信息,即可快速地發(fā)布到車端供車輛定位導(dǎo)航使用。
離線重建
由于實時性的要求,端側(cè)實時重建方案需要偏定制化的硬件方案來提供足夠的算力支撐。另一方面,如果不需要實時的建圖,也可以使用前文提到的SfM方式先進(jìn)行稀疏重建并使用神經(jīng)網(wǎng)絡(luò)預(yù)測深度圖,之后結(jié)合語義分割結(jié)果進(jìn)行后續(xù)的要素跟蹤與矢量化。
具體而言,在獲得相機(jī)位姿和深度信息后,可以將路面像素投影到世界坐標(biāo)系中。之后,使用了語義跟蹤的技術(shù)來對反投影出的路面進(jìn)行融合。也就是利用幀間特征點(diǎn)的匹配關(guān)系,將每一幀投影的路面切片進(jìn)行對齊與融合,就可以得到相對平整清晰的路面DOM。同時在圖像上進(jìn)行路面標(biāo)識的檢測,基于檢測結(jié)果提取矢量關(guān)鍵點(diǎn),并把這些關(guān)鍵點(diǎn)投到路面,就獲得了矢量化的路面標(biāo)識。在長距離的重建過程中,在多次經(jīng)過或者掉頭的場景,會出現(xiàn)已經(jīng)矢量化的車道線或路面標(biāo)識重影。可以對已經(jīng)恢復(fù)出的矢量標(biāo)識進(jìn)行回環(huán)檢測,并對其進(jìn)行與融合,進(jìn)一步消弭位姿與深度誤差帶來的影響。

基于語義分割及檢測進(jìn)行路面標(biāo)識矢量化(上)車道線矢量化的結(jié)果(下)
業(yè)務(wù)實踐中的探索
上文介紹了業(yè)界常見的幾種視覺建圖方案路線。在實際應(yīng)用的過程中,可以基于業(yè)務(wù)場景、數(shù)據(jù)特點(diǎn)、成本限制、硬件條件等實際因素,對其中的一些步驟進(jìn)行改造或組合。在這種改造中,只有對每種建圖路線的優(yōu)劣、限制條件有著比較深入的理解,才能真正設(shè)計出貼合業(yè)務(wù)需求的好算法方案。在無人車的地圖生產(chǎn)過程中,我們結(jié)合實際運(yùn)營的業(yè)務(wù)需求與場景條件,也進(jìn)行了一些積極的探索。
在SfM重建過程中,目前稀疏重建算法只能處理短距離場景(2公里左右),而這距離實際業(yè)務(wù)需求有著指數(shù)級的差距。我們設(shè)計了分段重建、多段拼接以及聯(lián)合優(yōu)化的策略,把稀疏重建算法真正的應(yīng)用于實際業(yè)務(wù),不僅保證了重建精度,絕對誤差控制在0.5米以內(nèi),而且極大的縮短了重建耗時。
在特征點(diǎn)提取以及深度估計的網(wǎng)絡(luò)訓(xùn)練過程中,目前的公開數(shù)據(jù)集和實際業(yè)務(wù)場景之間存在較大的domain gap。因此我們采用了transfer learning的算法進(jìn)行了初步的探索,取得了不錯的成果,最終重建的精度和穩(wěn)定性都獲得了顯著的提升。
總結(jié)與展望
在高精建圖重建任務(wù)中,相比于激光建圖路線,視覺建圖路線具備精度略低,成本極低,算力消耗較低等特點(diǎn)。因此,視覺建圖更適合進(jìn)行大范圍實時的更新。 在業(yè)務(wù)實踐中,激光建圖和視覺建圖的優(yōu)勢被很好的融合在了一起。在視覺重建方案中,利用了激光建圖生成的點(diǎn)云數(shù)據(jù)進(jìn)行訓(xùn)練數(shù)據(jù)集的構(gòu)建,得到了貼合實際場景的深度預(yù)測模型。通過視覺重建獲得的DOM和道路元素矢量結(jié)果可以對激光建圖結(jié)果形成很好的補(bǔ)充,提高了建圖生產(chǎn)的魯棒性。 在后續(xù)的迭代過程中,我們會持續(xù)的基于業(yè)務(wù)的需要和運(yùn)營場景的特點(diǎn)進(jìn)行技術(shù)優(yōu)化。除了提升既有的方案性能,還將對一些新的方向進(jìn)行探索,包括:
全路況全天候的更新發(fā)現(xiàn)技術(shù)
全國范圍內(nèi)全等級道路的更新維護(hù)能力
端云結(jié)合的建圖計算架構(gòu)
希望通過我們的努力,為無人車配送業(yè)務(wù)提供新鮮而高質(zhì)量的高精地圖,保證業(yè)務(wù)的健康發(fā)展,把生活的便利帶給每一位消費(fèi)者。
審核編輯 :李倩
-
自動駕駛
+關(guān)注
關(guān)注
784文章
13924瀏覽量
166858 -
無人車
+關(guān)注
關(guān)注
1文章
304瀏覽量
36529
原文標(biāo)題:無人車業(yè)務(wù)中的視覺三維重建
文章出處:【微信號:vision263com,微信公眾號:新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
三維測量在醫(yī)療領(lǐng)域的應(yīng)用
三維測量技術(shù)在工業(yè)中的應(yīng)用
三維掃描與建模的區(qū)別 三維掃描在工業(yè)中的應(yīng)用
三維激光掃描儀與無人機(jī)結(jié)合的應(yīng)用
商湯科技運(yùn)用AI大模型實現(xiàn)實景三維重建
CASAIM與邁普醫(yī)學(xué)達(dá)成合作,三維掃描技術(shù)助力醫(yī)療輔具實現(xiàn)高精度三維建模和偏差比對
建筑物邊緣感知和邊緣融合的多視圖立體三維重建方法

三維可視化技術(shù)的應(yīng)用現(xiàn)狀和發(fā)展前景
留形科技借助NVIDIA平臺提供高效精確的三維重建解決方案
基于大模型的仿真系統(tǒng)研究一——三維重建大模型
泰來三維|三維激光掃描技術(shù)在古建筑保護(hù)中的應(yīng)用

三維可視:展現(xiàn)未來的視覺盛宴
泰來三維|數(shù)字化工廠_煤礦三維掃描數(shù)字化解決方案

三維掃描與3D打印在法醫(yī)頭骨重建中的突破性應(yīng)用
泰來三維|文物三維掃描,文物三維模型怎樣制作






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論