 HugeCTR系列第2部分:訓練大型深度學習推薦模型
HugeCTR系列第2部分:訓練大型深度學習推薦模型
在 Merlin HugeCTR 博文系列的第一部分,我們討論了訓練大型深度學習推薦系統所面臨的挑戰,以及 HugeCTR 如何解決這些問題。
深度學習推薦系統可能包含超大型嵌入表,這些嵌入表可能會超出主機或 GPU 顯存。
我們專為推薦系統設計了 HugeCTR。
這是一個專門用于在 GPU 上訓練和部署大型推薦系統的框架。
它為在多個 GPU 或節點上分配單個嵌入表提供了不同的策略。
HugeCTR 是 NVIDIA Merlin] 的主要訓練引擎,后者是一種 GPU 加速框架,旨在為推薦系統工作提供一站式服務,從數據準備、特征工程、多 GPU 訓練到本地或云中的生產級推理。
訓練性能和可擴展性一直是 HugeCTR 的突出特性,為 MLPerf 訓練 v0.7 推薦任務中的 NVIDIA 獲獎作品提供支持,但我們近期采納了早期采用者和客戶的反饋,以幫助改進易用性。
這篇博文將著重討論我們在易用性方面的持續承諾和近期改進。
HugeCTR 是一種定制的深度學習框架,使用 CUDA C++ 編寫,專用于推薦系統。
起初,超參數和神經網絡架構在 JSON 配置中定義,然后通過命令行接口執行。
表 1 匯總了命令行和 Python API 之間的主要區別。
我們建議使用 Python API,并將在后面部分中重點介紹。
但是,如果您對命令行界面感興趣,可以在此處找到一些示例。
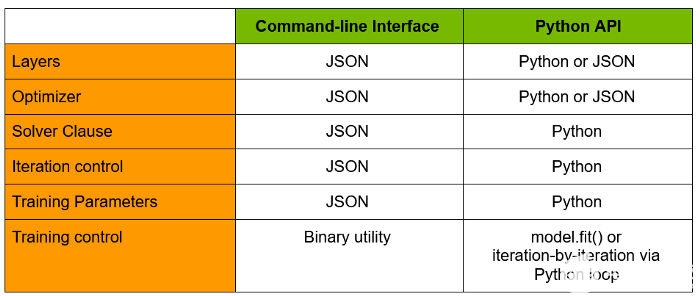
表 1:HugeCTR 接口比較。
直接從 Python 配置和訓練 HugeCTR
自 v2.3 版本起,HugeCTR 開始提供易于使用的 Python 接口,用于定義模型架構、超參數、數據加載程序以及訓練循環。
此接口使 HugeCTR 更接近于數據科學 Python 生態系統和實踐。
利用此接口的方法有兩種:
1. 類似于 Keras 的高級 Python API
HugeCTR 現在提供了一個類似 Keras 的高級 Python API 套件,用于定義模型、層、優化器和執行訓練。
下文提供了一個示例代碼段。
如下所示,此 API 模擬熱門的 Keras 構建-編譯-適應范式。
2. 低級 Python API
HugeCTR 低級 Python API 允許從 JSON 文件讀取模型定義和優化器配置,從而提供向后兼容性。
此外,此 API 允許使用 Python 循環不斷手動執行訓練,從而獲得對訓練的精細控制。
在本博客的動手實踐部分中,我們將詳細介紹如何使用此 API 基于兩個數據集訓練模型。
我們將在以下示例中演示此 API。
使用預訓練的 HugeCTR 模型進行預測
隨著 v3.0 版本的發布,HugeCTR 增加了對基于 GPU 的推理的支持,可生成許多批次的預測。
HugeCTR 將參數服務器、嵌入緩存和推理會話分離開來,以便更好地管理資源以及更有效地利用 GPU。
參數服務器用于加載和管理嵌入表。
對于超過 GPU 顯存的嵌入表,參數服務器將嵌入表存儲在 CPU 內存上。
嵌入緩存為模型提供嵌入查找服務。活動嵌入條目存儲在 GPU 顯存上,以便快速查找。
推理會話將這兩者與模型權重和其他參數結合起來,以執行前向傳播。
下文提供了初始化 HugeCTR 推理的函數調用序列示例。
我們將使用 config_file、embedding_cache 和 parameter_server 初始化 InferenceSession。
HugeCTR Python 推理 API 需要一個 JSON 格式的推理配置文件,該文件類似于訓練配置 JSON。
但是,在添加推理子句時,我們需要省略優化器和求解器子句。
我們還需要將輸出層更改為 Sigmoid 類型。
推理子句中的 dense_model_file 和 sparse_model_file 參數應設置為指向由 HugeCTR 訓練的模型文件(_dense_xxxx.model 和 0_sparse_xxxx.model)。
我們在 Github 存儲庫中提供了多個完整示例:電子商務行為數據集和 Microsoft 新聞數據集。
我們一起來看一些示例
我們在 Github 存儲庫中提供了 HugeCTR API 的多個端到端示例。這些筆記本基于實際數據集和應用領域提供了完整的 Merlin 演練,從數據下載、預處理和特征工程到模型訓練和推理。
1. 高級 Python API 與 Criteo 數據集
Criteo 1TB Click Logs 數據集是公開可用于推薦系統的大型數據集。
它包含約 40 億個示例的 1.3TB 未壓縮點擊日志。
在我們的示例中,數據集使用 Pandas 或 NVTabular 進行預處理,以規范化連續特征,并對分類特征進行分類。
之后,我們使用 HugeCTR 的高級 API 訓練深度和交叉神經網絡架構。
首先,我們定義求解器和優化器,以使用它初始化 HugeCTR 模型。
然后,我們可以逐層添加,這類似于 TensorFlow Keras API。
最后,我們只需要調用 .fit() 函數。
2. 低級 Python API 與電子商務行為數據集
在此演示筆記本中,我們將使用 REES46 營銷平臺中的多品類商店的電子商務行為數據[/u]作為我們的數據集。
此筆記本基于 RecSys 2020 大會上的 NVIDIA 教程構建而成。
我們使用 NVTabular 進行特征工程和預處理,并使用 HugeCTR 訓練 Facebook 深度學習推薦系統模型 (DLRM)。
我們針對 Criteo 點擊日志數據集改編了一個示例 Json 配置文件。
需要編輯以與此數據集匹配的幾個參數為:
slot_size_array:分類變量的基數,可以從 NVTabular 工作流程對象獲取。
dense_dim:密集特征的數量
slot_num:分類變量的數量
以下 Python 代碼會按批執行參數更新。

同樣,我們針對 Microsoft 新聞數據集提供了第 2 個示例。
嘗試使用 HugeCTR 的命令行和 Python API 訓練推薦系統管線
我們致力于提供用戶友好且易于使用的體驗,以簡化推薦系統工作流程。
我們近期根據早期采用者和客戶的反饋對 HugeCTR 接口進行了改進。
HugeCTR Github 存儲庫提供了有關如何基于多個公共數據集(從小型到大型數據集都包含在內)使用此新接口的示例。
我們想邀請您針對您自己的領域改編這些示例,并見證 Merlin 的處理能力。
和往常一樣,我們希望通過 Github 以及其他渠道獲得您的反饋。
這是我們 HugeCTR 系列中關于“使用 HugeCTR 的新 API 訓練大型深度學習推薦系統模型”的第二篇博文。
下一篇博文將討論如何部署到生產。
關于作者
Vinh Nguyen 是一位深度學習的工程師和數據科學家,發表了 50 多篇科學文章,引文超過 2500 篇。在 NVIDIA ,他的工作涉及廣泛的深度學習和人工智能應用,包括語音、語言和視覺處理以及推薦系統。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5072瀏覽量
103507 -
API
+關注
關注
2文章
1509瀏覽量
62263 -
深度學習
+關注
關注
73文章
5511瀏覽量
121392
發布評論請先 登錄
相關推薦
直播預約 |數據智能系列講座第4期:預訓練的基礎模型下的持續學習







 工商網監
工商網監
評論